




7 月 5 日,2025 时序数据库技术创新大会在北京成功举办,清华大学软件学院长聘副教授龙明盛在大会上做主题报告《Timer 3.0:新一代生成式时序大模型》,深入剖析当前时间序列分析领域面临的核心挑战,系统阐述了时序大模型的技术演进趋势与行业痛点,并重点分享清华团队自主研发的时序大模型 Timer 从 1.0 至 3.0 版本的关键技术路线、创新突破点及在多项国际基准测试中的卓越表现。
以下为报告核心内容总结。
目录
时序分析三大挑战
时序大模型发展与研究历程
自研时序大模型 Timer 的探索之路
· Timer 1.0:实现少样本预测、多任务适配双能力
· Timer 2.0:盘活历史数据,适配长上下文预测场景
· Timer 3.0:生成式预测“深度思考”,万亿级数据规模训练
· 未来展望:路虽远,行则将至
01
时序分析三大挑战
龙明盛教授首先系统地梳理了时序分析的技术挑战。他指出,在工业时序数据分析领域,核心需求聚焦于通过对历史数据的深度挖掘,构建预测式分析模型,以实现对设备复杂工况的精准预判,并最终支撑智能化运维决策体系的建立。
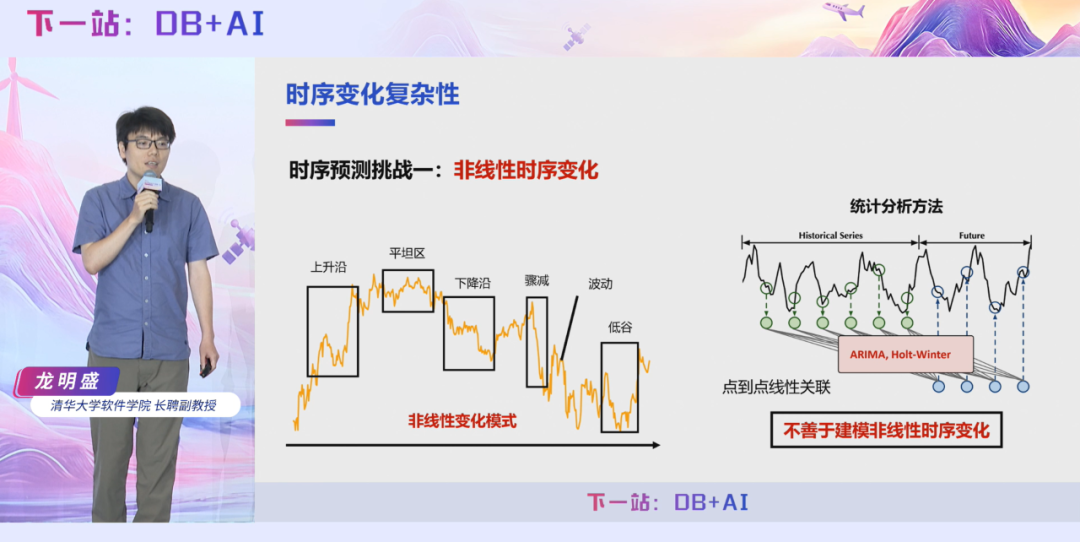
龙明盛教授认为,时间序列数据作为重要的工业资产,其分析面临三大核心难题:第一,数据变化呈现非线性特征,传统线性建模工具,如 ARIMA、Holt-Winters 存在理论局限,无法适配时序数据变化趋势。
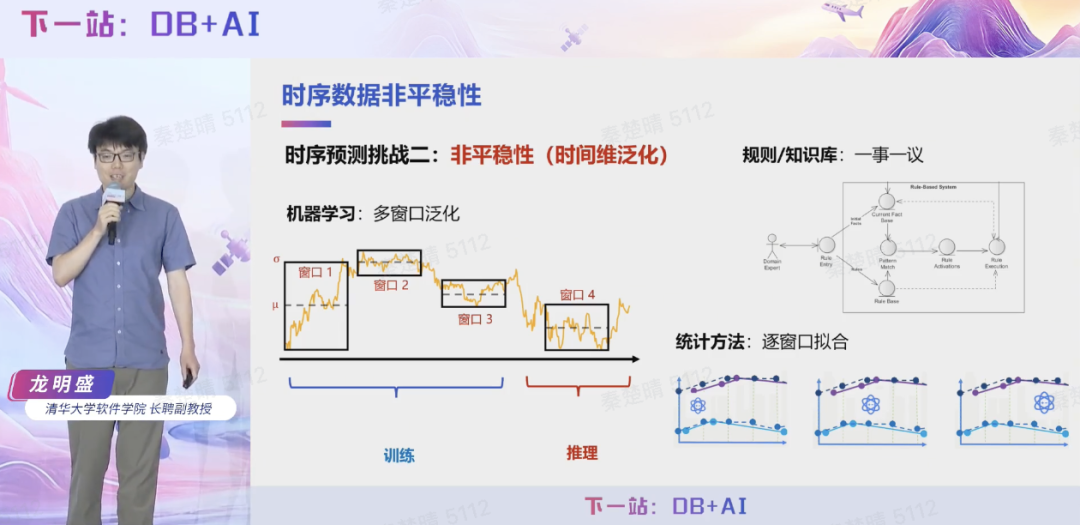
第二,时序数据变化往往呈现非平稳性,传统分析方法需依赖大量人工规则,一事一议地进行拟合,大幅增加了建模复杂性,无法高效进行扩展。
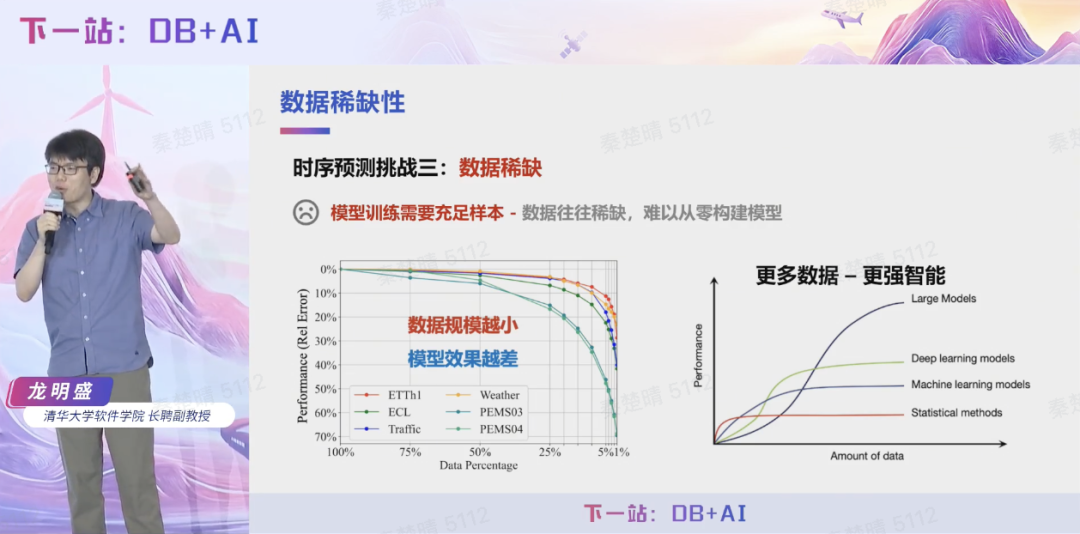
第三,模型训练需要充足数据样本,在历史数据稀缺环境下,模型往往难以构建,而当数据规模扩大时,现有模型又存在容量天花板,出现性能饱和现象,无法有效支撑大规模时序分析。
02
时序大模型发展与研究历程
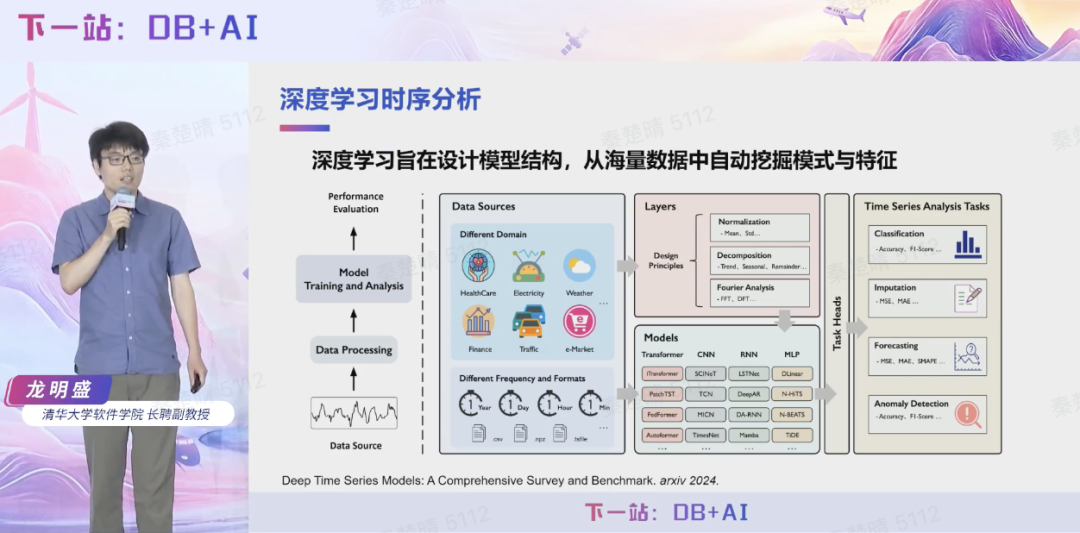
龙明盛教授系统回顾了清华团队在时序大模型领域的研究历程与技术探索。团队在过去五年中构建了完整的时序分析技术栈,从数据预处理发展至深度学习模型,最终形成涵盖 FFT 频域变换、数据分解、归一化等分析算子的自研时序大模型成果。
龙明盛教授将时序分析技术演进划分为三个阶段:传统统计分析(1.0)、深度学习模型(2.0)和时序大模型(3.0)。团队的时序大模型技术研发秉持孙家广院士“能用、管用、好用”的研发理念,始于服务北京冬奥会的实践场景。
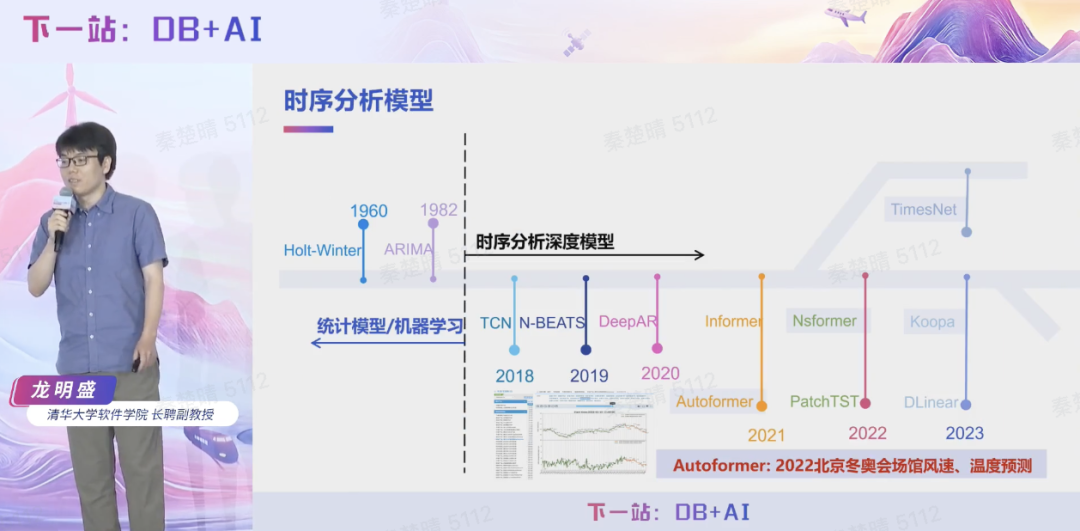
2023 年下半年,清华团队在 2023 IoTDB 用户大会上发布了支持深度学习模型的 IoTDB 原生节点 AINode,同时启动了从深度学习模型到大模型的升级转型,希望进一步满足用户对开箱即用、一键微调分析模型的迫切需求。
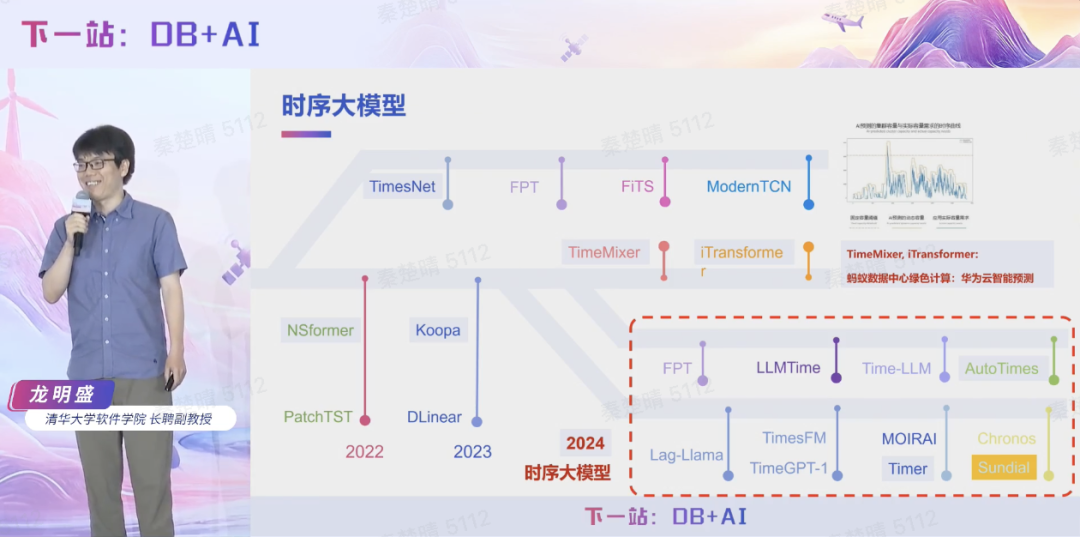
尽管时序大模型概念兴起不足两年,但发展极为迅速,呈现出激烈竞争态势。龙明盛教授认为,时序大模型的核心价值在于实现“一对多”的泛化能力——通过海量数据训练获得通用时序理解能力,并能够灵活适配各类下游任务。这种“一库一模型”的架构理念,将彻底突破传统“单模型对应单任务”的局限,使时序大模型真正具备与数据库同等重要的基础设施地位,成为工业智能化转型的核心支撑。
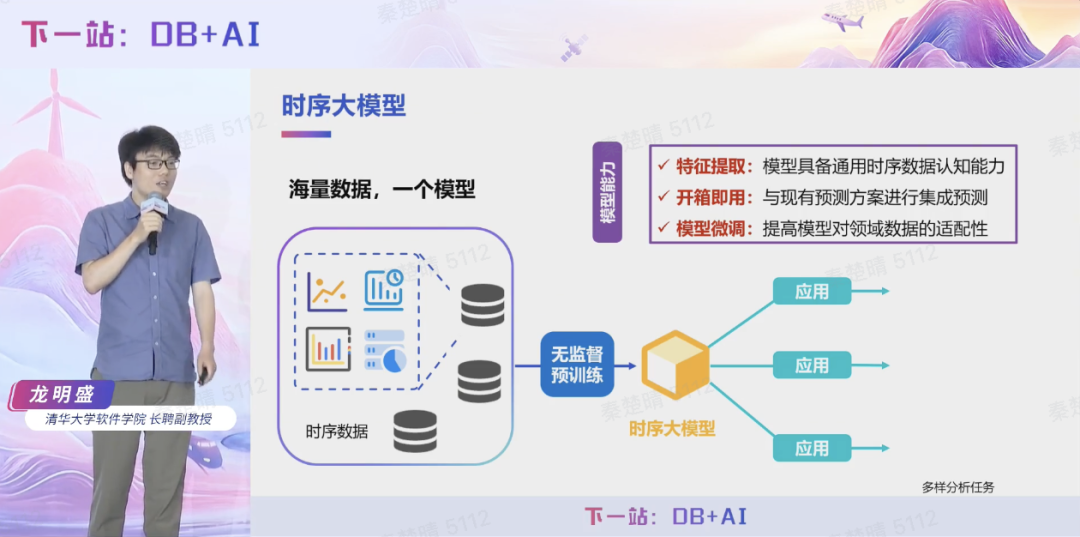
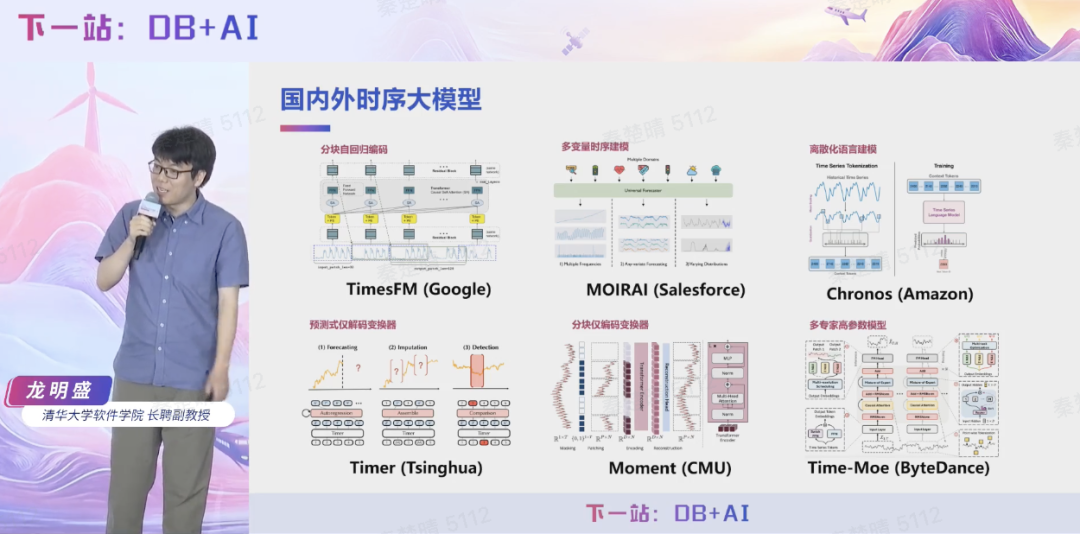
同时,龙明盛教授深入剖析了时序大模型领域的技术发展现状。作为国际上最早开展时序大模型研究的团队之一,龙明盛教授指出,行业初期普遍存在简单移植语言模型架构的现象,而这种做法其实无法解决时序数据分析复杂性所带来的一系列根本问题。
主流科技企业在时序大模型方向的技术方案集中在解决时序数据分析中的特定技术难题:Google 采用分窗注意力建模,延续了语言模型的传统方法;Salesforce 的 MOIRAI 模型通过展平处理多变量数据,一定程度解决了时间序列多变量分析问题,但成效有限;亚马逊的 Chronos 模型直接将时间点类比为自然语言词汇,导致预测长度受限和资源消耗过大等问题。
龙明盛教授特别强调,时序数据与自然语言存在本质差异,如何在大模型中定义窗口和 Token 尚未得到彻底解决。即便引入混合专家模型,仍面临诸多技术瓶颈。
03
自研时序大模型 Timer 的探索之路
(1)Timer 1.0:实现少样本预测、多任务适配双能力
龙明盛教授指出,与自然语言数据相比,时序数据具有两个本质差异:其一,时序数据本质上是多变量序列而非单序列;其二,时序数据展现出更强的多样性,包括形态变化、采样频率差异和值域分布波动等 OOD(Out-of-Distribution)特性。这些特性导致直接应用 Transformer 等架构面临根本性困难。
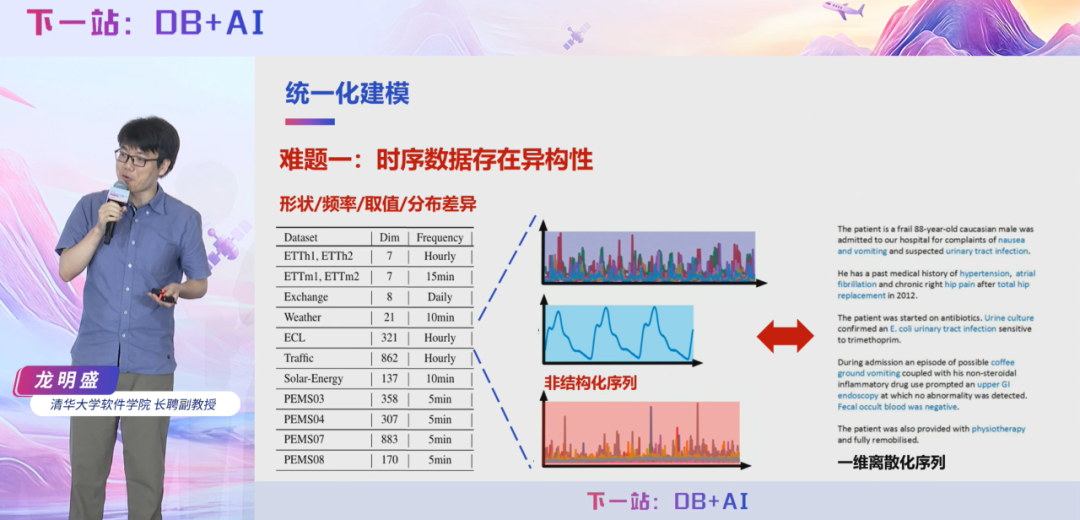
针对这些问题,团队在自研时序大模型 Timer 1.0 中重点实施了两项关键创新:首先通过值域规范化与统计检
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1955
1955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











