







 本文介绍了如何在PyCharm中调试Scrapy项目,包括使用run.py进行简单调试以及复制scrapy/cmdline.py进行环境配置,详细步骤有助于理解Scrapy的命令行执行过程。
本文介绍了如何在PyCharm中调试Scrapy项目,包括使用run.py进行简单调试以及复制scrapy/cmdline.py进行环境配置,详细步骤有助于理解Scrapy的命令行执行过程。
scrapy在pycharm 调试
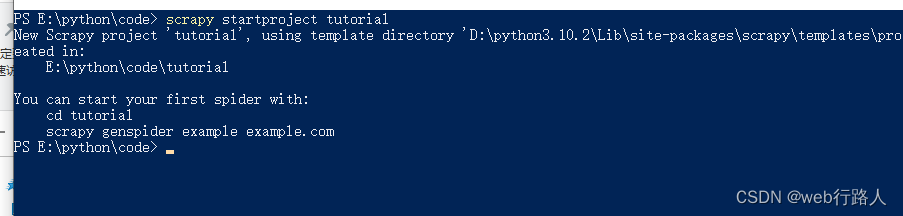
1、使用scrapy创建一个项目
scrapy startproject tutorial
2、在朋友pycharm中调试scrapy
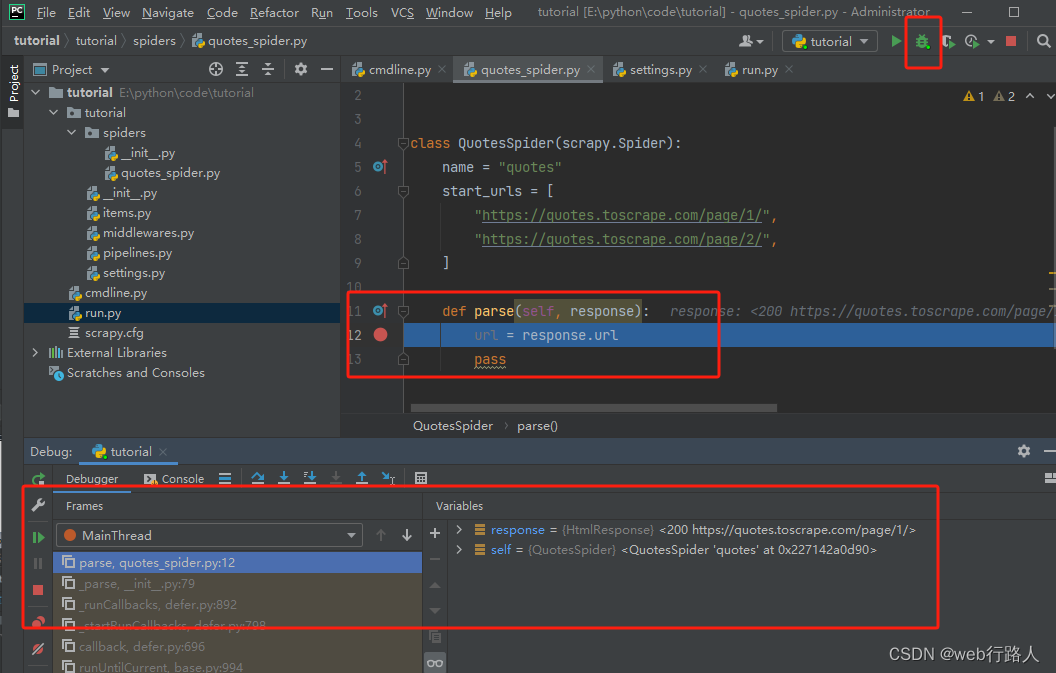
2.1 通过文件run.py调试
在根目录下新建一个文件run.py(与scrapy.cfg文件的同一目录下), debug ‘run’即可
# -*- coding:utf-8 -*-
from scrapy import cmdline
# quotes 对应的是爬虫名 在cmd运行 scrapy crawl quotes 同步
cmdline.execute("scrapy crawl quotes".split())
调试与运行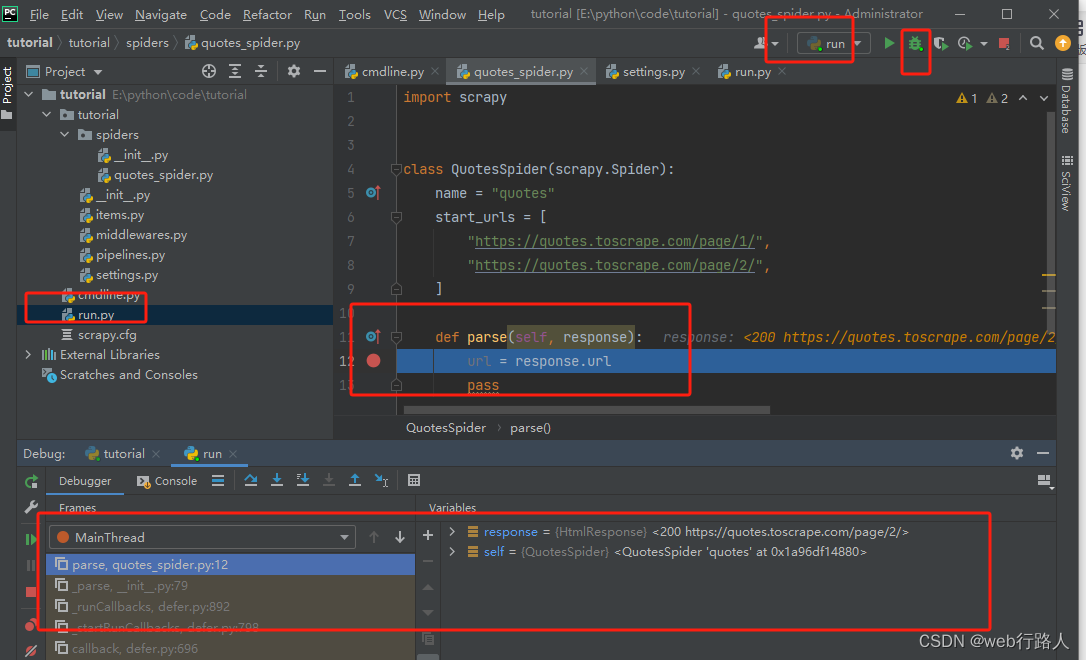
2.2 配置环境调试
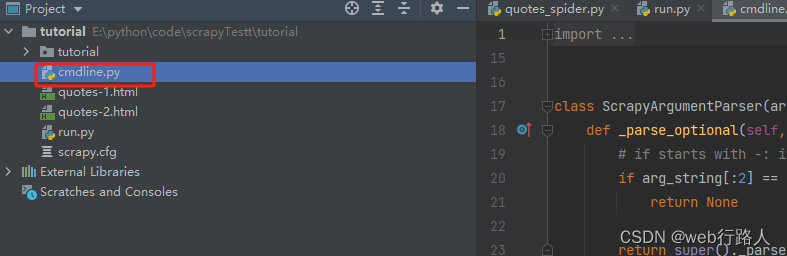
复制cmdline.py到项目主目录
找到scrapy下的cmdline.py文件(比如我这里是D:\python3.10.2\Lib\site-packages\scrapy\cmdline.py)复制一份到tutorial项目的根目录下(scrapy.cfg文件的同一目录下)
编缉文件调试运行配置
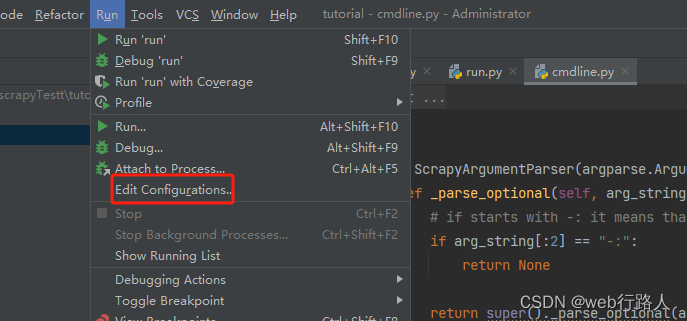
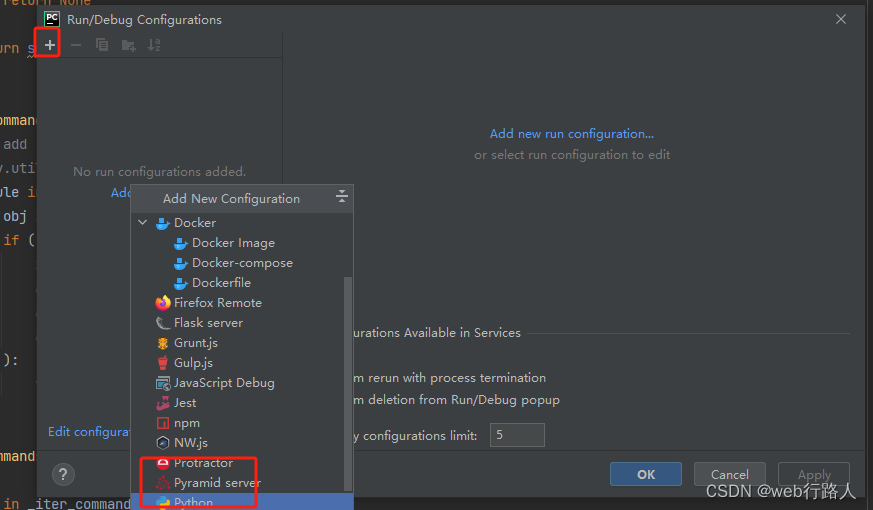
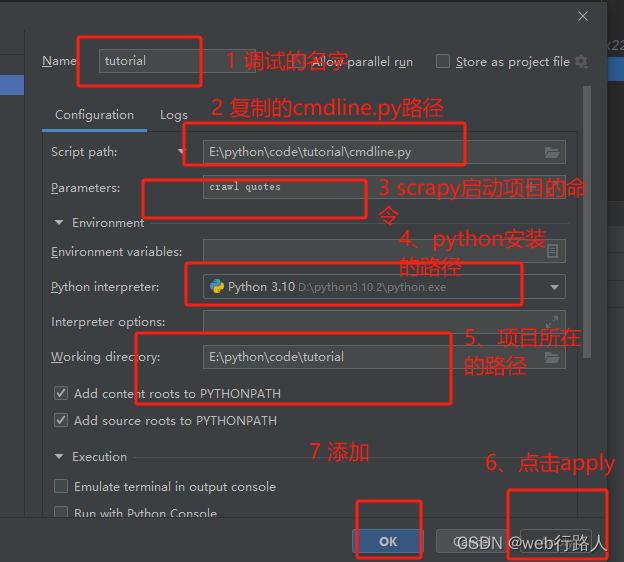
调试与运行

















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









