







 本文详细介绍了基于深度学习的个性化召回算法item2vec,包括其背景、物理意义、主流程及word2vec模型的数学原理。item2vec利用word2vec的训练方法,将用户行为序列转化为item组成的句子,通过word2vec得到item的向量表示,进而计算item之间的相似性,用于推荐。同时,文章也分析了item2vec的缺陷和训练流程。
本文详细介绍了基于深度学习的个性化召回算法item2vec,包括其背景、物理意义、主流程及word2vec模型的数学原理。item2vec利用word2vec的训练方法,将用户行为序列转化为item组成的句子,通过word2vec得到item的向量表示,进而计算item之间的相似性,用于推荐。同时,文章也分析了item2vec的缺陷和训练流程。
文章目录
第04章基于深度学习的个性化召回算法item2vec
本章节重点介绍一种基于深度学习的个性化召回算法item2vec。从item2vec的背景与物理意义以及算法的主流程进行介绍。并对该算法依赖的模型word2vec数学原理进行浅析。最后结合公开数据集代码实战item2vec算法。
本章节重点介绍基于深度学习的个性化召回算法item2vec。分为两部分:第一部分,item2vec背景和物理意义,论文依据,算法流程,以及item2vec的依据的模型word2vec的数学原理等等理论部分解析。第二部分,根据示例数据,item2vec的算法流程,编程实战,训练模型得到item对应的向量完成推荐并分析推荐结果。
一、基于深度学习的个性化召回算法item2vec
1、个性化召回算法item2vec背景与物理意义
个性化召回算法item2vec背景
- Item2item的推荐方式效果显著:
很多场景下item2item的推荐方式要优于user2item;
item2item的推荐方式:在获取item相似度矩阵之后,根据用户的最近的行为,根据行为过的item找到相似的item,完成推荐,如itemCF。
user2item:根据用户的基本属性和历史行为等基于一定的模型,算出最可能喜欢的item列表写在KV存储中;当用户访问系统的时候,将这些item列表推荐给用户,像userCF、LFM、personal rank算法等都是这种方式。
- NN model(神经网络)模型的特征抽象能力
神经网络的特征抽象能力是要比浅层的模型特征抽象能力更强,主要有两方面原因:
(1)输入层与隐含层,隐层与输入层之间,所有的网络都是全连接的网络;
(2)激活函数的去线性化;
基于上述,基于神经网络的item2item的个性化召回算法item2vec也就在这个大背景下产生了。
3、依据的算法论文:Item2Vec: Neural Item Embedding for Collaborative Filtering
核心内容1:论文首先介绍了item2vec落地场景是类似于相关推荐的场景。也就是说用户点击了某item a APP,那么推荐一款类似的APP给用户。
核心内容2:介绍了item2vec所选的model,也就是word2vec算法原理,文中采用了负采样的训练方法进行介绍,因为我们知道word2vec还有一种也就所说的哈夫曼树的方式进行训练。那么我们后面也用负采样的方式进行介绍word2vec的算法原理。
核心内容3:论文抽象了算法的整体流程。
核心内容4:论文将给出了与之前流行的item2item算法进行结果对比。
个性化召回算法item2vec物理意义
在介绍item2item之前,先介绍一下原型word2vec。
- word2vec
根据所提供的语料,语料可以想象成一段一段的文字,将语料中的词embedding成词向量,embedding成词向量之间的距离远近可以表示成词与词之间的远近。(word2vec原理中详细介绍怎么样做到可以表征词与词距离的远近)
- item2item
(1)将用户行为序列转换成item组成的句子。
解释:在系统中,无论是用户的评分系统,还是信息流场景下用户的浏览行为,或者是电商场景下用户的购买行为。在某一天内,用户会进行一系列的行为,那么将这一系列的行为抽象出来。每一个用户组成的item与item之间的这种序列的连接关系就变成了之前所说的文字组成的一段一段的句子,那么这里的每一个word相当于这里的item。
(2)模仿word2vec训练word embedding 过程,将item embedding。
word embedding的过程只需要提供语料,也就是一段一段的文字,那么训练得到的word embedding可以表征词语义的远近,那么同样希望表征item之间内涵的远近。
所以,可以将第一步构成的item语料放到word2vec中,也能够完成item embedding。embedding完成的向量同样可以表示item之间的隐语义的远近,也就是说,可以表示item之间的相似性。
以上就是item2vec的物理意义。
个性化召回算法item2vec缺陷
(1)用户的行为序列时序性缺失:
在介绍物理意义的时候,说过将用户的行为转化成由item组成的句子,这里句子之间词与词之间的顺序与按照用户行为顺序进行排列和不按照用户行为顺序进行排列的结果是几乎一致的。
也就是用户的行为顺序性,模型是丢失的。
(2)用户行为序列中的item强度是无区分性的:
这里比如说,在信息流场景中,观看短视频的50%或者80%或者100%,在用item组成的句子当中,同样都是出现一次的,而不是说观看100%就会出现2次。
再如,在电商场景中,可能你购买一件商品,或者说你加了购物车,都会出现一次;而不会说,你购买了就会出现两次。加了购物车,在句子当中出现一次。在item cf算法中,item 相似度矩阵计算 ,当时引入了用户行为item的总数,用户行为item的时间这两个特征,来分别将公式进行升级。所以在item2vec算法中,是没有这个消息的。所以是item2vec的缺陷之一。
2、item2vec算法应用的主流程
(1)从log中抽取用户行为序列
按照每个用户“天”级别,行为过的item,构成一个完整的句子,这里的行为根据不同的推荐系统所指的不同。比如:在信息流场景下,用户点击就可以认为是行为;那么在评分系统中,我们可能需要评分大于几分;在电商系统中,可能希望用户购买,得到用户行为序列所构成的item句子。
(2)将用户序列当做语料训练word2vec得到item embedding
在训练过程中,word2vec代码不需要书写,但是有很多参数是需要我们具体设定的。
(3)得到item sim关系用于推荐
根据第二个步骤中得到每一个item所embedding的向量,可以计算每一个item最相似的top k个,然后将相似度矩阵离线写入到KV当中,当用户访问我们的推荐系统的时候,用户点击了哪些item,推出这些item所最相似的top k个给用户,就完成了推荐。
eg:
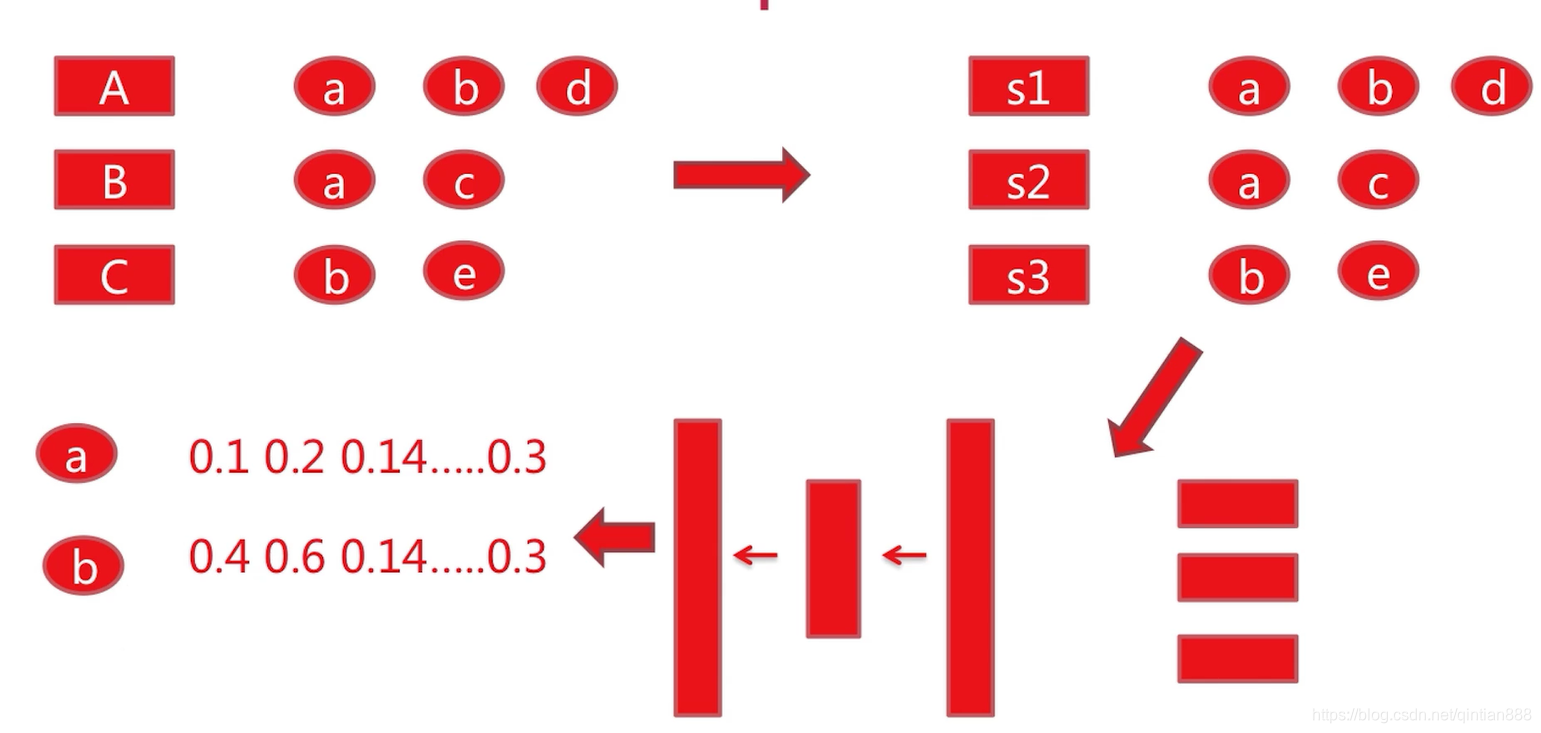
1、首先第一步:这是我们从推荐系统log中获得的,也就是说User A行为过item a、item b、item d,User B行为过item a、item c,User C行为过item b、item e。
2、继而我们需要将这些转化成句子。句子1就是a、b、d。句子2就是a、c。句子3就是b、e。这里我们已经没有了user之间的关系,只留下item组成的句子。
3、将句子放入到放入word2vec模型,这里就是一个输入(word2vec模型是一个三层的神经网络:输入层、隐含层、输出层,具体每一层的作用,公式原理后面详细介绍。)
经过word2vec模型的训练,会得到每一个item对应的embedding层向量。这里只写了item a [0.1,0.2,0.14…0.3] ,item b [0.4,0.6,0.14…0.3]。item c,item d,item e也是可以得到的。
4、得到item向量之后,就得到item的sim关系。基于item sim的关系,我们便完成了用户的推荐。
3、item2vec依赖模型word2vec介绍(连续词袋模型和跳字模型(skip-gram))
item2vec依赖模型word2vec的数学原理详细介绍
word2vec model
是围绕负采样的训练方法进行介绍,因为我们知道word2vec还有一种也就所说的哈夫曼树的方式进行训练(这里就不做介绍了)。
word2vec有两种形式:连续词袋模型和跳字模型(skip-gram)
- CBOW(continuous bag of words)连续词袋模型
- skip gram()跳字模型
二、item2vec依赖模型word2vec之CBOW数学原理介绍
1、CBOW网络结构
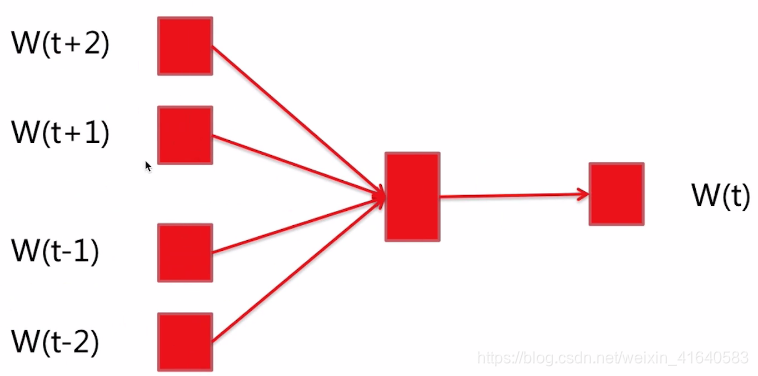
网络分为三层:输入层、投影层、输出层。
输入层:上下文;比如说这里有五个词W(t+2)、W(t+1)、W(t)、W(t-1)、W(t-2)。这里我们需要输入的训练数据是W(t)的上下文,即是W(t+2)、W(t+1)、W(t-1)、W(t-2)。
投影层:将上下文的词输入的向量加起来;因为给每个词都初始化了一个向量。比如说我们需要让它的长度是16。那么刚开始的时候,这些词W(t+2)、W(t+1)、W(t-1)、W(t-2),再包括了W(t)都有一个初始化的向量。把这些向量加到了投影层。
输出层:当前词;
投影层与输出层之间是全连接,如果输出的这个词是这里的W(t)的话,希望最大化的就是这个概率。而除了W(t),词典(词典指训练语料包含的所有的词)中所有的其他的词,其余词的概率我们都希望最小那个概率。
这就引申出一个问题,如果其余词都是负样本的话,负样本太多,训练太慢。
所以,采用负采样(后面介绍)的方法。这里我们先不要关心负采样的具体是怎么做的,后面我们会详细的介绍
也就是说,有了正样本W(t)与它的上下文,负样本是通过负采样得到的,我们希望最小化负样本所对应的模型的输出。这里实际上,最后一层的输出不仅仅是只有W(t),实际上是有字典中每一个词。因为每一个词都有一个与输出层之间的全连接,这也是模型需要训练的参数之一。
然后,模型需要得到的是每一个词,我们初始化的那个向量,让它训练,根据我们传入的训练样本,训练完成的向量,就是最后模型输出。我们就是依赖每一个词对应的向量,完成item相似度矩阵之间的运算。
与传统的监督模型有所不同,传统的模型在训练完成之后,需要将它保存,然后对外提供服务,当我们传入真实样本的时候,希望得到一个输出值;而这里不是。下面我们来看下一中形式。
2、CBOW的数学公式
- 问题抽象
g ( w ) = ∏ u ∈ w ∪ N E G ( w ) p ( u ∣ Context ( w ) ) g(w)=\prod_{u \in w \cup N E G(w)} p(u | \operatorname{Context}(w)) g(w)=u∈w∪NEG(w)∏p(u∣Context(w))
上式是想最大化的条件概率函数。
下面我来解释一下这个公式:
Context ( w ) \text { Context }(w) Context (w):某一词W(t)的上下文的词,已知上下文,想预测中间词。
可能有的同学对于这个训练样本还不是很了解,下面我举一个最简单的例子,有一句话是我是中国人,那么经过分词之后呢,变成了(我 是 中国 人)这么四个字也就是w1,w2,w3,w4,如果我们选窗口是1的话,在这里第1组的训练样本变成了(我 是 中国 人),其中这个"是"就是公式这里的w,它的上下文呢,w(t+1)呢是’中国’,w(t-1)是"我"这个词。
我们知道了"中国",“我"这个词。如果u是W的话(这个u是公式中W"是"的话),则是需要最大化条件概率;如果是W的负样本(NEG(w))(除了"是”,以外的其他词),我们想要把这个概率最小化,最小化这个条件概率 p ( u ∣ Context ( w ) ) p(u | \text { Context }(w)) p(u∣ Context (w)),也就是最大化 1 − p ( u ∣ Context ( w ) ) 1-p(u | \text { Context }(w)) 1−p(u∣ Context (w))条件概率。那么无论是u是w,或者u是我们选择的负采样的负样本都能统一起来了,实际上这个式子由两部分组成。
这里的条件概率是指:
p ( u ∣ Context ( w ) ) = σ ( X w T θ u ) L w ( u ) ( 1 − σ ( X w T θ u ) ) ( 1 − L w ( u ) ) p(u | \text { Context }(w))=\sigma\left(X_{w}^{T} \theta^{u}\right)^{L^{w}(u)}\left(1-\sigma\left(X_{w}^{T} \theta^{u}\right)\right)^{\left(1-L^{w}(u)\right)} p(u∣ Context (w))=σ(XwTθu)Lw(u)(1−σ(XwTθu))(1−Lw(u))
这个式子由两部分组成:
(1)当u=w时,也就是说label L w ( u ) L^{w}(u) Lw(u)=1,起作用的是前一部分,因为后面的指数变为零次幂( 1 − L w ( u ) 1-L^{w}(u) 1−Lw(u)=0),零次幂的话,后面部分就等于1了。起作用的是前一部分,我们是想最大化的正样本的概率。解释一下这里的 X w T X_{w}^{T} XwT和 θ u \theta^{u} θu:
X w T X_{w}^{T} XwT:CBOW的时候,投影层是将w对应的上下文的词向量加和。也就是我们这里举例子的"我"和"中国"对应的向量加和,便是这里的 X w T X_{w}^{T} XwT。
θ u \theta^{u} θu:隐含层(投影层)和输出层对应的词为u的时候,它们之间的全连接。
所以,想通过模型训练,让这两个参数 X w T X_{w}^{T} XwT和 θ u \theta^{u} θu相乘得到的结果为1。(按照我们的距离就是16维的横竖向量相乘应该是一个常数,这里我们希望通过训练,让他最终相乘得到的数字是1)
(2)负采样部分,也就是后面那一部分,我们这里负采样选取的负样本,希望这一部分是0。也就是希望这一部分 1 − σ ( X w T θ u ) 1-\sigma\left(X_{w}^{T} \theta^{u}\right) 1−σ(XwTθu)为1,也就是最大化 1 − σ ( X w T θ u ) 1-\sigma\left(X_{w}^{T} \theta^{u}\right) 1−σ(X
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









