





一、前言
随着大模型的飞速进化和发展,越来越多的传统开发者开始关注和转向大模型开发。但是,由于大模型领域有着众多的专业术语和一堆名词概念,导致不具备AI背景知识,但是想利用大模型来进行开发的人摸不着头脑,刚开始容易懵逼。几个非常尴尬而又典型的灵魂拷问就是,既然是大模型开发,**那什么是大模型?大模型在哪?我怎么才能在代码中引入大模型?**这些问题看似简单,实在会者不难,难者不会。所以,今天今天这篇的目的就是为大家说清楚这些问题。
二、大模型是什么
关于“大模型是什么”这个问题,上一篇介绍大模型应用开发基础知识中就已经介绍过这些基础概念,不知道的朋友可以翻看一下之前的文章了解了解,这里就不再赘述。
三、大模型在哪
知道了大模型的概念,接下来随之而来的第二个问题就是,大模型在哪?
其实大家要知道,大模型其实就是一堆训练好的文件而已,并不神秘。既然是文件,那么我们想要使用大模型,就会有两个步骤。
步骤一、找到并下载这些模型文件到自己电脑上来。
步骤二、找个能读懂理解这些文件的工具,命令它为我们工作。
3.1 下载模型文件
接下来,我们先进行第一步,看看去哪找这些大模型文件。目前业界用得最多的两个找模型文件的网站分别是huggingface,地址是https://huggingface.co/
以及modelscope,地址是https://www.modelscope.cn/home,也被称为魔搭社区。
huggingface是全球大模型集散地,基本上所有机构、公司发布的最新模型都会公布在huggingface上。但针对国人有个比较尴尬的地方是需要科学上网访问,而且通常模型文件下载速度也非常慢。所以,如果是国内的话,比较推荐访问modelscope,你可以理解为它是huggingface的国内平替。
大家可以在这两个网站上看到很多很多各种各样的模型文件,包括大家熟悉的DeepSeek、千问等,凡是开源的都可以在上面找到模型文件。模型文件通常都比较大,动辄几个G几十上百G的都非常常见,所以下载模型文件也是一个比较费时的工作。
一般想下载模型到本地,都是为了在本地搭建自己的私有模型,然后再利用这些模型来工作。那么这些模型怎么才能用得起来呢?这就涉及到我们上面讲的步骤二了。
3.2 使用ollama框架
步骤二是找一个能读懂这些模型文件的工具来帮我们使用这些模型文件。目前有很多能使用模型文件的方法,除了使用python的pytorch库之外,也可以使用一些现成的工具,比如ollama、chatbox这些。本文就以常用的ollama为例来讲解如何使用模型框架工具来使用下载好的模型文件。
首先,我们需要下载并安装ollama这个框架。官网下载地址:https://ollama.com/。如果官网下载慢的同学,也可以关注本号发送消息“ollama”通过百度网盘获取安装包。
注意,ollama只能安装到默认位置C盘,无法更改安装位置。默认安装位置为:C:\Users\Administrator\AppData\Local\Programs\Ollama。
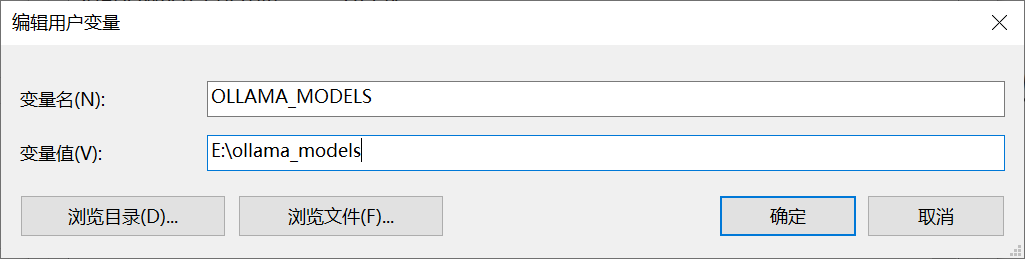
接下来,将ollama的安装路径配置到环境变量,并且将默认的模型文件下载位置配置到环境变量(模型文件一般比较大,配置模型文件位置可以避免ollama将模型文件下载到C盘)。配置模型文件下载位置的方式如下,在环境变量配置时,添加如下键值对。比如我就是放到E盘的ollama_models这个文件夹下。
ollama安装好之后,我们既可以使用ollama直接在线拉取指定模型文件,也可以直接使用已经下载好的模型文件。如果你的模型文件已经下载好了的话,直接把这个模型放在刚刚配置好的模型下载位置即可使用。如果之前没有下载模型文件,也可以直接用ollama来帮你下载模型文件。在ollama官网通过模型下载页面选择模型。比如想下载一个deepseek r1的模型文件,如下图所示:
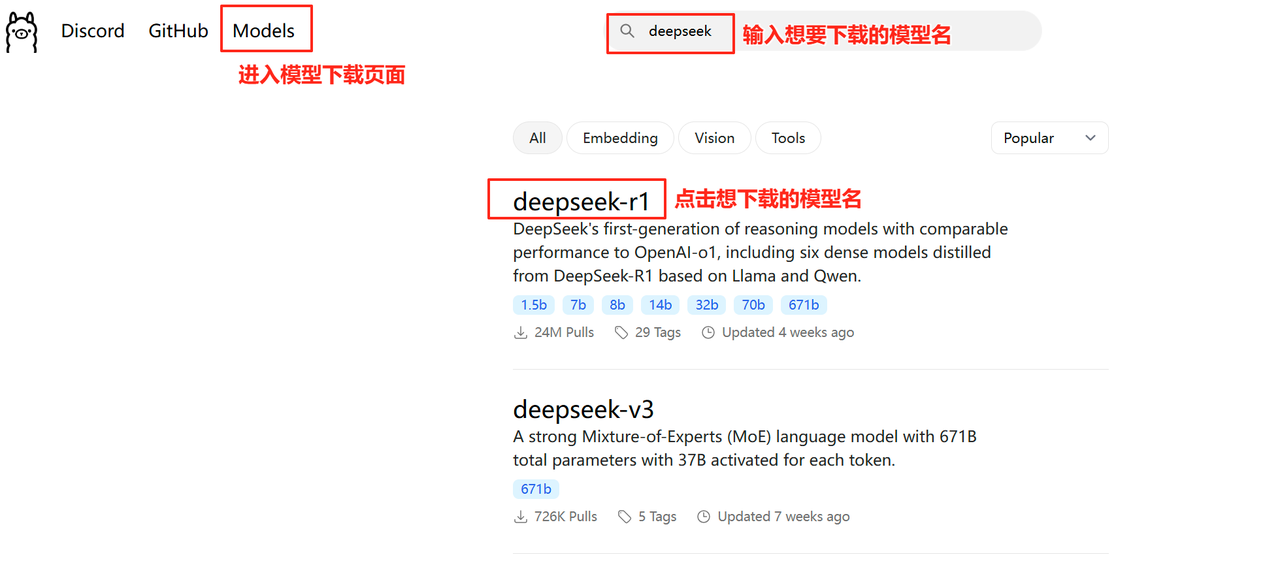
点击模型名之后,会跳转到下载模型命令的页面,如下图所示:
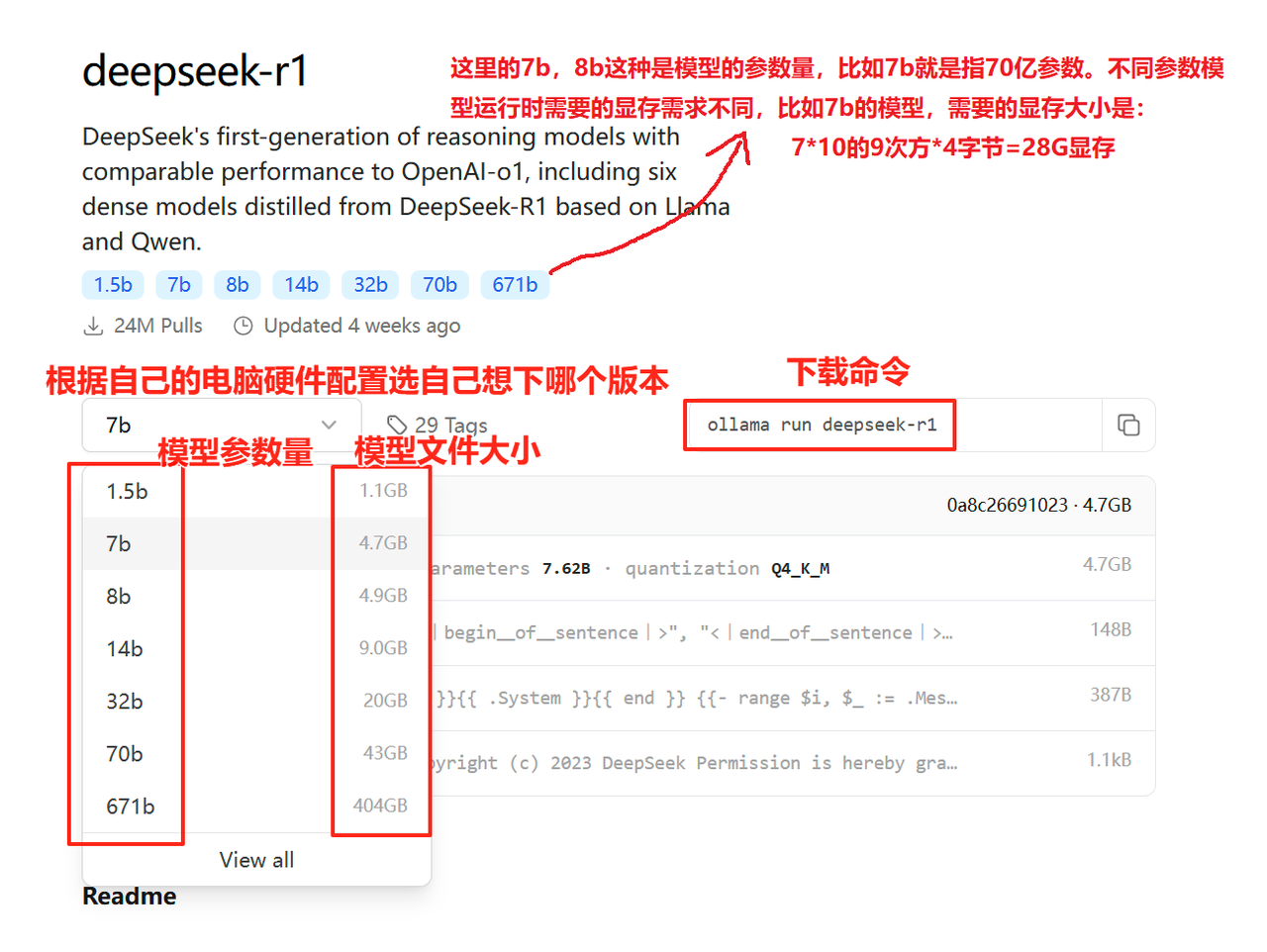
这里需要根据自己的电脑配置选择想下的版本,选好后,右边会出现对应的下载命令。接下来就可以进入下一步。
接下来,我们就可以启动ollama服务,将上一步中生成的下载命令直接拷贝过来,通过命令行下载模型文件。
ollama run deepseek-r1:8b
执行这个命令时,ollama会先检查本地有没有对应的模型文件,如果有就直接运行这个模型,如果没有,就下载对应的模型文件,非常简单。
下载完毕后,可以去之前定义的模型下载路径去检查模型是否下载完成了。一般会有这两个文件夹:

模型文件下载完毕后,如果要运行模型,则直接打开命令行运行ollama run的命令即可,就是第4步下载模型文件的命令。运行后,界面如下,默认是对话模式。
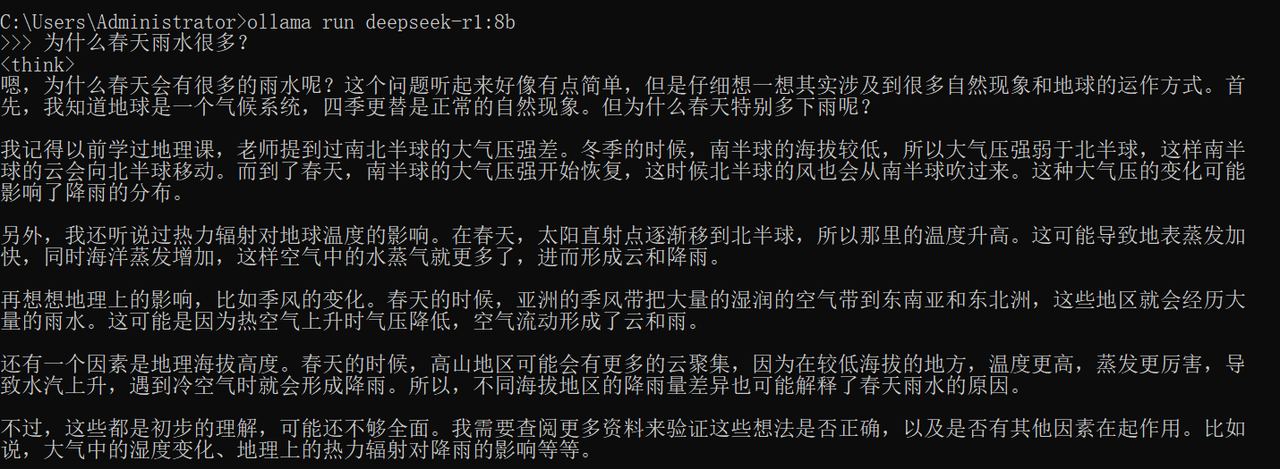
看到这里,很多新手已经想从入门到放弃了,好麻烦啊。其实还好,步骤看着多,一步一步耐心执行一遍就熟悉了,除了下载速度不太快之外,基本没有什么别的坑。当然,如果确实不想在本地搭建模型,也完全可以忽略以上所有步骤,咱们直接使用在线的大模型接口即可,效果完全一样甚至更好,适合大部分大模型应用开发者。
3.3 使用在线大模型
受限于大模型的算力资源要求,一般情况下个人电脑或服务器都无法部署真正的大参数模型。所以绝大多数情况下,真实业务场景下我们都需要通过调用远程云端模型API的方式来使用大模型进行应用开发。那么什么场景下应该使用本地模型,什么场景下应该使用在线模型呢?一般我们可以遵循以下原则:
- 如果不受资源限制,并且注重隐私,建议使用本地模型,一般适合大中型企业。
- 如果想快速上手,并且对成本不是很敏感,建议使用在线模型,一般适合个人开发者或小型团队。
接下来,我给大家介绍一些国内常用的在线大模型提供商,大家可以自己去熟悉一下即可。每个提供商都会在自己的模型信息页面上写清楚模型的相关信息及调用方法,大家照着样例代码写即可。
3.4 常见在线大模型平台
常见的大模型服务提供商基本都提供了大模型服务的API调用方式,这种方式基本上都是收费的,但基本上每个平台在注册时都会有免费的赠送额度,这些免费赠送额度对于初学者或者模型研究人员来说基本是足够的,所以不影响我们平时使用大模型的API。
接下来,我给大家介绍一些常见的在线模型平台,大家可以根据自己的实际情况来选择。
**阿里百炼:**https://bailian.console.aliyun.com/model-market#/model-market
**火山方舟:**https://console.volcengine.com/ark/region:ark+cn-beijing/model?feature=&vendor=Bytedance&view=LIST_VIEW
deepseek官网:https://api-docs.deepseek.com/zh-cn/
Moonshot开发平台:https://platform.moonshot.cn/docs/api/chat
智谱AI开放平台:https://open.bigmodel.cn/console/modelcenter/square
**硅基流动:**https://siliconflow.cn/zh-cn/models
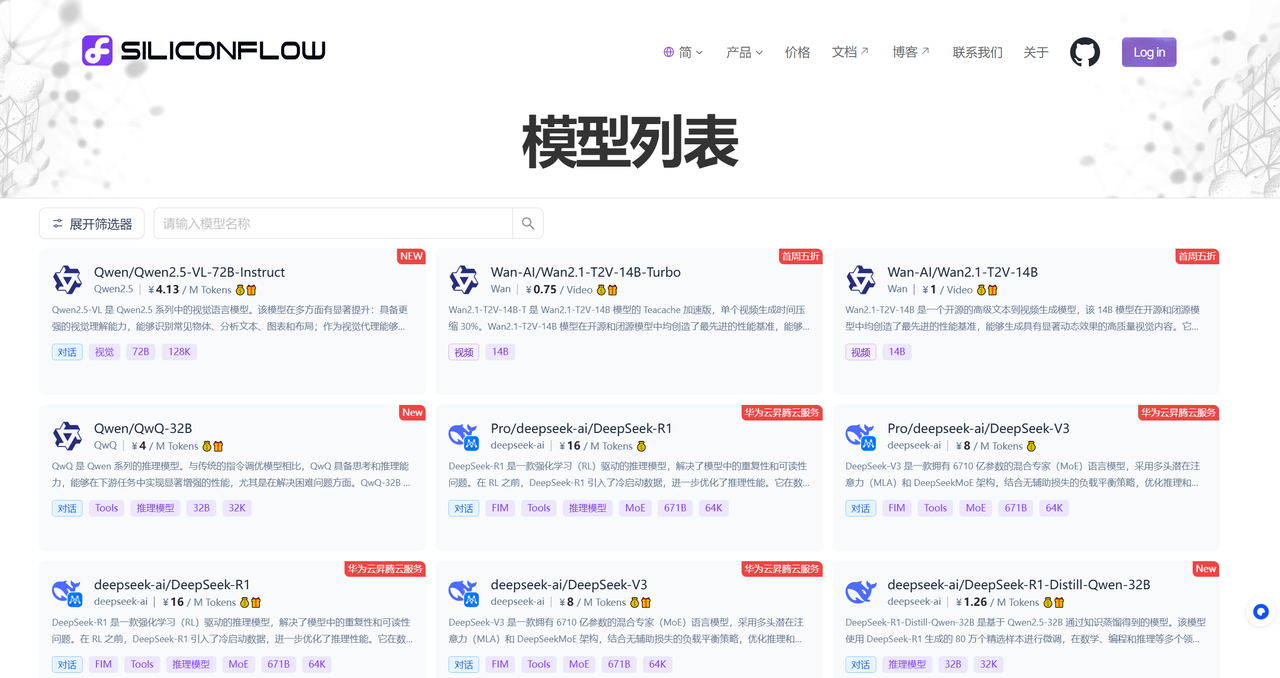
以上的模型服务商都是我们平时常用的平台,特别推荐阿里百炼、硅基流动以及智谱AI。这些平台大部分模型都有赠送的token,其中阿里百炼每个模型都有50w-100w不等的免费token额度,而且大部分每个月都送,学生学习和个人使用基本都够用了,基本不用花钱。
如何在代码中引入大模型
知道了本地模型搭建方式以及在线模型平台,最后一个问题,如何在代码中引入大模型,来完整真正的大模型应用开发工作呢?接下来我以常用的阿里百炼平台为例,讲解接入云端在线大模型的方法和步骤。其他平台的操作步骤基本类似,大家只要熟悉一个其他完全没有问题。
第一步,注册用户,申请API key
要使用平台,第一步当然是要注册用户了,这个不说了,注册好用户之后,首先要申请API key,所有模型供应商都是通过API key来识别用户的。在阿里百炼平台,申请API key步骤如下,其他平台操作步骤类似。
点击头像,点击主账号管理,先创建一个工作空间。
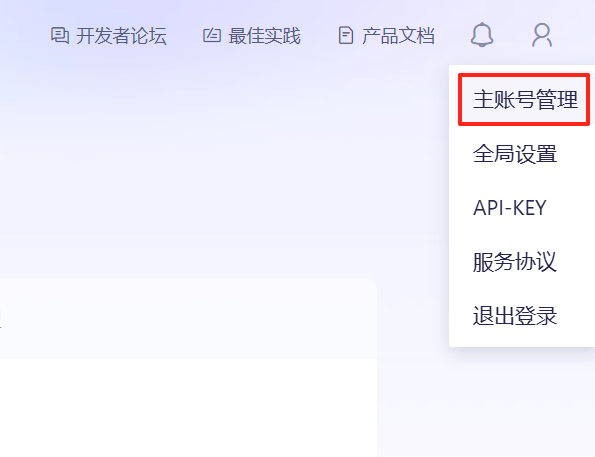
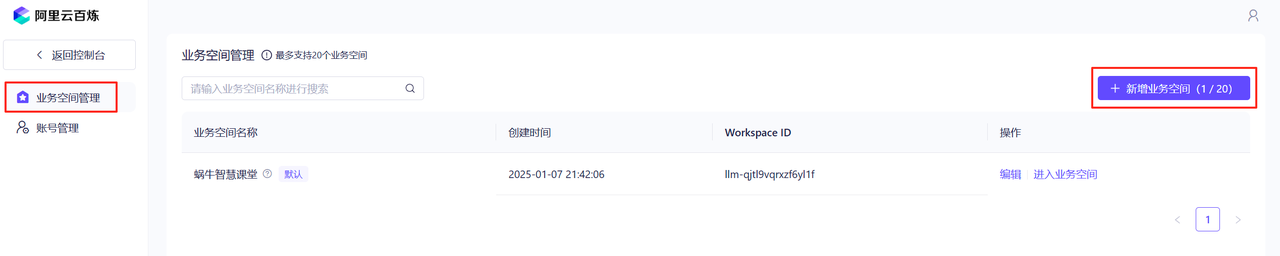
创建工作空间时随便写一个名字就可以了,主要是下面创建APIkey需要选一个工作空间。接下来,返回控制台,再点击头像,点击API-KEY,进入API-Key的列表。点击”创建我的API KEY“。

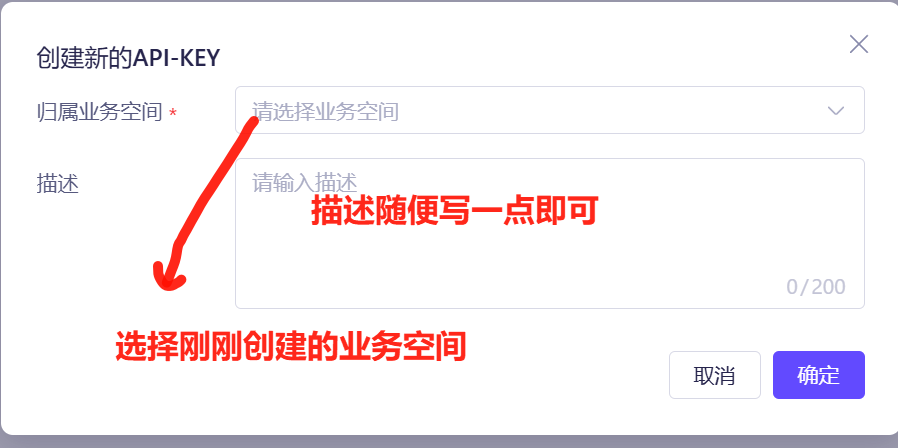
点击确定后,就可以在API key列表中看到刚刚创建的API key。然后点击查看按钮,可以复制这个API key
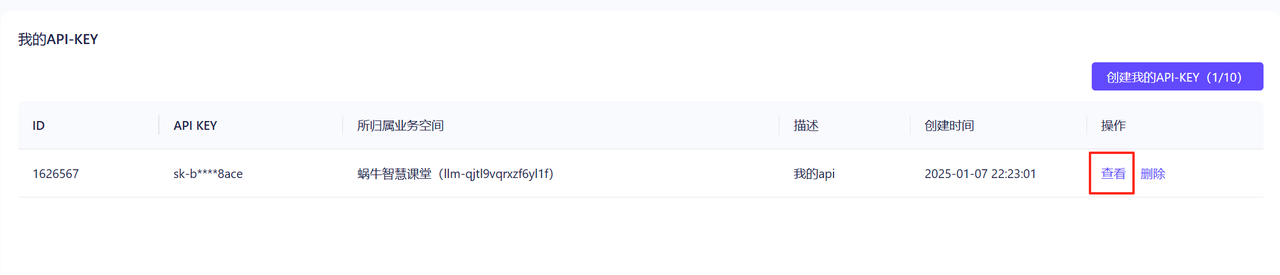
第二步,通过API key调用大模型
通过上面的操作,已经申请到了API key,接下来就可以用这个API key在代码中调用大模型了。如何调用大模型,可以查看大模型列表里面的详情描述,里面就有详细的API调用接口的例子。
先回到模型广场,选择自己要使用的大模型。大家如果不知道该选什么模型,可以先看看模型的种类,如下图所示。
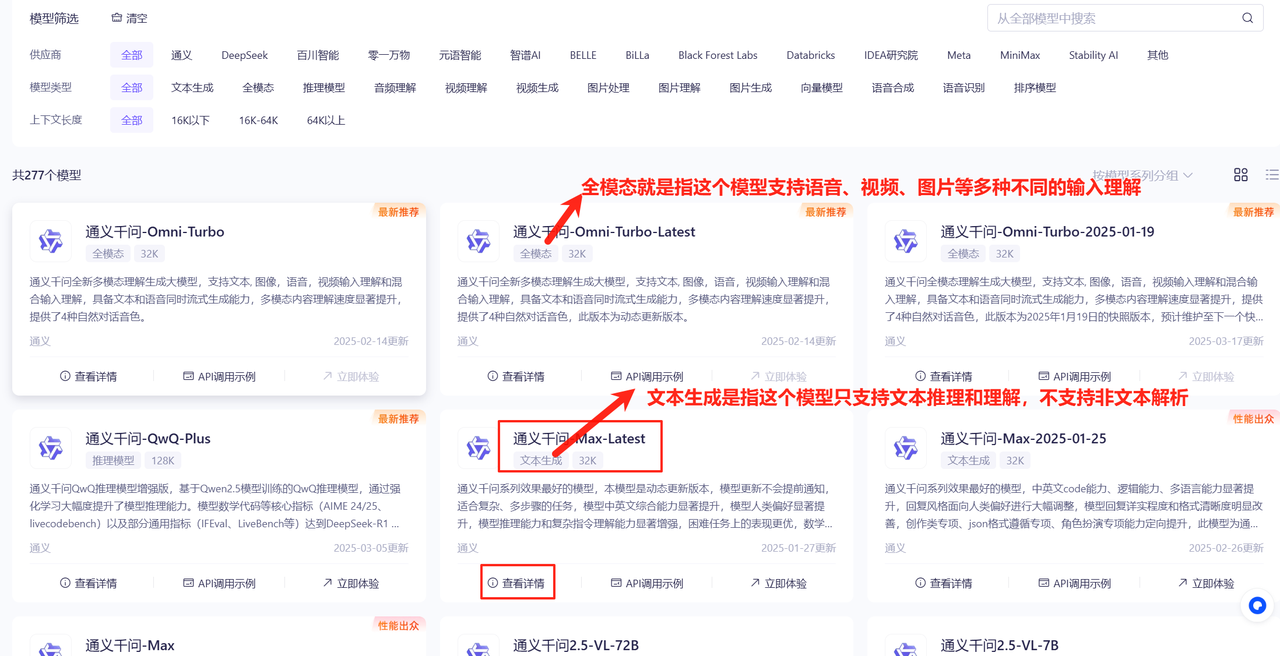
选定模型后,比如我想调用通义千问-Max-Latest这个模型,就在模型广场找到它,点击查看详情按钮。接下来,就会出现模型的介绍和赠送的token使用量等信息。
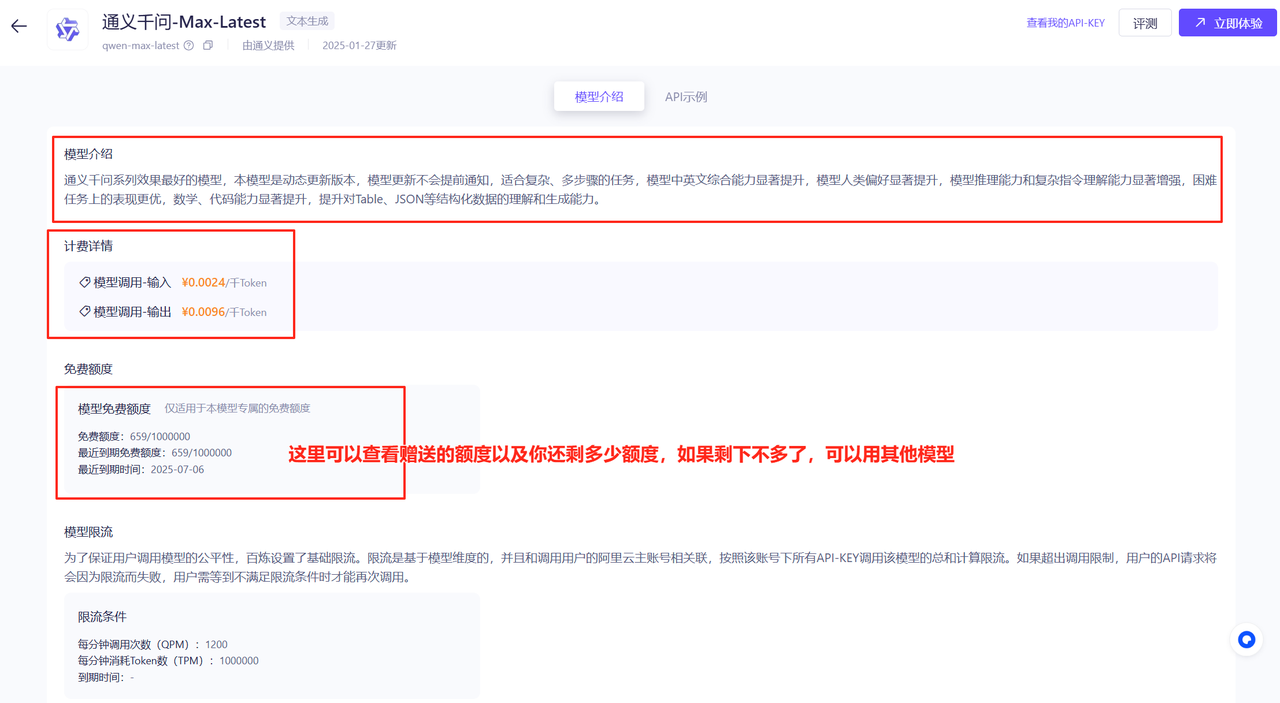
如果要看API怎么调,可以点击旁边的API示例。往下拉,可以看到下面这个内容。
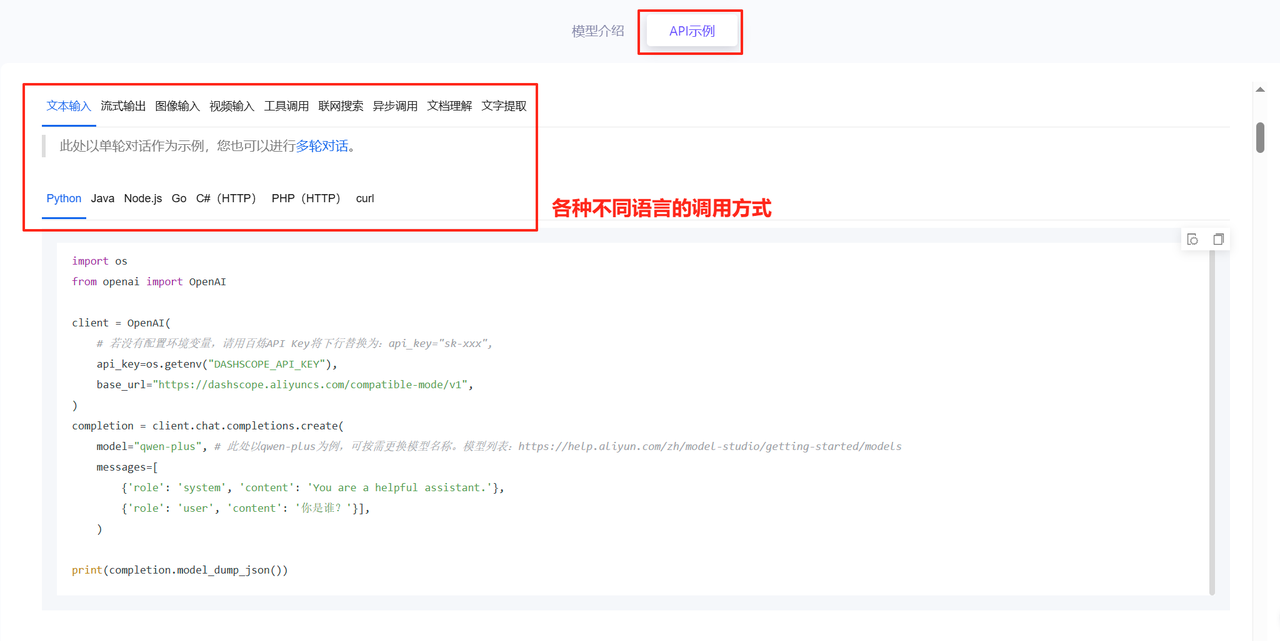
大家可以根据代码示例,在自己的代码中调用相关的模型就好。模型接入后,接下来就可以开始愉快地编写代码了。
如果觉得本文对你有帮助,欢迎大家点赞、转发、收藏一键三连,谢谢大家,祝大家学习愉快!

















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









