



 本文详细介绍如何在Eclipse中配置Hadoop环境,包括下载并安装必要的组件、配置Hadoop和JDK环境变量、以及在Eclipse中设置Hadoop位置等步骤。同时,还提供了常见问题的解决方案。
本文详细介绍如何在Eclipse中配置Hadoop环境,包括下载并安装必要的组件、配置Hadoop和JDK环境变量、以及在Eclipse中设置Hadoop位置等步骤。同时,还提供了常见问题的解决方案。
参考 http://www.powerxing.com/hadoop-build-project-using-eclipse/
hadoop-eclipse-plugin下载地址
第一步:选择 Window 菜单下的 Preference。
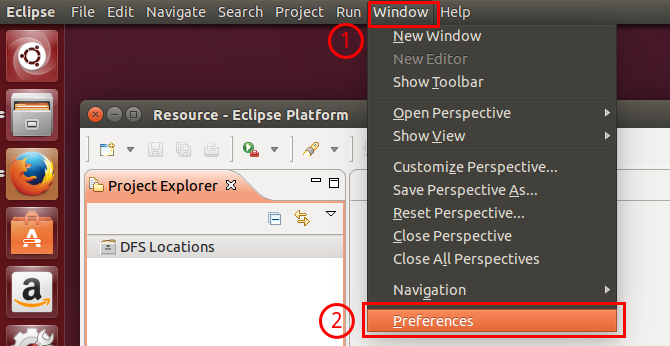
打开Preference
此时会弹出一个窗体,窗体的左侧会多出 Hadoop Map/Reduce 选项,点击此选项,选择 Hadoop 的安装目录(如/usr/local/hadoop,Ubuntu不好选择目录,直接输入就行)。
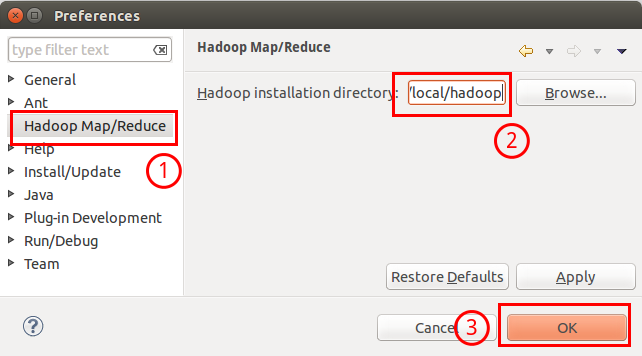 选择 Hadoop 的安装目录
选择 Hadoop 的安装目录
第二步:切换 Map/Reduce 工作目录,选择 Window 菜单下选择 Open Perspective -> Other,弹出一个窗体,从中选择 Map/Reduce 选项即可进行切换。
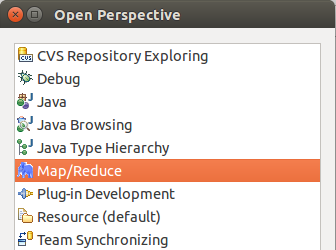
切换 Map/Reduce 工作目录
第三步:建立与 Hadoop 集群的连接,点击 Eclipse软件右下角的 Map/Reduce Locations 面板,在面板中单击右键,选择 New Hadoop Location。
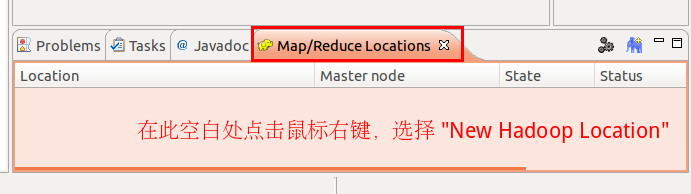
建立与 Hadoop 集群的连接
在弹出来的 General 选项面板中进行 Master 的设置,设置要要 Hadoop 的配置一致,如我使用的Hadoop伪分布式配置,设置了 fs.defaultFS 为 hdfs://localhost:9000,则 DFS Master 那的 Post 也应改为 9000。
Location Name 随意填写,Map/Reduce Master 的 Host 就填写你本机的IP(localhost 也行),Port 默认就是 50020。最后的设置如下:
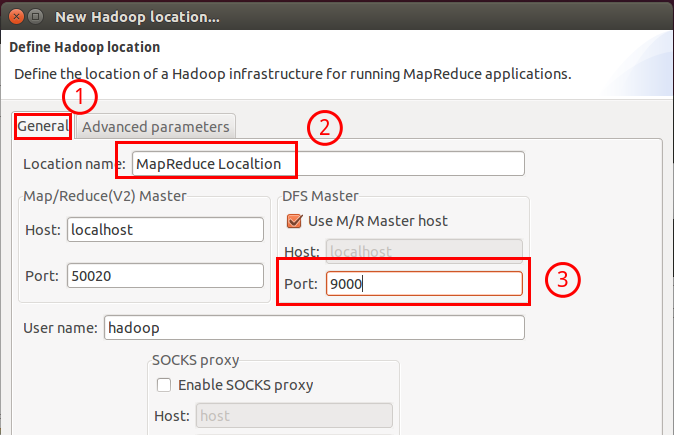
Hadoop Location 的设置
接着再切换到 Advanced parameters 选项面板,这边有详细的配置,切记需要与 Hadoop 的配置(/usr/local/hadoop/etc/hadoop中的配置文件)一致,如我配置了 hadoop.tmp.dir ,就要进行修改。
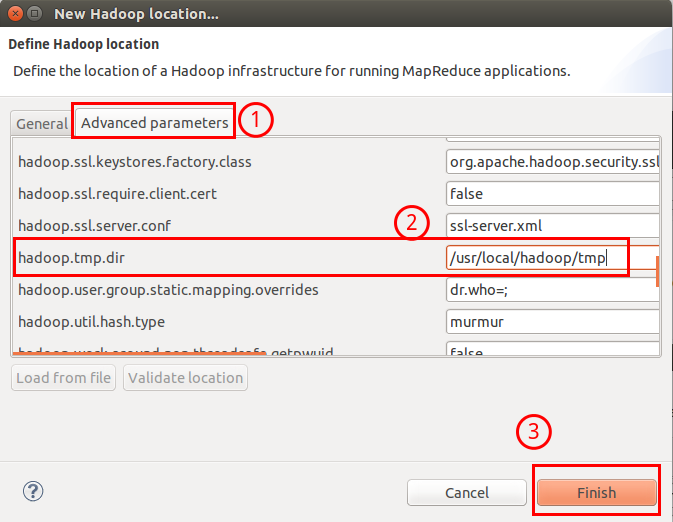
Hadoop Location 的设置
最后点击 finish,Map/Reduce Location 就创建好了。
这样配置就完成了。
在 Eclipse 中运行 MapReduce 项目会遇到的问题
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export JRE_HOME=/usr/lib/jvm/java-7-openjdk-amd64/jre
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#set hadoop environment
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
#set scala environment
export SCALA_HOME=/usr/local/scala-2.10.4
export PATH=$PATH:$SCALA_HOME/bin
#set spark environment
export SPARK_HOME=/usr/local/spark-1.5.2
export PATH=$PATH:$SPARK_HOME

















 515
515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









