






 本文介绍了BeautifulSoup,一个用于解析HTML和XML的Python库,重点讲解了其简单易用性、HTML/XML解析能力、标签选择器和强大的文档遍历功能。通过实例演示了如何使用BeautifulSoup对HTML文件进行读取、解析和数据提取。
本文介绍了BeautifulSoup,一个用于解析HTML和XML的Python库,重点讲解了其简单易用性、HTML/XML解析能力、标签选择器和强大的文档遍历功能。通过实例演示了如何使用BeautifulSoup对HTML文件进行读取、解析和数据提取。
一、Beautiful Soup(中文名为美丽汤)是一个用于解析HTML和XML文档的Python库。它的主要用途是从网页中提取数据,因此常被用于网页爬虫和数据挖掘等任务。Beautiful Soup的特点包括:
-
简单易用: Beautiful Soup提供了一种简单的方式来浏览和搜索HTML文档的树状结构。用户可以方便地遍历文档、查找元素以及提取数据。
-
HTML/XML解析: Beautiful Soup能够解析不规范的HTML和XML文档,并能够处理糟糕的标记和结构,使得在实际应用中更容易提取所需的信息。
-
标签选择器: Beautiful Soup允许使用标签名、属性等多种方式来选择文档中的元素,从而精确定位所需的数据。
-
强大的文档遍历功能: 可以轻松地遍历文档的树状结构,包括向上、向下、和横向导航,方便提取不同深度的数据。
二、下面我们将使用beautifulsoup对解析html文件具体使用
1、准备阶段:
安装所需模块 bs4 以及 lxml
pip insatll bs4
pip insatll lxml
我的html文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>简单的 HTML 页面</title>
</head>
<body>
<h1>欢迎来到我的网页!</h1>
<p>这是一个简单的 HTML 页面示例。</p>
<ul>
<li>项目1</li>
<li>项目2</li>
<li>项目3</li>
</ul>
</body>
</html>
2、使用open对对文件进行读写并创建对象
from bs4 import BeautifulSoup
with open("index.txt", "r",encoding='utf-8') as f:
con = f.read() # 读取本地文件
soup = BeautifulSoup(con, 'lxml')
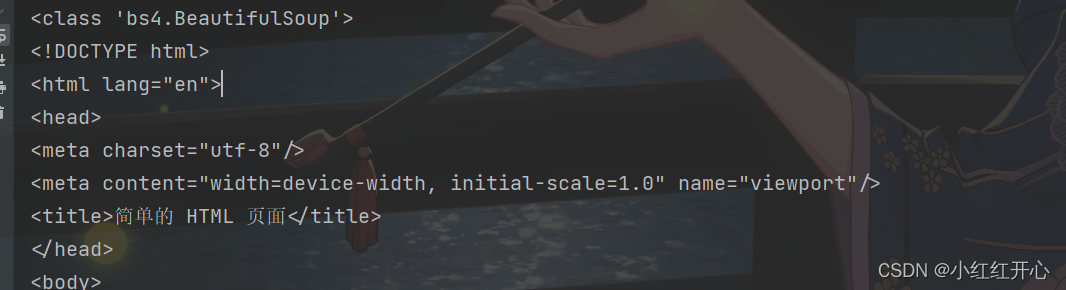
print(type(soup))
print(soup)
二、使用常见的方法来对soup来进行解析
解析方法
find(name, attrs, recursive, string, **kwargs):查找第一个符合条件的标签。
from bs4 import BeautifulSoup
with open("index.txt", "r",encoding='utf-8') as f:
con = f.read() # 读取html文件。
soup = BeautifulSoup(con, 'lxml')
# find(name, attrs, recursive, string, **kwargs):查找第一个符合条件的标签。
print(soup.find('li')) # 查找第一个li标签。
print(type(soup.find('li')))
f.close()

find_all(name, attrs, recursive, string, limit, **kwargs):查找所有符合条件的标签,返回列表。
from bs4 import BeautifulSoup
with open("index.txt", "r",encoding='utf-8') as f:
con = f.read() # 读取html文件。
soup = BeautifulSoup(con, 'lxml')
# find_all(name, attrs, recursive, string, limit, **kwargs):查找所有符合条件的标签,返回列表。
print(soup.find_all('li')) # 查找所有符合条件的标签,返回列表。
print(type(soup.find_all('li')))
# 类型发生改变
print(type(soup.find_all('li')[0]))
f.close()

标签选择方法
from bs4 import BeautifulSoup
with open("index.txt", "r",encoding='utf-8') as f:
con = f.read() # 读取html文件。
soup = BeautifulSoup(con, 'lxml')
# tag.name:获取标签的名字。
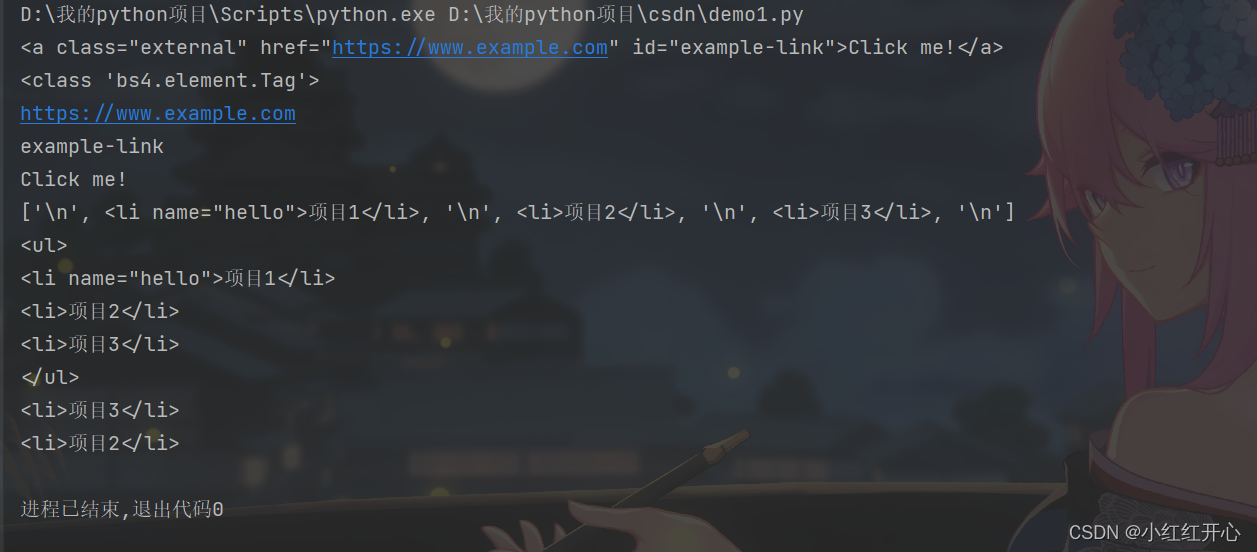
print(soup.find("a"))
print(type(soup.find("a")))
# tag['attribute'] :获取标签的属性值
print(soup.find("a")['href'])
print(soup.find("a")['id'])
# tag.text:获取标签内的文本内容。
print(soup.find("a").text)
# tag.contents:获取标签的子节点,返回一个列表
print(soup.find('ul').contents)
# tag.parent:获取父标签
print(soup.find("li").parent)
# tag.find_next(name, attrs, text, **kwargs):查找下一个符合条件的标签。
print(soup.find("li").find_next("li").find_next("li"))
# tag.find_previous(name, attrs, text, **kwargs):查找前一个符合条件的标签
print(soup.find("li").find_next("li").find_next("li").find_previous("li"))
f.close()
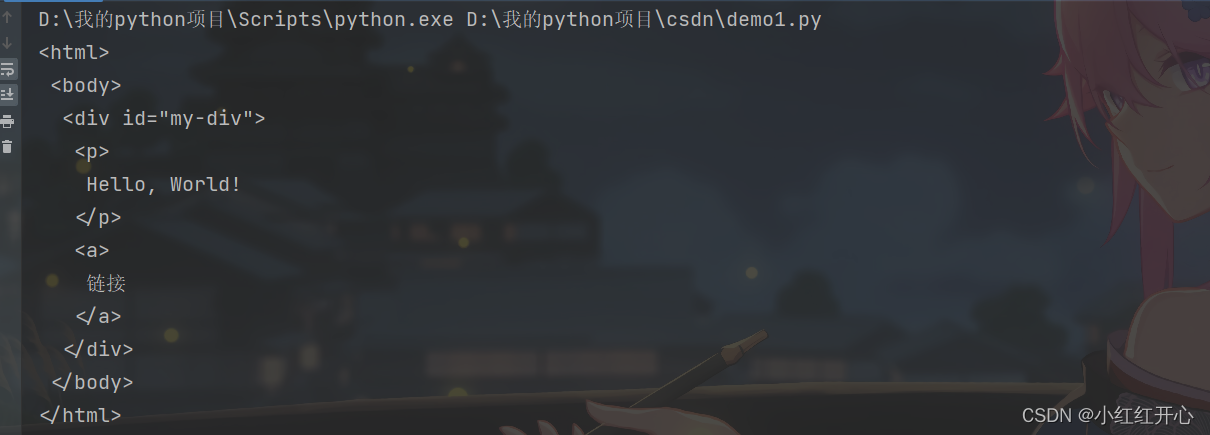
修改文档方法: tag.append(element): 将一个元素追加到标签的子节点列表中。
from bs4 import BeautifulSoup
# 示例HTML文档
html_doc = """
<html>
<body>
<div id="my-div">
<p>Hello, World!</p>
</div>
</body>
</html>
"""
# 解析HTML文档
soup = BeautifulSoup(html_doc, 'html.parser')
# 创建一个新元素
new_element = soup.new_tag("a")
new_element.string = "链接"
# 找到div元素并将新元素追加到其中
div_tag = soup.find(id="my-div")
div_tag.append(new_element)
# 打印修改后的HTML
print(soup.prettify())
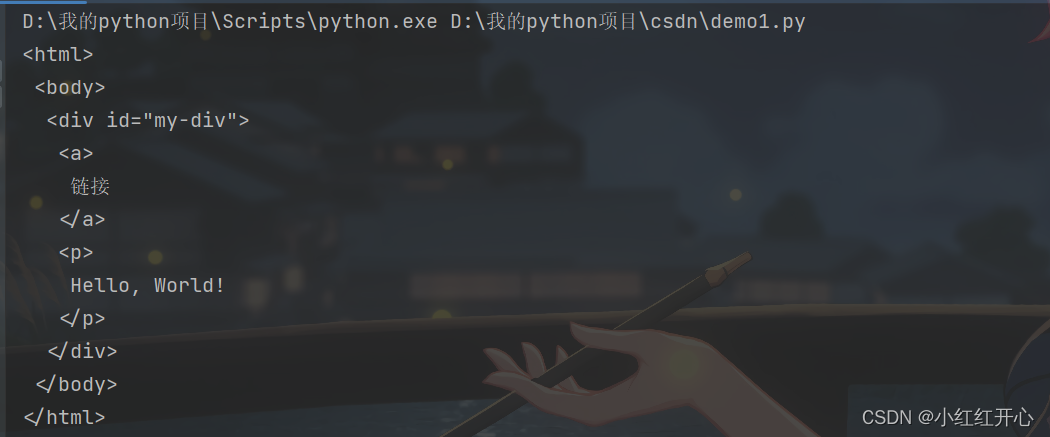
tag.insert(position, element): 在指定位置插入一个元素。
from bs4 import BeautifulSoup
# 示例HTML文档
html_doc = """
<html>
<body>
<div id="my-div">
<p>Hello, World!</p>
</div>
</body>
</html>
"""
# 解析HTML文档
soup = BeautifulSoup(html_doc, 'html.parser')
# 创建一个新元素
new_element = soup.new_tag("a")
new_element.string = "链接"
# 找到div元素并在特定位置插入新元素
div_tag = soup.find(id="my-div")
div_tag.insert(0, new_element) # 在开头插入
# 打印修改后的HTML
print(soup.prettify())
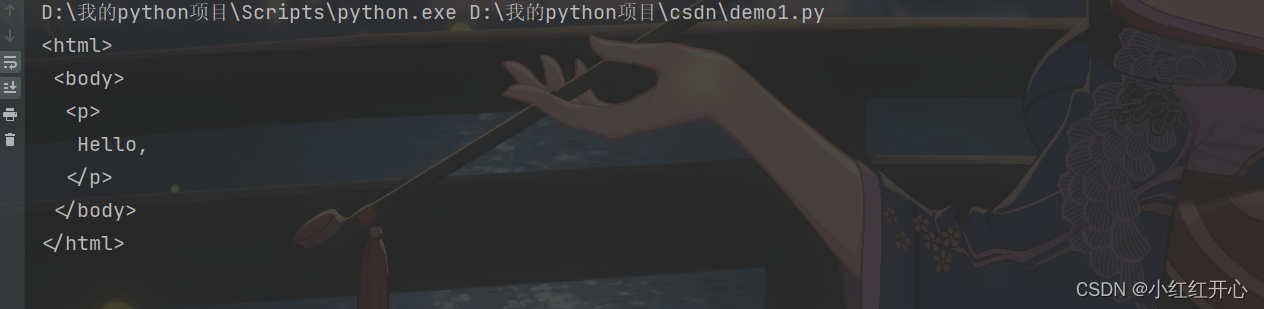
tag.decompose(): 移除标签或字符串,将文档树中的标签删除。
from bs4 import BeautifulSoup
# 示例HTML文档
html_doc = """
<html>
<body>
<p>Hello, <b>World!</b></p>
</body>
</html>
"""
# 解析HTML文档
soup = BeautifulSoup(html_doc, 'html.parser')
# 找到<b>标签并将其移除(删除)
b_tag = soup.find('b')
b_tag.decompose()
# 打印修改后的HTML
print(soup.prettify())
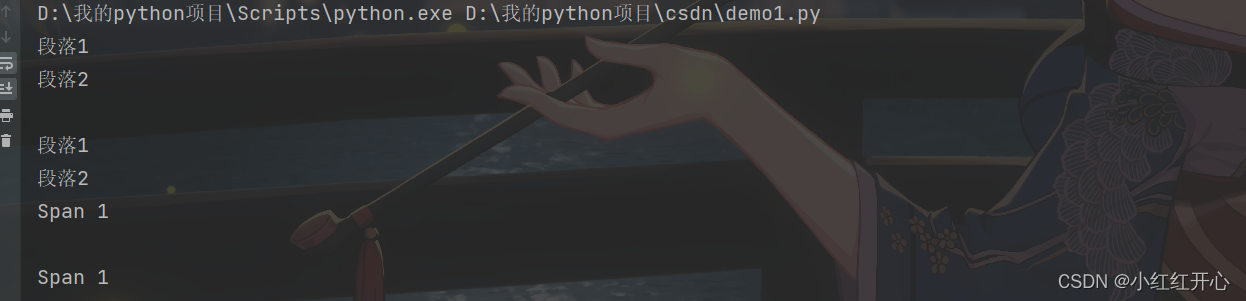
过滤方法:
filter(tag_name, recursive, string, **kwargs): 根据条件过滤标签,返回一个可迭代对象。
from bs4 import BeautifulSoup
# 示例HTML文档
html_doc = """
<html>
<body>
<div class="container">
<p>段落1</p>
<p>段落2</p>
<span>Span 1</span>
</div>
</body>
</html>
"""
# 解析HTML文档
soup = BeautifulSoup(html_doc, 'html.parser')
# 根据标签名过滤
p_tags = soup.find_all('p')
for p in p_tags:
print(p.text)
# 根据class属性过滤
container_div = soup.find(class_='container')
print(container_div.text)
# 根据自定义函数过滤
def custom_filter(tag):
return tag.name == 'span' and 'Span' in tag.text
span_tag = soup.find_all(custom_filter)
for span in span_tag:
print(span.text)



















 1260
1260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











