







unordered_set、unordered_map 与其 multi 类的简单模拟实现与源码展示
一、前言
unordered_set、unordered_map、unordered_multiset、unordered_multimap 的底层都使用的是哈希表,关于哈希表的讲解与源码获取请参考:哈希表介绍、实现与封装
由于这四种类关联性强,核心部分会放在一起讲解。
以下代码环境为 VS2022 C++。
二、multi 多重设计
unordered_multiset 与 unordered_multimap 支持相同 key 值重复,我们只需要修改哈希表 的 insert 底层部分逻辑即可。
当然,这需要分开非多重的与多重的执行函数。这里用的是仿函数处理,哈希表采取模版使用仿函数,用来针对 multi 与 非 multi 情况。
insert 多重设计
对于 multi 类,插入一定会成功,返回 true 即可。对于 非 multi 类,我们需要遍历当前哈希桶中的所有元素,重复即插入失败返回 false,反之返回 true。
struct IsMultiInsertSolve
{
template<class pNode, class Key, class GetKey, class EqualTo>
bool operator()(pNode cur, const Key& key, const GetKey& _getKey, const EqualTo& _equalt_to) const
{
return true; // 允许 Multi,则一直插入成功
}
};
struct NoMultiInsertSolve
{
template<class pNode, class Key, class GetKey, class EqualTo>
bool operator()(pNode cur, const Key& key, const GetKey& _getKey, const EqualTo& _equal_to) const
{
while (cur != nullptr) // 检查重复值,有则插入失败
{
if (_equal_to(_getKey(cur->_data), key))
{
return false;
}
cur = cur->_next;
}
return true;
}
};
三、迭代器实现
iterator 实现思路分析
iterator 实现的框架跟 list 的 iterator 思路是一致的,用一个类型封装结点的指针,再通过重载运算符实现,迭代器像指针一样访问哈希桶的数据,要注意的是哈希表的迭代器是单向迭代器。
这里的难点是 operator++ 的实现。iterator 中有一个指向结点的指针,如果:
-
当前桶下面还有结点,则结点的指针指向下一个结点。
-
当前桶走完了,需要想办法计算找到下一个桶,则我们需要找到当前所在的哈希桶位置(使用哈希函数获取)和 哈希表记录哈希桶的 vector 去定位,这时下一个不为空的桶的第一个节点就是目标。
所以设计迭代器时可以传哈希表对象的指针,也可以仅仅传它的 哈希函数 与 vector 。
begin() 返回第一个桶中第一个节点指针构造的迭代器,这里 end() 返回迭代器可以用空表示。
unordered_set 与其他三个类 iterator 的 key 不支持修改,在哈希表内我们把 vector 的元素类型和迭代器的模板参数改成 const Key 或者 pair<const Key, Value> 即可。
迭代器实现可参考下面的代码。
迭代器实现代码展示
template<class Type, class Reference, class Pointer, class GetKey, class HashFunc>
class Iterator // 获取数据的 key // 哈希函数
{
typedef Iterator<Type, Reference, Pointer, GetKey, HashFunc> Self;
typedef HashNode<Type> Node;
typedef Node* pNode;
pNode _point_node;
const std::vector<pNode>& _table; // 记录哈希桶的 vector 获取
static const constexpr GetKey _getKey = GetKey();
static const constexpr HashFunc _hashFunc = HashFunc();
template<class Type, class Key, class GetKey, class HashFunc, class EqualTo, class MultiInsertSolve>
friend class HashTable_base;
public:
Iterator(const pNode& point_node, const std::vector<pNode>& table)
:_point_node(point_node)
, _table(table)
{
;
}
bool operator==(const Self& it) const
{
return _point_node == it._point_node;
}
bool operator!=(const Self& it) const
{
return _point_node != it._point_node;
}
Reference operator*() const
{
return _point_node->_data;
}
Pointer operator->() const
{
return &(_point_node->_data);
}
Self& operator++() // 单向迭代器只有 ++
{
assert(_point_node != nullptr);
if (_point_node->_next != nullptr) // 下一个地址不空 ++ 就是下一个节点
{
_point_node = _point_node->_next;
return *this;
}
Hash_mapping index = (_hashFunc(_getKey(_point_node->_data)) + 1) % _table.size();
while (index < _table.size() && _table[index] == nullptr) // 找到下一个不为空的哈希桶
{
++index;
}
if (index >= _table.size()) // 如果后面没有数据,这里规定 nullptr 为 end()
{
_point_node = nullptr;
}
else
{
_point_node = _table[index]; // 有数据,直接指向第一个节点
}
return *this;
}
};
四、基础实现
基础函数实现
四个类的大多数函数相同,我们可以先在哈希表中实现,其他再具体处理即可。
迭代器实现
四个类的迭代器实现相同,这里以 unordered_set 为例。
迭代器实现请参考:
std::unordered_set::begin
std::unordered_set::end
std::unordered_map::cbegin
std::unordered_multimap::cend
注意到实现时有 local_iterator 与 const_local_iterator,它们是哈希桶的迭代器,参数中加入了 size_type 类型的 n,表示的是 编号为 n 的哈希桶。
begin(n) 表示得到哈希表第 n 个哈希桶的开始节点,end(n) 表示得到哈希表第 n 个哈希桶的结束位置(因为是遵循左闭右开原则 [ begin, end ) ),则实现时将 n 进行哈希函数处理,begin 直接返回当前哈希桶的第一个节点的迭代器,end 返回下一个哈希桶的第一个节点的迭代器。
typedef Iterator<Type, Type&, Type*, GetKey, HashFunc> iterator;
typedef Iterator<Type, const Type&, const Type*, GetKey, HashFunc> const_iterator;
typedef iterator local_iterator;
typedef const_iterator const_local_iterator;
iterator begin()
{
const_iterator it = cbegin();
return { it._point_node, _table };
}
iterator end()
{
return iterator(nullptr, _table);
}
const_iterator begin() const
{
assert(_size != 0);
Hash_mapping index = 0;
while (_table[index] == nullptr)
{
++index;
}
return const_iterator(_table[index], _table);
}
const_iterator end() const
{
return const_iterator(nullptr, _table);
}
const_iterator cbegin() const
{
return begin();
}
const_iterator cend() const
{
return end();
}
local_iterator begin(size_t index)
{
const_local_iterator it = cbegin(index);
return { it._point_node, _table };
}
local_iterator end(size_t index)
{
const_local_iterator it = cend(index);
return { it._point_node, _table };
}
const_local_iterator begin(size_t index) const
{
assert(index < _table.size());
assert(_table[index] != nullptr);
return { _table[index], _table };
}
const_local_iterator end(size_t index) const
{
++index; // 寻找下一个桶的第一个节点迭代器
while (index < _table.size() && _table[index] == nullptr)
{
++index;
}
if (index < _table.size())
{
return { _table[index], _table };
}
else
{
return { nullptr, _table };
}
}
const_local_iterator cbegin(size_t index) const
{
return begin(index);
}
const_local_iterator cend(size_t index) const
{
return end(index);
}
插入实现
插入实现请参考:
std::unordered_set::insert
std::unordered_multiset::insert
std::unordered_map::insert
std::unordered_multimap::insert
这里只实现 3 个,包括 迭代器插入实现、初始化列表实现、正常插入。
迭代器插入实现、初始化列表实现可以直接在哈希表内部实现。正常插入我们可以先在哈希表中实现返回值为 std::pair<iterator, bool> 的 insert 来兼容 非 multi 类型,在 四个类中 再分别进行适配处理。
std::pair<iterator, bool> insert(const Type& data)
{
checkCapacity(); // 容量检查
Hash_mapping index = _hashFunc(_getKey(data)) % _table.size();
pNode cur = _table[index];
// multi 与 非 multi 处理
if (_mulInsertSolve(cur, _getKey(data), _getKey, _equal_to) == false)
{
return { iterator(cur, _table) , false };
}
pNode newNode = new Node(data); // 这里直接头插
newNode->_next = _table[index];
_table[index] = newNode;
++_size;
return { iterator(newNode, _table), true };
}
template<class InputIterator>
void insert(InputIterator begin, InputIterator end)
{
while (begin != end)
{
insert(*begin);
++begin;
}
}
void insert(std::initializer_list<Type> list)
{
for (auto& e : list)
{
insert(e);
}
}
查找实现
查找实现请参考:
std::unordered_set::find
std::unordered_multiset::find
std::unordered_map::find
std::unordered_multimap::find
multixxx 的 find 需要找到当前容器中第一个插入的相同的 key,实现比较麻烦。而这里实现 unordered_multixxx 的 find 只需要寻找到匹配的 key 值即可。
pNode _find(const Key& key) const
{
if (_size == 0)
{
return nullptr;
}
Hash_mapping index = _hashFunc(key) % _table.size();
pNode cur = _table[index];
while (cur != nullptr)
{
if (_equal_to(_getKey(cur->_data), key)) // 找到直接返回地址
{
return cur;
}
cur = cur->_next;
}
return nullptr; // 否则为空
}
iterator find(const Key& key)
{
return iterator(_find(key), _table);
}
const_iterator find(const Key& key) const
{
return const_iterator(_find(key), _table);
}
删除实现
std::unordered_set::erase
std::unordered_multiset::erase
std::unordered_map::erase
std::unordered_multimap::erase
iterator erase(const_iterator position)
{
--_size;
const_iterator const_next = position;
++const_next;
iterator next = { const_next._point_node, _table };
Hash_mapping index = _hashFunc(_getKey(*position)) % _table.size();
if (_table[index] == position._point_node) // 是头节点删除返回
{
_table[index] = position._point_node->_next;
delete position._point_node;
position._point_node = nullptr; // 删除后迭代器失效
return next;
}
pNode prev = _table[index]; // 其他节点需要遍历哈希桶
pNode cur = prev->_next;
while (cur != nullptr)
{
if (cur == position._point_node)
{
prev->_next = cur->_next;
delete cur;
cur = prev->_next;
break;
}
else
{
prev = cur;
cur = cur->_next;
}
}
position._point_node = nullptr; // 删除后迭代器失效
return next;
}
size_t erase(const Key& key)
{
if (_size == 0)
{
return 0;
}
size_t before = _size; // 删除前的个数
// 兼容 multi 删除
Hash_mapping index = _hashFunc(key) % _table.size();
while (_table[index] != nullptr && _equal_to(_getKey(_table[index]->_data), key))
{ // 数据有可能连续堆积在头节点,使用循环
pNode temp = _table[index];
_table[index] = _table[index]->_next;
delete temp;
--_size;
}
if (_table[index] == nullptr)
{
return before - _size;
}
pNode prev = _table[index];
pNode cur = prev->_next;
while (cur != nullptr)
{
if (_equal_to(_getKey(cur->_data), key))
{
prev->_next = cur->_next;
delete cur;
cur = prev->_next;
--_size;
}
else
{
prev = cur;
cur = cur->_next;
}
}
return before - _size;
}
iterator erase(const_iterator begin, const_iterator end)
{
while (begin != end)
{
const_iterator temp = begin;
++begin;
erase(temp);
}
return iterator(end._point_node, _table);
}
计数实现
计数实现请参考:
std::unordered_set::count
std::unordered_multiset::count
std::unordered_map::count
std::unordered_multimap::count
为兼容 multi 的计数,哈希表中实现的计数返回的是 size_t 类型:
size_t count(const Key& key) const
{
Hash_mapping index = _hashFunc(key) % _table.size();
pNode cur = _table[index];
size_t count = 0;
while (cur != nullptr) // 统计相同 key 个数
{
if (_equal_to(_getKey(cur->_data), key))
{
++count;
}
cur = cur->_next;
}
return count;
}
哈希表内部实现
哈希表中要求有 load_factor,我们实现的同时一并把与它有关联的简单函数实现,四个类中都一样,这里以 unordered_set 的为参考。
float set_load_factor = 1.0f; // 负载因子
bucket_count
std::unordered_set::bucket_count
返回当前哈希表中桶的数量:
size_t bucket_count() const
{
return _table.size();
}
max_bucket_count
std::unordered_set::max_bucket_count
返回哈希表最多能够记录多少个哈希桶:
size_t max_bucket_count() const
{
return 4294967291; // 这里存的最大质数是它,那就只能记录这么多个哈希桶
}
bucket_size
std::unordered_set::bucket_size
返回当前编号的哈希桶存储的节点数量:
size_t bucket_size(Hash_mapping index) const
{
assert(index < _table.size());
size_t count = 0;
for (pNode cur = _table[index]; cur != nullptr; cur = cur->_next)
{
++count;
}
return count;
}
bucket
std::unordered_set::bucket
返回 key 所在哈希桶的编号:
size_t bucket(const Key& key) const
{
return _hashFunc(key);
}
load_factor
std::unordered_set::load_factor
返回当前负载因子:
float load_factor() const
{
return 1.0f * _size / _table.size();
}
max_load_factor
std::unordered_set::max_load_factor
返回负载因子上限,超过上限哈希表会扩容:
float max_load_factor() const
{
return set_load_factor;
}
void max_load_factor(float num)
{
set_load_factor = num; // 重新设置最大负载因子
}
rehash
std::unordered_set::rehash
当 num 大于当前哈希表容量会进行扩容处理,小于或等于未定(这里小于等于直接退出)。
void rehash(size_t num)
{
if (num <= _table.size())
{
return;
}
capacityExpansion(num);
}
reserve
std::unordered_set::reserve
与 rehash 有细微差别,是在 num 大于 哈希表容量 × 负载因子 再扩容,小于或等于未定(这里小于等于直接退出)。
void reserve(size_t num)
{
if (num <= _table.size() * set_load_factor)
{
return;
}
capacityExpansion(num);
}
unordered_map operator[] 处理
unordered_map operator[] 实现请参考:
std::unordered_map::operator[]
unordered_map 的 operator[] 比较特殊,当在 unordered_map 中找到对应的 key 会返回对应的 value ,如果没有对应的 key 会插入 key 值,其 value 会使用其默认构造函数构造。
四个类中只有它需要使用,这里拿出来单独在 unordered_map 中实现:
Value& operator[](const Key& key)
{
auto get = insert({ key, Value() }); // 插入失败会返回已有的迭代器
return get.first->second;
}
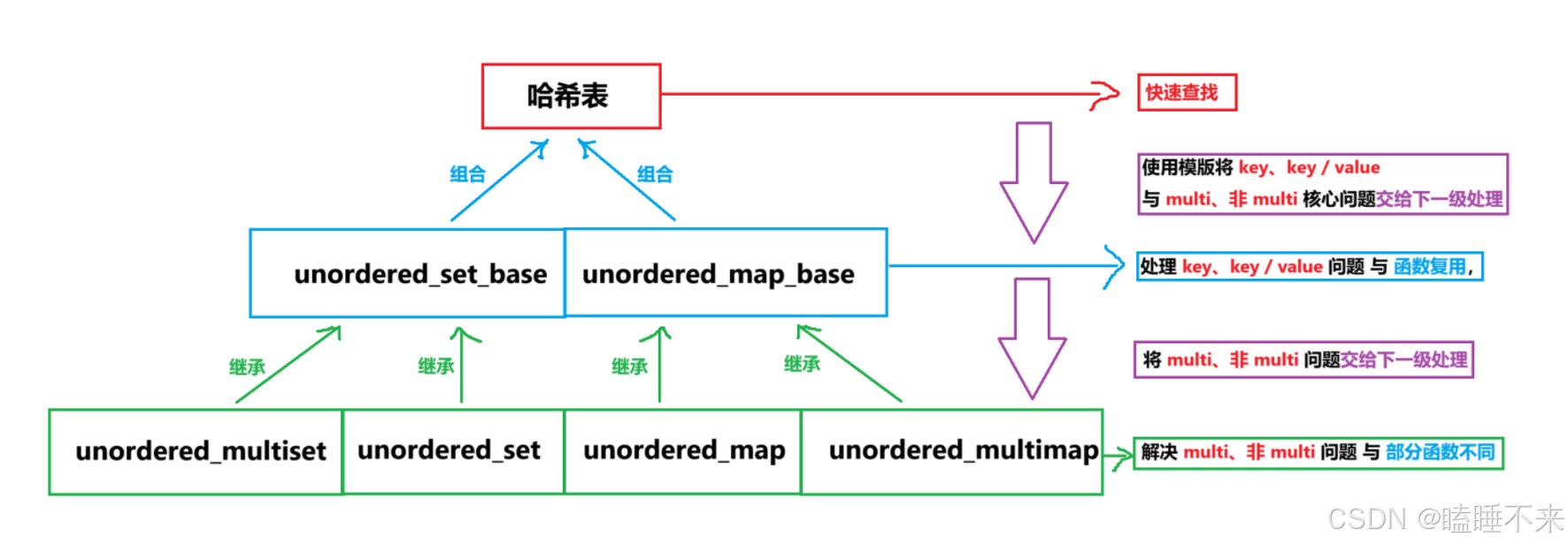
unordered_set、unordered_map 与其 multi 类设计
我们可以设计一个层次结构来具体处理上面遗留的问题:
-
哈希表使用模版将 key、key / value 与 multi、非 multi 核心问题交给下一级处理。
-
我们使用 unordered_set_base 和 unordered_map_base 与哈希表组合,处理 key、key / value 问题 与 函数复用,将 multi、非 multi 问题交给下一级处理。
-
unordered_set、unordered_multiset 继承 unordered_set_base,解决 multi、非 multi 问题 与 部分函数不同,unordered_map、unordered_multimap 继承 unordered_map_base,解决 multi、非 multi 问题 与 部分函数不同。
用图来表示更清晰:
源码放在下一部分。
五、源码展示
哈希表源码
在 HashTable.hpp 中:
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include <cassert>
namespace my
{
template<class Type>
struct HashNode
{
HashNode* _next = nullptr;
Type _data;
HashNode(const Type& data)
:_data(data)
{
;
}
};
typedef unsigned int Hash_mapping;
template<class Type, class Reference, class Pointer, class GetKey, class HashFunc>
class Iterator // 获取数据的 key // 哈希函数
{
typedef Iterator<Type, Reference, Pointer, GetKey, HashFunc> Self;
typedef HashNode<Type> Node;
typedef Node* pNode;
pNode _point_node;
const std::vector<pNode>& _table; // 记录哈希桶的 vector 获取
static const constexpr GetKey _getKey = GetKey();
static const constexpr HashFunc _hashFunc = HashFunc();
template<class Type, class Key, class GetKey, class HashFunc, class EqualTo, class MultiInsertSolve>
friend class HashTable_base;
public:
Iterator(const pNode& point_node, const std::vector<pNode>& table)
:_point_node(point_node)
, _table(table)
{
;
}
bool operator==(const Self& it) const
{
return _point_node == it._point_node;
}
bool operator!=(const Self& it) const
{
return _point_node != it._point_node;
}
Reference operator*() const
{
return _point_node->_data;
}
Pointer operator->() const
{
return &(_point_node->_data);
}
Self& operator++() // 单向迭代器只有 ++
{
assert(_point_node != nullptr);
if (_point_node->_next != nullptr) // 下一个地址不空 ++ 就是下一个节点
{
_point_node = _point_node->_next;
return *this;
}
Hash_mapping index = (_hashFunc(_getKey(_point_node->_data)) + 1) % _table.size();
while (index < _table.size() && _table[index] == nullptr) // 找到下一个不为空的哈希桶
{
++index;
}
if (index >= _table.size()) // 如果后面没有数据,这里规定 nullptr 为 end()
{
_point_node = nullptr;
}
else
{
_point_node = _table[index]; // 有数据,直接指向第一个节点
}
return *this;
}
};
template<class Type, class Key, class GetKey, class HashFunc, class EqualTo, class MultiInsertSolve>
class HashTable_base
{
typedef HashNode<Type> Node;
typedef Node* pNode;
static const constexpr GetKey _getKey = GetKey();
static const constexpr EqualTo _equal_to = EqualTo();
static const constexpr HashFunc _hashFunc = HashFunc();
static const constexpr MultiInsertSolve _mulInsertSolve = MultiInsertSolve();
std::vector<pNode> _table;
size_t _size = 0;
float _set_load_factor = 1.0f;
private:
static const int prime_num = 28;
static int getNextPrime(int num)
{
static const Hash_mapping prime_list[prime_num] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291,
};
int left = 0;
int right = prime_num - 1;
while (left < right)
{
int mid = left + ((right - left) >> 1);
if (prime_list[mid] <= num)
{
left = mid + 1;
}
else
{
right = mid;
}
}
return prime_list[left];
}
void checkCapacity()
{
if (_size < _table.size() * _set_load_factor)
{
return;
}
capacityExpansion(_table.size());
}
void capacityExpansion(size_t num)
{
std::vector<pNode> newTable;
newTable.resize(getNextPrime(num));
for (pNode& head : _table) // 可以不用删除节点,修改它的指针成员链接即可
{
if (head == nullptr)
{
continue;
}
pNode cur = head;
while (cur != nullptr) // 链表遍历修改链接
{
Hash_mapping index = _hashFunc(_getKey(cur->_data)) % newTable.size();
pNode temp = cur;
cur = cur->_next;
if (newTable[index] == nullptr) // 为空
{
newTable[index] = temp;
temp->_next = nullptr;
}
else // 否则头插
{
temp->_next = newTable[index];
newTable[index] = temp;
}
}
head = nullptr;
}
std::swap(_table, newTable); // 交换即可
}
pNode _find(const Key& key) const
{
if (_size == 0)
{
return nullptr;
}
Hash_mapping index = _hashFunc(key) % _table.size();
pNode cur = _table[index];
while (cur != nullptr)
{
if (_equal_to(_getKey(cur->_data), key)) // 找到直接返回地址
{
return cur;
}
cur = cur->_next;
}
return nullptr; // 否则为空
}
std::pair<pNode, pNode> _equal_range(const Key& key) const
{
Hash_mapping index = _hashFunc(key) % _table.size();
pNode cur = _table[index];
pNode first = nullptr;
pNode last = nullptr;
while (cur != nullptr)
{
if (_equal_to(_getKey(cur->_data), key))
{
if (first == nullptr)
{
first = cur;
}
last = cur;
}
}
iterator getLast(last, _table);
++getLast;
return { first, getLast._point_node };
}
public:
HashTable_base()
:_table(53)
{
;
}
HashTable_base(const HashTable_base& hashTable)
:_table(hashTable._table.size())
, _size(hashTable._size)
,_set_load_factor(hashTable._set_load_factor)
{
for (size_t i = 0; i < hashTable._table.size(); ++i)
{
if (hashTable._table[i] == nullptr)
{
continue;
}
pNode cur = hashTable._table[i];
_table[i] = new Node(cur->_data);
cur = cur->_next;
pNode prev = _table[i];
while (cur != nullptr)
{
prev->_next = new Node(cur->_data);
prev = cur;
cur = cur->_next;
}
}
}
HashTable_base& operator=(const HashTable_base& hashTable)
{
if (this == &hashTable)
{
return *this;
}
HashTable_base temp = hashTable;
swap(temp);
return *this;
}
HashTable_base(HashTable_base&& hashTable)
{
swap(hashTable);
}
HashTable_base& operator=(HashTable_base&& hashTable)
{
swap(hashTable);
return *this;
}
void swap(HashTable_base& hashTable)
{
std::swap(_table, hashTable._table);
std::swap(_size, hashTable._size);
std::swap(_set_load_factor, hashTable._set_load_factor);
}
template<class InputIterator>
HashTable_base(InputIterator begin, InputIterator end)
: _table(53)
{
while (begin != end)
{
insert(*begin);
++begin;
}
}
HashTable_base(std::initializer_list<Type> list)
:_table(53)
{
for (auto& e : list)
{
insert(e);
}
}
~HashTable_base()
{
clear();
}
public:
typedef Iterator<Type, Type&, Type*, GetKey, HashFunc> iterator;
typedef Iterator<Type, const Type&, const Type*, GetKey, HashFunc> const_iterator;
typedef iterator local_iterator;
typedef const_iterator const_local_iterator;
iterator begin()
{
const_iterator it = cbegin();
return { it._point_node, _table };
}
iterator end()
{
return iterator(nullptr, _table);
}
const_iterator begin() const
{
assert(_size != 0);
Hash_mapping index = 0;
while (_table[index] == nullptr)
{
++index;
}
return const_iterator(_table[index], _table);
}
const_iterator end() const
{
return const_iterator(nullptr, _table);
}
const_iterator cbegin() const
{
return begin();
}
const_iterator cend() const
{
return end();
}
local_iterator begin(size_t index)
{
const_local_iterator it = cbegin(index);
return { it._point_node, _table };
}
local_iterator end(size_t index)
{
const_local_iterator it = cend(index);
return { it._point_node, _table };
}
const_local_iterator begin(size_t index) const
{
assert(index < _table.size());
assert(_table[index] != nullptr);
return { _table[index], _table };
}
const_local_iterator end(size_t index) const
{
++index; // 寻找下一个桶的第一个节点迭代器
while (index < _table.size() && _table[index] == nullptr)
{
++index;
}
if (index < _table.size())
{
return { _table[index], _table };
}
else
{
return { nullptr, _table };
}
}
const_local_iterator cbegin(size_t index) const
{
return begin(index);
}
const_local_iterator cend(size_t index) const
{
return end(index);
}
public:
std::pair<iterator, bool> insert(const Type& data)
{
checkCapacity(); // 容量检查
Hash_mapping index = _hashFunc(_getKey(data)) % _table.size();
pNode cur = _table[index];
// multi 与 非 multi 处理
if (_mulInsertSolve(cur, _getKey(data), _getKey, _equal_to) == false)
{
return { iterator(cur, _table) , false };
}
pNode newNode = new Node(data); // 这里直接头插
newNode->_next = _table[index];
_table[index] = newNode;
++_size;
return { iterator(newNode, _table), true };
}
template<class InputIterator>
void insert(InputIterator begin, InputIterator end)
{
while (begin != end)
{
insert(*begin);
++begin;
}
}
void insert(std::initializer_list<Type> list)
{
for (auto& e : list)
{
insert(e);
}
}
iterator find(const Key& key)
{
return iterator(_find(key), _table);
}
const_iterator find(const Key& key) const
{
return const_iterator(_find(key), _table);
}
iterator erase(const_iterator position)
{
--_size;
const_iterator const_next = position;
++const_next;
iterator next = { const_next._point_node, _table };
Hash_mapping index = _hashFunc(_getKey(*position)) % _table.size();
if (_table[index] == position._point_node) // 是头节点删除返回
{
_table[index] = position._point_node->_next;
delete position._point_node;
position._point_node = nullptr; // 删除后迭代器失效
return next;
}
pNode prev = _table[index]; // 其他节点需要遍历哈希桶
pNode cur = prev->_next;
while (cur != nullptr)
{
if (cur == position._point_node)
{
prev->_next = cur->_next;
delete cur;
cur = prev->_next;
break;
}
else
{
prev = cur;
cur = cur->_next;
}
}
position._point_node = nullptr; // 删除后迭代器失效
return next;
}
size_t erase(const Key& key)
{
if (_size == 0)
{
return 0;
}
size_t before = _size; // 删除前的个数
// 兼容 multi 删除
Hash_mapping index = _hashFunc(key) % _table.size();
while (_table[index] != nullptr && _equal_to(_getKey(_table[index]->_data), key))
{ // 数据有可能连续堆积在头节点,使用循环
pNode temp = _table[index];
_table[index] = _table[index]->_next;
delete temp;
--_size;
}
if (_table[index] == nullptr)
{
return before - _size;
}
pNode prev = _table[index];
pNode cur = prev->_next;
while (cur != nullptr)
{
if (_equal_to(_getKey(cur->_data), key))
{
prev->_next = cur->_next;
delete cur;
cur = prev->_next;
--_size;
}
else
{
prev = cur;
cur = cur->_next;
}
}
return before - _size;
}
iterator erase(const_iterator begin, const_iterator end)
{
while (begin != end)
{
const_iterator temp = begin;
++begin;
erase(temp);
}
return iterator(end._point_node, _table);
}
size_t size() const
{
return _size;
}
size_t max_size() const
{
return max_bucket_count() * _set_load_factor;
}
void clear()
{
for (pNode& head : _table) // 遍历哈希表
{
if (head == nullptr)
{
continue;
}
pNode cur = head; // 检查是否有资源
while (cur != nullptr)
{
pNode temp = cur;
cur = cur->_next;
delete temp; // 释放
}
head = nullptr; // 指针置空
}
_size = 0;
}
size_t count(const Key& key) const
{
Hash_mapping index = _hashFunc(key) % _table.size();
pNode cur = _table[index];
size_t count = 0;
while (cur != nullptr) // 统计相同 key 个数
{
if (_equal_to(_getKey(cur->_data), key))
{
++count;
}
cur = cur->_next;
}
return count;
}
std::pair<iterator, iterator> equal_range(const Key& key)
{
std::pair<pNode, pNode> double_it = _equal_rand(key);
return { iterator(double_it.first, _table), iterator(double_it.second, _table) };
}
std::pair<const_iterator, const_iterator> equal_range(const Key& key) const
{
std::pair<pNode, pNode> double_it = _equal_rand(key);
return { const_iterator(double_it.first, _table), const_iterator(double_it.second, _table) };
}
public:
size_t bucket_count() const
{
return _table.size();
}
size_t bucket(const Key& key) const
{
return _hashFunc(key);
}
size_t max_bucket_count() const
{
return 4294967291; // 这里存的最大质数是它,那就只能记录这么多个哈希桶
}
size_t bucket_size(Hash_mapping index) const
{
assert(index < _table.size());
size_t count = 0;
for (pNode cur = _table[index]; cur != nullptr; cur = cur->_next)
{
++count;
}
return count;
}
public:
float load_factor() const
{
return 1.0f * _size / _table.size();
}
float max_load_factor() const
{
return _set_load_factor;
}
void max_load_factor(float num)
{
_set_load_factor = num;
}
void reserve(size_t num)
{
if (num <= _table.size() * _set_load_factor)
{
return;
}
capacityExpansion(num);
}
void rehash(size_t num)
{
if (num <= _table.size())
{
return;
}
capacityExpansion(num);
}
};
template<class Key>
struct defaultHashFunc
{
Hash_mapping operator()(const Key& key) const
{
return key;
}
};
template<>
struct defaultHashFunc<std::string>
{
Hash_mapping operator()(const std::string& key) const
{
Hash_mapping the_map = 0;
for (char ch : key)
{
the_map += ch;
the_map *= 131;
}
return the_map;
}
};
template<class Key>
struct defaultEqualTo
{
bool operator()(const Key& key1, const Key& key2) const
{
return key1 == key2;
}
};
struct IsMultiInsertSolve
{
template<class pNode, class Key, class GetKey, class EqualTo>
bool operator()(pNode cur, const Key& key, const GetKey& _getKey, const EqualTo& _equalt_to) const
{
return true; // 允许 Multi,则一直插入成功
}
};
struct NoMultiInsertSolve
{
template<class pNode, class Key, class GetKey, class EqualTo>
bool operator()(pNode cur, const Key& key, const GetKey& _getKey, const EqualTo& _equal_to) const
{
while (cur != nullptr) // 检查重复值,有则插入失败
{
if (_equal_to(_getKey(cur->_data), key))
{
return false;
}
cur = cur->_next;
}
return true;
}
};
}
unordered_set 与 unordered_multiset
在 unordered_set.hpp 中:
#pragma once
#include "HashTable.hpp"
namespace my
{
template<class Key, class HashFunc, class EqualTo, class MultiInsertSolve>
class unordered_set_base
{
protected:
typedef const Key ConstKeyType; // const key
struct GetSetKey
{
const Key& operator()(const ConstKeyType& data) const
{
return data;
}
};
typedef HashTable_base<ConstKeyType, Key, GetSetKey, HashFunc, EqualTo, MultiInsertSolve> HashTable_base;
HashTable_base _hashTable;
public:
unordered_set_base() = default;
template<class InputIterator>
unordered_set_base(InputIterator begin, InputIterator end)
:_hashTable(begin, end)
{
;
}
unordered_set_base(std::initializer_list<ConstKeyType> list)
:_hashTable(list)
{
;
}
public:
typedef typename HashTable_base::iterator iterator;
typedef typename HashTable_base::const_iterator const_iterator;
typedef typename HashTable_base::local_iterator local_iterator;
typedef typename HashTable_base::const_local_iterator const_local_iterator;
iterator begin()
{
return _hashTable.begin();
}
const_iterator begin() const
{
return _hashTable.begin();
}
const_iterator cbegin() const
{
return _hashTable.cbegin();
}
iterator end()
{
return _hashTable.end();
}
const_iterator end() const
{
return _hashTable.end();
}
const_iterator cend() const
{
return _hashTable.cend();
}
local_iterator begin(size_t index)
{
return _hashTable.begin(index);
}
local_iterator end(size_t index)
{
return _hashTable.end(index);
}
const_local_iterator begin(size_t index) const
{
return _hashTable.begin(index);
}
const_local_iterator end(size_t index) const
{
return _hashTable.end(index);
}
const_local_iterator cbegin(size_t index) const
{
return _hashTable.cbegin(index);
}
const_local_iterator cend(size_t index) const
{
return _hashTable.cend(index);
}
public:
template<class InputIterator>
void insert(InputIterator begin, InputIterator end)
{
_hashTable.insert(begin, end);
}
void insert(std::initializer_list<ConstKeyType> list)
{
_hashTable.insert(list);
}
size_t erase(const Key& key)
{
return _hashTable.erase(key);
}
iterator erase(const_iterator position)
{
return _hashTable.erase(position);
}
iterator erase(const_iterator begin, const_iterator end)
{
return _hashTable.erase(begin, end);
}
iterator find(const Key& key)
{
return _hashTable.find(key);
}
const_iterator find(const Key& key) const
{
return _hashTable.find(key);
}
size_t size() const
{
return _hashTable.size();
}
size_t max_size() const
{
return _hashTable.max_size();
}
void clear()
{
_hashTable.clear();
}
bool empty() const
{
return size() == 0;
}
void swap(unordered_set_base& one)
{
std::swap(_hashTable, one._hashTable);
}
size_t count(const Key& key) const
{
return _hashTable.count();
}
public:
size_t bucket_count() const
{
return _hashTable.bucket_count();
}
size_t bucket(const Key& key) const
{
return _hashTable.bucket(key);
}
size_t max_bucket_count() const
{
return _hashTable.max_bucket_count();
}
size_t bucket_size(Hash_mapping index) const
{
return _hashTable.bucket_size(index);
}
public:
float load_factor() const
{
return _hashTable.load_factor();
}
float max_load_factor() const
{
return _hashTable.max_load_factor();
}
void max_load_factor(float num)
{
_hashTable.max_load_factor(num);
}
void reserve(size_t num)
{
_hashTable.reserve(num);
}
void rehash(size_t num)
{
_hashTable.rehash(num);
}
};
template<class Key, class HashFunc = defaultHashFunc<Key>, class EqualTo = defaultEqualTo<Key>>
class unordered_set : public unordered_set_base<Key, HashFunc, EqualTo, NoMultiInsertSolve>
{ // 非 multi
typedef unordered_set_base<Key, HashFunc, EqualTo, NoMultiInsertSolve> unordered_set_base;
typedef const Key ConstKeyType;
public:
typedef typename unordered_set_base::iterator iterator;
unordered_set() = default;
template<class InputIterator>
unordered_set(InputIterator begin, InputIterator end)
:unordered_set_base(begin, end)
{
;
}
unordered_set(std::initializer_list<ConstKeyType> list)
:unordered_set_base(list)
{
;
}
std::pair<iterator, bool> insert(const ConstKeyType& data)
{
return this->_hashTable.insert(data);
}
};
template<class Key, class HashFunc = defaultHashFunc<Key>, class EqualTo = defaultEqualTo<Key>>
class unordered_multiset : public unordered_set_base<Key, HashFunc, EqualTo, IsMultiInsertSolve>
{ // multi
typedef unordered_set_base<Key, HashFunc, EqualTo, IsMultiInsertSolve> unordered_set_base;
typedef const Key ConstKeyType;
public:
typedef typename unordered_set_base::iterator iterator;
unordered_multiset() = default;
template<class InputIterator>
unordered_multiset(InputIterator begin, InputIterator end)
:unordered_set_base(begin, end)
{
;
}
unordered_multiset(std::initializer_list<ConstKeyType> list)
:unordered_set_base(list)
{
;
}
iterator insert(const ConstKeyType& data)
{
auto get = this->_hashTable.insert(data);
return get.first;
}
};
}
unordered_map 与 unordered_multimap
在 unordered_map.hpp 中:
#pragma once
#include "HashTable.hpp"
namespace my
{
template<class Key, class Value, class HashFunc, class EqualTo, class MultiInsertSolve>
class unordered_map_base
{
protected:
typedef std::pair<const Key, Value> ConstKeyType; // pair<const Key, Value>
struct GetMapKey
{
const Key& operator()(const ConstKeyType& data) const
{
return data.first;
}
};
typedef HashTable_base<ConstKeyType, Key, GetMapKey, HashFunc, EqualTo, MultiInsertSolve> HashTable_base;
HashTable_base _hashTable;
public:
unordered_map_base() = default;
template<class InputIterator>
unordered_map_base(InputIterator begin, InputIterator end)
:_hashTable(begin, end)
{
;
}
unordered_map_base(std::initializer_list<ConstKeyType> list)
:_hashTable(list)
{
;
}
public:
typedef typename HashTable_base::iterator iterator;
typedef typename HashTable_base::const_iterator const_iterator;
typedef typename HashTable_base::local_iterator local_iterator;
typedef typename HashTable_base::const_local_iterator const_local_iterator;
iterator begin()
{
return _hashTable.begin();
}
const_iterator begin() const
{
return _hashTable.begin();
}
const_iterator cbegin() const
{
return _hashTable.cbegin();
}
iterator end()
{
return _hashTable.end();
}
const_iterator end() const
{
return _hashTable.end();
}
const_iterator cend() const
{
return _hashTable.cend();
}
local_iterator begin(size_t index)
{
return _hashTable.begin(index);
}
local_iterator end(size_t index)
{
return _hashTable.end(index);
}
const_local_iterator begin(size_t index) const
{
return _hashTable.begin(index);
}
const_local_iterator end(size_t index) const
{
return _hashTable.end(index);
}
const_local_iterator cbegin(size_t index) const
{
return _hashTable.cbegin(index);
}
const_local_iterator cend(size_t index) const
{
return _hashTable.cend(index);
}
public:
template<class InputIterator>
void insert(InputIterator begin, InputIterator end)
{
_hashTable.insert(begin, end);
}
void insert(std::initializer_list<ConstKeyType> list)
{
_hashTable.insert(list);
}
size_t erase(const Key& key)
{
return _hashTable.erase(key);
}
iterator erase(const_iterator position)
{
return _hashTable.erase(position);
}
iterator erase(const_iterator begin, const_iterator end)
{
return _hashTable.erase(begin, end);
}
iterator find(const Key& key)
{
return _hashTable.find(key);
}
const_iterator find(const Key& key) const
{
return _hashTable.find(key);
}
size_t size() const
{
return _hashTable.size();
}
size_t max_size() const
{
return _hashTable.max_size();
}
void clear()
{
_hashTable.clear();
}
bool empty() const
{
return size() == 0;
}
void swap(unordered_map_base& one)
{
std::swap(_hashTable, one._hashTable);
}
size_t count(const Key& key) const
{
return _hashTable.count();
}
public:
size_t bucket_count() const
{
return _hashTable.bucket_count();
}
size_t bucket(const Key& key) const
{
return _hashTable.bucket(key);
}
size_t max_bucket_count() const
{
return _hashTable.max_bucket_count();
}
size_t bucket_size(Hash_mapping index) const
{
return _hashTable.bucket_size(index);
}
public:
float load_factor() const
{
return _hashTable.load_factor();
}
float max_load_factor() const
{
return _hashTable.max_load_factor();
}
void max_load_factor(float num)
{
_hashTable.max_load_factor(num);
}
void reserve(size_t num)
{
_hashTable.reserve(num);
}
void rehash(size_t num)
{
_hashTable.rehash(num);
}
};
template<class Key, class Value, class HashFunc = defaultHashFunc<Key>, class EqualTo = defaultEqualTo<Key>>
class unordered_map : public unordered_map_base<Key, Value, HashFunc, EqualTo, NoMultiInsertSolve>
{ // 非 multi
typedef unordered_map_base<Key, Value, HashFunc, EqualTo, NoMultiInsertSolve> unordered_map_base;
typedef std::pair<const Key, Value> ConstKeyType;
public:
typedef typename unordered_map_base::iterator iterator;
unordered_map() = default;
template<class InputIterator>
unordered_map(InputIterator begin, InputIterator end)
:unordered_map_base(begin, end)
{
}
unordered_map(std::initializer_list<ConstKeyType> list)
:unordered_map_base(list)
{
}
public:
Value& operator[](const Key& key)
{
auto get = insert({ key, Value() }); // 插入失败会返回已有的迭代器
return get.first->second;
}
std::pair<iterator, bool> insert(const ConstKeyType& data)
{
return this->_hashTable.insert(data);
}
};
template<class Key, class Value, class HashFunc = defaultHashFunc<Key>, class EqualTo = defaultEqualTo<Key>>
class unordered_multimap : public unordered_map_base<Key, Value, HashFunc, EqualTo, IsMultiInsertSolve>
{ // multi
typedef unordered_map_base<Key, Value, HashFunc, EqualTo, IsMultiInsertSolve> unordered_map_base;
typedef std::pair<const Key, Value> ConstKeyType;
public:
typedef typename unordered_map_base::iterator iterator;
unordered_multimap() = default;
template<class InputIterator>
unordered_multimap(InputIterator begin, InputIterator end)
:unordered_map_base(begin, end)
{
}
unordered_multimap(std::initializer_list<ConstKeyType> list)
:unordered_map_base(list)
{
}
public:
iterator insert(const ConstKeyType& data)
{
auto get = this->_hashTable.insert(data);
return get.first;
}
};
}
六、准确性测试(VS2022 release)
unordered_set 测试
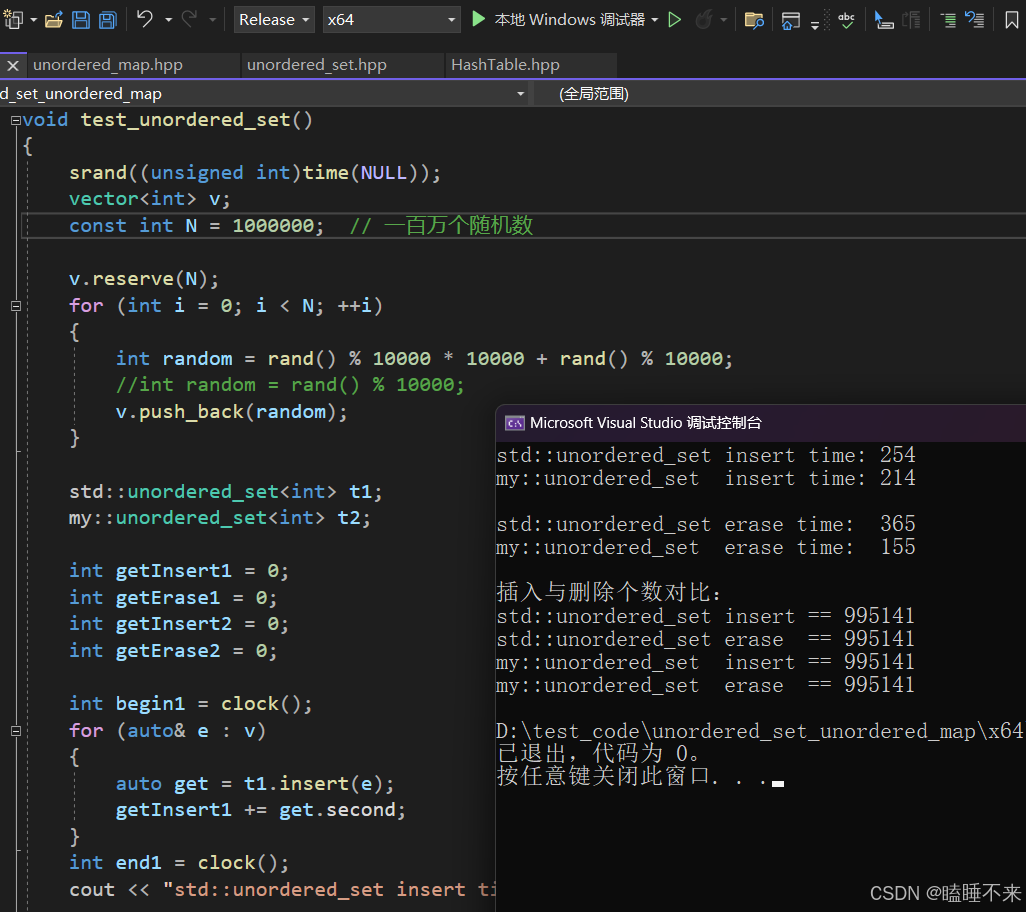
测试源码:
void test_unordered_set()
{
srand((unsigned int)time(NULL));
vector<int> v;
const int N = 1000000; // 一百万个随机数
v.reserve(N);
for (int i = 0; i < N; ++i)
{
int random = rand() % 10000 * 10000 + rand() % 10000;
//int random = rand() % 10000;
v.push_back(random);
}
std::unordered_set<int> t1;
my::unordered_set<int> t2;
int getInsert1 = 0;
int getErase1 = 0;
int getInsert2 = 0;
int getErase2 = 0;
int begin1 = clock();
for (auto& e : v)
{
auto get = t1.insert(e);
getInsert1 += get.second;
}
int end1 = clock();
cout << "std::unordered_set insert time: " << end1 - begin1 << endl;
int begin3 = clock();
for (auto& e : v)
{
auto get = t2.insert(e);
getInsert2 += get.second;
}
int end3 = clock();
cout << "my::unordered_set insert time: " << end3 - begin3 << endl << endl;
int begin2 = clock();
for (auto& e : v)
{
auto get = t1.erase(e);
getErase1 += get;
}
int end2 = clock();
cout << "std::unordered_set erase time: " << end2 - begin3 << endl;
int begin4 = clock();
for (auto& e : v)
{
auto get = t2.erase(e);
getErase2 += get;
}
int end4 = clock();
cout << "my::unordered_set erase time: " << end4 - begin4 << endl << endl;
cout << "插入与删除个数对比:" << endl;
cout << "std::unordered_set insert == " << getInsert1 << endl;
cout << "std::unordered_set erase == " << getErase1 << endl;
cout << "my::unordered_set insert == " << getInsert2 << endl;
cout << "my::unordered_set erase == " << getErase2 << endl;
}
unordered_multiset 测试
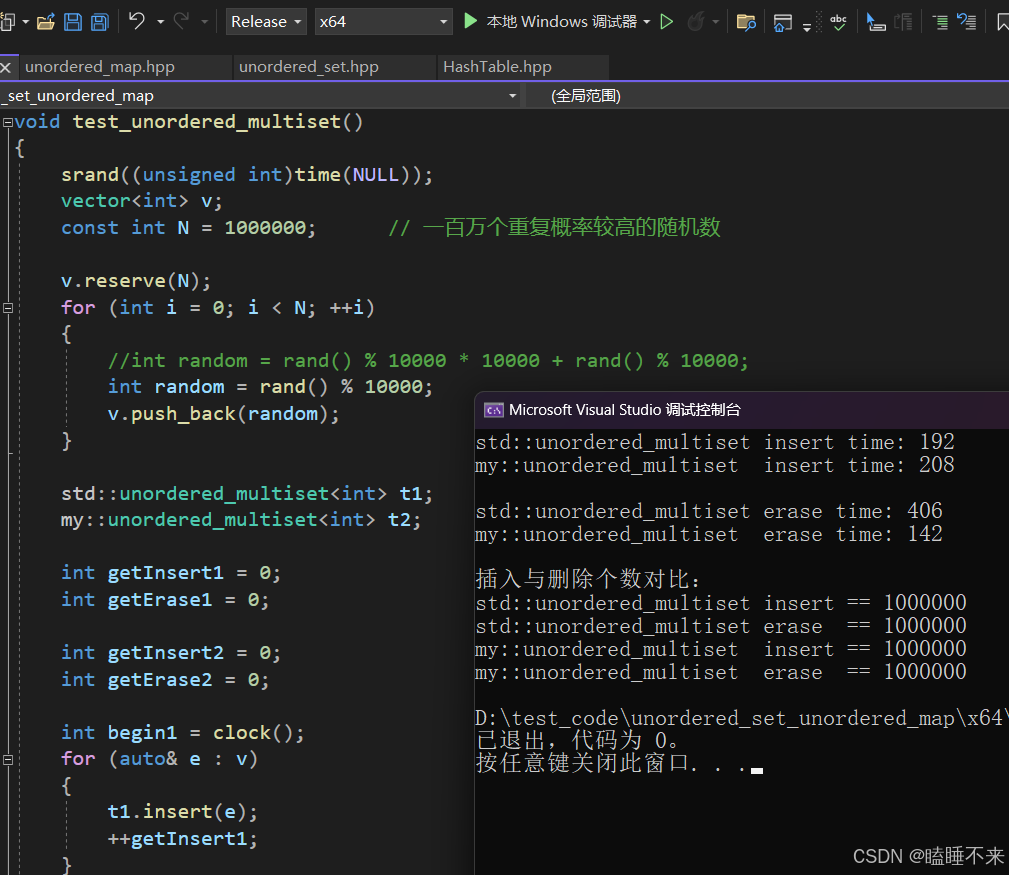
测试源码:
void test_unordered_multiset()
{
srand((unsigned int)time(NULL));
vector<int> v;
const int N = 1000000; // 一百万个重复概率较高的随机数
v.reserve(N);
for (int i = 0; i < N; ++i)
{
//int random = rand() % 10000 * 10000 + rand() % 10000;
int random = rand() % 10000;
v.push_back(random);
}
std::unordered_multiset<int> t1;
my::unordered_multiset<int> t2;
int getInsert1 = 0;
int getErase1 = 0;
int getInsert2 = 0;
int getErase2 = 0;
int begin1 = clock();
for (auto& e : v)
{
t1.insert(e);
++getInsert1;
}
int end1 = clock();
cout << "std::unordered_multiset insert time: " << end1 - begin1 << endl;
int begin3 = clock();
for (auto& e : v)
{
t2.insert(e);
++getInsert2;
}
int end3 = clock();
cout << "my::unordered_multiset insert time: " << end3 - begin3 << endl << endl;
int begin2 = clock();
for (auto& e : v)
{
auto get = t1.erase(e);
getErase1 += get;
}
int end2 = clock();
cout << "std::unordered_multiset erase time: " << end2 - begin3 << endl;
int begin4 = clock();
for (auto& e : v)
{
auto get = t2.erase(e);
getErase2 += get;
}
int end4 = clock();
cout << "my::unordered_multiset erase time: " << end4 - begin4 << endl << endl;
cout << "插入与删除个数对比:" << endl;
cout << "std::unordered_multiset insert == " << getInsert1 << endl;
cout << "std::unordered_multiset erase == " << getErase1 << endl;
cout << "my::unordered_multiset insert == " << getInsert2 << endl;
cout << "my::unordered_multiset erase == " << getErase2 << endl;
}
unordered_map 测试
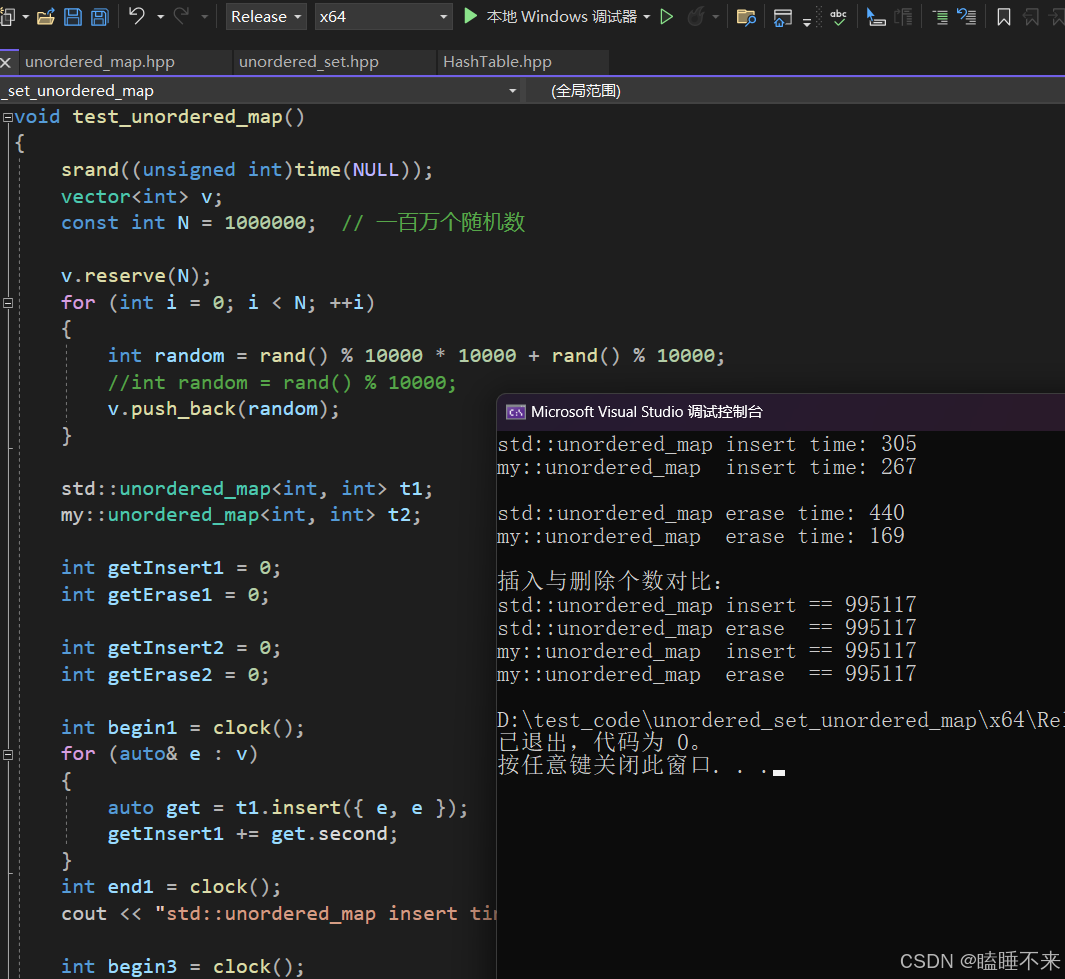
测试源码:
void test_unordered_map()
{
srand((unsigned int)time(NULL));
vector<int> v;
const int N = 1000000; // 一百万个随机数
v.reserve(N);
for (int i = 0; i < N; ++i)
{
int random = rand() % 10000 * 10000 + rand() % 10000;
//int random = rand() % 10000;
v.push_back(random);
}
std::unordered_map<int, int> t1;
my::unordered_map<int, int> t2;
int getInsert1 = 0;
int getErase1 = 0;
int getInsert2 = 0;
int getErase2 = 0;
int begin1 = clock();
for (auto& e : v)
{
auto get = t1.insert({ e, e });
getInsert1 += get.second;
}
int end1 = clock();
cout << "std::unordered_map insert time: " << end1 - begin1 << endl;
int begin3 = clock();
for (auto& e : v)
{
auto get = t2.insert({ e, e });
getInsert2 += get.second;
}
int end3 = clock();
cout << "my::unordered_map insert time: " << end3 - begin3 << endl << endl;
int begin2 = clock();
for (auto& e : v)
{
auto get = t1.erase(e);
getErase1 += get;
}
int end2 = clock();
cout << "std::unordered_map erase time: " << end2 - begin3 << endl;
int begin4 = clock();
for (auto& e : v)
{
auto get = t2.erase(e);
getErase2 += get;
}
int end4 = clock();
cout << "my::unordered_map erase time: " << end4 - begin4 << endl << endl;
cout << "插入与删除个数对比:" << endl;
cout << "std::unordered_map insert == " << getInsert1 << endl;
cout << "std::unordered_map erase == " << getErase1 << endl;
cout << "my::unordered_map insert == " << getInsert2 << endl;
cout << "my::unordered_map erase == " << getErase2 << endl;
}
unordered_multimap 测试
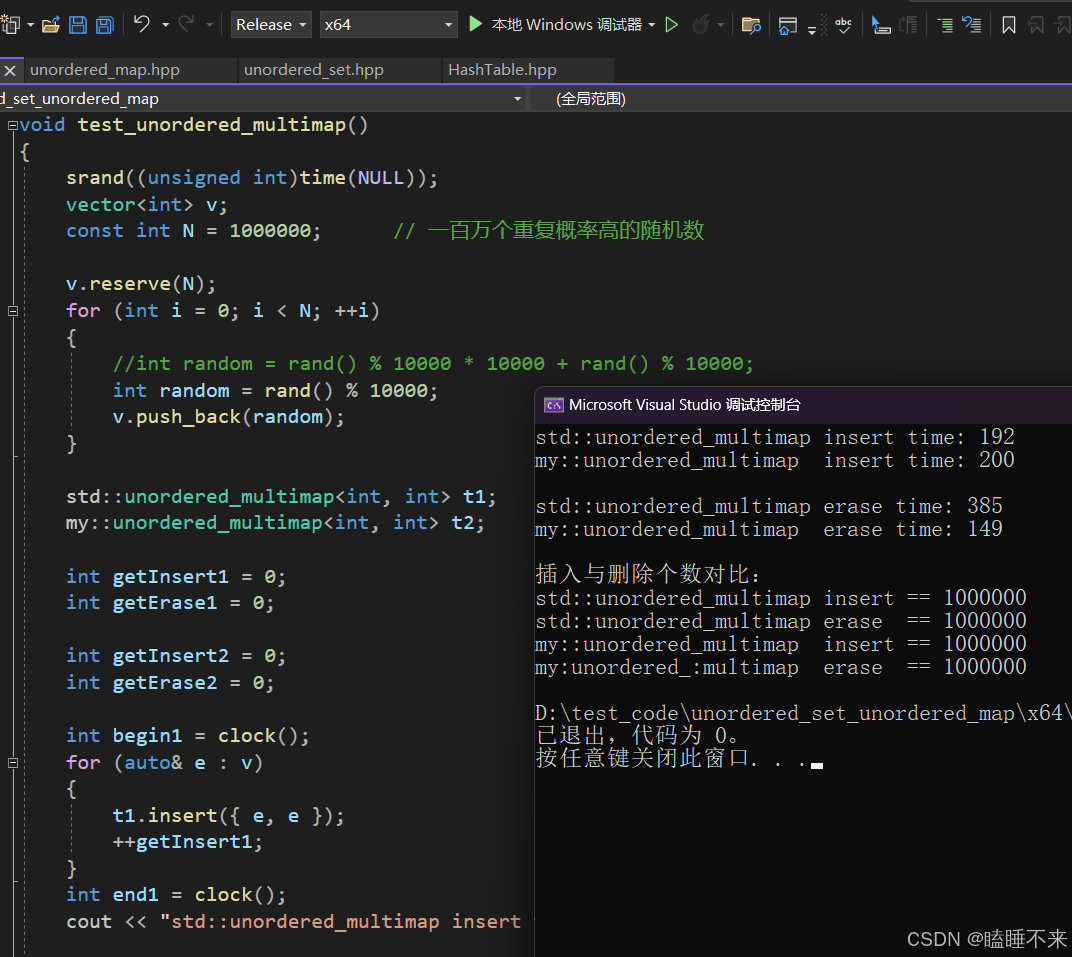
测试源码:
void test_unordered_multimap()
{
srand((unsigned int)time(NULL));
vector<int> v;
const int N = 1000000; // 一百万个重复概率高的随机数
v.reserve(N);
for (int i = 0; i < N; ++i)
{
//int random = rand() % 10000 * 10000 + rand() % 10000;
int random = rand() % 10000;
v.push_back(random);
}
std::unordered_multimap<int, int> t1;
my::unordered_multimap<int, int> t2;
int getInsert1 = 0;
int getErase1 = 0;
int getInsert2 = 0;
int getErase2 = 0;
int begin1 = clock();
for (auto& e : v)
{
t1.insert({ e, e });
++getInsert1;
}
int end1 = clock();
cout << "std::unordered_multimap insert time: " << end1 - begin1 << endl;
int begin3 = clock();
for (auto& e : v)
{
t2.insert({ e, e });
++getInsert2;
}
int end3 = clock();
cout << "my::unordered_multimap insert time: " << end3 - begin3 << endl << endl;
int begin2 = clock();
for (auto& e : v)
{
auto get = t1.erase(e);
getErase1 += get;
}
int end2 = clock();
cout << "std::unordered_multimap erase time: " << end2 - begin3 << endl;
int begin4 = clock();
for (auto& e : v)
{
auto get = t2.erase(e);
getErase2 += get;
}
int end4 = clock();
cout << "my::unordered_multimap erase time: " << end4 - begin4 << endl << endl;
cout << "插入与删除个数对比:" << endl;
cout << "std::unordered_multimap insert == " << getInsert1 << endl;
cout << "std::unordered_multimap erase == " << getErase1 << endl;
cout << "my::unordered_multimap insert == " << getInsert2 << endl;
cout << "my:unordered_:multimap erase == " << getErase2 << endl;
}
multi erase 测试
我们测试 multi 类 erase 是否能删除多个相同 key 的元素,这里以 unordered_multimap 为例:
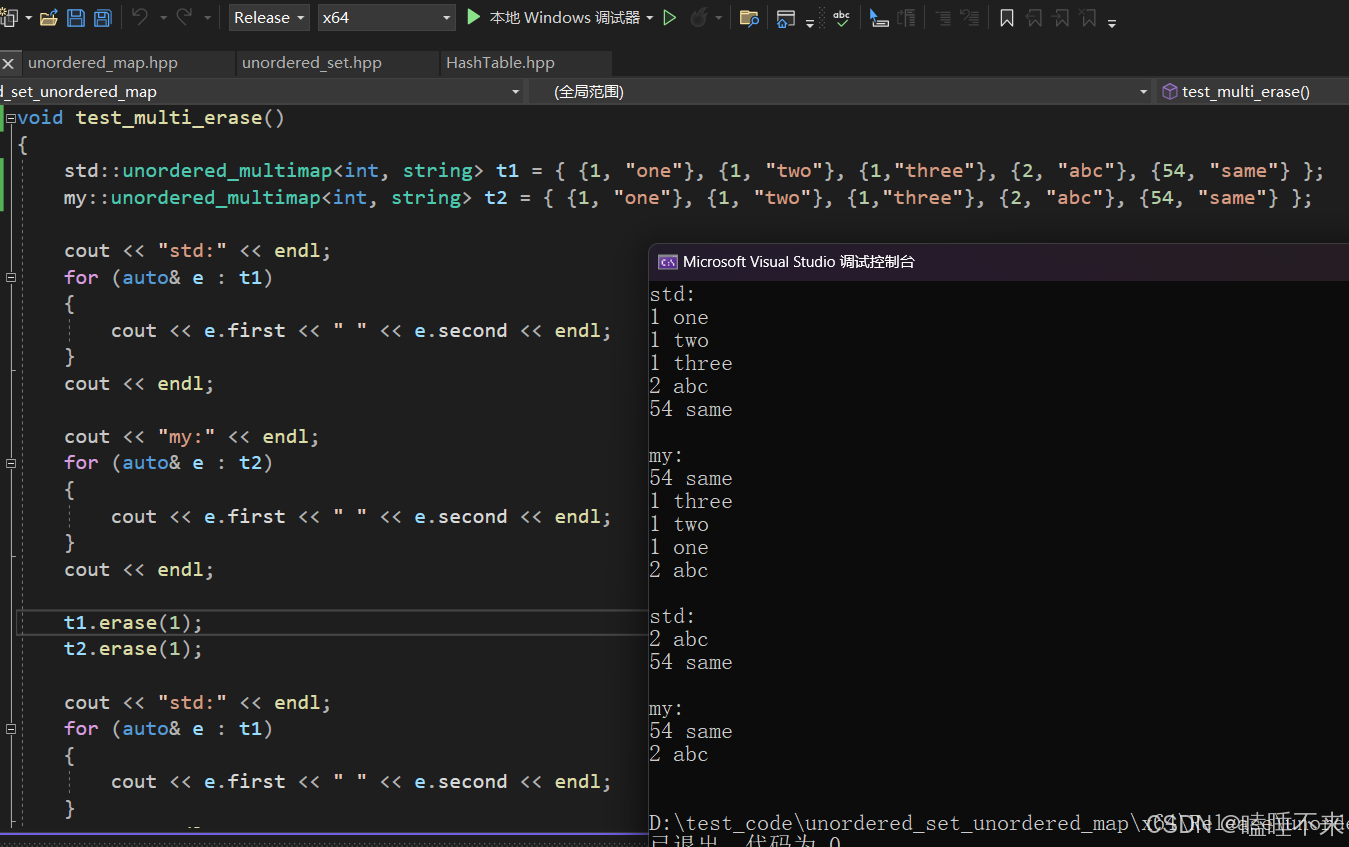
测试源码:
void test_multi_erase()
{
std::unordered_multimap<int, string> t1 = { {1, "one"}, {1, "two"}, {1,"three"}, {2, "abc"}, {54, "same"} };
my::unordered_multimap<int, string> t2 = { {1, "one"}, {1, "two"}, {1,"three"}, {2, "abc"}, {54, "same"} };
cout << "std:" << endl;
for (auto& e : t1)
{
cout << e.first << " " << e.second << endl;
}
cout << endl;
cout << "my:" << endl;
for (auto& e : t2)
{
cout << e.first << " " << e.second << endl;
}
cout << endl;
t1.erase(1);
t2.erase(1);
cout << "std:" << endl;
for (auto& e : t1)
{
cout << e.first << " " << e.second << endl;
}
cout << endl;
cout << "my:" << endl;
for (auto& e : t2)
{
cout << e.first << " " << e.second << endl;
}
cout << endl;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









