



📌 一、为什么需要经典网络结构?
深度学习网络结构是AI炼丹的“丹方”,直接决定模型性能。经典网络结构经过学术界和工业界验证,具有以下价值:
- 可复现性:代码开源,实验结果可复现(避免“玄学炼丹”)。
- 迁移学习:特征提取能力强,适合迁移到新任务(如用ResNet预训练模型炼制医学图像分类)。
- 工程优化:经过GPU/TPU优化,训练效率高(如GoogleNet的Inception模块减少计算量)。
🎯 一、经典网络结构深度解析
1、LeNet(1998):卷积神经网络的开山鼻祖——炼丹界的“青铜剑”
- 结构特点:
- 7层架构(2卷积层 + 2池化层 + 3全连接层)。
- 输入尺寸:32×32(专为MNIST手写数字设计)。
- 激活函数:Sigmoid(现代网络多用ReLU,毕竟“火候”更猛)。
- 炼丹效果:
- 在MNIST上准确率99%+,但泛化能力弱(换数据集直接“翻车”,比如扔给它一张猫图,它会说:“这是啥?8?”)。
- 适合新手村联手,但别指望它打BOSS。
- 适用场景:
- 简单图像分类(如银行支票数字识别)。
🖼️ 结构示意图:
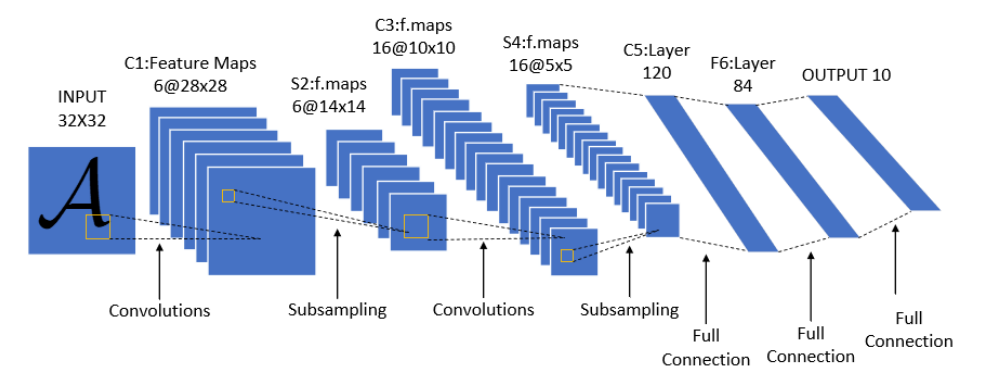
(卷积层→池化层→全连接层,像一把青铜剑,简单但锋利)
🎯 2、AlexNet(2012):深度学习的“第一次工业革命”
- 结构特点:
- 8层架构(5卷积层 + 3全连接层)。
- 输入尺寸:224×224(ImageNet大赛专用)。
- 炼丹秘籍:ReLU激活函数、Dropout防过拟合、双GPU并行训练。
- 炼丹效果:
- 在ImageNet上准确率84.7%,直接碾压传统方法(准确率提升10%,从此GPU成为炼丹标配)。
- 但参数多达6000万,炼一炉丹得等半天(现在ResNet-152都152层了,它还是弟弟)。
- 适用场景:
- 大型图像分类(如ImageNet 1000类)。
、🖼️ 结构示意图:
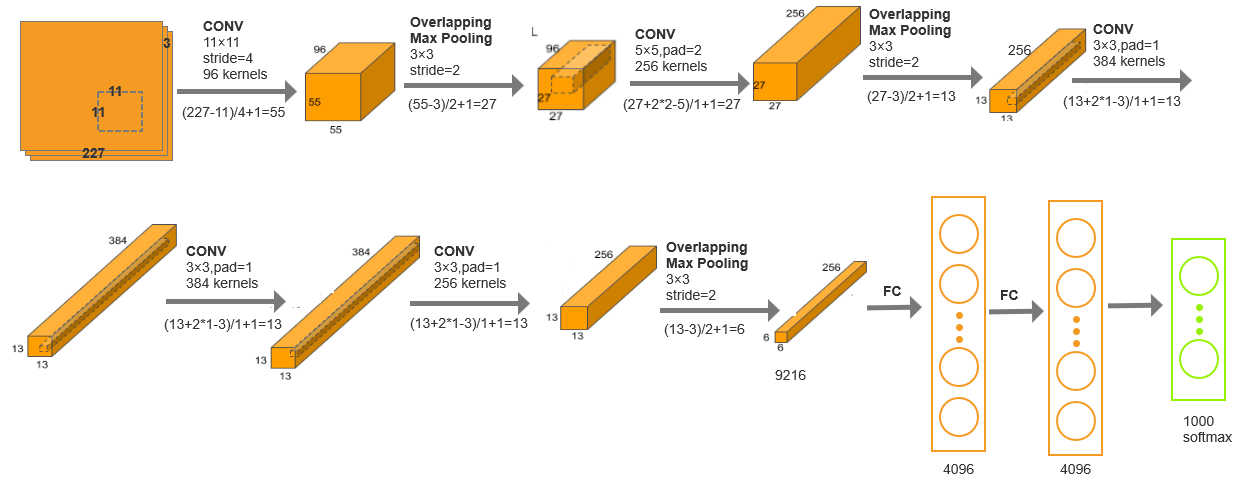
🎯 3、VGGNet(2014):堆料狂魔的暴力美学
- 结构特点:
- 16/19层架构(VGG16/VGG19)。
- 输入尺寸:224×224。
- 炼丹秘籍:3×3小卷积核堆叠(减少参数,增加非线性,相当于用“小铲子”一点点挖特征)。
- 炼丹效果:
- 在ImageNet上准确率92.7%,但参数多达1.38亿(炼一炉丹烧掉一台电脑)。
- 适用场景:
- 特征提取(如迁移到目标检测任务)。
📊 参数对比:
| 网络 | 参数量 | 炼丹时间 |
|---|---|---|
| AlexNet | 6000万 | 🕒 中等 |
| VGGNet | 1.38亿 | 🕒🕒🕒 长 |
🖼️ 结构示意图:
、
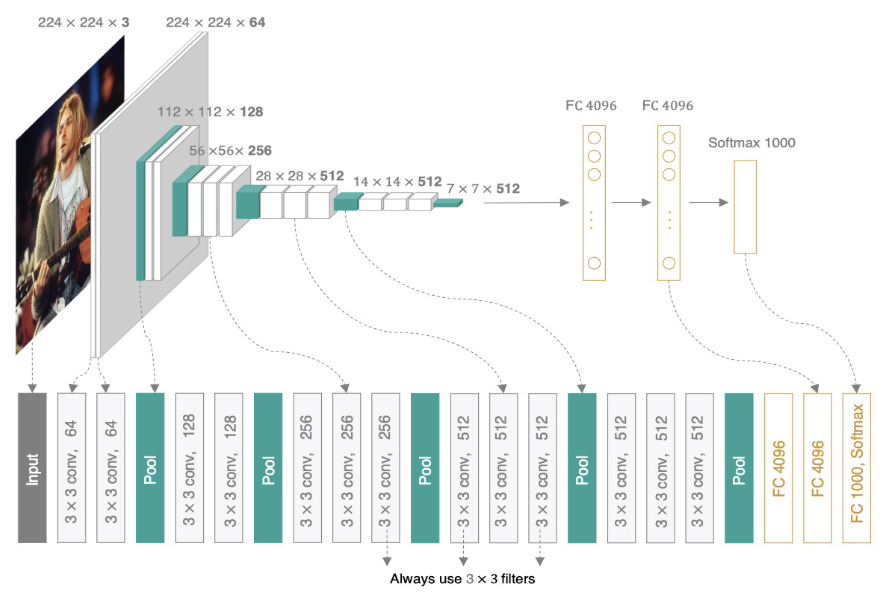
(多层3×3卷积堆叠,像叠罗汉,参数爆炸但效果稳)
🎯 4、GoogleNet(Inception V1,2014):炼丹界的“多核处理器”
- 结构特点:
- 22层架构,Inception模块(并行1×1、3×3、5×5卷积)。
- 炼丹秘籍:1×1卷积降维(减少计算量)。
- 炼丹效果:
- 在ImageNet上准确率93.3%,但参数仅500万(VGGNet的零头)。
- 适用场景:
- 移动端轻量化模型(如手机拍照APP)。
🖼️ Inception模块示意图:
、
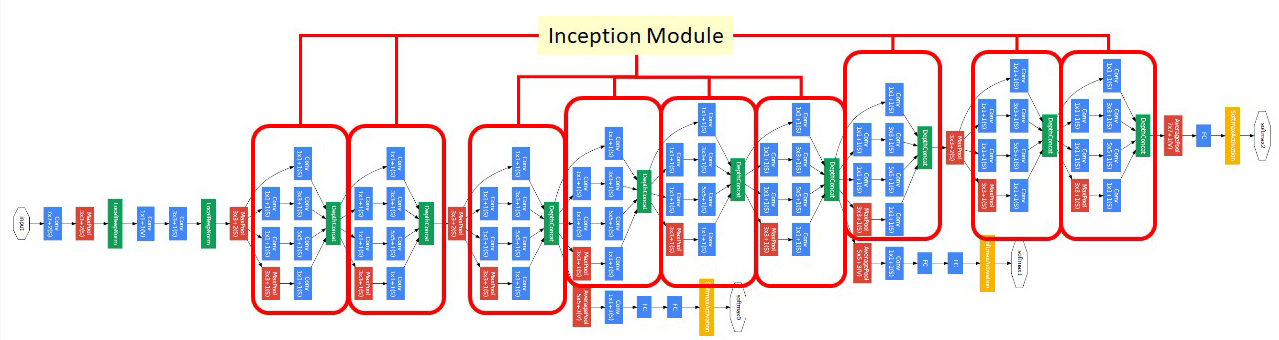
(并行卷积,像多核处理器同时处理任务)
🎯 5、ResNet(2015):炼丹界的“永动机”,解决深层网络退化
- 结构特点:
- 152层架构,残差连接(跳跃连接,防止梯度消失)。
- 炼丹秘籍:BatchNorm(加速收敛)、He初始化(解决深层网络初始化问题)。
- 炼丹效果:
- 在ImageNet上准确率96.4%(人类水平97%,基本追平)。
- 适用场景:
- 全领域任务(分类、检测、分割)。
🔥 残差连接示意图:

(直接跳跃连接,像永动机的循环泵)
🎯 6、Transformer(2017+):NLP的王者跨界图像领域
- 结构特点:
- 自注意力机制(Self-Attention),取代卷积操作。
- 代表模型:ViT(Vision Transformer)、Swin Transformer。
- 炼丹效果:
- 在ImageNet上准确率98%+(超越ResNet)。
- 适用场景:
- 图像分类、目标检测、语义分割(全领域通用)。
💡 类比说明:
- 卷积网络:像“放大镜”,局部扫描图像。
- Transformer:像“全局视野”,一眼看穿整个图像。
📊 三、经典网络结构对比表
| 网络 | 层数 | 参数量 | 创新点 | 适用场景 |
|---|---|---|---|---|
| LeNet | 7 | 6万 | 卷积+池化组合 | 简单图像分类 |
| AlexNet | 8 | 6000万 | ReLU、Dropout、双GPU | 大型图像分类 |
| VGGNet | 16/19 | 1.38亿 | 3×3小卷积堆叠 | 特征提取 |
| GoogleNet | 22 | 500万 | Inception模块、1×1卷积降维 | 移动端轻量化 |
| ResNet | 152 | 6000万 | 残差连接、BatchNorm | 全领域任务 |
| Transformer | - | - | 自注意力机制 | 全领域任务(性能更强) |
🔥 结语:炼丹不息,创新不止!
从LeNet到ResNet,深度学习炼丹术已经从“青铜时代”进化到“外挂时代”。未来,我会继续分享更多炼丹技巧(比如Transformer炼丹术、AutoML自动炼丹),并期待和大家一起炼出更猛的丹!
🔥关联文章 🌟
深度学习数据集探秘:从炼丹到实战的进阶之路(与CNN的奇妙联动)
🔥 炼丹之路,你我同行! 🌟


















 3030
3030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











