






目录
前言
面试过程中,项目相关的问题因人而异,本帖重点记录在面试过程中遇到的算法/场景题/八股。
腾讯微信小店(一面挂)
很尴尬,面试官全程问项目,深挖项目的算法实现细节,由于对这部分了解不够透彻,问完感觉基本就无了。临了最终还考察了一个场景题,感觉还是挺有意义的,分享一下:
假设已有十万个二叉树,每个二叉树的节点都是一个byte值,在给一个新的二叉树,如何快速判断新的二叉树是否在已有的树里出现过?(特地强调:不需要考虑数据分片、分布式计算等方案...在单机情况下提出解决方案)
一听完题,首先我就想到了用数组来编码表达二叉树,因为二叉树 先/中/后 序遍历都是一个固定的数组顺序。但其实由于每个节点是一个byte,可以更进一步用位图BitMap的形式表达,内存更紧凑,更有利于节省内存(临场发挥太紧张了,这块没表达出来)
位图是什么?参考:位图算法:什么是BitMap - 程序员自由之路 - 博客园
那具体如何编码呢?这里有两种表达形式,但都存在一定问题
(1)以满二叉树的形式进行转换
即最深层节点数量为2^(n-1),编码后的结果数组长度=2^n−1,n是二叉树的深度。
例:
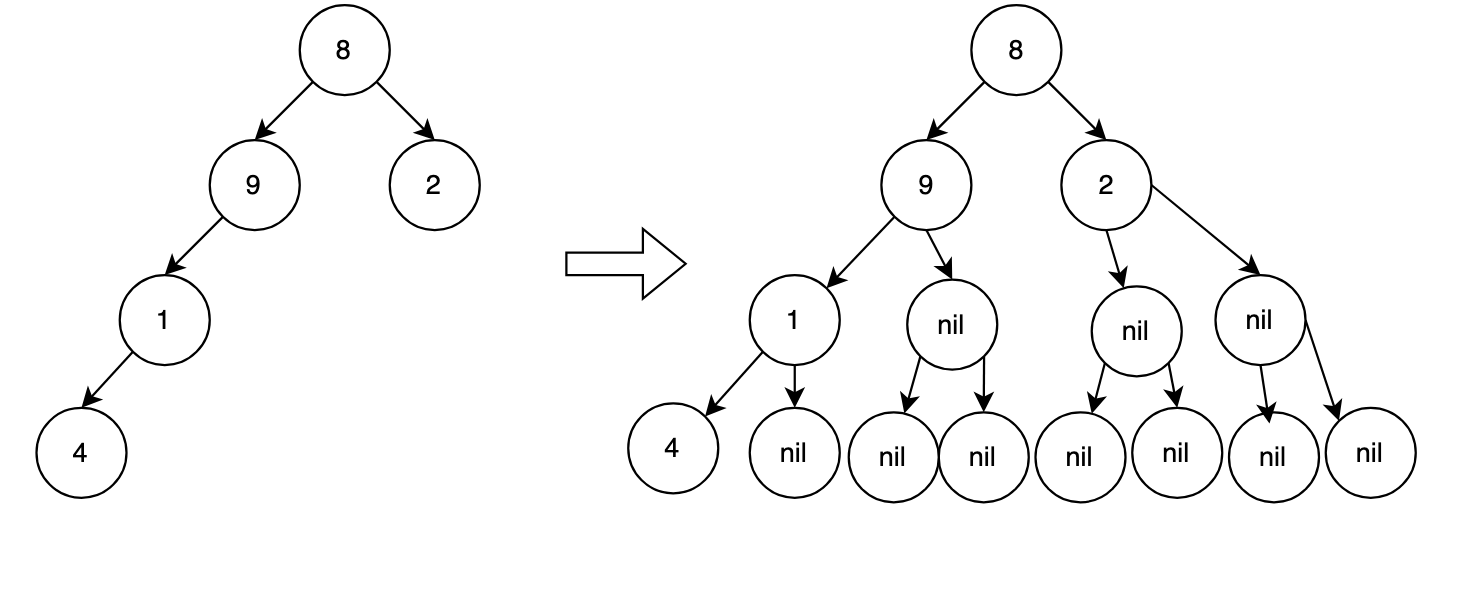
深度为4,数组长度为2^4-1=15,编码结果为(这里用0表示nil节点):
【8,9,1,4,0,0,0,0,2,0,0,0,0,0,0】
可以看到数组非常稀疏,冗余存储了大量的nil(0)元素,浪费了大量的内存。
(2)忽略二叉树中为空的节点二叉树,直接转换。
但这样对吗?以先序遍历将树转换成数组为例,考虑如下情况,针对两个结构不同的二叉树,却会得出一样的结果:【8,9,1,4,2】
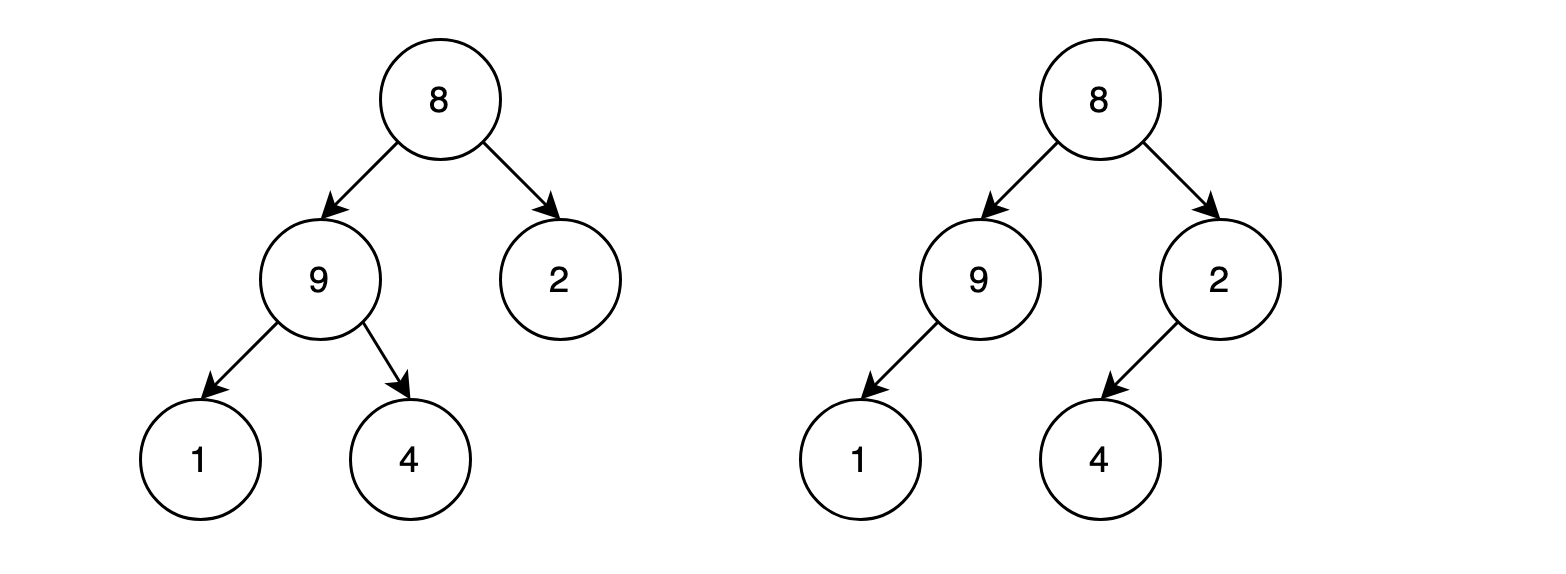
究其原因,是因为我们丢失了节点所在的位置信息,如果将位置信息一起保存下来,原本1*N的结果数组将是如下的2*N的结果数组。
我们将根节点编号为 1,对于编号为i的节点,其左子节点编号为2i,右子节点编号为2i+1,可以得到:
第一棵树:[[1,8],[2,9],[3,2],[4,1],[5,4]]
第二棵树:[[1,8],[2,9],[3,2],[4,1],[6,4]]
如果按以上方案二编码完成了,如何存储这么多个2*N的数组呢,并且实现快速定位呢?
我第一时间想到二叉堆,将每个2*N的数组作为二叉堆的节点,输入新的二叉树编码后直接进入二叉堆查找.....但其实问题只让定位是否存在,而不是要查找精确值或者最接近目标的值。因此这里只需要对每个2*N的数组进行hash编码即可,参考各大语言的hashmap实现,使用散列表形式,如果有冲突使用链表解决,最终构建出一个hashmap,这样即可实现O(1)的查询复杂度。
(3)直接遍历二叉树进行字符串编码
既然我们最终使用了hash编码,其实节点的值以及位置信息对查找结果来说帮助并不大,可以对每个二叉树进行遍历,编码成字符串,再进行hash即可,如下编码使用#代替空节点。
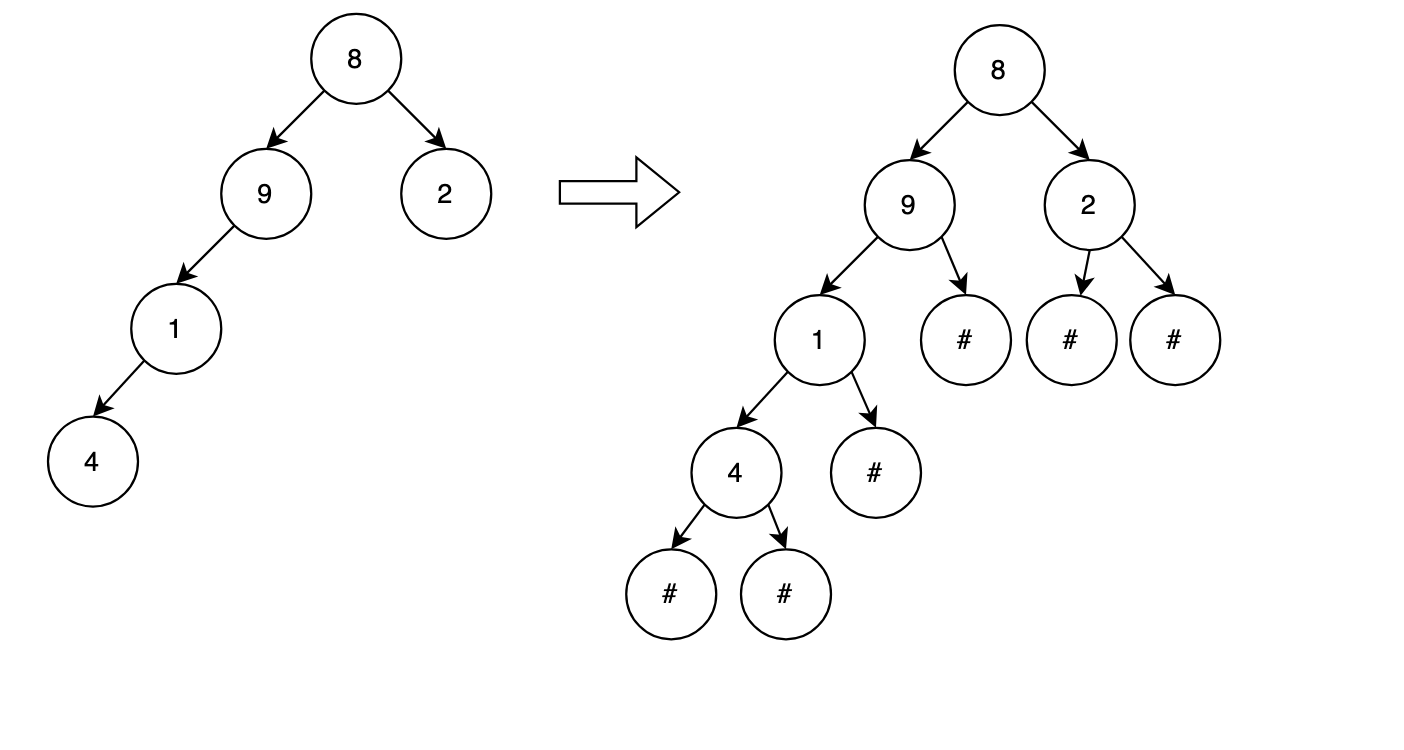
示例结果:"8914####2##"
package main
import (
"crypto/sha256"
"encoding/hex"
"fmt"
)
// TreeNode 定义二叉树节点结构
type TreeNode struct {
Val int
Left *TreeNode
Right *TreeNode
}
// preorderHash 先序遍历二叉树并生成哈希值
func preorderHash(root *TreeNode) string {
var preorderStr string
var preorder func(node *TreeNode)
preorder = func(node *TreeNode) {
if node == nil {
preorderStr += "#"
return
}
preorderStr += fmt.Sprintf("%d", node.Val)
preorder(node.Left)
preorder(node.Right)
}
preorder(root)
hash := sha256.Sum256([]byte(preorderStr))
return hex.EncodeToString(hash[:])
}
func main() {
// 假设已有十万个二叉树,存储在 trees 切片中
var trees []*TreeNode
// 这里省略了生成十万个二叉树的代码
// 存储已有二叉树的哈希值
hashSet := make(map[string]bool)
for _, tree := range trees {
treeHash := preorderHash(tree)
hashSet[treeHash] = true
}
// 新的二叉树
newTree := &TreeNode{
Val: 1,
Left: &TreeNode{
Val: 2,
},
Right: &TreeNode{
Val: 3,
},
}
// 判断新的二叉树是否在已有的树里出现过
newTreeHash := preorderHash(newTree)
if _, exists := hashSet[newTreeHash]; exists {
fmt.Println("新的二叉树在已有的树里出现过")
} else {
fmt.Println("新的二叉树不在已有的树里出现过")
}
}
富途(已OC)
待补充
字节番茄(一面挂)
最近两年第一场面试,挂在八股准备不充分。
算法
字节数据中台(一面挂)
依旧挂在项目,面试官不认可难点和挑战点。
算法
八股
略
字节供应链(一面挂)
这次准备比较充分,场景八股全答上来了,出了道简单的算法题也秒了,但怀疑是kpi面,第二天收到被挂的短信,问hr反馈匹配度横向对比挂了,呵呵了...
算法题:汽水的价格是2块钱一瓶,2个瓶盖能换一瓶汽水,4个空瓶也能换一瓶汽水,请问10块钱最多能喝多少瓶汽水?
这里贴出豆包给的答案:
package main
import (
"fmt"
)
func maxBottles(money int) int {
totalBottles := 0
caps := 0
emptyBottles := 0
// 初始购买
boughtBottles := money / 2
totalBottles += boughtBottles
caps += boughtBottles
emptyBottles += boughtBottles
for caps >= 2 || emptyBottles >= 4 {
// 用瓶盖换汽水
capExchangedBottles := caps / 2
totalBottles += capExchangedBottles
caps = caps % 2 + capExchangedBottles
emptyBottles += capExchangedBottles
// 用空瓶换汽水
bottleExchangedBottles := emptyBottles / 4
totalBottles += bottleExchangedBottles
emptyBottles = emptyBottles % 4 + bottleExchangedBottles
}
return totalBottles
}
func main() {
money := 10
result := maxBottles(money)
fmt.Printf("10块钱最多能喝 %d 瓶汽水\n", result)
}


















 1548
1548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









