




 YARN是Hadoop的资源管理系统,由ResourceManager、ApplicationMaster、NodeManager和Container组成。ResourceManager通过Scheduler和ApplicationsManager管理集群资源,ApplicationMaster与NodeManager协作执行任务。Container作为资源抽象,封装了节点上的内存和CPU等资源。Job运行流程包括提交Job、调度资源、启动Task、监控进度直至Job完成。YARN允许灵活的资源分配,优化了集群资源利用率。
YARN是Hadoop的资源管理系统,由ResourceManager、ApplicationMaster、NodeManager和Container组成。ResourceManager通过Scheduler和ApplicationsManager管理集群资源,ApplicationMaster与NodeManager协作执行任务。Container作为资源抽象,封装了节点上的内存和CPU等资源。Job运行流程包括提交Job、调度资源、启动Task、监控进度直至Job完成。YARN允许灵活的资源分配,优化了集群资源利用率。
YARN是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
YARN通用资源管理框架组成部分:
1,ResourceManager(RM):由Scheduler(资源调度器)和ApplicationsManager(ASM:应用管理器)2个组件组成。RM和每个NodeManager (NM)构成一个资源估算框架,管理协调分配集群中的资源,对集群中所有的资源拥有最终最高级别的仲裁权。
Scheduler:资源调度器主要负责将集群中的资源分配。Yarn默认实现了如下资源调度器:

ApplicationsManager:应用管理器主要负责接收应用程序,协商获取第一个Container用于执行AM,并且在AM Container失败后,提供重启服务。
2,ApplicationMaster(AM):主要与RM协商获取应用程序所需资源。实际的资源都在NM中,所以AM和NM合作,在NM中运行任务,AM和MapReduce TASK都运行在Container中,Container由RM调度(启动/停止)并由NM(NodeManager)管理,监控所有Task的运行情况,在任务运行失败时,重新为任务申请资源以启动任务。
注:(MRAppMaster是mapreduce的ApplicationMaster实现)
3,Nodemanager(NM):用来启动和监控本地计算机资源单位Container的利用情况,是每个节点上的资源和任务管理器,定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态,并且接受并处理来自AM的Container启动/停止等请求。
4,Container:Container是yarn资源的抽象,它封装了某个节点上的多维度资源(内存,cpu,磁盘,网络等),当AM向RM申请资源时,RM为AM返回的资源便是用 Container表示的。yarn会为每个任务分配一个Container,且该任务只能使用该Container描述的资源,它是一个动态资源划分单位,是根据应用程序的需求动态生成的。(目前yarn只支持cpu和内存2种资源)
注:(YarnChild是Container实现)
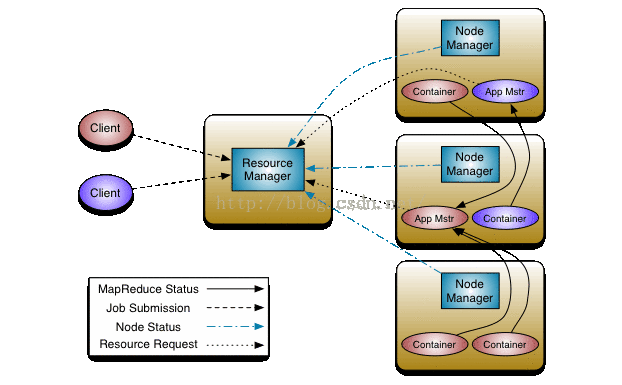
来源:http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html
JOB运行流程:
1:用户向YARN中提交JOB,当在配置文件中设置mapreduce.framework.name为yarn时候,MapReduce2.0继承接口ClientProtocol的模式就激活了。RM会生成新的Job ID(即Application ID),接着Client计算输入分片,拷贝资源(包括Job JAR文件、配置文件,分片信息)到HDFS,最后用submitApplication函数提交JOB给RM。
获取新的JobID源码(org.apache.hadoop.mapred.YARNRunner):
@Override
public JobID getNewJobID() throws IOException, InterruptedException {
return resMgrDelegate.getNewJobID();
}
submitApplication提交应用程序源码(org.apache.hadoop.mapred.YARNRunner):
@Override
public JobStatus submitJob(JobID jobId, String jobSubmitDir, Credentials ts)
throws IOException, InterruptedException {
addHistoryToken(ts);
// Construct necessary information to start the MR AM
ApplicationSubmissionContext appContext =
createApplicationSubmissionContext(conf, jobSubmitDir, ts);
// Submit to ResourceManager
try {
ApplicationId applicationId =
resMgrDelegate.submitApplication(appContext);
ApplicationReport appMaster = resMgrDelegate
.getApplicationReport(applicationId);
String diagnostics =
(appMaster == null ?
"application report is null" : appMaster.getDiagnostics());
if (appMaster == null
|| appMaster.getYarnApplicationState() == YarnApplicationState.FAILED
|| appMaster.getYarnApplicationState() == YarnApplicationState.KILLED) {
throw new IOException("Failed to run job : " +
diagnostics);
}
return clientCache.getClient(jobId).getJobStatus(jobId);
} catch (YarnException e) {
throw new IOException(e);
}
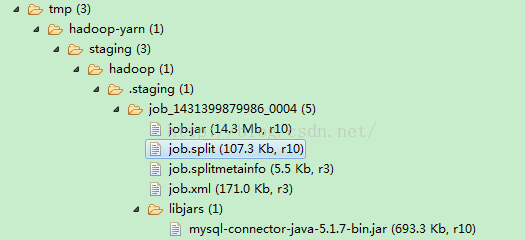
}通过Eclipse的Hadoop插件,可以查看应用程序的相关信息:
2:ASM(应用管理器)接受submitApplication方法提交的JOB,则将其请求交给Scheduler(调度器)处理,Scheduler(调度器)分配Container,同时RM在NM上分配应用程序第一个Container来启动AM进程,MRAppMatser会初始化一定数量的记录对象(bookkeeping)来跟踪JOB的运行进度, 并收集每个TASK的进度和完成情况,接着MRAppMaster收集计算后的输入分片情况,如果应用程序很小,能在同一个JVM上运行,则用uber模 式,下面会讲满足什么情况才采用uber模式。
3: 如果不在uber模式下运行,则Application Master会为所有的Map和Reducer Task向RM请求Container,所有的请求都通过heartbeat(心跳)传递,心跳也传递其他信息,例如关于map数据本地化的信息,分片所 在的主机和机架地址信息,这些信息帮助调度器来做出调度的决策,调度器尽可能遵循数据本地化或者机架本地化的原则分配Container。
在 Yarn中,例如,用yarn.scheduler.capacity.minimum- allocation-mb设置最小申请资源1G,用yarn.scheduler.capacity.maximum-allocation-mb设置最大可申请资源10G 这样一个Task申请的资源内存可以灵活的在1G~10G范围内
4: 获取到Container后,NM上的Application Master就联系NM启动Container,Task最后被一个叫org.apache.hadoop.mapred.YarnChild的main 类执行,不过在此之前各个资源文件已经从分布式缓存拷贝下来,这样才能开始运行map Task或者reduce Task。PS:YarnChild是一个(dedicated)的JVM。
5:当Yarn运行同时,各个Container会报告它的进度和状态给Application Master,客户端会每秒轮询检测Application Master,这样就随时收到更新信息,这些信息可以通过Web UI来查看。
6:客户端每5秒轮询检查Job是否完成,期间需要调用函数Job类下waitForCompletion()方法,Job结束后该方法返回。轮询时间间隔可以用配置文件的属性mapreduce.client.completion.pollinterval来设置
7:应用程序运行完成后, MRAppMaster向ResourceManager注销并关闭自己。
YARN能够调度CPU和内存,有些任务使用CPU比较多,有些任务就比较占内存,所以要根据任务的特点合理的利用计算机资源。


















 142
142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









