






前言
学完python基础,开始入门理论,正好本学期开展有关专业课。希望深入且高效的学习,注入思考,沉浸式探索知识😍
学习资料李宏毅老师-机器学习 & 西瓜书教材
基本概念
机器学习三部
1.确定变量
y为明天数据;x为以前数据;
想得到y=f(x) 最简单的:y=wx+b;
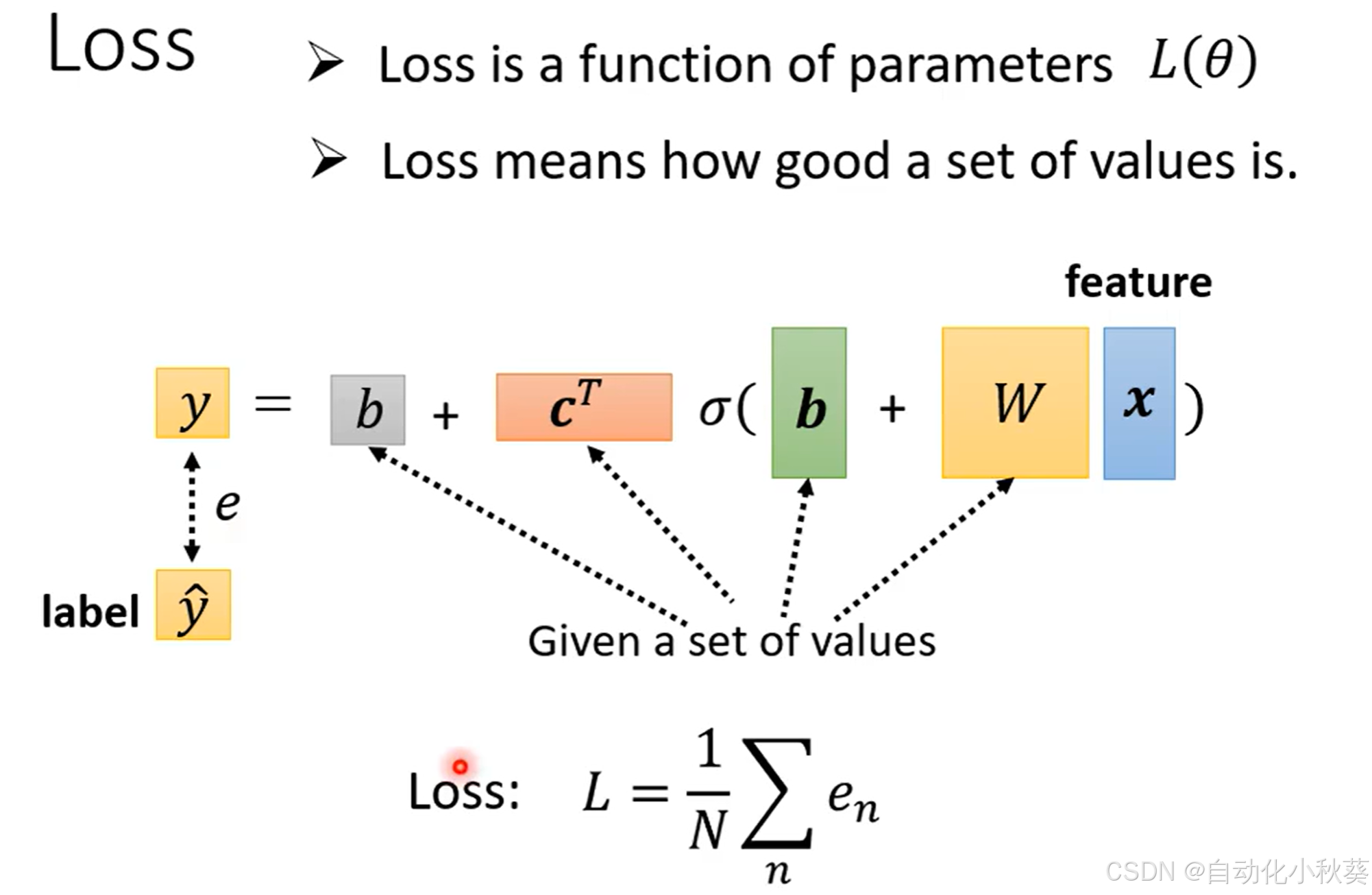
2.定义Loss函数
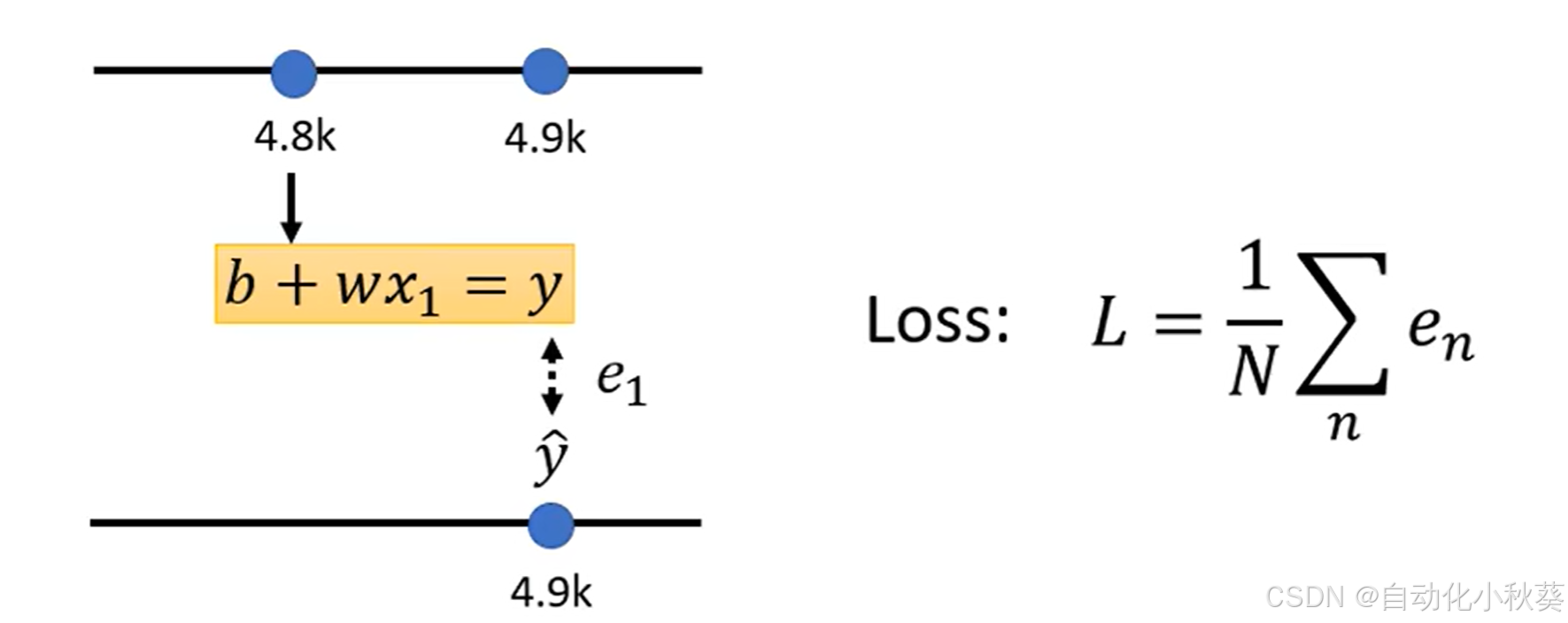
L越小说明预算准确性越高。
3.Optimization 解函数
求解smaller Loss为目的
借助Gradient descent 去寻找最优参数值:先以一个未知数为例
- 随机选取一个
- 对
求偏导数:
我们 知道微分正负代表斜率方向,微分大小代表斜率大小
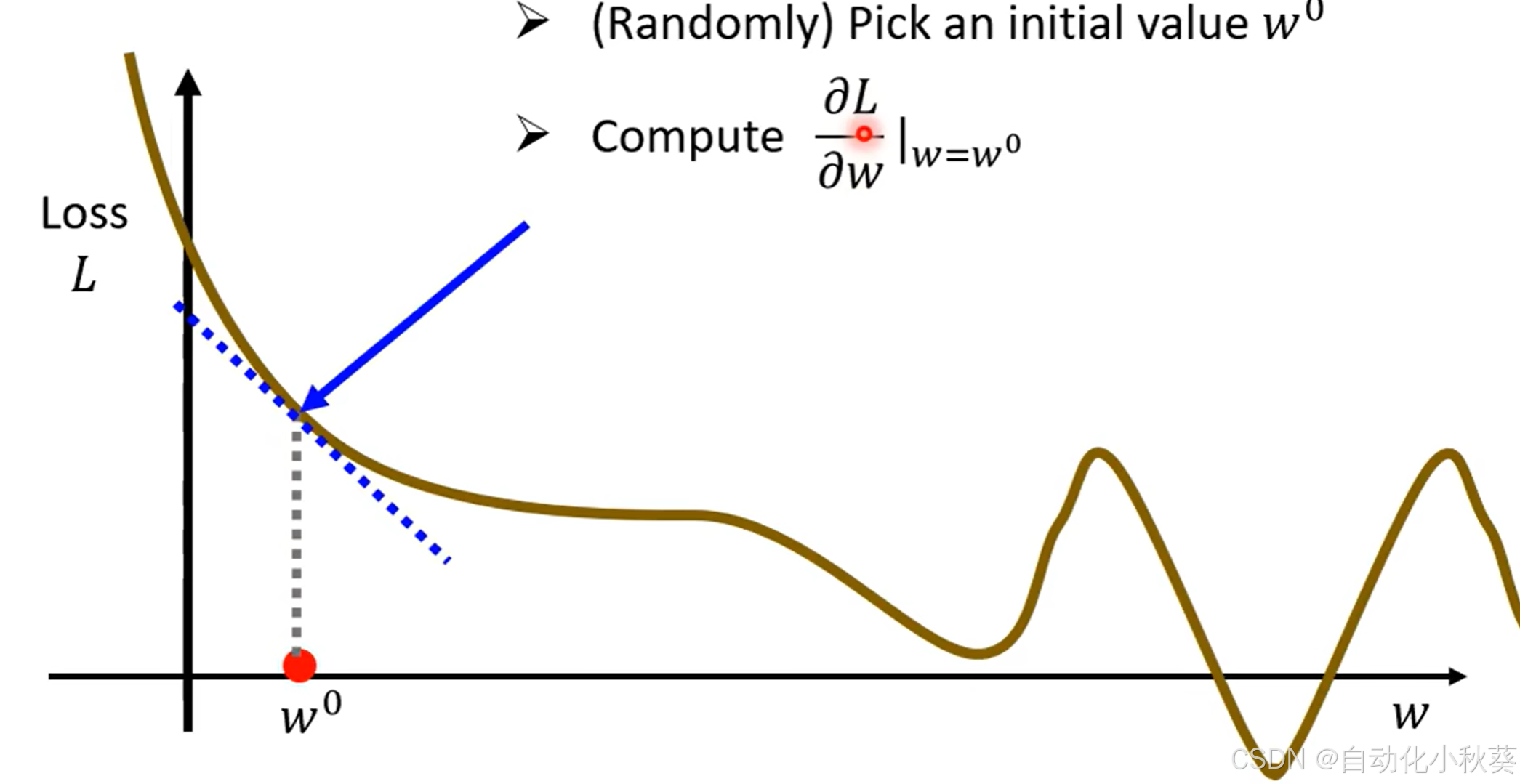
当微分结果为负数时,代表左高右低,为了找寻小Loss值应该往右边也就是增大w方向取值,反之往左w小的方向取值。
假设往大了找w那么应该多大?
这个scale跨度怎么取?
scale =
(learning rate):自己取,影响数值改变快慢,越大越快 [hyperparameters自定义参数]
一般来说取到 此时参数为最优解。
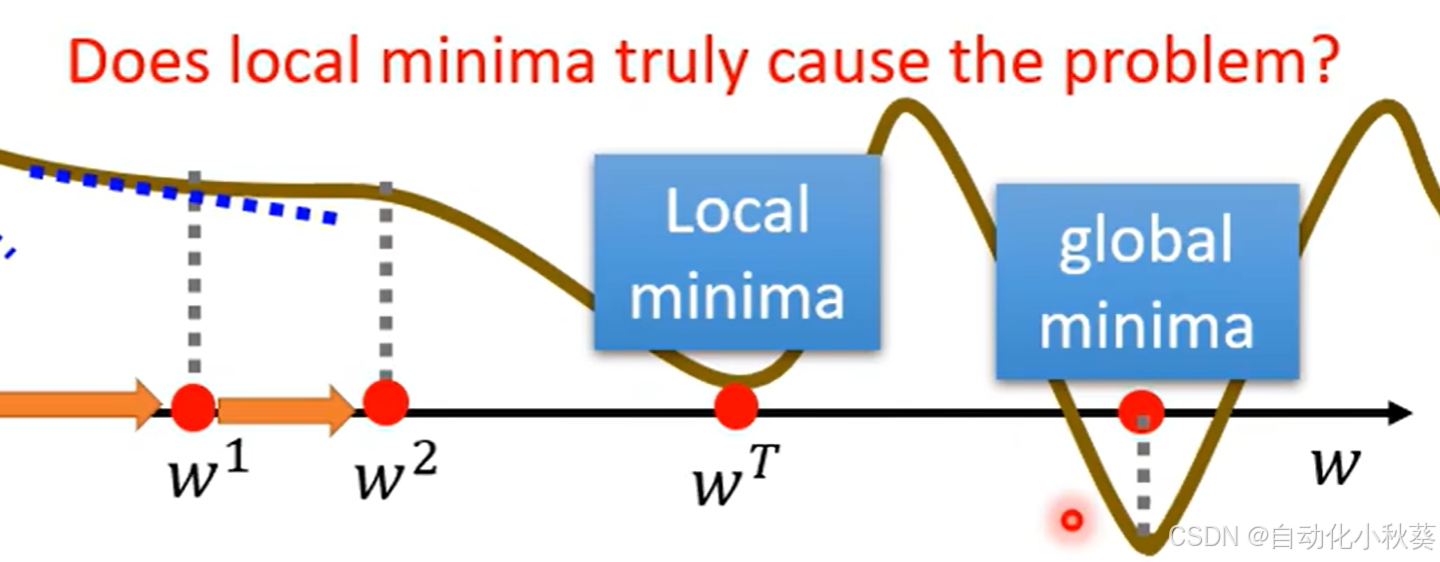
但是这么取会有一个问题,就是L并不是全局最小值,只是局部最小值。(暂时不讨论其影响,因为Local minima不是主要问题)
那么我们知道, 有2个未知数,所以,对w,b分别求偏导即可

复杂函数关系
step1
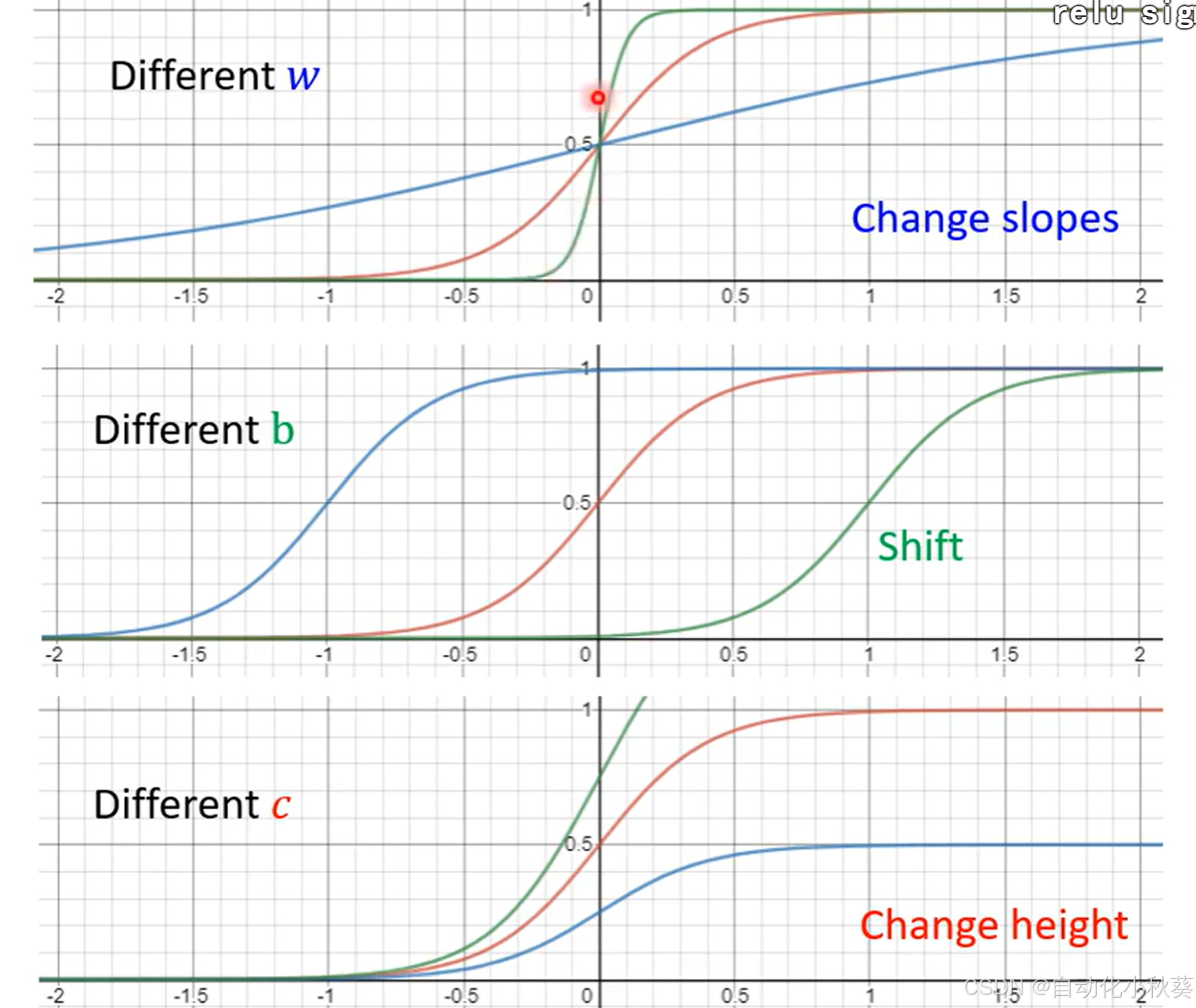
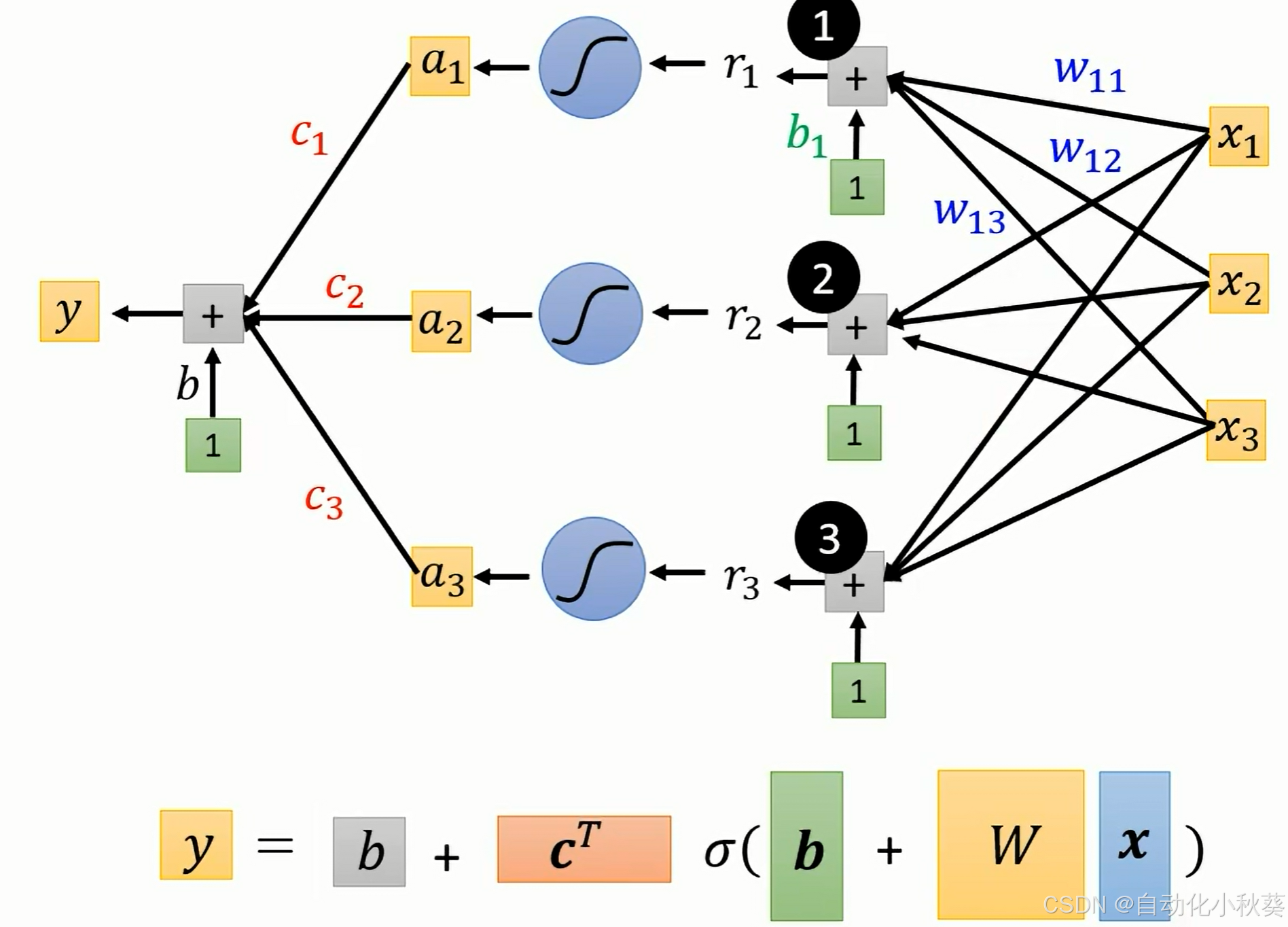
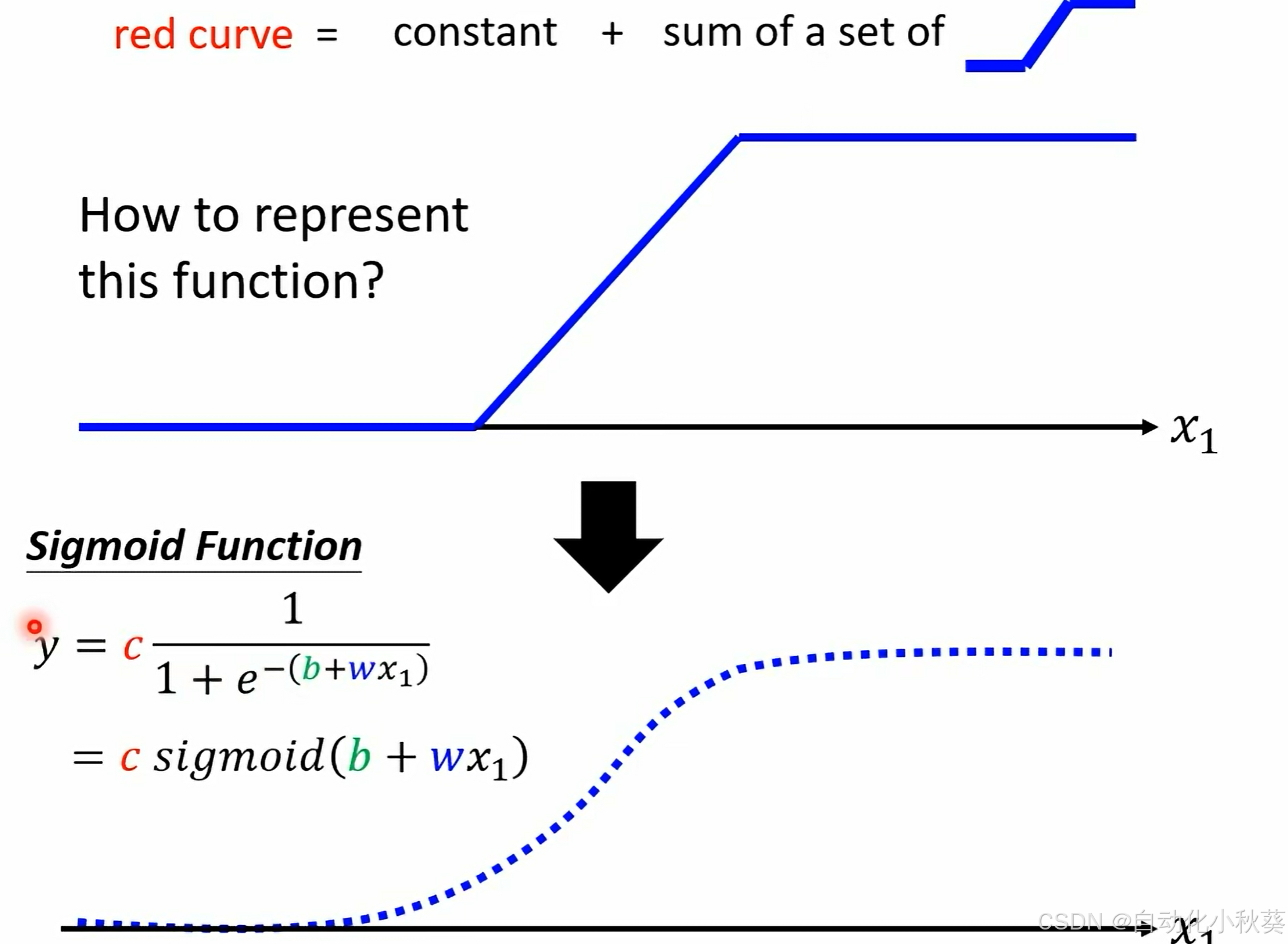 为实现蓝色实线函数,我们可以采用sigmoid函数来实现,改变(c,b,w)数值即可构造不同形状函数。
为实现蓝色实线函数,我们可以采用sigmoid函数来实现,改变(c,b,w)数值即可构造不同形状函数。
OK,那么对于一个复杂的关系,就可以用不同sigmoid叠加形成:
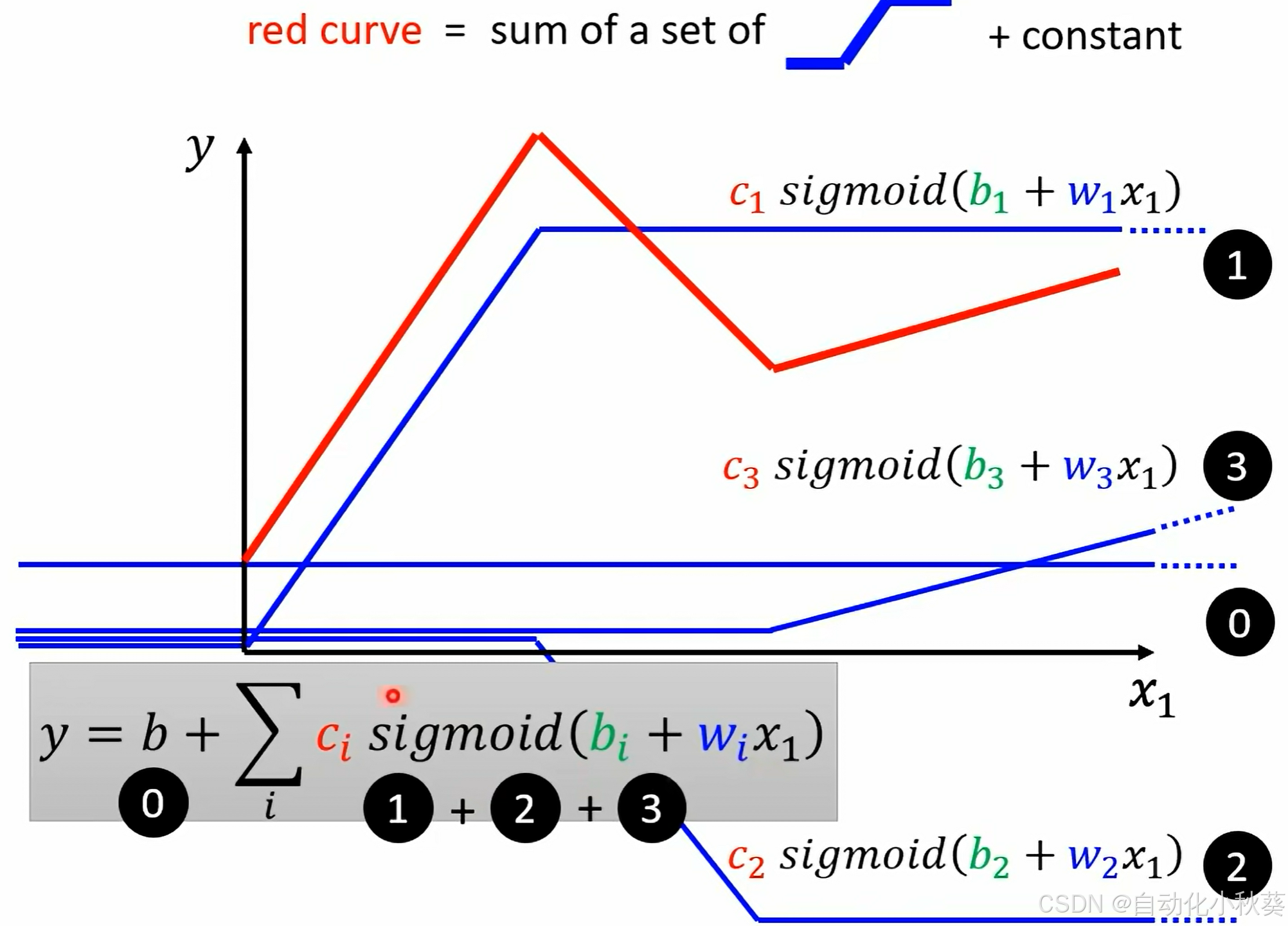
补充一下:红线是根据已有数据取点描绘出来的,用sigmoid取不同(b,ci,bi,wi)去逼近这个红线.
将上述表达式转用矩阵形式表达出来,b,W,x均为向量
step2
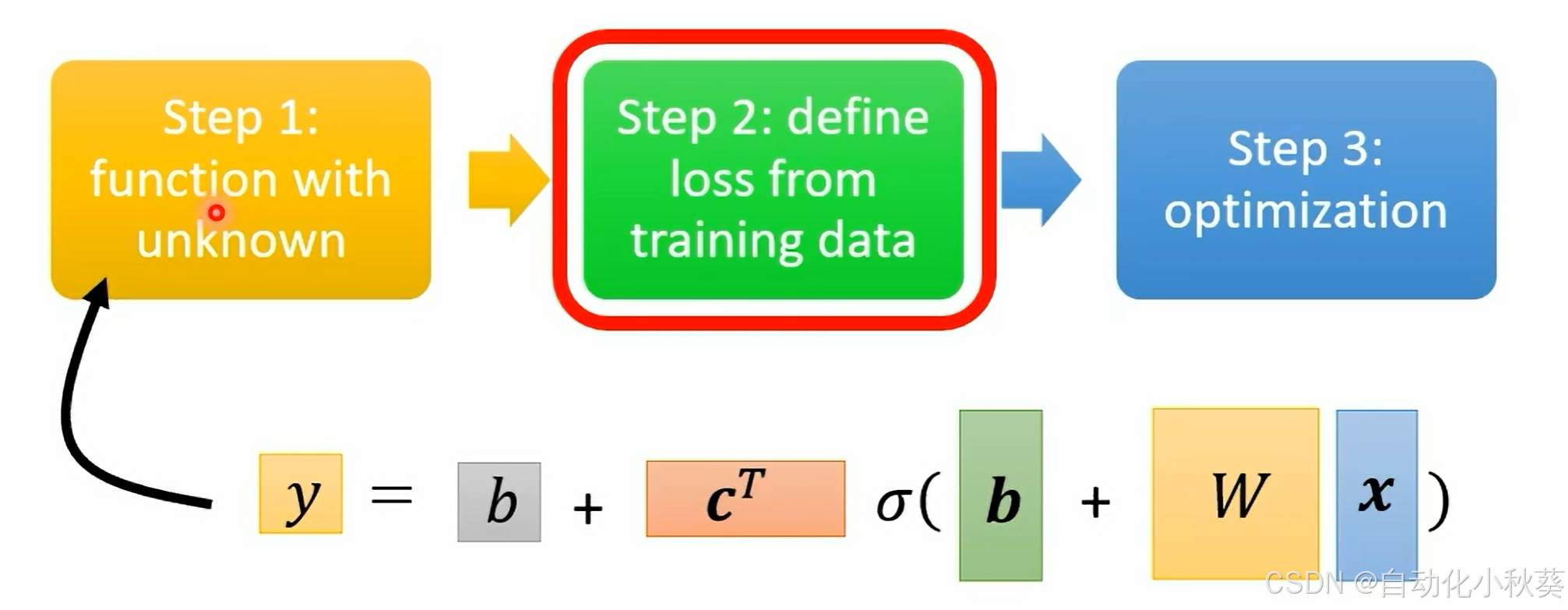
将所有未知量放入
,构建
。
先随机给一组,带入已知的x数据,求L (
已知)
step3
gradient descent:
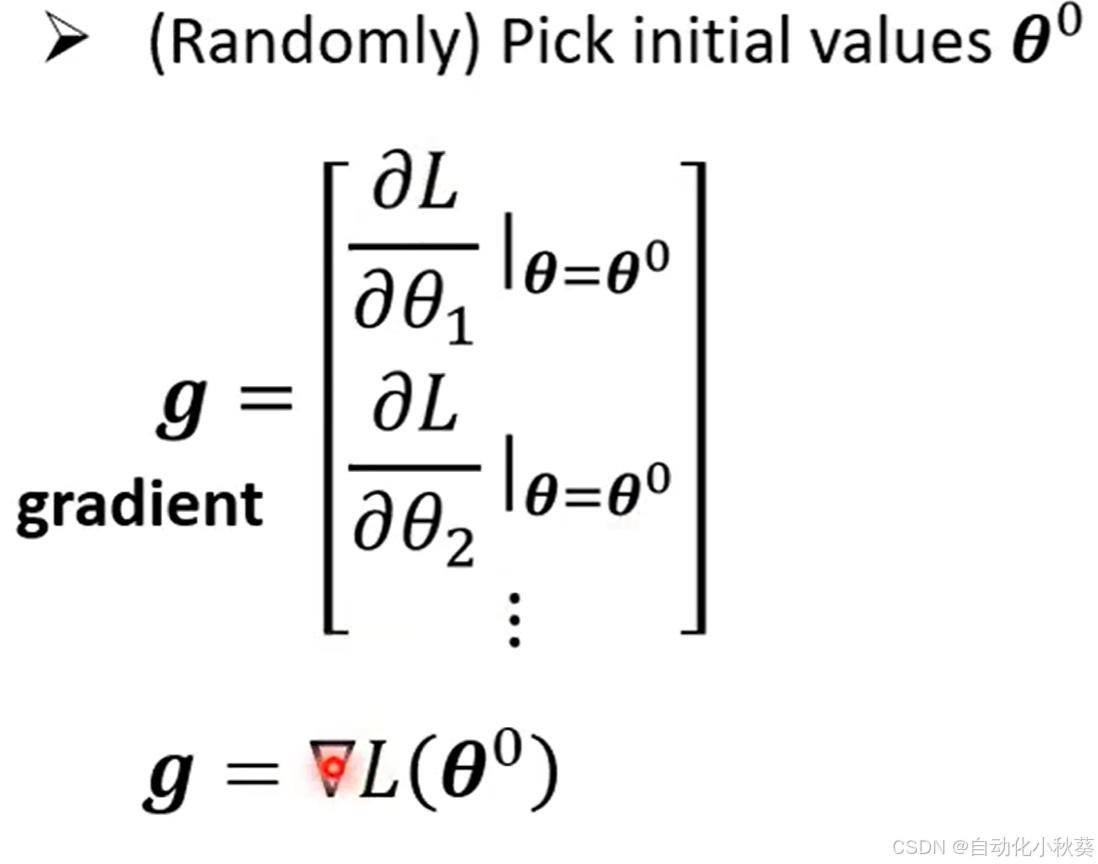
根据微分结果更新值:
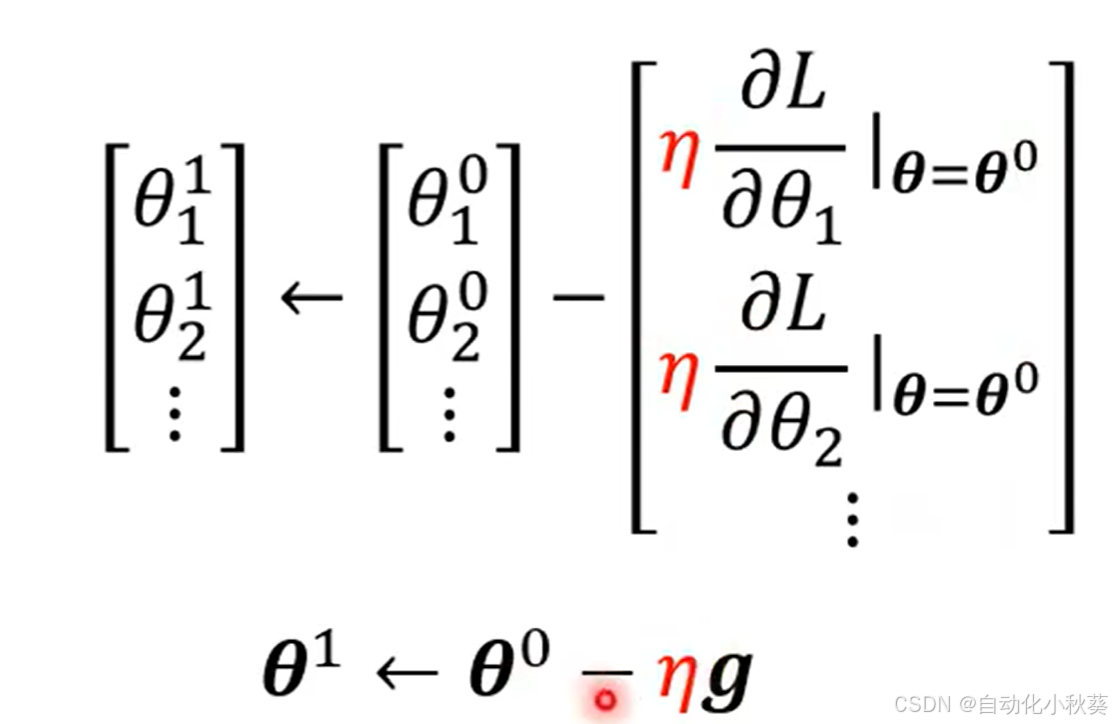
最后参数确定,预测值可以带入求出:(给前3天数据得明天数据)
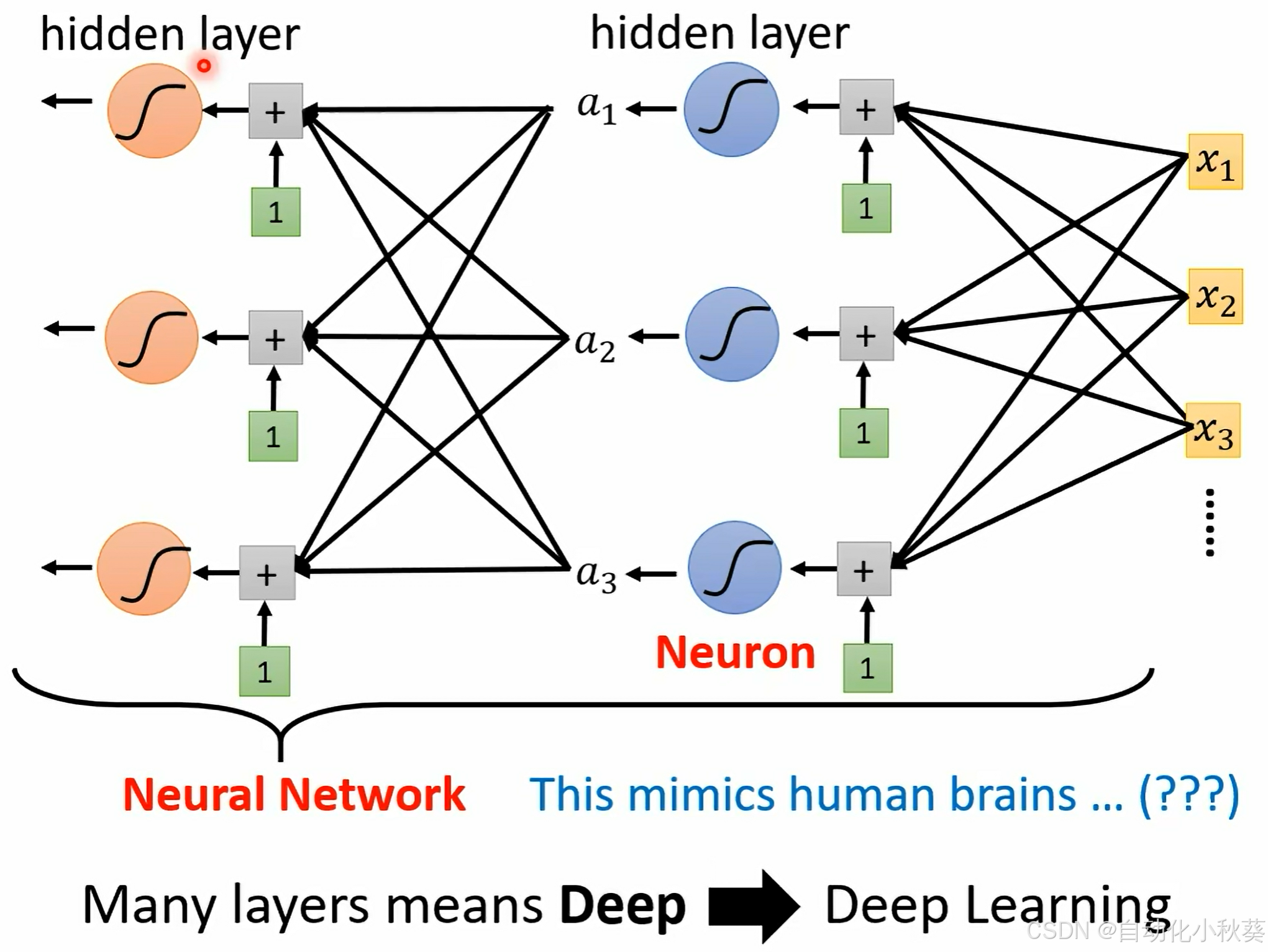
首先我们拟合函数y是靠多个sigmoid函数叠加起来(step1),划分的越细,叠加的函数会越多,可以理解为越胖,实际上L确实会越小(但是效果没那么好)。但是实际上并没有采用过多的叠加,而是多次套用sigmoid运算去给未知数取值,L也会越小(不过拟合的情况下)。
,多层重复计算,
.......
这个过程叫深度学习,但是有点疑惑?不断套用的方法代表什么含义呢,为什么得到的预测值越准?
先把这个疑问放这。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









