







 本文深入解析Java关键字如instanceof、transient、volatile的功能,探讨Java内存模型、volatile禁止指令重排序的原理,详解变量命名规则、基本数据类型及包装类型。同时,文章还介绍了Java中的几种运算符、排序算法、数组操作、override与overload的区别,以及static关键字的理解和应用,全面覆盖Java内部类的使用,抽象类与接口的区别,方法重写的注意事项,异常处理方式,HashMap与Hashtable的对比,序列化的实现方法,hashcode的作用等核心知识点。
本文深入解析Java关键字如instanceof、transient、volatile的功能,探讨Java内存模型、volatile禁止指令重排序的原理,详解变量命名规则、基本数据类型及包装类型。同时,文章还介绍了Java中的几种运算符、排序算法、数组操作、override与overload的区别,以及static关键字的理解和应用,全面覆盖Java内部类的使用,抽象类与接口的区别,方法重写的注意事项,异常处理方式,HashMap与Hashtable的对比,序列化的实现方法,hashcode的作用等核心知识点。
最新公司没什么活,今天项目经理找了一些基础的面试题,下面我把自己回答整理的答案分享一下,可能回答的不够全面,大佬多包涵。
说说以下java关键字的含义
isntanceof trainsient volatile
instanceof:用于判断一个类是否为另一个的实例,或直接或间接子类,或者是其接口的实现类
trainsient : 对象如果标注此属性,那么对象在序列化是会忽略此属性
volatile:保证内存可见性,保证数据从主存中加载,但并不保证原子性。禁止指令重排序
java 内存模型
JMM决定一个线程对共享变量的写入何时对另一个线程可见,JMM定义了线程和主内存之间的抽象关系:共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),本地内存保存了被该线程使用到的主内存的副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存中的变量。
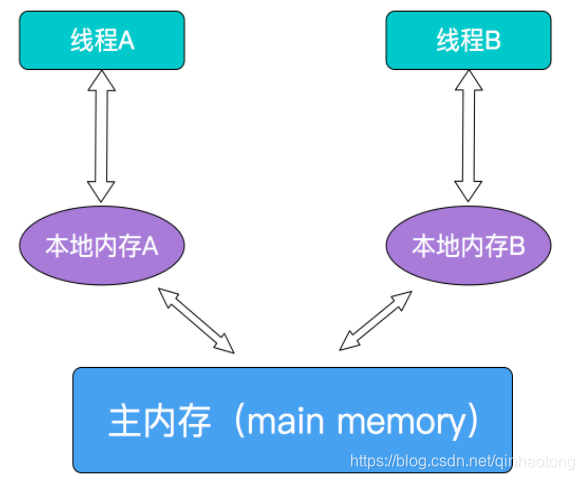
对于普通的共享变量来讲,线程A将其修改为某个值发生在线程A的本地内存中,此时还未同步到主内存中去;而线程B已经缓存了该变量的旧值,所以就导致了共享变量值的不一致。解决这种共享变量在多线程模型中的不可见性问题,较粗暴的方式自然就是加锁,但是此处使用synchronized或者Lock这些方式太重量级了,比较合理的方式其实就是volatile。
需要注意的是,JMM是个抽象的内存模型,所以所谓的本地内存,主内存都是抽象概念,并不一定就真实的对应cpu缓存和物理内存
volatile 禁止指令重排序
volatile经典的禁止,指令重排的案例就是,双重检测锁的单例模式的实现。
private volatile Singleton instance;
public static Singleton getInstance()
{
if (instance == null)
{
synchronized(Singleton.class) { //1
if (instance == null) //2
instance = new Singleton(); //3
}
}
return instance;
}
实例化一个对象其实可以分为三个步骤:
(1)分配内存空间。
(2)初始化对象。
(3)将内存空间的地址赋值给对应的引用。
但是由于操作系统可以对指令进行重排序,所以上面的过程也可能会变成如下过程:
(1)分配内存空间。
(2)将内存空间的地址赋值给对应的引用。
(3)初始化对象
如果乱序执行,则可能返回“半个实例”
说说java变量的命名规则
方法名首字母小写,如果名称由多个单词组成,每个单词的首字母都要大写,不能以数字开头
说说java中的基本数据类型及其对应的包装类型
byte,short,int,long,boolean,float,double,char;
对应的包装类为,Byte,Short,Integer,Long,Boolean,Float,Double,Character
包装类型的使用都应该使用equals方法 ,拿integer为例,在装箱过程中,如果数值在-128 到 127 之间会从缓存中获取,这样造成在缓存数值范围内是可以通过 == 判断,超出则无法通过 == 判断
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
说说如下注释使用的地方
// /* / /* */ <%-- --> – #
// java中的注释,常用于方法内临时简短的说明
/**/ java中的注释,用于多行注释
/***/ java中的注释,多用于解释方法,类说明,可生成javadoc
<!---- > html 注释,xml注释
<% ----> jsp 页面注释
– sql中注释
# shell注释,常见软件的 .conf 等配置文件中的注释
说说java中的几种运算符,以及运算符之间的优先级
加括号的优先(个人感觉没必要记)
常见的排序算法,手写冒牌排序
public static void sort(int[] a) {
int i,j,temp;
for(i=0;i<a.length;i++){
for(j=i+1;j<a.length;j++){
if (a[i]>a[j]) {
temp=a[i];
a[i]=a[j];
a[j]=temp;
}
}
}
}
数组初始化的几种方式,数组的扩容,数组的复制
-
动态初始化
int[] a = new int[100]; for(int i = 0;i<a.length;i++){ a[i] = i; } -
静态初始化
int[] a = {1,2,3}; int[] a = new int[] {1,2,3};
什么是override,什么是overload,有何区别
override:(1)方法名、参数、返回值相同。 (2)子类方法不能缩小父类方法的访问权限。 (3)子类方法不能抛出比父类方法更多的异常(但子类方法可以不抛出异常)。 (4)存在于父类和子类之间。 (5)方法被定义为final不能被重写。 (6)被覆盖的方法不能为private,否则在其子类中只是新定义了一个方法,并没有对其进行覆盖。
overload:(1)参数类型、个数、顺序至少有一个不相同。 (2)不能重载只有返回值不同的方法名。
int a = 0; 那么 ++a + a++ + ++a + a 结果是多少
结果等于8;++a + a++ + ++ a + a 第一个 ++a,a先++然后在运算,此时 a = 1, 第二个 a++,先运算后++,++ 后 a = 2,第三个 ++ a,先++ 后运算,运算完成后 a = 3, 第四个 a 此时 a = 3;
1 + 1 + 3 + 3 = 8;
实例化一个对象过程中,说一说父类、子类中都做了些什么事。
- JVM会读取指定的路径下的.class文件,并加载进内存,且会先加载Person的父类(如果有直接父类的情况下)。
- 在堆内存地址中开辟空间并分配地址。
- 在对象空间中,对对象中的属性进行默认初始化。(基本类型,引用类型赋值null)
- 调用对应的构造函数进行初始化。
- 在构造函数的第一行,先调用父类中的构造函数进行初始化。
- 父类初始化完毕后,再对子类的属性进行显示初始化。
- 进行子类构造函数的特定初始化。
- 将地址值赋给引用变量。
说说你对static关键字的理解
在类中,用static声明的成员变量为静态成员变量,也称为类变量。类变量的生命周期和类相同,在整个应用程序执行期间都有效。
- static修饰的成员变量和方法,从属于类
- 普通变量和方法从属于对象
- 静态方法不能调用非静态成员,编译会报错.
static关键字的用途
- static 修饰方式方法:static方法也成为静态方法,由于静态方法不依赖于任何对象就可以直接访问
- static 变量:静态变量被所有对象共享,在内存中只有一个副本,在类初次加载的时候才会初始化,非静态变量是对象所拥有的,在创建对象的时候被初始化,存在多个副本,各个对象拥有的副本互不影响
- static块:静态代码块,在类加载后执行执行一次,在静态初始化块中不能直接访问非staic成员。
说说Java中的内部类
内部类可以分为,成员内部类,静态内部类,局部内部类,匿名内部类
- 成员内部类
public class InnerClass {
private String name = "name";
class Inner{
public void test(){
// 可以访问外部私有变量
System.out.println(name);
}
}
public static void main(String[] args) {
// 创建成员内部类,成员内部类依赖于外部类存在
InnerClass.Inner i = new InnerClass().new Inner();
}
}
- 局部内部类
public class InnerClass {
private String name = "name";
public String test() {
// 局部内部类可以访问外部变量
// 局部内部类访问,方法内的变量,必须声明为final
int a = 10;
class T {
public String t1() {
// a = 20;
System.out.println(name);
sout(a);
return "hello " + name;
}
}
return new T().t1();
}
public static void main(String[] args) {
InnerClass innerClass = new InnerClass();
System.out.println(innerClass.test());
}
}
- 匿名内部类
// 最典型的匿名内部类,一次性使用,无法创建匿名内部类的实例,便捷给出某个接口的实现.
// 在匿名内部类中,访问局部变量,局部变量需要声明为final
int a = 10;
new Thread(new Runnable() {
@Override
public void run() {
sout(a);
}
}).start();
- 静态内部类
public class InnerClass {
private String name = "name";
private static int age = 18;
static class T{
public void test(){
// System.out.println(name);
System.out.println(age);
}
}
public static void main(String[] args) {
InnerClass.T t = new InnerClass.T();
}
}
静态内部类,单例懒加载
public class SingleDemo {
//单实例作为静态内部类的成员变量
private static class SingleDemoInstance{
private static final SingleDemo single = new SingleDemo();
}
//
public static SingleDemo getSingle() {
return SingleDemoInstance.single;
}
//私有构造器
private SingleDemo() {}
}
说说抽象类和接口的区别
- 接口和抽象类的区别
- 抽象类要被子类继承,接口要被类实现。
- 接口只能做方法声明,抽象类中可以做方法声明,也可以做方法实现
- 接口里定义的变量只能是公共的静态的常量(public static final),抽象类中的变量是普通变量
- 抽象类里可以没有抽象方法
- 抽象方法要被实现,所以不能是静态的,也不能是私有的。
- 接口可继承接口,并可多继承接口,但类只能单根继承。
- 抽象类里的抽象方法必须全部被子类所实现,如果子类不能全部实现父类抽象方法,那么该子类只能是抽象类。同样,实现一个接口的时候,如不能全部实现接口方法,那么该类也只能为抽象类。
在java8中可以在接口中定义默认方法,默认方法可以在接口中实现,也可以在接口中定义静态方法,
public interface DefaultInterface {
default String getName() {
return "haha";
}
public static String getAge() {
return "aaa";
}
}
但这就带来一个问题,如果一个类继承一个类和实现一个接口之间,继承类的方法和实现的默认方法冲突,如何解决,它默认调用的是继承类的方法,类优先 那如果实现两个接口,两个接口的默认方法冲突呢,那必须显示的重写选定一个接口的默认方法
方法重写时需要注意什么
-
重写方法的方法名和参数列表要和被重写方法一致。
-
在 java 1.4版本以前,重写方法的返回值类型被要求必须与被重写方法一致,但是在java 5.0中放宽了这一个限制,添加了对协变返回类型的支持,在重写的时候,重写方法的返回值类型可以是被重写方法返回值类型的子类。但是,对于基本数据类型,由于它们不是类,所以不能实现协变返回类型,但是使用对应的包装类则可以。
-
重写方法不能使用比被重写方法更严格的权限,即重写方法的权限要大于或者等于被重写方法的权限。
// 错误示例
class A{
public Object test(){
return null;
}
}
class B extends A{
private String test(){
return null;
}
}
什么叫向上造型,什么叫向下造型
向上造型:父类引用指向子类对象。
Animal a = new Dog();
向下造型:逆向操作,将父类引用的对象,强制转换为具体的子类对象。
Animal a = new Dog();
if(a instanceof Dog){
Dog b = (Dog)a
}
Java中有几种处理异常的方式,说说try catch时需要注意什么
异常的大致结构,所有的异常都继承自Throwable,在遇到异常时,可以显示的try catch 或者 throw 交给上层处理
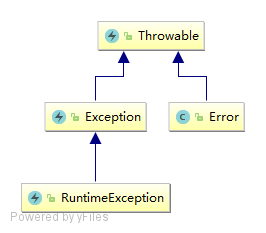
Error:Error类以及他的子类的实例,代表了JVM本身的错误。错误不能被程序员通过代码处理,Error很少出现。因此,程序员应该关注Exception为父类的分支下的各种异常类。
Exception:Exception以及他的子类,代表程序运行时发送的各种不期望发生的事件。可以被Java异常处理机制使用,是异常处理的核心。
finally
finally块不管异常是否发生,只要对应的try执行了,则它一定也执行。只有一种方法让finally块不执行:System.exit()。因此finally块通常用来做资源释放操作:关闭文件,关闭数据库连接等等。
public static int fun()
{
int i = 10;
try
{
return i;
}catch(Exception e){
return i;
}finally{
i = 20;
}
}
返回值为10
public static StringBuilder fun() {
StringBuilder s = new StringBuilder("Hello");
try {
//doing something
s.append("Word");
return s;
} catch (Exception e) {
return s;
} finally {
s.append("finally");
}
}
返回值helloworldfinally,
一个方法的返回值,就一个位置。 例子一中return i;返回的一个具体的数值,返回值已经写入内存,finally中修改的i并不会影响返回的i; 例而二中返回的是引用,所以finally有修改了 stringBuilder的值
从处理层面来说,异常可以分为两类,UncheckedException,CheckedException
非检查异常(unckecked exception):Error 和 RuntimeException 以及他们的子类。javac在编译时,不会提示和发现这样的异常,不要求在程序处理这些异常。所以如果愿意,我们可以编写代码处理(使用try…catch…finally)这样的异常,也可以不处理。对于这些异常,我们应该修正代码,而不是去通过异常处理器处理 。这样的异常发生的原因多半是代码写的有问题。如除0错误ArithmeticException,错误的强制类型转换错误ClassCastException,数组索引越界ArrayIndexOutOfBoundsException,使用了空对象NullPointerException等等。
检查异常(checked exception):除了Error 和 RuntimeException的其它异常。javac强制要求程序员为这样的异常做预备处理工作(使用try…catch…finally或者throws)。在方法中要么用try-catch语句捕获它并处理,要么用throws子句声明抛出它,否则编译不会通过。这样的异常一般是由程序的运行环境导致的。因为程序可能被运行在各种未知的环境下,而程序员无法干预用户如何使用他编写的程序,于是程序员就应该为这样的异常时刻准备着。如SQLException , IOException,ClassNotFoundException 等。
写一个身份证号码的正则表达式
^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]
\d{5}:后面跟着5位任意数字 40411
(18|19|([23]\d)):匹配 18-23
\d{2}:年的两位数字
连接一下正则表达式的基础知识
Java的substring方法和js的substr有何区别
java中的substring(int beginIndex, int endIndex)
js中的substring(int beginIndex,int length)
将当前时间转换为yyyy-MM-ddHH:mm:ss格式,将一天后的现在也转为这种格式
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date date = new Date();
System.out.println(simpleDateFormat.format(date));
Calendar calendar = Calendar.getInstance();
calendar.setTime(date);
calendar.add(Calendar.DAY_OF_MONTH,1);
Date date2 = new Date(calendar.getTimeInMillis());
System.out.println(simpleDateFormat.format(date2));
java8中的日期用法,旧的时间API是线程不安全,新的时间API的线程安全的不可变的,统一在在time包下
LocalDateTime now = LocalDateTime.now();
LocalDateTime nextDay = LocalDateTime.now().plusDays(1);
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
String format = now.format(dateTimeFormatter);
String format1 = nextDay.format(dateTimeFormatter);
System.out.println(format);
System.out.println(format1);
Map的put方法返回值是什么,remove方法的返回值是什么
hashMap中 put 方法的一处代码,如果key已经存在返回旧的value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
hashMap的remove方法返回是否删除成功,它的removeNode方法返回旧的节点。
public boolean remove(Object key, Object value) {
return removeNode(hash(key), key, value, true, true) != null;
}
removeNode方法
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
// 判断需要移除的node的散列点是否为null
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
// 声明变量,注意看node的复制
Node<K,V> node = null, e; K k; V v;
// 判断需要删除的是否为第一个节点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 如果需要删除的k,v与第一个节点的kv相同,node = p(需要删除节点)
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
// 直接获取hash,key对应的节点
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
// 如果链表结构循环查找对应的node
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
// 赋值为需要删除的node
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
// 返回删除的节点
return node;
}
}
return null;
}
作用域public,private,protected,以及不写时的区别
| 作用域 | 当前类 | 同一个包(package) | 子孙类 | 其他包(package) |
|---|---|---|---|---|
| public | ⚪ | ⚪ | ⚪ | ⚪ |
| protected | ⚪ | ⚪ | ⚪ | X |
| friendly | ⚪ | ⚪ | X | X |
| private | ⚪ | X | X | X |
&和&&的区别
&& 为 与 条件判断,区别在于 && 会短路,在判断条件一定false将不会去判断条件二
// condition == null 将不会执行 condtion.getValue... 保证 condition.getValue 不会报空指针
if(condition == null && "I love you".equals(condition.getValue()){
return "I hate you";
}
String s = new String(“xyz”);创建了几个String Object
两个。第一个对象是字符串常量"xyz" 第二个对象是new String()的时候产生的,在堆中分配内存给这个对象,只不过这个对象的内容是指向字符串常量"xyz" 另外还有一个引用s,指向第二个对象。这是一个变量,在栈中分配内存。
谈谈final, finally, finalize的区别
-
final为关键字,final定义基本类型变量时,要求变量初始化必须在声明时或者构造函数中,不能用于其它地方。该关键字定义的常量,除了初始化阶段,不能更改常量的值; final定义对象的引用,该引用的初始化与定义常量时的要求一致;该关键字定义的对象内容可以改变,但是引用指向的地址不能改变;final修饰类时无法被其他任何类继承。
-
**finalize()**方法在Object中进行了定义,用于在对象“消失”时,由JVM进行调用用于对对象进行垃圾回收。
-
finally为区块标志,用于try语句中,表示必须运行的区块部分。
-
谈谈String, StringBuilder, StringBuffer的区别
说出ArrayList,Vector, LinkedList的存储性能和特性
ArrayList:底层数据结构是数组,运行所有元素,包括null,查询快,增删慢,线程不安全(非同步),效率高!
Vector:底层数据结构是数组,查询快,增删慢,线程安全(同步),效率低~!
LinkedList:底层数据结构是链表,允许null元素,查询慢,增删快,线程不安全(非同步),效率高!
HashMap和Hashtable的区别
Hashtable继承自Dictionary类,而HashMap是Java1.2引进的Map interface的一个实现。
最大的不同是,Hashtable的方法是Synchronize的,而HashMap不是,在多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap 就必须为之提供外同步。
遍历map
Map<String,String> map = new HashMap<>();
// 获取key集合遍历
Set<String> strings = map.keySet();
// 获取value集合遍历
Collection<String> strings1 = map.values();
// 获取entry遍历,entry是map存储kv的结构
Set<Map.Entry<String, String>> entries = map.entrySet();
// 获取entry的迭代器遍历
map.entrySet().iterator();
// 使用java8的 forEach遍历
map.forEach((x,y)->{
});
什么是java序列化,如何实现java序列化?
java序列化,将一个对象转为二进制流,进行传输,或存储。
将一个类,序列化到文件中
ObjectOutputStream outputStream = null;
try {
outputStream = new ObjectOutputStream( new FileOutputStream("storePath"));
outputStream.writeObject(new Object());
outputStream.flush();
} catch (IOException e) {
e.printStackTrace();
}finally {
if(outputStream != null){
try {
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
反序列化
ObjectInputStream in = null;
try {
in = new ObjectInputStream(new FileInputStream("filePath"));
Object temp = in.readObject();
if(temp instanceof XXX){
// 类型判断,强制转换使用
}
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
} finally {
if(in != null){
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Hashcode的作用
1、hashCode的存在主要是用于查找的快捷性,如Hashtable,HashMap等,hashCode是用来在散列存储结构中确定对象的存储地址的;
2、如果两个对象相同,就是适用于equals(java.lang.Object) 方法,那么这两个对象的hashCode一定要相同;
3、如果对象的equals方法被重写,那么对象的hashCode也尽量重写,并且产生hashCode使用的对象,一定要和equals方法中使用的一致,否则就会违反上面提到的第2点;
4、两个对象的hashCode相同,并不一定表示两个对象就相同,也就是不一定适用于equals(java.lang.Object) 方法,只能够说明这两个对象在散列存储结构中,如Hashtable,他们“存放在同一个篮子里”。
HashMap的hashcode的作用
hashMap中使用对象的hashCode来进行散列,确定对象存储位置。
// hashMap的,确定对象存储位置所用的散列方法
static final int hash(Object key) {
int h;
// hash码前十六为与后十六位异或,这是为了随机的获取三劣质
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









