







 决策树是一种有监督的分类算法,分为离散性和连续性两种类型。概念包括熵、信息增益、信息增益比和基尼指数,用于评价特征划分效果。决策树构造涉及特征选择、生成和裁剪,常见的决策树类型如ID3、C4.5和CART,它们在特征选择时分别依据信息增益、信息增益比和基尼指数。剪枝是防止过拟合的重要步骤,包括预剪枝和后剪枝策略。
决策树是一种有监督的分类算法,分为离散性和连续性两种类型。概念包括熵、信息增益、信息增益比和基尼指数,用于评价特征划分效果。决策树构造涉及特征选择、生成和裁剪,常见的决策树类型如ID3、C4.5和CART,它们在特征选择时分别依据信息增益、信息增益比和基尼指数。剪枝是防止过拟合的重要步骤,包括预剪枝和后剪枝策略。
0 介绍
决策树是一个有监督分类与回归算法。 (本文只介绍分类,回归还没搞懂)
决策树:是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果,本质是一颗由多个判断节点组成的树。
决策树的分类:主要取决于目标变量的类型。
- 离散性决策树:离散性决策树,其目标变量是离散的,如性别:男或女等;
- 连续性决策树:连续性决策树,其目标变量是连续的,如工资、价格、年龄等;
决策树的变量可以有两种:
1) 数字型(Numeric):变量类型是整数或浮点数,如前面例子中的“年收入”。用“>=”, “>”,“<”或“<=”作为分割条件
(排序后,利用已有的分割情况,可以优化分割算法的时间复杂度)。
2) 名称型(Nominal):类似编程语言中的枚举类型,变量只能重有限的选项中选取,比如前面例子中的“婚姻情况”,只能是“单身”,“已婚”或“离婚”,使用“=”来分割。
1 概念
1. 熵
物理学上,熵 Entropy 是“混乱” 程度的量度。 系统越有序,熵值越低;系统越混乱或者分散,熵值越高
信息理论:
1、当系统的有序状态一致时,数据越集中的地方熵值越小,数据越分散的地方熵值越大。这是从信息的完整性上进行的描述。
2、当数据量一致时,系统越有序,熵值越低;系统越混乱或者分散,熵值越高。这是从信息的有序性上进行的描述。
假如事件A的分类划分是,每部分发生的概率是
,那信息熵定义为公式如下:

2. 信息增益
信息增益为以某特征划分数据集前后的熵的差值。使用划分前后集合熵的差值来衡量使用当前特征对于样本集合D划分效果的好坏。
 (ID3, 信息增益最大作为最优特征)
(ID3, 信息增益最大作为最优特征)
D:为样本集,Ent(D):整体熵
a:离散型属性, v: 是a属性里可能的取值节点:第v个分支节点包含了D中所有在属性a上取值为a\^v的样本
缺点:信息增益偏向取值较多的特征(原因:当特征的取值较多时,根据此特征划分更容易得到纯度更高的子集,因此划分后的熵更低,即不确定性更低,因此信息增益更大)
3. 信息增益比
定义:特征A对训练数据集D的信息增益比定义为其信息增益
与训练数据集D的经验熵之比:

其中, 
信息增益比本质: 信息增益的基础乘上一个惩罚参数。特征个数较多时,惩罚参数较小;特征个数较少时,惩罚参数较大。
缺点:信息增益比偏向取值较少的特征
原因: 当特征取值较少时的值较小,因此其倒数较大,因而信息增益比较大。因而偏向取值较少的特征
使用信息增益比(例:C4.5):基于以上缺点,并不是直接选择信息增益率最大的特征,而是现在候选特征中找出信息增益高于平均水平的特征,然后在这些特征中再选择信息增益率最高的特征
4. 基尼指数
分类问题中,假设有K个类,样本点属于第k类的概率为,则概率分布的基尼指数定义为:

备注:表示选中的样本属于k类别的概率,则这个样本被分错的概率为
。
基尼值:从数据集D中随机抽取两个样本,起类别标记不一致的概率,故,
值越小,数据集D的纯度越高,
基尼指数值越大,样本集合的不确定性也就越大。
对于给定的样本集合D,其基尼指数为:(选择使划分后基尼系数最小的属性作为最优化分属性)
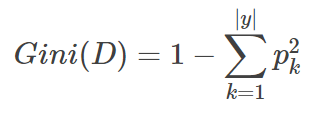 , |y|是类的个数。
, |y|是类的个数。
在特征A的条件下,集合D的基尼指数定义为:
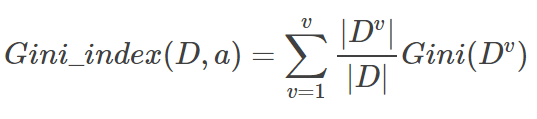 ( CART,基尼指数最小的作为最优特征)
( CART,基尼指数最小的作为最优特征)
5. 基尼增益: (样本集合D的基尼指数-在特征A的条件下的集合D的基尼指数)
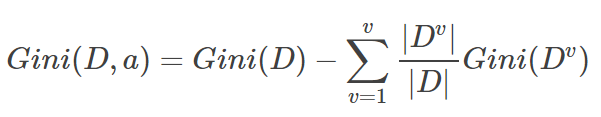
2 决策树的构造
决策树的构造过程一般分为3个部分,分别是特征选择、决策树生成和决策树裁剪。
(1)特征选择:
特征选择表示从众多的特征中选择一个特征作为当前节点分裂的标准,如何选择特征有不同的量化评估方法,从而衍生出不同的决策树,如ID3(通过信息增益选择特征)、C4.5(通过信息增益比选择特征)、CART(通过Gini指数选择特征)等
目的(准则):使用某特征对数据集划分之后,各数据子集的纯度要比划分钱的数据集D的纯度高。
(2)决策树的生成
根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止生长。
(3)决策树的裁剪
决策树容易过拟合,一般需要剪枝来缩小树结构规模、缓解过拟合。
3.常见的决策树类型

ID3算法实现步骤:
输入:训练数据集D,特征集A,阈值ε;
输出:决策树T.
Step1:若D中所有实例属于同一类![]() ,则T为单结点树,并将类
,则T为单结点树,并将类![]() 作为该节点的类标记,返回T;
作为该节点的类标记,返回T;
Step2:若A=Ø,则T为单结点树,并将D中实例数最大的类![]() 作为该节点的类标记,返回T;
作为该节点的类标记,返回T;
Step3:否则,2.1.1(3)计算A中个特征对D的信息增益,选择信息增益最大的特征![]() ;
;
Step4:如果![]() 的信息增益小于阈值ε,则T为单节点树,并将D中实例数最大的类
的信息增益小于阈值ε,则T为单节点树,并将D中实例数最大的类![]() 作为该节点的类标记,返回T
作为该节点的类标记,返回T
Step5:否则,对![]() 的每一种可能值
的每一种可能值![]() ,依
,依![]() 将D分割为若干非空子集
将D分割为若干非空子集![]() ,将
,将![]() 中实例数最大的类作为标记,构建子结点,由结点及其子树构成树T,返回T;
中实例数最大的类作为标记,构建子结点,由结点及其子树构成树T,返回T;
Step6:对第i个子节点,以![]() 为训练集,以
为训练集,以![]() 为特征集合,递归调用Step1~step5,得到子树
为特征集合,递归调用Step1~step5,得到子树![]() ,返回
,返回![]() ;
;
举例:
如下图,第一列为论坛号码,第二列为性别,第三列为活跃度,最后一列用户是否流失(1,流失==positive)。
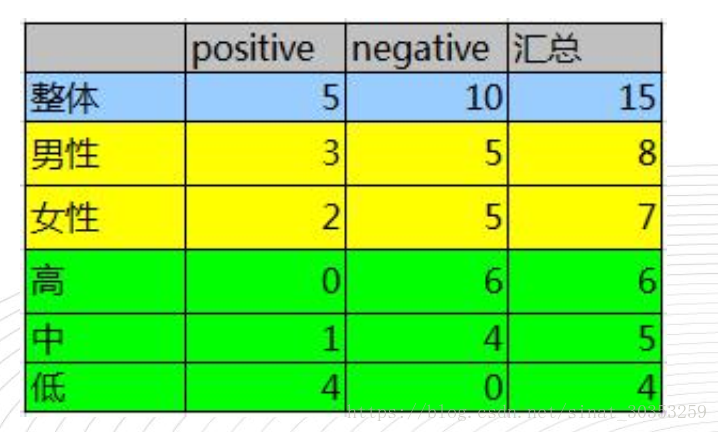
1)整体熵:![]()
性别熵:![]()
![]()
性别信息增益:![]()
活跃度熵:E(a1) =0, E(a2) = 0.7219 , E(a3) = 0
活跃度信息增益: ![]()
ID3 结论:活跃度的信息增益比性别的信息增益大,即活跃度对用户流失的影响比性别大。在做特征选择或者数据分析的时候, 我们应该先考察活跃度这个指标。
2) 性别信息增益比:
活跃度信息增益比:
C4.5 结论:活跃度信息增益高于平均水平(性别信息增益低于平均水平,从高于平均增益的特征中选择增益比最高的特征),在两个特征中,先考察活跃度这个指标。
3) 给定的样本集合D,其基尼指数
特征 性别的条件下,集合D的基尼指数为:
特征 活跃度的条件下,集合D的基尼指数为:
CART 结论:活跃度的基尼指数比性别的基尼指数小,在做特征选择或者数据分析的时候, 我们应该先考察活跃度这个指标。
4. 剪枝
1)为什么要剪枝:
随着树的增长, 在训练样集上的精度是单调上升的,然而在独立的测试样例上测出的精度先上升后下降。
- 原因1: 噪声、 样本冲突, 即错误的样本数据。
- 原因2: 特征即属性不能完全作为分类标准。
- 原因3: 巧合的规律性, 数据量不够大。
2)常用的剪枝方法:
预剪枝:
(1)每一个结点所包含的最小样本数目,例如10,则该结点总样本数小于10时,则不再分;
(2)指定树的高度或者深度,例如树的最大深度为4;
(3)指定结点的熵小于某个值,不再划分。随着树的增长, 在训练样集上的精度是调上升的, 然而在独立的测试样例上 测出的精度先上升后下降。
后剪枝:在已生成过拟合决策树上进行剪枝,可以得到简化版的剪枝决策树。
(1)REP-错误率降低剪枝
(2)PEP-悲观剪枝
(3)CCP-代价复杂度剪枝
(4)MEP-最小错误剪枝
3)结论:
决策树的剪枝,由于生成的决策树存在过拟合问题,需要对它进行剪枝,以简化学到的决策树。决策树的剪枝,往往从已生成的树上剪掉一些叶节点或叶节点以上的子树,并将其父节点或根节点作为新的叶节点,从而简化生成的决策树模型。
(ID3不能剪枝,C4.5和CRAT都可以剪枝??)
参考:机器学习之-常见决策树算法(ID3、C4.5、CART)

















 9205
9205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









