







一、 实验目标
- 加强对Cache工作原理的理解;
- 体验程序中访存模式变化是如何影响cahce效率进而影响程序性能的过程;
- 学习在X86真实机器上通过调整程序访存模式来探测多级cache结构以及TLB的大小。
二、实验环境
X86真实机器
三、实验内容与步骤
1、分析Cache访存模式对系统性能的影响
-
- 给出一个矩阵乘法的普通代码A,设法优化该代码,从而提高性能。
- 改变矩阵大小,记录相关数据,并分析原因。
2、编写代码来测量x86机器上(非虚拟机)的Cache 层次结构和容量
- 设计一个方案,用于测量x86机器上的Cache层次结构,并设计出相应的代码;
- 运行你的代码获得相应的测试数据;
- 根据测试数据来详细分析你所用的x86机器有几级Cache,各自容量是多大?
- 根据测试数据来详细分析L1 Cache行有多少?
4、选做:尝试测量你的x86机器TLB有多大?
代码A:
#include <sys/time.h>
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char *argv[])
{
float *a,*b,*c, temp;
long int i, j, k, size, m;
struct timeval time1,time2;
if(argc<2) {
printf("\n\tUsage:%s <Row of square matrix>\n",argv[0]);
exit(-1);
} //if
size = atoi(argv[1]);
m = size*size;
a = (float*)malloc(sizeof(float)*m);
b = (float*)malloc(sizeof(float)*m);
c = (float*)malloc(sizeof(float)*m);
for(i=0;i<size;i++) {
for(j=0;j<size;j++) {
a[i*size+j] = (float)(rand()%1000/100.0);
b[i*size+j] = (float)(rand()%1000/100.0);
}
}
gettimeofday(&time1,NULL);
for(i=0;i<size;i++) {
for(j=0;j<size;j++) {
c[i*size+j] = 0;
for (k=0;k<size;k++)
c[i*size+j] += a[i*size+k]*b[k*size+j];
}
}
gettimeofday(&time2,NULL);
time2.tv_sec-=time1.tv_sec;
time2.tv_usec-=time1.tv_usec;
if (time2.tv_usec<0L) {
time2.tv_usec+=1000000L;
time2.tv_sec-=1;
}
printf("Executiontime=%ld.%06ld seconds\n",time2.tv_sec,time2.tv_usec);
return(0);
}//main
四、实验结果及分析
1、分析Cache访存模式对系统性能的影响
表1、普通矩阵乘法与及优化后矩阵乘法之间的性能对比
| 矩阵大小 | 100 | 500 | 1000 | 1500 | 2000 | 2500 | 3000 |
| 一般算法执行时间 | 0.003441 | 0.376243 | 3.040972 | 11.365134 | 28.187060 | 66.850033 | 110.220587 |
| 优化算法执行时间 | 0.003226 | 0.341660 | 2.729945 | 9.148617 | 21.719988 | 42.329491 | 73.006282 |
| 加速比 speedup | 1.066646 | 1.101220 | 1.113932 | 1.242279 | 1.297747 | 1.579278 | 1.509741 |
加速比定义:加速比=优化前系统耗时/优化后系统耗时;
所谓加速比,就是优化前的耗时与优化后耗时的比值。加速比越高,表明优化效果越明显。
分析原因:
由于是在windows上运行程序,因此需要更改一下源代码,修改成如下:
#include <windows.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main(int argc, char* argv[]) {
float* a, * b, * c;
long int i, j, k, size, m;
LARGE_INTEGER frequency, start_time, end_time;
if (argc < 2) {
printf("\n\tUsage:%s <Row of square matrix>\n", argv[0]);
exit(-1);
}
size = atoi(argv[1]);
m = size * size;
a = (float*)malloc(sizeof(float) * m);
b = (float*)malloc(sizeof(float) * m);
c = (float*)malloc(sizeof(float) * m);
srand(time(NULL));
for (i = 0; i < size; i++) {
for (j = 0; j < size; j++) {
a[i * size + j] = (float)(rand() % 1000 / 100.0);
b[i * size + j] = (float)(rand() % 1000 / 100.0);
}
}
QueryPerformanceFrequency(&frequency);
QueryPerformanceCounter(&start_time);
for (i = 0; i < size; i++) {
for (j = 0; j < size; j++) {
c[i * size + j] = 0;
for (k = 0; k < size; k++)
c[i * size + j] += a[i * size + k] * b[k * size + j];
}
}
QueryPerformanceCounter(&end_time);
double elapsed_time = (double)(end_time.QuadPart - start_time.QuadPart) / frequency.QuadPart;
printf("Execution time = %.6f seconds\n", elapsed_time);
free(a);
free(b);
free(c);
return 0;
}运行结果如下
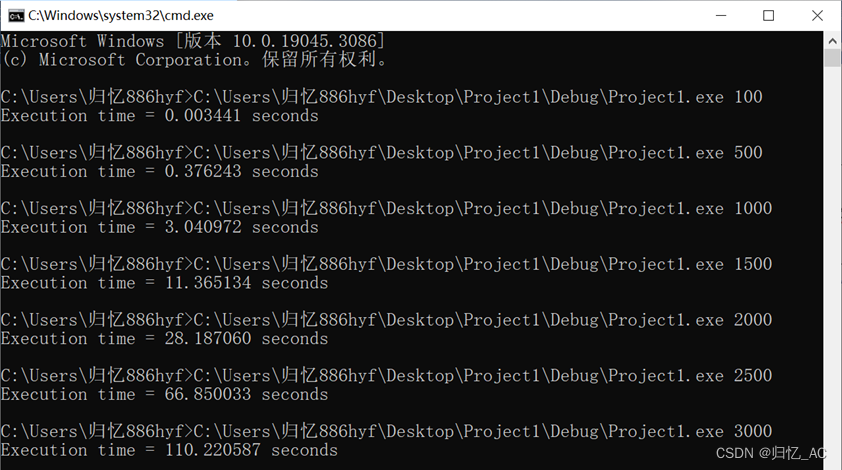
优化代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <omp.h>
#include<time.h>
void matrix_multiply(float* a, float* b, float* c, long int size, long int block_size) {
#pragma omp parallel for
for (long int ii = 0; ii < size; ii += block_size) {
for (long int kk = 0; kk < size; kk += block_size) {
for (long int jj = 0; jj < size; jj += block_size) {
for (long int i = ii; i < ii + block_size; i++) {
for (long int k = kk; k < kk + block_size; k++) {
for (long int j = jj; j < jj + block_size; j++) {
c[i * size + j] += a[i * size + k] * b[k * size + j];
}
}
}
}
}
}
}
int main(int argc, char* argv[]) {
float* a, * b, * c;
long int size, m, block_size;
double start_time, end_time;
if (argc < 3) {
printf("\n\tUsage:%s <Row of square matrix> <Block size>\n", argv[0]);
exit(-1);
}
size = atoi(argv[1]);
block_size = atoi(argv[2]);
m = size * size;
a = (float*)calloc(m, sizeof(float));
b = (float*)calloc(m, sizeof(float));
c = (float*)calloc(m, sizeof(float));
srand(time(NULL));
for (long int i = 0; i < size; i++) {
for (long int j = 0; j < size; j++) {
a[i * size + j] = (float)(rand() % 1000 / 100.0);
b[j * size + i] = (float)(rand() % 1000 / 100.0); // 行列颠倒存取
}
}
start_time = omp_get_wtime();
matrix_multiply(a, b, c, size, block_size);
end_time = omp_get_wtime();
double elapsed_time = end_time - start_time;
printf("Execution time = %.6f seconds\n", elapsed_time);
free(a);
free(b);
free(c);
return 0;
}运行结果如下
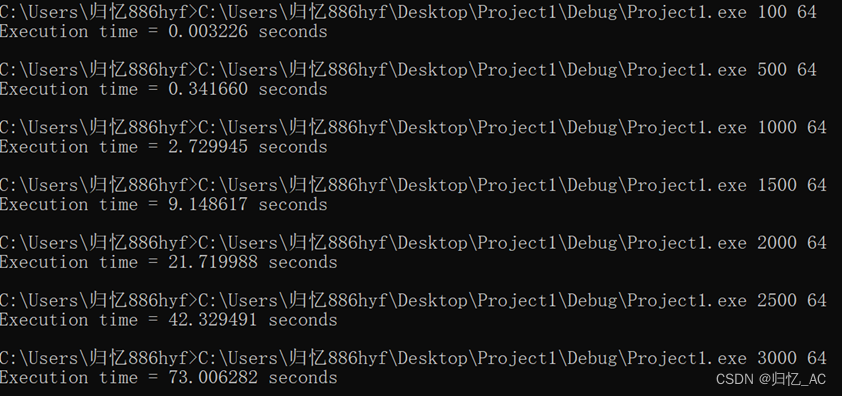
代码采用了循环顺序优化、矩阵分块和并行化策略进行优化,因此速度更快。
1.循环顺序优化:在矩阵相乘的代码中,内层循环的顺序对访存模式和缓存性能有很大的影响。通过调整循环的顺序,使得内层循环访问的数据更加连续,可以提高缓存命中率,减少缓存不命中的次数,从而提高性能。在优化后的代码中,我们将内层循环的顺序进行调整,以使访问矩阵B的数据更加连续。
2.矩阵分块:将大矩阵分割为更小的块,可以提高局部性,减少对主存的访问次数,从而提高Cache的命中率和数据重用,进而提高性能。通过引入块级别的循环,每次只处理一个块的数据,可以充分利用块内数据的局部性。在优化后的代码中,我们使用了矩阵分块的策略,将矩阵相乘过程划分为多个小块的计算,以充分利用局部性。
3.并行化:并行化是通过利用多个处理器核心或线程来同时执行任务,以加速计算过程。在矩阵相乘中,我们可以使用并行化技术,例如OpenMP,将任务分配给多个线程同时进行计算。并行化可以充分利用多核处理器的计算能力,加速矩阵相乘的计算过程。在优化后的代码中,我们使用OpenMP库的指令进行并行化,通过使用#pragma omp parallel for指令,将矩阵相乘的任务分配给多个线程并行执行。
2、测量分析出Cache 的层次结构、容量以及L1 Cache行有多少?
(1)实验原理;
cache分为3层L1、L2、L3,对于每一个层级边界的数据存取会产生较大的速率变化,从而大概得出各层级的cache大小。
(2)测量方案及代码;
使用两种测量方案来分析Cache的层次结构、容量以及L1 Cache行的大小。
测量内存块大小对性能的影响:
1. testCache 函数用于测量不同内存块大小下的运行时间。
首先,根据传入的内存块大小,创建一个对应大小的字符数组 arr。
然后,使用随机数生成器在 0 到 n-1 的范围内产生 100000000 个随机位置,并将这些位置存储在 pos 数组中。
接下来,通过循环遍历 pos 数组,在 arr 数组中取数并进行求和操作。
最后,使用 high_resolution_clock 计时器测量代码执行的时间,并将结果输出。
测量缓存行大小对性能的影响:
2. testCacheLine 函数用于测量不同缓存行大小下的运行时间。
首先,根据传入的缓存行大小,使用循环访问方式遍历字符数组 cache1。
内部循环每次迭代按照缓存行大小进行访问,从数组中取出数据并进行求和操作。
然后,使用 high_resolution_clock 计时器测量代码执行的时间,并将结果输出。
通过这两种测量方案,可以观察到不同内存块大小和缓存行大小对程序性能的影响。当内存块大小接近或等于缓存的容量时,执行时间会显著减少,而当缓存行大小合理时,可以利用局部性原理提高缓存命中率,进一步提高性能。根据实验结果,可以估算出系统的Cache层次结构、容量以及L1 Cache行的大小。
代码如下:
#include <iostream>
#include <random>
#include <vector>
#include <cstring>
#include <chrono>
using namespace std;
using namespace std::chrono;
random_device rd;
mt19937 gen(rd());
vector<int> sizes{ 8,16,32,64,128,256,384,512,768,1024,1536,2048,3072,4096,5120,6144,7168,8192,10240,12288,16384 };
char* cache1;
vector<int> line{ 1,2,4,8,16,32,64,96,128,192,256,512,1024,1536,2048 };
// 测层级,参数为内存块大小(对应cache大小),存于字符数组,随机产生访问位置存于位置数组,若设置的内存块大小刚好是cache大小,cache层级边界时间会有较大改变
void testCache(int size) {
int n = size / sizeof(char); // 获得字符数组大小
char* arr = new char[n]; // 申请对应大小字符数组用于存储同等大小内存块
memset(arr, 1, sizeof(char) * n); // 初始字符数组
uniform_int_distribution<> num(0, n - 1); // 大规模随机数0~n-1
vector<int> pos; // 位置数组
for (int i = 0; i < 100000000; i++)
{
pos.push_back(num(gen)); // 随机产生位置并压入数组
}
int sum = 0; // 由于取数
high_resolution_clock::time_point t1 = high_resolution_clock::now();
for (int i = 0; i < 100000000; i++) {
sum += arr[pos[i]]; // 取数
}
high_resolution_clock::time_point t2 = high_resolution_clock::now();
duration<double> time_span = duration_cast<duration<double>>(t2 - t1);
double dt = time_span.count();
cout << "size=" << (size / 1024) << "KB,time=" << dt << "s" << endl;
delete[]arr;
}
// 测试缓存行大小对性能的影响
void testCacheLine(char* cache1, int line, int size)
{
int n = size / sizeof(char);
int sum = 0;
high_resolution_clock::time_point t1 = high_resolution_clock::now();
for (int j = 0; j < line; j++)
{
for (int i = 0; i < n; i += line)
{
sum += cache1[i];
}
}
high_resolution_clock::time_point t2 = high_resolution_clock::now();
duration<double> time_span = duration_cast<duration<double>>(t2 - t1);
double dt = time_span.count();
cout << "length=" << line << "B time=" << dt << endl;
}
int main() {
for (auto s : sizes)
{
testCache(s * 1024);
}
cache1 = new char[100000000 * 10 / sizeof(char)];
memset(cache1, 1, 100000000 * 10); // 初始字符数组
for (auto l : line)
{
testCacheLine(cache1, l, 100000000);
}
return 0;
}(3)测试结果;
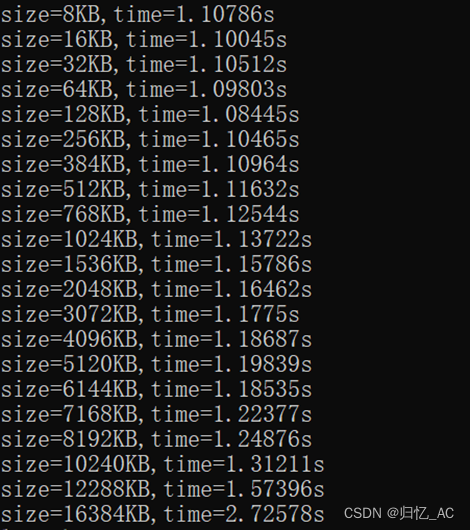
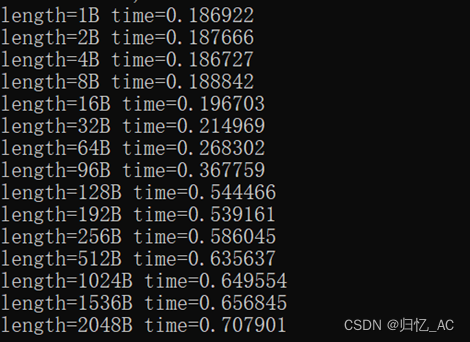
(4)分析过程;
由数据可以看出,384KB-512KB首次出现较大时间增加,所以估计第一级cache大小在384KB-512KB;3072KB-4096KB再次出现较大时间增加,所以估计第二级cache大小在3072KB-4096KB;在16384KB的时间变化较大,就应该是超过第三级cache的区域,所以估计第三级cache在16384KB左右。
cacheline测试里,发现在间隔超过32B长度取数时时间增加较大,所以估计cacheline为32B。
(5)验证实验结果。
结果正确
五、实验结论与心得体会
通过此次实验,加深了对cache的理解,学会了如何对cache进行简单的测量。
(by 归忆)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











