






 本文详细介绍如何使用Python进行网页爬取,包括Twisted和Scrapy的安装配置,以及针对智联招聘网站的爬虫实践,涉及数据提取、项目结构搭建、浏览器伪装等关键步骤。
本文详细介绍如何使用Python进行网页爬取,包括Twisted和Scrapy的安装配置,以及针对智联招聘网站的爬虫实践,涉及数据提取、项目结构搭建、浏览器伪装等关键步骤。
声明:
此篇为学习李刚老师疯狂python讲义里爬虫的笔记。
1、下载twisted:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
2、安装twisted
pip install [包所在的路径]\包名
3、安装scrapy
pip install scrapy
4、
爬取地址:
https://www.zhipin.com/c101280100
5、shell调试
scrapy shell “https://www.zhipin.com/c101280100”
报错
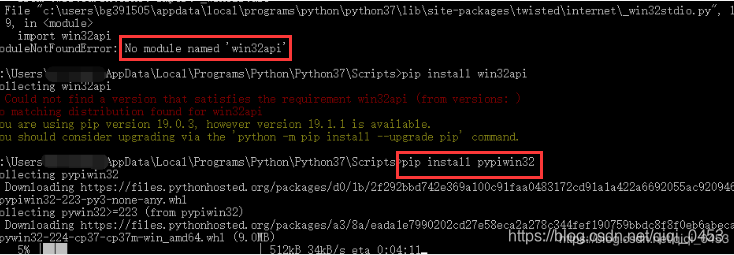
有反爬设置
浏览器伪装或者模拟登录
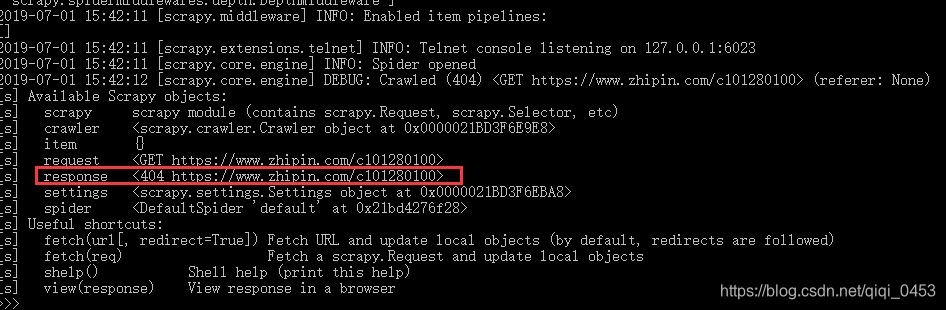
浏览器伪装
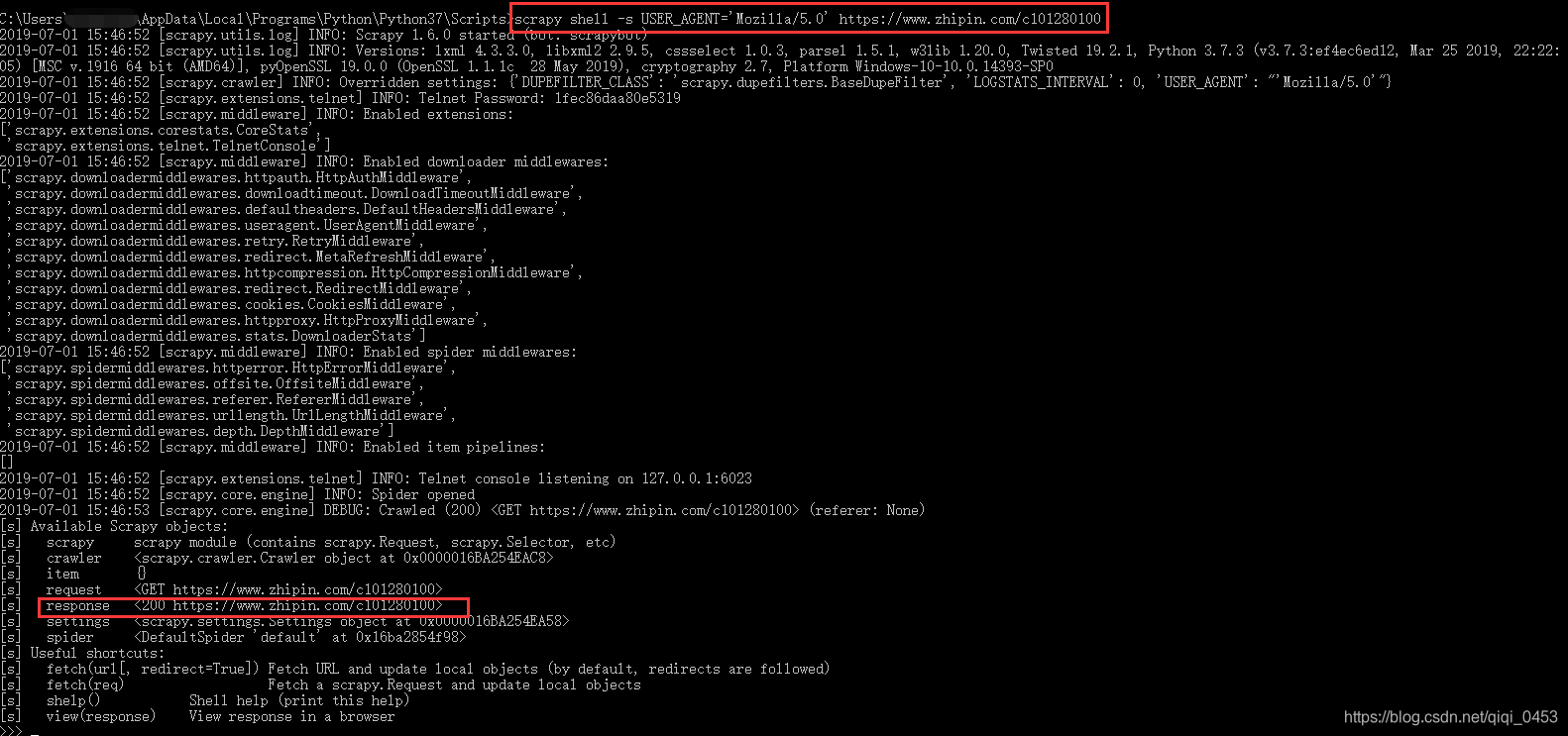
获取job-title

response.xpath(’//div[@class=“job-primary”]/div/h3/a/div[@class=“job-title”]/text()’).extract()

6、开始一个爬虫项目
项目结构如下:

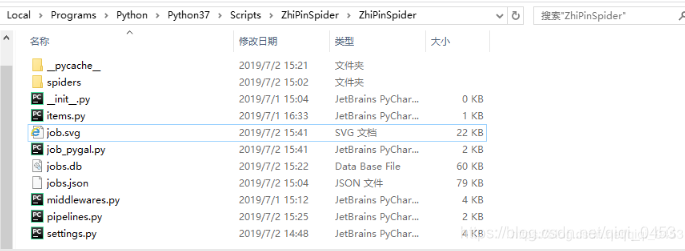
① 建立项目
scrapy startproject 【项目名称】
②生成蜘蛛
scrapy genspider 【蜘蛛名】“zhipin.com”
③写items文件
定义要爬取得数据
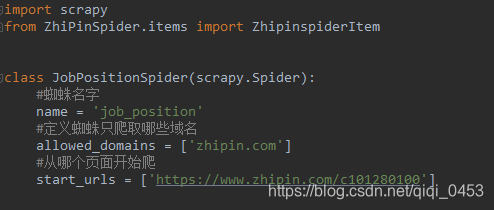
④写蜘蛛文件”job_position"
通过 response.xpath 获取item并返回item
⑤写pipelines文件
通过重写process_item方法,定义将item导出或者存储至数据库
⑥配置settings文件
伪装浏览器,配置pipelines


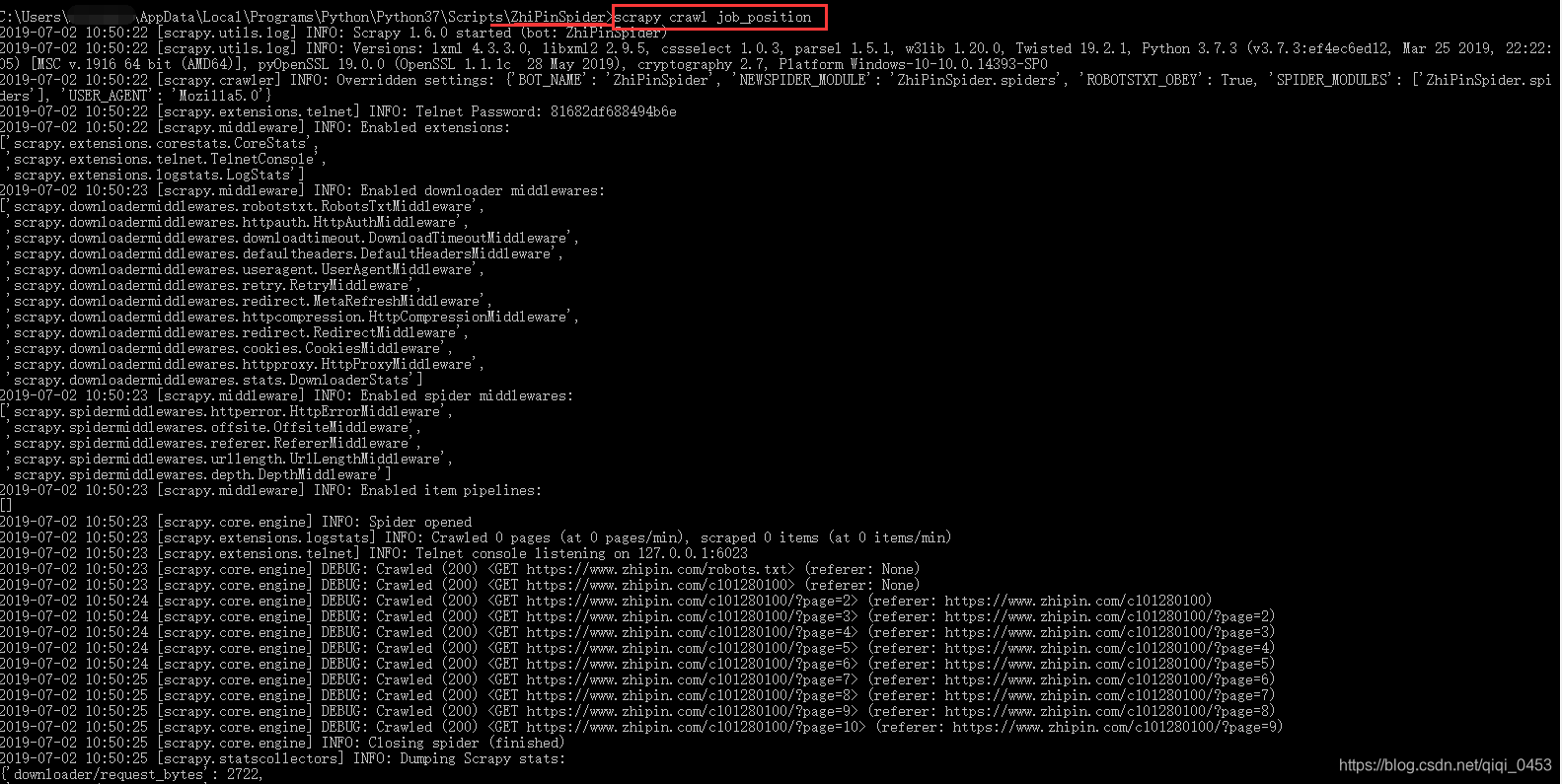
⑦开始爬虫
在项目的根目录也就是spiders这个文件夹的目录执行命令:scrapy crawl [蜘蛛名] -s LOG_FILE=debug.log
(-s LOG_FILE=debug.log)不会在控制台打印爬取过程的debug信息,而是将日志打印到debug.log文件中
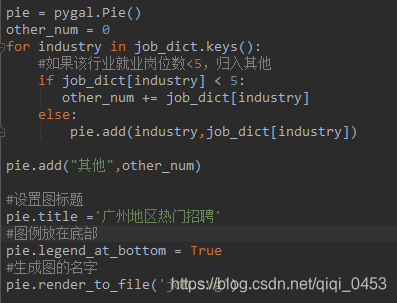
可以使用pygal模块生成svg图,分析数据。
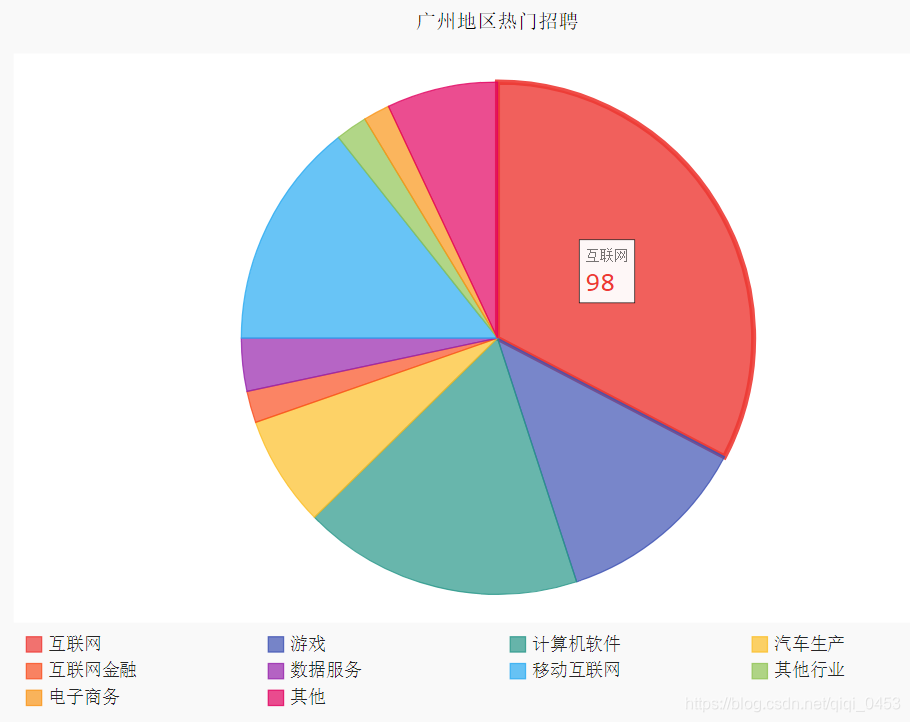
生成的svg图,在qq浏览器打开的,使用IE的时候鼠标放上去不显示个数,还以为是pygal版本问题,结果换个浏览器就好了。

















 1531
1531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









