






在OpenAI的“12天OpenAI”盛会的第二幕中,他们揭开了o1模型的强化微调(Reinforcement Fine-Tuning, RFT)的神秘面纱,这一创新的突破性进展预示着传统微调时代的终结。RFT不仅仅是复制已有的模式,它赋予了模型深层次的推理能力。
OpenAI通过强化学习的技术,旨在赋予各组织构建专家级别的人工智能的能力,以便在法律、医疗、金融等高复杂度领域中大显身手。这种创新的方法允许组织以极小的数据量——有时仅需12个样本——通过强化学习来训练模型,处理特定领域的任务。
这种新方法与传统的监督式微调不同。根据OpenAI的说法,模型不仅仅学习复制训练数据的风格和语调,而是可以通过问题发展出新的“思考”方式。在给出一个问题时,模型有时间以o1风格解决它。然后评估系统对答案进行评分——加强成功的推理模式,同时削弱错误的模式。
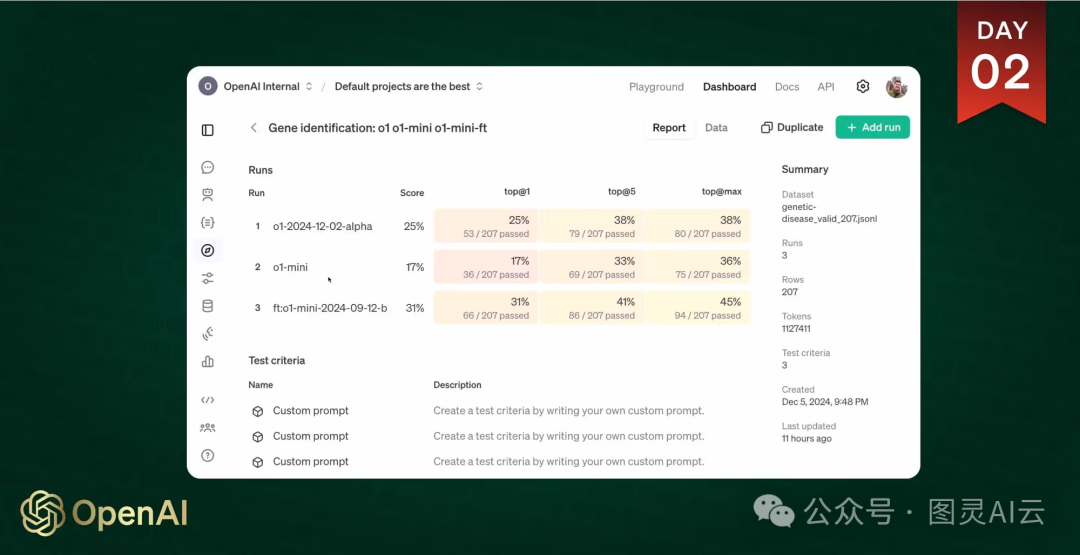
RFT通过参考答案来评估和完善模型的输出,从而在专家级别的任务中提升了推理和准确性。OpenAI通过微调o1-mini模型展示了这一技术,使其在预测遗传疾病方面比之前的版本更为精确。
模型微调的新篇章
与常规的微调不同,RFT专注于培养模型的思考和推理能力,正如OpenAI研究主管Mark Chen所言:“这不是普通的微调……它利用了强化学习算法,使我们的能力从高级高中水平提升到了专家博士水平。”
局限性:尽管如此,这种方法并非万能。OpenAI工程师John Allard指出,RFT在那些结果“客观正确且广泛认可”的任务中表现出色,但在主观性强或创造性应用中,由于共识难以定义,可能会遇到挑战。
与传统的完整微调相比,RFT在计算上更为高效。然而,批评者指出,RFT的性能严重依赖于任务设计和训练数据的质量。
有趣的是,RFT仅需几十个样本就能实现显著的性能提升,因为模型是从反馈中学习,而不需要看到所有可能的场景。
早期采用者,包括伯克利实验室的研究人员,已经取得了显著的成果。例如,经过微调的o1-mini模型在识别导致罕见疾病的遗传突变方面优于其基础版本。
OpenAI已经向选定的组织开放了其RFT alpha计划。参与团队将获得OpenAI的基础设施访问权限,以训练针对其独特需求优化的模型。Allard表示:“开发者现在可以利用我们内部使用的工具来构建特定领域的专家模型。”
计算生物学家Justin Reese强调了RFT在医疗保健中的变革潜力,尤其是对于影响数百万人的罕见疾病。他说:“将领域专业知识与生物医学数据上的系统推理相结合是改变游戏规则的。”
同样,OpenAI与汤森路透的合作已经在法律模型的微调中展示了成功,为法律和保险等高风险领域的增强AI应用铺平了道路。
AI定制的新纪元
OpenAI计划在2025年公开发布RFT,并旨在根据早期参与者的反馈进行完善。除了最初的应用之外,OpenAI设想RFT模型能在数学、研究和基于代理的决策等领域取得进展。Chen说:“这是为了为人类最复杂的挑战创造超专业化的工具。”
简而言之,这项技术将OpenAI的o1系列模型转变为特定领域的专家,使它们在复杂、高风险的任务中以无与伦比的准确性进行推理,胜过它们的基础版本。
常规微调通常涉及在新数据集上训练预训练模型,使用监督学习,模型根据数据集中提供的确切输出或标签调整其参数。
另一方面,RFT使用强化学习,模型从其性能的反馈中学习,而不仅仅是从直接示例中学习。
与传统的从固定标签中学习不同,模型根据其在任务上的表现按照预定义的评分标准或评分员进行评分。这允许模型探索不同的解决方案,并从结果中学习,专注于提高推理能力。
ChatGPT o1 Pro——奢华之选
在“12天OpenAI”的第一天,公司发布了o1的完整版本和一个新的200美元ChatGPT Pro模型。ChatGPT Pro计划包括Plus计划的所有功能,并提供额外的o1 Pro模式,据说使用“更多的计算力来解决最难问题的最佳答案”。此外,该计划将提供无限访问o1、o1-mini和GPT-4o以及高级语音模式。
OpenAI还宣布了针对模型的新开发者中心功能。这些包括结构化输出、函数调用、开发者消息和API图像理解。OpenAI还表示他们正在努力为o1模型带来API支持。
“为了额外澄清:o1在我们的Plus层级中可用,每月20美元。有了新的Pro层级(每月200美元),它可以为最难的问题进行更深入的思考。大多数用户会对Plus层级的o1非常满意!”OpenAI首席Sam Altman在X上发帖。
社区中的许多人认为200美元对于ChatGPT Pro订阅来说太贵了。“我不认为我需要每月200美元的o1 Pro。o1对我来说已经足够了。嘿,即使是GPT-4o对我来说也足够了,”一位用户在X上发帖。
“ChatGPT o1 Pro感觉就像买了一辆兰博基尼。你加入了吗?”另一位用户发帖。
沃顿商学院副教授Ethan Mollick,他有早期访问o1的权限,分享了他的体验,并将其与Claude Sonnet 3.5和Gemini进行了比较。他说:“它可以解决一些博士级别的问题,在科学、金融和其他高价值领域有明显的应用。发现用途将需要真正的研发努力。”
他解释说,虽然o1在解决Sonnet难以解决的特定难题方面优于Sonnet,但它并不是在每个领域都超越Sonnet。Sonnet在其他领域仍然更强。“o1作为作家并不更好,但它通常能够比Sonnet更好地发展复杂的情节,因为它可以更好地提前计划,”他说。
一位Reddit用户分享了他们在实际应用中测试OpenAI的o1 Pro(200美元)与Claude Sonnet 3.5(20美元)8小时后的体验。
在复杂推理方面,o1 Pro是赢家,提供了稍微更好的结果,但每个响应需要多花20-30秒。Claude Sonnet 3.5虽然更快,在这些任务上达到了90%的准确率。在代码生成方面,Claude Sonnet 3.5优于o1 Pro,产生了更干净、更易于维护的代码和更好的文档,而o1 Pro倾向于过度设计解决方案。
同样,Abacus AI的负责人Bindu Reddy说,根据她自OpenAI尚未发布API以来进行的手动测试,Sonnet 3.5在编码方面的表现仍然优于o1。
“早期迹象表明,当涉及到编码时,Sonnet 3.5仍然占据统治地位。我们能够在OpenAI选择提供API时确认这一结果,”她说。
强化微调有啥特点?
强化微调是人工智能领域的一种先进方法,它增强了AI模型在复杂、特定领域任务中的能力。以下是RFT的主要特点:
-
结合强化学习:RFT融合了强化学习技术,这是一种机器学习方法,其中代理通过在环境中采取行动来实现目标,从而学习如何做出决策。模型通过以奖励或惩罚形式接收的反馈来学习。
-
优化推理能力:与传统的微调不同,后者侧重于训练模型复制基于标记数据的期望输出,RFT优化模型的推理和问题解决能力。它不仅仅是模仿正确答案,而是理解和学习如何做出逻辑决策。
-
定制化和专业化:RFT允许创建针对特定领域的AI模型,如法律、医疗、金融或科学。这些模型可以在需要高水平专业知识和精确度的任务中表现出色。
-
效率和易用性:RFT通过向外部开发者提供先进的AI训练方法,使他们即使没有广泛的强化学习专业知识也能创建和实施专业化的AI解决方案,从而降低了进入门槛。
-
开发者友好的界面:使用RFT时,开发者只需要提供一个数据集和一个评分员(评估模型输出的系统),而复杂的强化学习和训练过程则由RFT框架本身处理。
-
突破潜力:通过使AI模型能够在专家级别进行推理,RFT为各个领域带来了显著突破的潜力,因为它可以以超出人类理解的方式提供帮助。
总的来说,强化微调是AI定制化的一个游戏规则改变者,它赋予开发者创建能够在各种复杂任务和行业中以专家水平执行的高度专业化AI模型的能力。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









