 Python基础语法与机器学习工具介绍
Python基础语法与机器学习工具介绍




 该博客主要介绍Python基础语法,包括字面量、注释、运算符等,详细讲解列表、元组等数据类型操作,以及判断、循环、函数的使用。还介绍了机器学习工具,如matplotlib、numpy、pandas的使用,包括绘图、数组生成、数据处理等,以及高级数据处理方法。
该博客主要介绍Python基础语法,包括字面量、注释、运算符等,详细讲解列表、元组等数据类型操作,以及判断、循环、函数的使用。还介绍了机器学习工具,如matplotlib、numpy、pandas的使用,包括绘图、数组生成、数据处理等,以及高级数据处理方法。
一,字面量
二,注释,运算符,标识符,数据类型转换
三,判断语句
四,循环语句
五,函数
六,机器学习工具
一, 字面量
使用input()语句可以从键盘获取输入
使用print()语句可以从键盘输出
1.数字数据类型
int(整数)、float(浮点数)、bool(布尔型)(True /False)、complex(复数)(eg:4+2j)
注意:在Python中浮点类型只有单精度float。
判断该数字的数据类型使用type()函数。
2.字符串:
| 格式符号 | 转化 |
| %s | 将内容转换成字符串,放入占位位置 |
| %d | 将内容转换成整数,放入占位位置 |
| %f | 将内容转换成浮点型,放入占位位置 |
3.列表:
(1)创建一个空列表:a=[]
访问列表中的某个元素:a=[索引]
访问列表的最后一个元素:a=[-1]
列表的切片a[::],逆序a[::-1]
(2)列表的方法
- 列表.append(元素)——在列表末尾添加一个元素
- 列表.extend(序列)——在列表末尾追加一个序列
- 列表.insert(索引,元素)——在列表对应的索引插入元素
- del列表[索引]——删除列表中对应索引的元素
- 列表.pop(索引)——删除列表中对应索引的元素,并返回删除的元素,默认最后一个。
- 列表.remove(元素)——删除列表中对应元素的第一个匹配项
- 列表.clear()——清空列表
- 列表[索引]=新元素——将列表对应索引的元素,修改为新元素
- 列表.index(元素)——返回元素对应的索引
(3)列表推导式
[表达式 for 变量 in 列表]
[表达式 for 变量 in 列表 if 条件]
例如:输出列表,里面包括从1-20,输出列表,里面包括1-20中的偶数
a=[x for x in range(1,21)]
print(a)
[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]
b=[x for x in range(1,21) if x%2==0]
print(b)
(4)列表函数
len()——列表的长度
a=[11,22,33,44,55]
Print(len(a))
注意:
+可以连接两个列表,得到一个新的列表
*可以用于一个列表和一个整数,实现列表的复制
a=[1,2,3]
b=['A','B','C']
print(a+b)
print(a*3)
sum()函数——将列表中的所有数相加
a=[11,22,33]
print(sum(a))
(5) in 和not in操作符
In——判断某个元素是否在列表中;判断某个字符或字符串是否在字符串中
Not in——判断某个元素是否不在列表中;判断某个字符或字符串是否不在字符串中
输出值可为布尔值,即True,False
(6)
enumerate()函数
在for循环中迭代,每次返回两个值:列表表项的索引和列表表项本身。
random.choice()函数
将从将列表中返回一个随机选择的表项。
Random.shuffle()函数
将对列表中的表项重新排序,该函数将就地修改列表,而不是返回新列表
(7) 排序
sort()可以对列表永久排序
列表.sort(reverse=True/False)
sorted()可以对列表进行临时排序
sorted(列表名,reverse=True/False)
reverse=True时,按降序排序。
reverse=False时,按升序排序。
(8) 多重赋值
在一行代码中,用列表中的值为多个变量赋值
例如:cat = ['fat','black','loud']
size,color,disposition=cat
4.元组:
元组输入时用(),不用[]。
元组的值无法修改,添加,删除。
(1)元组操作
创建一个空元组——a=()
创建包含一个元素的元组——b=(元素,)————包含一个元素的元组必须有逗号
创建元组——c=(元素1,元素2,)
(2)元组的访问
获取一个元素——元组序列(所有)
获取多个连接的元素——元组序列[开始索引,结束索引]
(3)元组的操作
Index()——从元组中找出某个对象第一个匹配项的下标位置
Count()——统计某个元素在元组中出现的次数
Len()——计数元组元素的个数,并返回值
Max()——返回元组中元素的最大值
Min()——返回元组中元素的最小值
5.集合:
可以使用{}或者set()函数创建集合,创建一个空集合必须为set()
集合序列.add(数据)——添加一个数据
集合序列.update(序列数据)——添加序列
集合序列.remove(数据)——删除集合中指定的数据
集合序列.pop()——随机删除集合中的某个数据
集合序列.discard(数据)——删除集合中指定的数据
6.字典:
(1)字典访问
访问值——字典序列[键]——访问已知键所对应的值
修改值——字典序列[键]=新值——修改已知键的值
添加键值对——字典序列[新键]=新值——添加新的键值对
del字典序列[键]——删除字典中对应的键的键值对
del字典序列——删除字典
字典序列.clear()——清空字典
字典序列.keys()——查找字典的所有的key
字典序列.values()——查找字典的所有value
(2)使用enumerate()函数枚举键值对
enumerate(序列,start=0)其中start=0为默认开始值为0
(3)Get()方法
a={'apple':2,'banana':3}
print('I have '+str(a.get('orange',0))+' oranges.')
print('I have '+str(a.get('apple',0))+' apples.')
(4)Setdefault()方法
a={'apple':2,'banana':3}
print(a.setdefault('orange',10))
print(a.setdefault('apple',10))
二,注释,运算符,标识符,数据类型转换
1. 单行注释以 #开头
多行注释: 以 一对三个双引号 引起来
2.数据类型转换
| 语句 | 说明 |
| int(x) | 将x转换为一个整数 |
| float(x) | 将x转换为一个浮点数 |
| str(x) | 将对象 x 转换为字符串 |
3.算术运算符
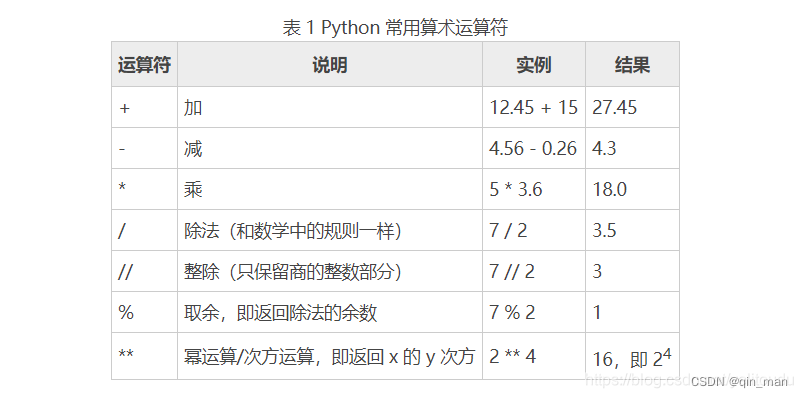
4.复合运算符
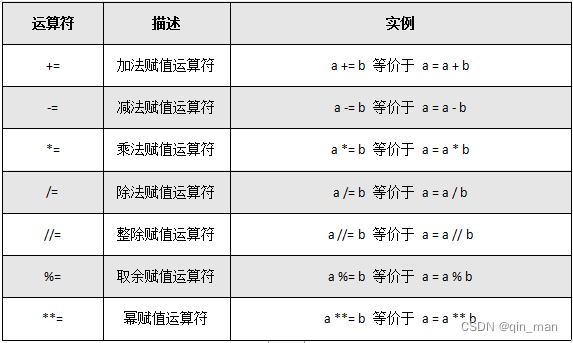
5.标识符
标识符: 是用户在编程的时候所使用的一系列名字,用于给变量、类、方法等命名
标识符命名中,只允许出现: 英文 中文 数字 下划线(_) 这四类元素。
注意:不推荐使用中文,数字不可以开头,且不可使用关键字
三,判断语句
1. if语句的基本格式
if 要判断的条件:
条件成立时,要做的事
- 判断条件必须是布尔类型
- True会执行if内的代码语句
- False则不会执行
- 判断语句后的冒号: 不要忘记
- 归属于if判断的代码块,需要有4个空格缩进,或一个tab
2. if else语句
if 条件:
满足条件时,要做的事情
else:
不满足条件时,要做的事情
- else后不需要条件
- 与if一致,else后的代码块也需要4个空格作为缩进,或一个tab
3.if elif else语句
if 条件:
满足条件时,要做的事情
elif 条件:
满足条件时,要做的事情
else:
不满足以上条件时,要做的事情
- elif可以写多个
- 判断是互斥且有序的,上一个满足后就不会进行判断了
4.判断语句的嵌套
if 条件1:
满足条件1所做的事情
if 条件2:
满足条件2所做的事情
elif 条件3
满足条件三所做的事情
if 条件4:
满足条件4所做的事情
elif 条件5:
满足条件5所做的事情
else:
满足条件3不满足条件4,5所做的事情
else:
if 条件6:
满足条件6所做的事情
else:
都不满足所做的事情
- 嵌套的关键点是:空格缩进
- 通过空格缩进来决定语句的层次关系
- 嵌套判断语句可以根据需求,自由组合来构建多层次判断
四,循环语句
Python里面提供了三种循环方式:
1.while 循环:在给定的判断条件为 true 时执行循环体,否则退出循环体。
while 条件:
语句1
2.for 循环:重复执行语句
for 【迭代变量】 in 【序列项目】:
语句1
3.嵌套循环:while 循环 和 for循环 之间的嵌套
#for 循环里面嵌套 for 循环
for 【迭代变量】 in 【序列项目】:
for 【迭代变量】 in 【序列项目】:
语句1
语句2
#while 循环里面嵌套 while循环
while 条件1:
while 条件2:
语句2
语句1
# for循环里面嵌套while循环
for 【迭代变量】 in 【序列项目】:
while 条件1:
语句1
语句2
# while循环里面嵌套for循环
while 条件1:
for 【迭代变量】 in 【序列项目】:
语句2
语句1
Python里面提供了三个循环控制语句:
- break 语句
- continue 语句
- pass 语句
| 控制语句 | 描述 |
|---|---|
| break 语句 | 在循环语句执行过程中终止循环,并且跳出整个循环 |
| continue 语句 | 在循环语句执行过程中终止当前循环,跳出该次循环。执行下一次循环。 |
| pass 语句 | pass是空语句,是为了保持程序结构的完整性。 |
range函数的使用方法:
range(start,stop[,step])- start:开始数值,默认为0,也就是如果不写这项,就是认为start=0
- stop:结束的数值,必须要写的。
- step:变化的步长,默认是1,也就是不写,就是认为步长为1。坚决不能为0
关于range的范围理解,range(100,1000)是从100到999。
相当于前一个数是闭区间,后一个数是开区间,
② 关于%的理解,取余数,例:7%4结果为3
③关于/ ,//的理解,/表示浮点数除法,返回浮点数(即小数值),例:8/4结果为4.0;//表示整数除法,返回整数值,例:7//3结果为2
五,函数
1. 定义函数
Def 函数名():
函数语句
调用函数名:
函数名()
返回值:
Def 函数名():
函数语句
Return 返回值
形参和实参(个数保持一致):
定义格式:
Def 函数名(形参1,形参2):
函数体
调用格式(实参1,实参2)
位置参数
Def 函数名(形参1,形参2):
函数体
函数名(实参1,实参2)
默认参数
Def 函数名(形参1=数据,...):
函数体
不定长参数
Def 函数名(*args):
函数体
函数名(实参1,实参2,...)
Def 函数名(kwargs):
函数体
- 参数定义顺序:
- 作用域:局部作用域(nonlocal),全局作用域(global)。
- 修改作用域:
2.函数参数
- 定义时小括号中的参数,用来接收参数用的,称为 “形参”
- 调用时小括号中的参数,用来传递给函数用的,称为 “实参”
3.全局变量: 在函数和类定义之外声明的变量。全局变量的缩进为0,作用域为定义的模块,从定义位置开始直到模块结束。
局部变量:在函数体中声明的变量。(包括形参变量也是局部变量)。
如果局部变量和全局变量同名,如果对同名变量进行赋值操作,则在函数内隐藏全局变量,只使用同名的局部变量
六,机器学习工具
| 工具 | 作用 |
|---|---|
| matplotlib | 画图工具 |
| numpy | 表格处理工具 |
| padas | 信息处理工具 |
(一)matplotlib
1.导入库:import matplotlib.pyplot as plt
2.创建画布:plt.figure(figsize = (a,b),dpi = )
3.绘制图像:plt.plot(x,y.color = '',linestyle = '',marker = '',linestyle='',label='')
颜色:
| 颜色 | 说明 | 颜色 | 说明 |
|---|---|---|---|
| r | 红色 | g | 绿色 |
| b | 蓝色 | w | 白色 |
| c | 青色 | m | 洋红 |
| y | 黄色 | k | 黑色 |
标记风格:
| 标记字符 | 说明 | 标记字符 | 说明 |
|---|---|---|---|
| '.' | 点标记 | ',' | 像素标记(极小点) |
| 'v' | 倒三角标记 | ’^‘ | 上三角标记 |
| '>' | 右三角标记 | '<' | 左三角标记 |
| '1' | 下花三角标记 | '2' | 上花三角标记 |
| '3' | 左花三角标记 | '4' | 右花三角标记 |
| 'o' | 实心圈标记 | 's' | 实心方形标记 |
| 'p' | 实心五角标记 | '*' | 星形标记 |
| 'h' | 竖六边形标记 | 'H' | 横六边形标记 |
| '+' | 十字标记 | 'x' | x标记 |
| 'D' | 菱形标记 | 'd' | 瘦菱形标记 |
线条样式:
| 样式 | 说明 |
|---|---|
| ’-‘ | 实线 |
| ’--‘ | 虚线 |
| ’-.‘ | 点划线 |
| ':' | 点虚线 |
4.增加自定义x,y刻度:
plt.xticks(x,rotation=,fontsize=)
plt.yticks(y,rotation=,fontsize=)
5.设置x,y标签和标题
plt.xlabel(,fontsize=)
plt.ylabel(,fontsize=)
plt.title(,fontsize=)
6.增加网格显示: plt.grid(True,linestyle=,alpha=)
7.设置图例位置: plt.legend(loc=)
| 位置 | 描述 | 对应数字 |
|---|---|---|
| best | 最佳位置 | 0 |
| upper right | 右上方 | 1 |
| upper left | 左上方 | 2 |
| lower left | 左下方 | 3 |
| lower right | 右下方 | 4 |
| right | 右边 | 5 |
| center left | 中间左边 | 6 |
| center right | 中间右边 | 7 |
| lower center | 下方中间 | 8 |
| upper center | 上方中间 | 9 |
| center | 正中心 | 10 |
8.显示图像:plt.show()
9.中文显示问题: plt.rcParams['font.sans-serif'] = ['SimHei']
10.折线图:
散点图:plt.scatter(x,y)
柱状图:plt.bar(x,width=,height=,label=,alpha=,align=,color=)
直方图:plt.hist(x,bins=None)
饼图:plt.pie(x,explode=None,labels=None,autopct=None,pctdistance=0.6,shadow=False,
labeldistance=1.1,startangle=None,radius=None,counterclock=True,wedgeprops=None,
textprops=None,center=(0,0),frame=False,rotatelabels=False,*,data=None)
例题:
# 导入matplotlib.pyplot,pandas并使用"plt"作为该模块的简写
import matplotlib.pyplot as plt
import pandas as pd
#设置字体,防止乱码
plt.rcParams["font.sans-serif"] = ["SimHei"]
#读取文件
data = pd.read_csv(r"D:\python1\数据集1.csv")
#将date转换为时间类型数据
data["Date"] = pd.to_datetime(data["Date"])
#求出死亡率
DeathRate = data["Deaths"]/data["Confirmed"]
#根据题目绘制折线图
plt.plot(data["Date"],DeathRate,color = "orange",marker = "o",label = "每日死亡率")
plt.xlabel("日期")
plt.ylabel("死亡率")
plt.title("2020年1月22日至2020年7月27日病毒死亡率走势")
plt.legend()
plt.show() 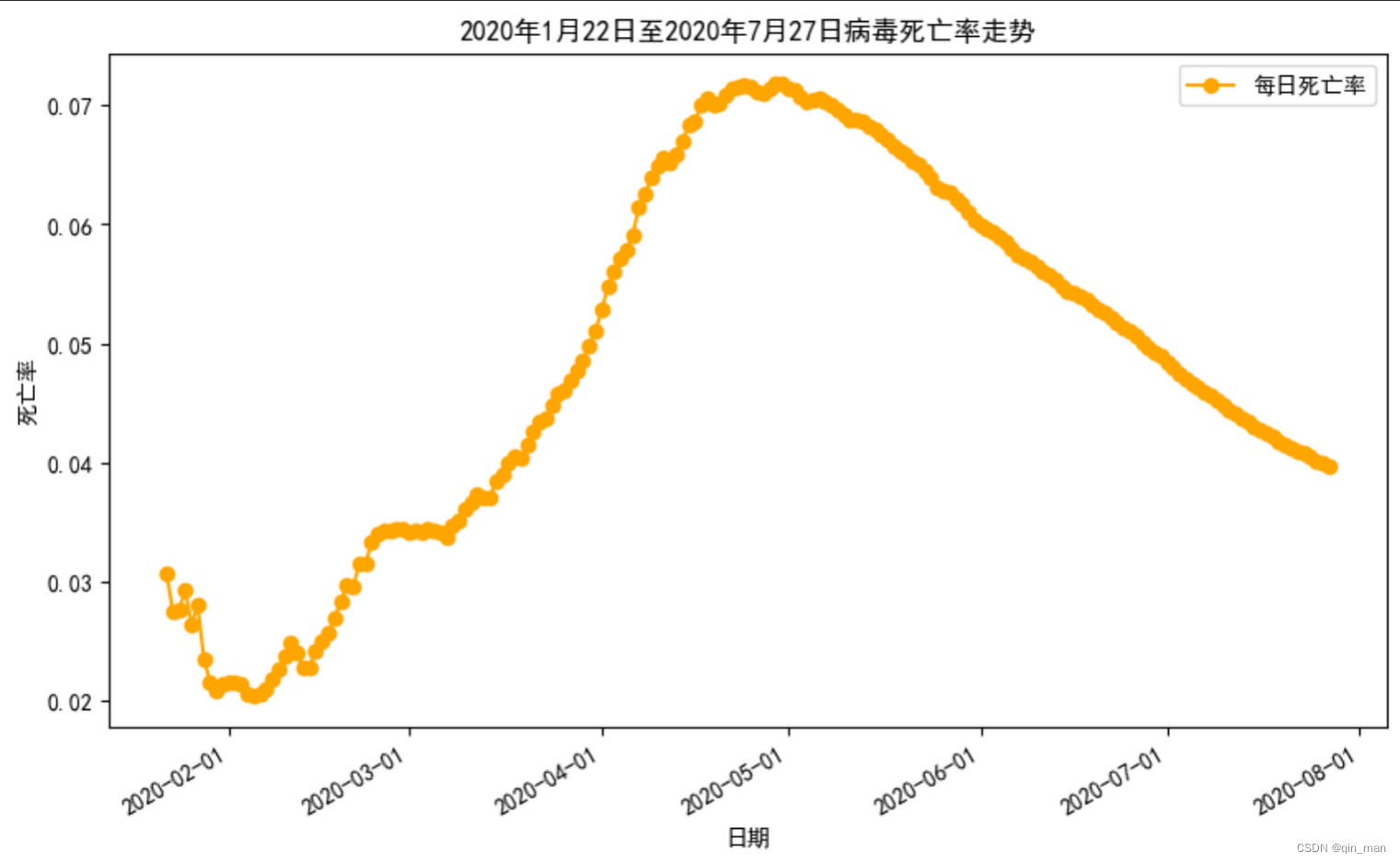
# 导入matplotlib.pyplot,numpy,pandas
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy.stats import norm
np.random.seed(42)
row = 10000
index = np.arange(1,row + 1)
#使用np.random.randint(初始值,结束值,个数)输出随机数
count = np.random.randint(0,10001,size = row)
class_data = np.random.choice([1,2,3,4,5],size = row)
normal = np.random.uniform(0,10001,size = row)
#np.random.rand(个数)一般输出的随机数一般范围在-1.96~1.96之间
zero = np.random.rand(row)
#保存数据csv
data={'index':index,'count':count,'class':class_data,'normal':normal,'0-1':zero}
df = pd.DataFrame(data)
df.to_csv('generated_data.csv',index = False)
data = pd.read_csv('generated_data.csv')
normal_data = data['normal']
mu,std = norm.fit(normal_data)
plt.hist(normal_data,bins = 50,density= True,alpha = 0.5, color = 'r')
#根据题目绘制折线图
xmin,xmax = plt.xlim()
#np.linspace(start, stop, num, endpoint) 创建等差数列,指定数量
x = np.linspace(xmin,xmax,100)
p = norm.pdf(x,mu,std)
#绘制图像(横轴,纵轴,颜色,线条宽度)
plt.plot(x,p,'k',linewidth = 2)
#设置x,y标题
plt.xlabel('value')
plt.ylabel('Frequency')
#设置图例位置
plt.legend(['Normal_distribution','Data'])
#添加网格显示
plt.grid(True)
#显示图像
plt.show()
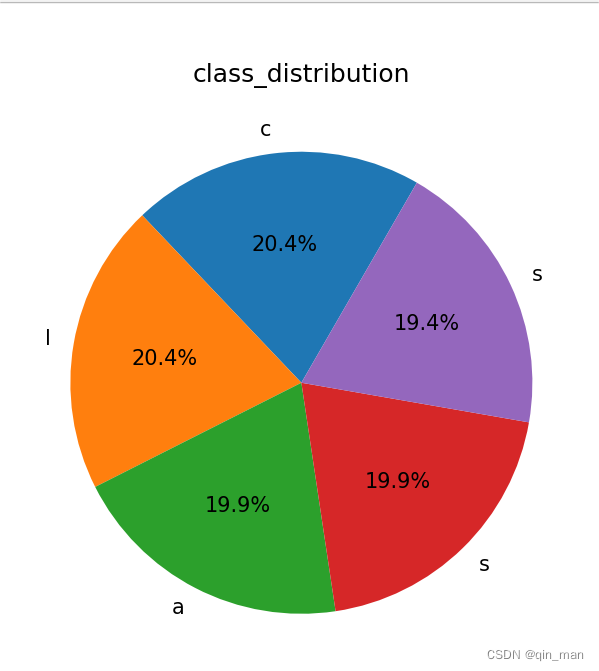
data = pd.read_csv('generated_data.csv')
class_counts = data['class'].value_counts()
#根据题目绘制折线图
plt.figure(figsize = (8,8))
plt.pie(class_counts,labels = class_counts.index,autopct = '%1.1f%%',startangle = 140)
plt.title('Disribution of classes')
plt.show()
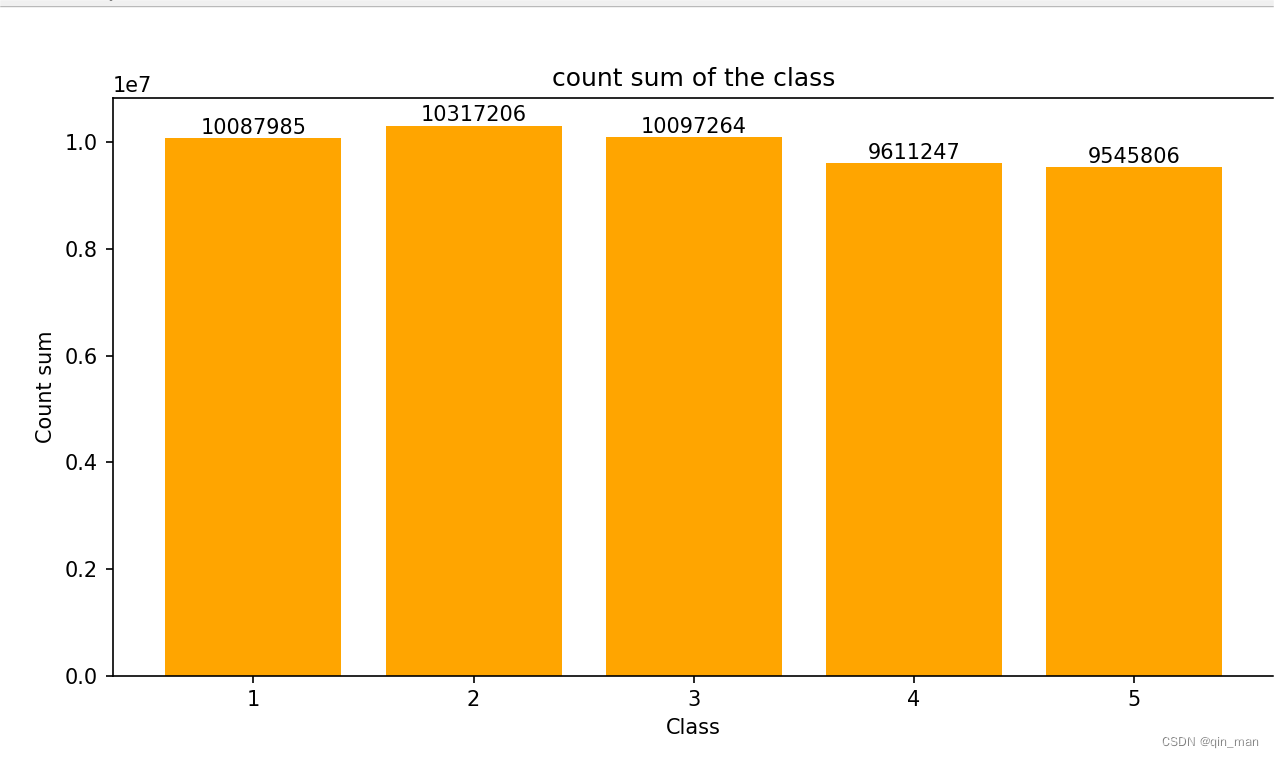
data = pd.read_csv('generated_data.csv')
plt.rcParams["font.sans-serif"] = ["SimHei"]
class_sum = df.groupby('class')['count'].sum()
plt.figure(figsize=(10,7))
class_sum.plot(kind='bar',color='green',edgecolor='black')
plt.title('各类别总计柱状图',fontsize='20')
plt.xlabel('类别',fontsize='15')
plt.ylabel('总数',fontsize='15')
plt.yticks(np.linspace(0,10000000, 11))
plt.tick_params(labelsize=15)
for a, b in enumerate(class_sum): #标记每列数值
plt.text(a, b, str(b),ha='center',va='bottom',fontsize=12)
plt.show()
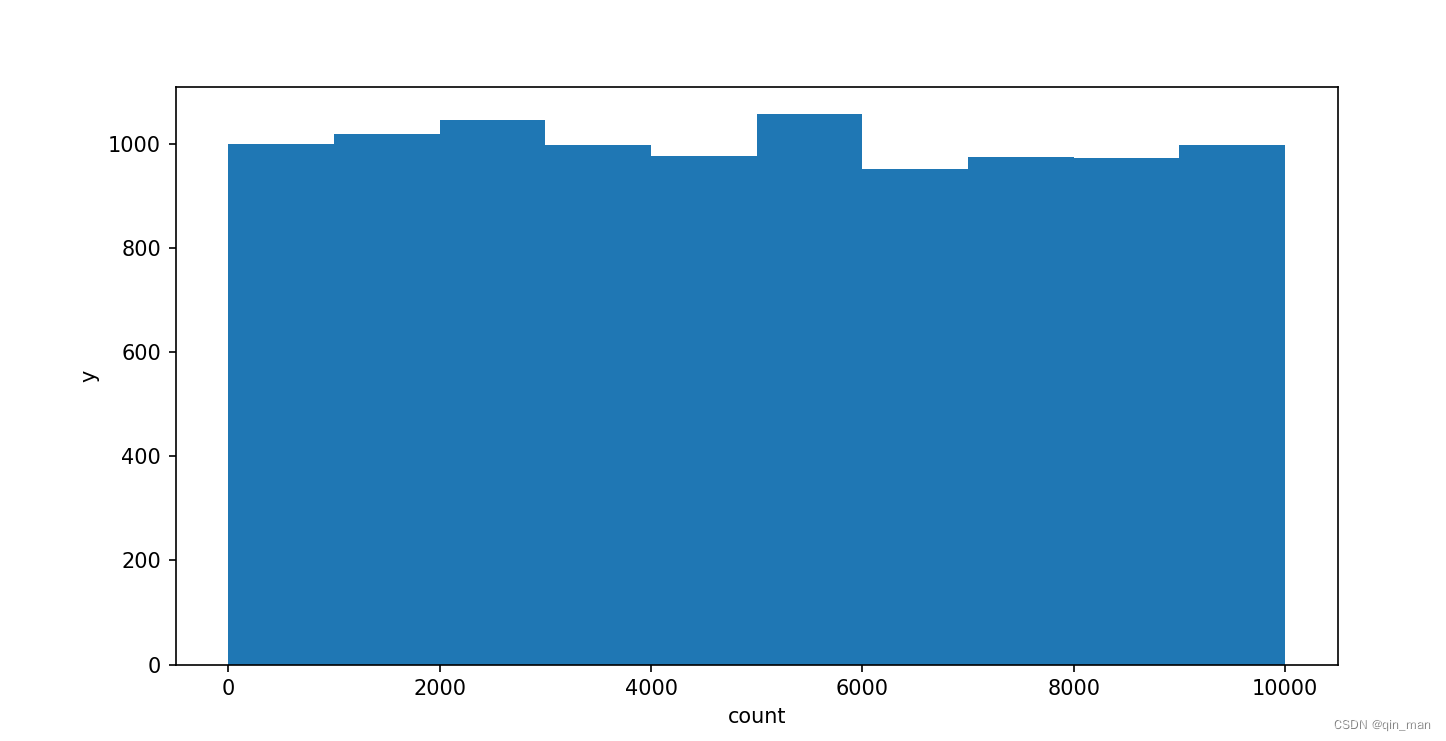
data = pd.read_csv('generated_data.csv')
plt.figure(figsize=(8, 6))
plt.hist(data['count'], bins=10, color='azure', edgecolor='black')
plt.xlabel('Count')
plt.ylabel('Frequency')
plt.title('Distribution of Counts in Ten Bins')
plt.grid(True)
plt.show()
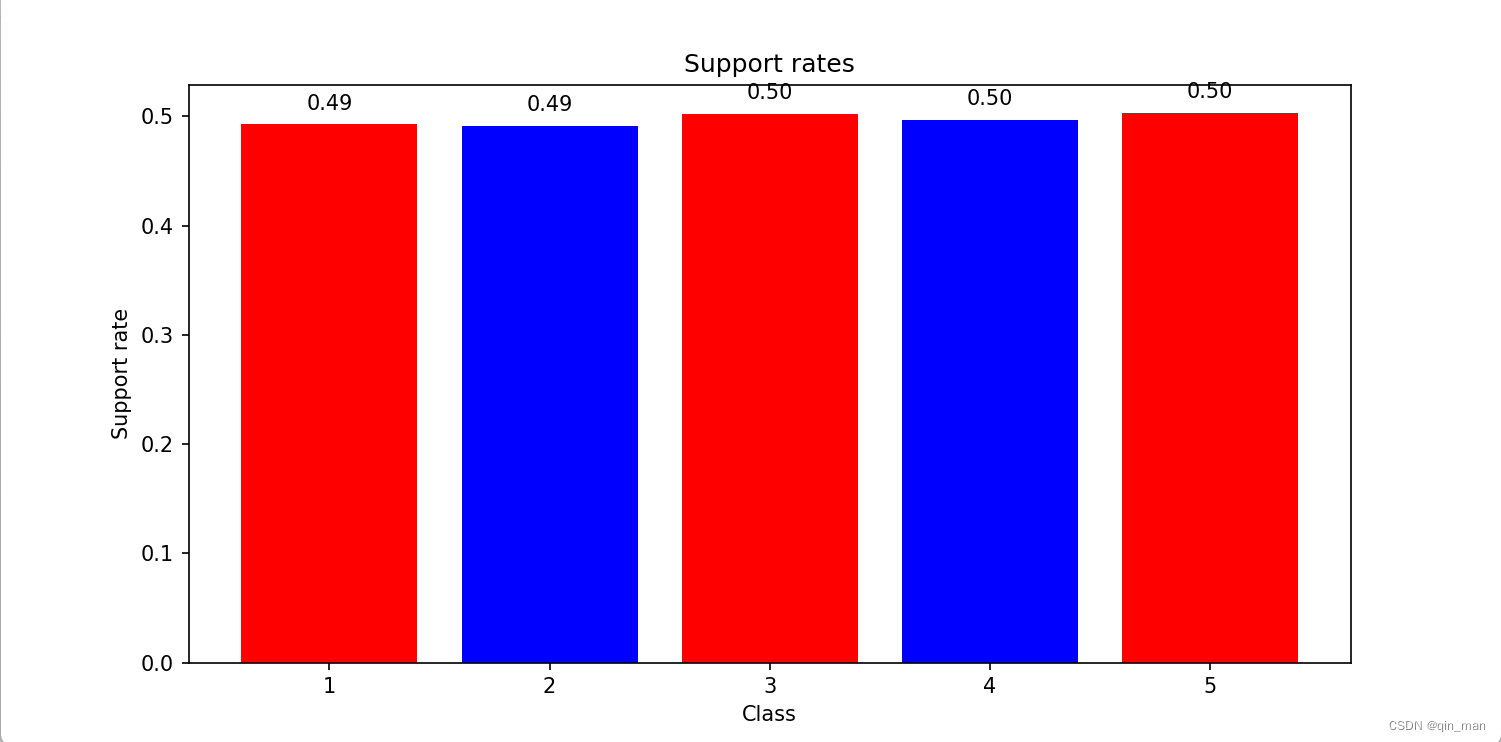
data = pd.read_csv('generated_data.csv')
support_rates = data.groupby('class')['0-1'].mean()
plt.figure(figsize=(8, 6))
colors = ['azure' if team == 1 else 'skyblue' for team in support_rates.index]
plt.bar(support_rates.index, support_rates, color=colors)
plt.xlabel('Team')
plt.ylabel('Support Rate')
plt.title('Support Rate for azure and skyblue Teams')
plt.ylim(0, 1)
plt.show()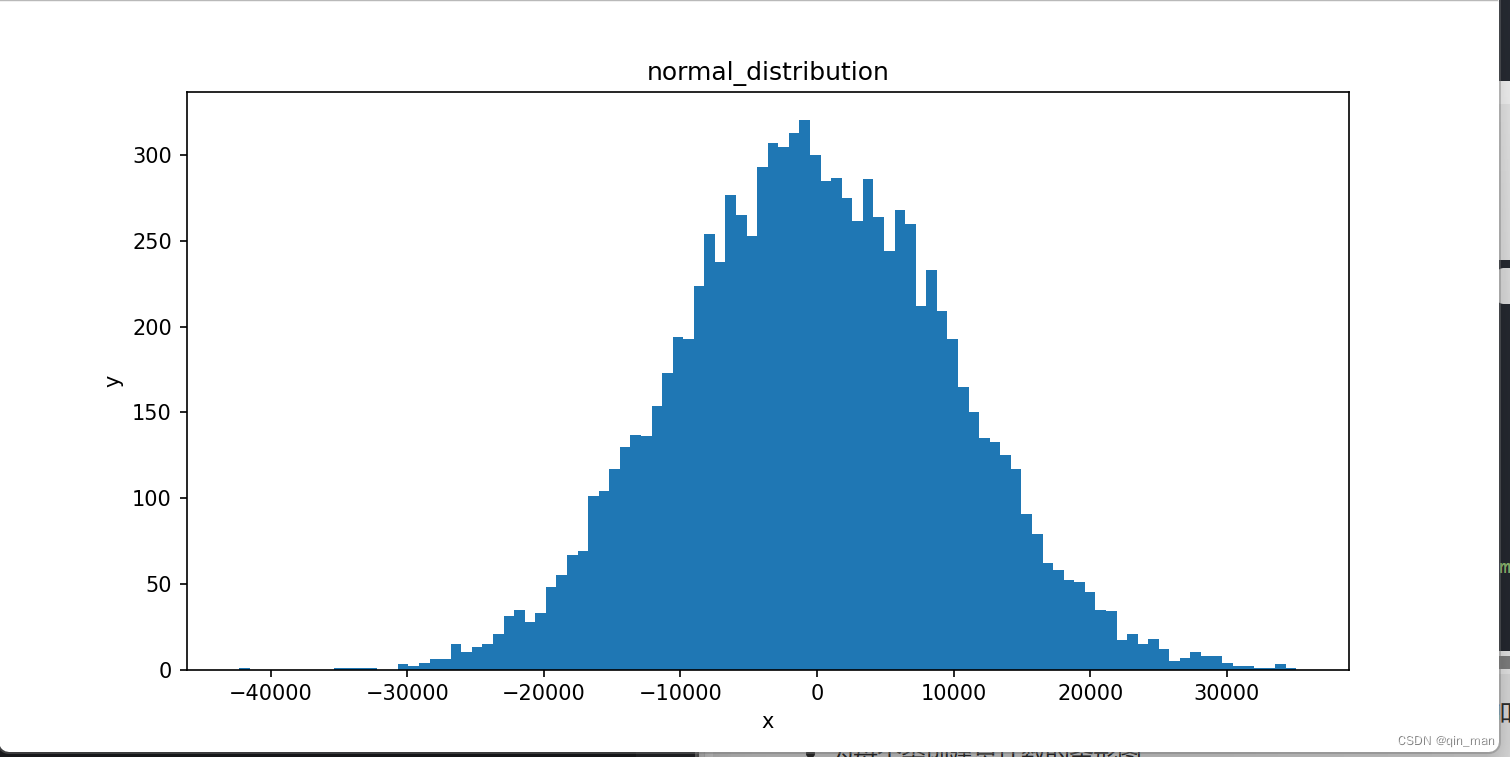
(二)numpy
1.导入库:import numpy as np
2.创建 data = np.array()
| 名称 | 作用 |
|---|---|
| data.shape | 查看数组的维度(以元组的形式输出) |
| data.ndim | 查看数组维数 |
| data.size | 查看数组中的元素数量 |
| data.itemsize | 查看一个数组元素的长度 |
| data.dtype | 查看数组元素的类型 |
3.从现有数组中生成
data1 = np.array(data)
data2 = np.asarray(data)
4.生成固定范围内的数组
创建等差数组,指定数量(步长自动计算) :np.linspace(start, stop, num, endpoint)
创建等差数组,指定步长(数量自动计算) :np.arange(start,stop,step,dtype)
创建等比数组,生成以10的N次幂的数据 : np.logspace(start,stop,num)
5.生成随机数组
np.random模块
正态分布:
(1)导入库:import random
(2)np.random.randn(d0,d1,d2,……,dn)
(3)np.random.normal(loc = 0.0,scale = 1.0,size = None)
(4)np.random.standard_normal(size = None)
均匀分布:
(1)np.random.rand(d0,d1,d2,……,dn)
(2)np.random.uniform(low = 0.0,high = 1.0,size = None)
(3)np.random.randint(low, high = None,size = None,dtype = 'i')
(三)pandas
1.导入库:import pandas as pd
2.画图:dataframe.plot(kind='line')
3.DataFrame运算
元素相加,维度相等时找不到元素默认用fill_value
dataframe.add(dataframe2, fill_value = None, axis = 1)
元素相减,维度相等时找不到元素默认用fill_value
dataframe.sub(dataframe2, fill_value = None, axis = 1)
元素相除,维度相等时找不到元素默认用fill_value
dataframe.div(dataframe2, fill_value = None, axis = 1)
元素相乘,维度相等时找不到元素默认用fill_value
dataframe.mul(dataframe2, fill_value = None, axis = 1)
4.文件读取:
pd.read_csv(filepath_or_buffer,sep = ',',usecols = None)
pd.read_hdf(path_or_buffer,key = None,**kwargs)
pd.read_json(path_or_buffer = None,orient = None,typ = 'frame',lines = False)
(四)高级数据处理
1.删除存在缺失值的对象 dataframe.dropna(axis = 0)
2.替换缺失值 dataframe.fillna(value, inplace = True)
3.分组:pd.qcut(data, q)
统计分组次数:series.values_counts()
自定义分组:pd.cut(data,bins)
4.合并:
按照行或列进行合并 pd.concat([data1, data2], axis = 1)
可以指定按照两组数据的共同键值对合并或者左右各自 pd.merge(left, right, how = 'inner', on = None)
5.交叉表:pd.crosstab(value1, value2)
透视表:
data.pivot .table()
DataFrame.pivot_table([],index = [])
6.分组:DataFrame.groupby(key, as_index = True)


















 249
249




 到【灌水乐园】发言
到【灌水乐园】发言







