






目录
1.安装前准备
(1)建立三个文件夹用于存储大数据软件、安装包、日志数据
mkdir -p /export/server
mkdir -p /export/software
mkdir -p /export/data
(2)安装jdk
略
(3)集群规划
主要搭建三台机器的集群,我这边三台集群的主机名为hadoop01、hadoop02、hadoop03集群规划如下
| 主机 | HDFS | YARN |
| hadoop01 | NameNode DataNode | ResourceManager NodeManager |
| hadoop02 | DataNode | NodeManager |
| hadoop03 | DataNode | DataNode SecondaryNameNode |
2.安装hadoop
进入software目录下
cd /export/software/
下载安装包
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz
解压安装包进入server目录下
cd /export/server
tar -zxvf /export/software/hadoop-3.3.5.tar.gz
3.hadoop文件
hadoop配置需要修改6个文件core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、workers。
(1)修改环境配置
vim /etc/profile
#hadoop
export HADOOP_HOME=/export/servers/hadoop-3.3.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/sbin
export PATH=$PATH:/export/servers/hadoop-3.3.5/bin
export JAVA_HOME PATH HADOOP_HOME
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootsource /etc/profile
把hadoop01环境配置分发到hadoop02、hadoop03上面
scp -r /etc/profile hadoop02:/etc/profile
scp -r /etc/profile hadoop03:/etc/profile
都要source /etc/profile
HADOOP_HOME和JAVA_HOME地址位置为你存放hadoop和jdk软件的位置
(2)修改hadoop-env.sh
vim /export/server/hadoop-3.3.5/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_161
(3)修改core-site.xml
vim /export/server/hadoop-3.3.5/etc/hadoop/core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<!-- 配置hadoop数据的存储临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-3.3.5/tmp</value>
</property>
<!-- 配置web端页面的静态用户,设置为自己的用户名 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!--定义HDFS所开放的代理服务 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
(4)修改hdfs-site.xml
vim /export/server/hadoop-3.3.5/etc/hadoop/hdfs-site.xml
<property>
<!-- NameNode 的 web端访问地址(对用户的查询端口)-->
<name>dfs.namenode.http-address</name>
<value>hadoop01:9870</value>
</property>
<!-- SecondaryNameNode 的 web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop03:9868</value>
</property>
<!--关闭安全模式-->
<property>
<name>dfs.safemode.threshold.pct</name>
<value>0.999f</value>
<description>
Specifies the percentage of blocks that should satisfy
the minimal replication requirement defined by dfs.replication.min.
Values less than or equal to 0 mean not to wait for any particular
percentage of blocks before exiting safemode.
Values greater than 1 will make safe mode permanent.
</description>
</property>
(5)修改mapred-site.xml
先输入 hadoop classpath 知道classpath路径复制路径
hadoop classpath
/export/servers/hadoop-3.3.5/etc/hadoop:/export/servers/hadoop-3.3.5/share/hadoop/common/lib/*:/export/servers/hadoop-3.3.5/share/hadoop/common/*:/export/servers/hadoop-3.3.5/share/hadoop/hdfs:/export/servers/hadoop-3.3.5/share/hadoop/hdfs/lib/*:/export/servers/hadoop-3.3.5/share/hadoop/hdfs/*:/export/servers/hadoop-3.3.5/share/hadoop/mapreduce/*:/export/servers/hadoop-3.3.5/share/hadoop/yarn:/export/servers/hadoop-3.3.5/share/hadoop/yarn/lib/*:/export/servers/hadoop-3.3.5/share/hadoop/yarn/*
下面的配置需要用到classpath输出内容,下面标红的就是需要用到classpath输出内容
vim /export/server/hadoop-3.3.5/etc/hadoop/mapred-site.xml
<!-- mapreduce的配置 -->
<!--classic、local:使用本机一台的资源、yarn:使用集群的资源-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器运行机器以及端口 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop02:10020</value>
</property><!-- 历史服务器web端地址 19888,可以查看程序的历史运行情况-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop02:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mr-history/tmp</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mr-history/done</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/export/servers/hadoop-3.3.5/etc/hadoop:/export/servers/hadoop-3.3.5/share/hadoop/common/lib/*:/export/servers/hadoop-3.3.5/share/hadoop/common/*:/export/servers/hadoop-3.3.5/share/hadoop/hdfs:/export/servers/hadoop-3.3.5/share/hadoop/hdfs/lib/*:/export/servers/hadoop-3.3.5/share/hadoop/hdfs/*:/export/servers/hadoop-3.3.5/share/hadoop/mapreduce/*:/export/servers/hadoop-3.3.5/share/hadoop/yarn:/export/servers/hadoop-3.3.5/share/hadoop/yarn/lib/*:/export/servers/hadoop-3.3.5/share/hadoop/yarn/*
</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/export/servers/hadoop-3.3.5/etc/hadoop:/export/servers/hadoop-3.3.5/share/hadoop/common/lib/*:/export/servers/hadoop-3.3.5/share/hadoop/common/*:/export/servers/hadoop-3.3.5/share/hadoop/hdfs:/export/servers/hadoop-3.3.5/share/hadoop/hdfs/lib/*:/export/servers/hadoop-3.3.5/share/hadoop/hdfs/*:/export/servers/hadoop-3.3.5/share/hadoop/mapreduce/*:/export/servers/hadoop-3.3.5/share/hadoop/yarn:/export/servers/hadoop-3.3.5/share/hadoop/yarn/lib/*:/export/servers/hadoop-3.3.5/share/hadoop/yarn/*
</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value> HADOOP_MAPRED_HOME=/export/servers/hadoop-3.3.5/etc/hadoop:/export/servers/hadoop-3.3.5/share/hadoop/common/lib/*:/export/servers/hadoop-3.3.5/share/hadoop/common/*:/export/servers/hadoop-3.3.5/share/hadoop/hdfs:/export/servers/hadoop-3.3.5/share/hadoop/hdfs/lib/*:/export/servers/hadoop-3.3.5/share/hadoop/hdfs/*:/export/servers/hadoop-3.3.5/share/hadoop/mapreduce/*:/export/servers/hadoop-3.3.5/share/hadoop/yarn:/export/servers/hadoop-3.3.5/share/hadoop/yarn/lib/*:/export/servers/hadoop-3.3.5/share/hadoop/yarn/*
</value>
</property>
(6)修改yarn-site.xml
vim /export/server/hadoop-3.3.5/etc/hadoop/yarn-site.xml
<!-- Site specific YARN configuration properties -->
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<!-- 环境变量的继承 container-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property><!-- nodemanager最多给多少内存给resourcemanager-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!--检查物理内存,只要超出任务所给存储就杀死任务,所以这里配置false,避免杀死 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 检查虚拟内存-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop02:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.web-proxy,address</name>
<value>hadoop02:8089</value>
</property>
<property>
<name>yarn.log.aggregation.enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.appliction.classpath</name>
<value> /export/servers/hadoop-3.3.5/etc/hadoop:/export/servers/hadoop-3.3.5/share/hadoop/common/lib/*:/export/servers/hadoop-3.3.5/share/hadoop/common/*:/export/servers/hadoop-3.3.5/share/hadoop/hdfs:/export/servers/hadoop-3.3.5/share/hadoop/hdfs/lib/*:/export/servers/hadoop-3.3.5/share/hadoop/hdfs/*:/export/servers/hadoop-3.3.5/share/hadoop/mapreduce/*:/export/servers/hadoop-3.3.5/share/hadoop/yarn:/export/servers/hadoop-3.3.5/share/hadoop/yarn/lib/*:/export/servers/hadoop-3.3.5/share/hadoop/yarn/*
</value>
<property>
<description>The class to use as the resource scheduler.</description>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
</property>
(7)修改workers
vim /export/server/hadoop-3.3.5/etc/hadoop/workers
hadoop01(主机名的名字)
hadoop02
hadoop03
(8)分发集群
完成在第一台主机上面的配置,就可以分发到例外几台主机了
scp -r /export/servers/hadoop-3.3.5/ hadoop02:/export/servers/
scp -r /export/servers/hadoop-3.3.5/ hadoop03:/export/servers/
4.测试hadoop
(1)集群初始化
如果集群第一次启动需要在第一台机器上进行初始化(如果对集群初始化后发现文件可能配置错了,修改文件后就需要关闭hadoop进程,再次进行初始化)
hdfs namenode -format
(2)启动HDFS
start-dfs.sh
(3)启动yarn
start-yarn.sh
下面为启动后的进程
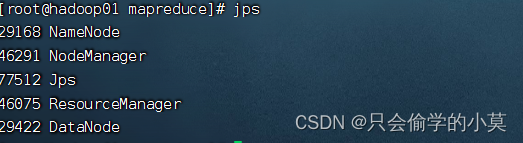
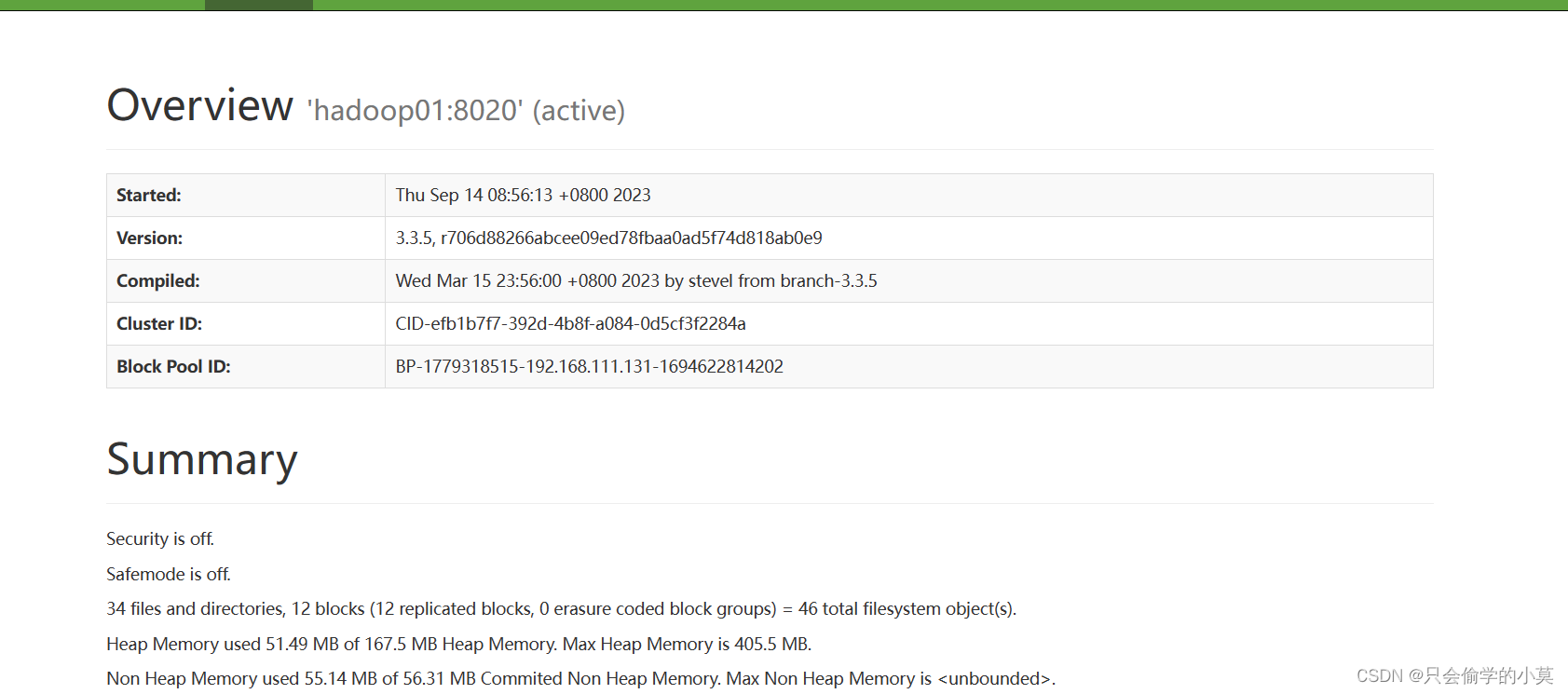
(4)打开web端验证
192.168.111.131:9870(前面为第一台主机的ip地址,后面为端口号)
192.168.111.131:8088
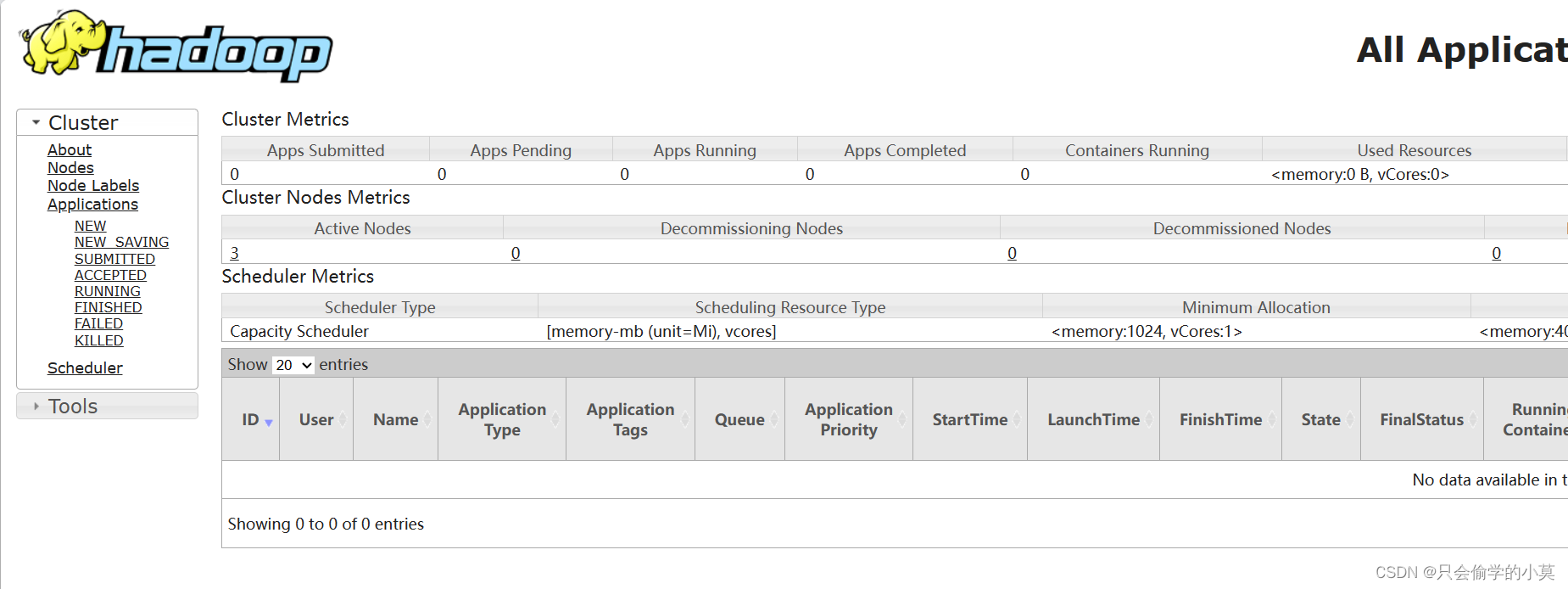
5.MapReduce测试
进入hadoop的MapReduce路径调用hadoop-mapreduce-examples-3.3.5.jar包进行pi计算
cd /export/servers/hadoop-3.3.5/share/hadoop/mapreduce/
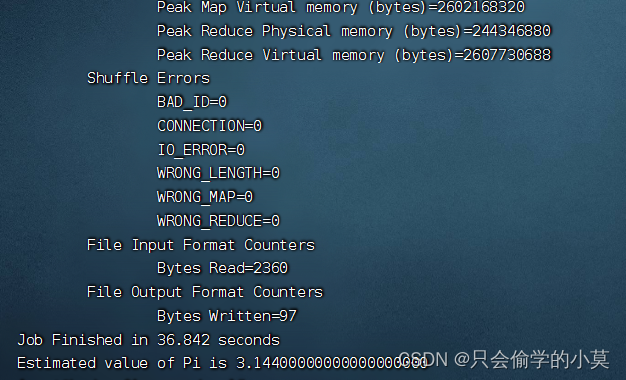
hadoop jar hadoop-mapreduce-examples-3.3.5.jar pi 20 100
计算出结果如图所示
6.hadoop常用的语句
hdfs dfs -ls <path>:列出路径下的所有文件和目录。
hdfs dfs -mkdir <path>:创建目录。
hdfs dfs -put <local_path> <hdfs_path>:将本地文件复制到HDFS中。
hdfs dfs -get <hdfs_path> <local_path>:将HDFS中的文件复制到本地。
hdfs dfs -cat <hdfs_file>:显示HDFS文件的内容。
hdfs dfs -rm <hdfs_path>:删除HDFS中的文件或目录。
hdfs dfs -du <hdfs_path>:显示HDFS中文件或目录的大小。
hdfs dfs mv <src_hdfs_path> <dest_hdfs_path>:将HDFS中的文件或目录移动到目标位置。
hdfs dfs -chown <user>:<group> <hdfs_path>:更改HDFS文件或目录的所有者和组。

















 955
955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









