






 本文通过图表直观展示了从常数复杂度到指数复杂度的各种时间复杂度,并举例说明了每种复杂度对应的典型算法场景,如常数复杂度的数组索引查找、对数复杂度的二分搜索等。
本文通过图表直观展示了从常数复杂度到指数复杂度的各种时间复杂度,并举例说明了每种复杂度对应的典型算法场景,如常数复杂度的数组索引查找、对数复杂度的二分搜索等。
前言
本篇不深究算法,旨在让大家对时间复杂度有一个直观感受,在面对代码时,能做到一个大概的判断。
各种时间复杂度的直观比较
O ( 1 ) < O ( l o g n ) < O ( n ) < O ( n l o g n ) < O ( n 2 ) < O ( n 3 ) < O ( 2 n ) < O ( n ! ) < O ( n n ) O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) <O(n^3) < O(2^n) < O(n!) < O(n^n) O(1)<O(logn)<O(n)<O(nlogn)<O(n2)<O(n3)<O(2n)<O(n!)<O(nn)
O(1) — 常数复杂度
O(log n) — 对数复杂度
O(n) — 线性复杂度
O(n log n) — 对数线性复杂度
O(nᵏ) — 多项式复杂度
O(kⁿ) — 指数复杂度
O(n!) — 阶乘复杂度
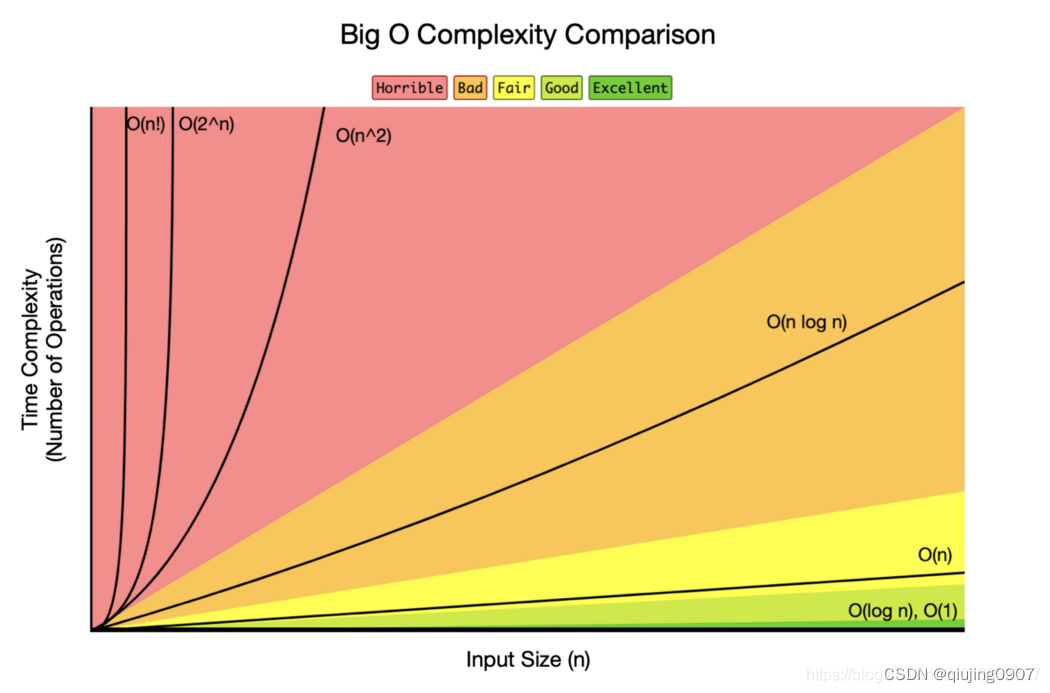
随着输入规模的增长,红色阴影区域中算法的运行时间急剧增长。另一方面,在黄色和绿色阴影区域中的算法,当输入规模增长时,运行时间在变化不是很大,因此它们更高效,处理大量数据时更游刃有余。
各种时间复杂度的场景
-
O(1) — 常数复杂度
这种复杂度的算法的运行时间不会随着输入规模的增加而增加。
场景
数组中按索引查找值,或者在哈希表中按键查找值 -
O(log n) — 对数复杂度
这是一种用于在有序数组中查找特定值的算法,每次降低一半的范围(以1/2的速度递减)
场景
二分搜索 -
O(n) — 线性复杂度
线性复杂度,随着输入规模增加,而线性增长
场景
数组遍历 -
O(n log n) — 对数线性复杂度
同时包含对数和线性部分
场景
常见的示例是排序算法
归并排序
跳表,然后二分查找 -
O(nᵏ) — 多项式复杂度
在这里,我们开始着手研究时间复杂度较差的算法,通常应尽可能避免使用它(请参考上文的图表,我们正处于红色区域!)。但是,许多「暴力」算法都属于多项式复杂度,可以作为帮助我们解决问题的切入点。例如:O(n²)
场景
双层循环 -
O(kⁿ) — 指数复杂度
倒数第二个常见时间复杂度是指数复杂度
即随着输入规模的增加,运行时间将按固定倍数来增长,
规模每+1,复杂度是原来的指数
即逻辑处理上,有分裂(分治)处理
场景
求斐波那契数列中的第n项,递归
def nth_fibonacci_term(n: int) -> int:
"""递归计算斐波纳契数列的第 n 项。假设 n 是整数。"""
# 基本情况 —— 前两项的值为 {0,1}
if n <= 2:
return n - 1
return nth_fibonacci_term(n - 1) + nth_fibonacci_term(n - 2)
- O(n!) — 阶乘复杂度
通常应避免这中复杂度,因为随着输入规模的增加,它们会很快变得难以运行。
场景
旅行推销员问题的暴力解法
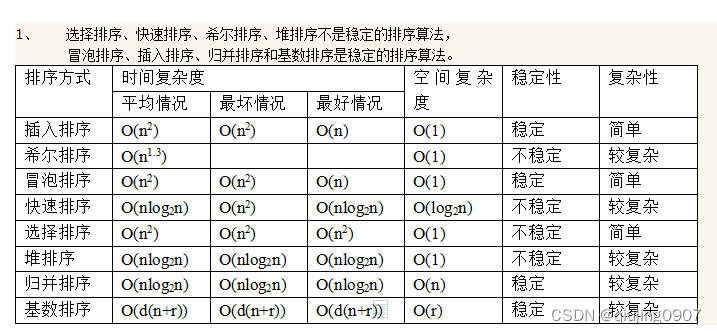
常用排序算法的时间复杂度
参考文章
《各种排序算法复杂度比较》
《Markdown系列(6)- 如何优雅地在Markdown中输入数学公式》
《算法中七种常见的时间复杂度》 (强力推荐这篇原文)

















 4580
4580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









