




 本文深入解析FutureTask组件、Fork/Join框架与BlockingQueue接口在Java并发编程中的应用,涵盖FutureTask的创建与使用,Fork/Join的工作窃取算法及其实现,以及BlockingQueue的多种实现类和适用场景。
本文深入解析FutureTask组件、Fork/Join框架与BlockingQueue接口在Java并发编程中的应用,涵盖FutureTask的创建与使用,Fork/Join的工作窃取算法及其实现,以及BlockingQueue的多种实现类和适用场景。
1.概述
FutureTask这个组件是JUC里边的但是它不是AQS的子类;创建线程有两种方式,一种是继承Thread,一种是实现Runnable接口,这两种方式有一个共同的缺陷就是执行完任务以后无法获取执行结果,从JDK1.5开始就提供了Future和Callable通过他们可以在任务执行完毕以后获取结果;
2.Callable Future FutureTask使用方法
① Callable与Runnable接口的对比
Runnable的代码非常简单,它是一个接口而且只有一个方法run();创建一个类实现它并在里边写一些操作,然后使用线程去执行该Runnable实现类即可以实现多线程;
②Callable的代码也非常简单,不同的是它是一个泛型的接口它里边有一个call()方法,call()方法的返回值类型就是我们创建Callable时传进去的V类型,Callable与Runnable的功能大致相似;相比较而言Callable比Runnable稍微强大一些,因为Callable对线程执行后可以有返回值并且可以抛出异常;
③Future也是一个接口,Future可以取消任务,查询任务是否被取消以及获取结果等操作;通常线程都是异步计算模型的,我们不能直接从别的线程中得到方法的返回值。这个时候我们就可以使用Future来完成;Future可以监视目标线程调用call()的情况,当我们调用Future的get()方法的时候就可以获取到结果,这个时候通常线程可能不会直接完成,当前线程就会开始阻塞,直到call()方法结束,返回结果线程才会继续执行,Future可以得到别的线程任务的方法的返回值。
④ FutureTask它的父类是RunnableFuture,而RunnableFuture继承了Runnable与Future这两个接口,由此我们可以直到FutureTask最终也是执行Callable类型的任务,如果构造函数参数是Runnable的话,它会转换成Callable类型,所以FutureTask即可以作为Runnable被线程执行也可以作为Future拿到线程的执行结果;
3.代码演示
// Future演示
@Slf4j
public class FutureExample {
static class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
log.info("do something in callable");
Thread.sleep(5000);
return "Done";
}
}
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
Future<String> future = executorService.submit(new MyCallable());
log.info("do something in main");
Thread.sleep(1000);
String result = future.get();
log.info("result:{}", result);
}
}

// FutureTask代码演示
@Slf4j
public class FutureTaskExample {
public static void main(String[] args) throws Exception {
FutureTask<String> futureTask = new FutureTask<String>(new Callable<String>() {
@Override
public String call() throws Exception {
log.info("do something in callable");
Thread.sleep(5000);
return "Done";
}
});
new Thread(futureTask).start();
log.info("do something in main");
Thread.sleep(1000);
String result = futureTask.get();
log.info("result:{}", result);
}
}

3.Fork/Join
ForkJoin框架是JDK7提供的一个,用于并行执行任务的框架,他将一个大任务分割成若干个小任务,最终汇总每个小任务的结果后,得到大任务的结果;从字面上看Fork就是切割任务,Join就是合并结果并得到最终的结果;它主要采取的是工作窃取算法,工作窃取算法主要是指某个线程从其他队列里窃取任务来执行;
工作窃取流程图
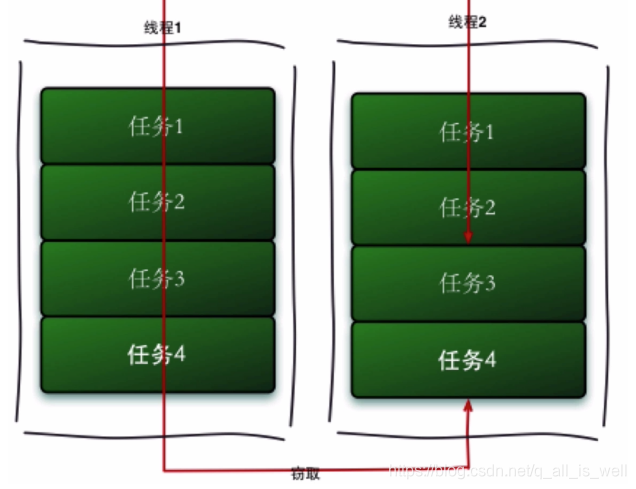
为什么要使用工作窃取算法
原理 :
假如我们需要做一个比较大的任务,我们可以把这个任务分割成互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,为每一个队列创建一个单独的线程,来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A线程里的任务,但是有一些线程会先于其他线程完成任务,这个时候其他线程对应的队列里还有任务等待处理,此时就需要使用工作窃取,来让空闲的线程获取别的线程的任务;但是这个时候多个线程会访问同一个队列,为了减少窃取任务线程与被窃取任务线程之间竞争通常我们会使用双端队列,被窃取任务的线程永远从双端队列的头部拿任务进行处理,而窃取任务的线程从双端队列的底部获取任务执行;
优点 :
这个工作窃取算法的优点就是充分利用线程进行并行计算并减少了线程间的竞争;
缺点 :
它的缺点是在个别情况下还是会存在竞争(比如双端队列里只有一个任务时),同时这样也消耗了更多的系统资源(创建了多个线程和多个双端队列)
工作窃取算法在ForkJoin中的应用 :
对于ForkJoin框架而言,当一个任务正在等待它使用Join操作创建的子任务结束时,执行这个任务的工作线程查找其他未被执行的任务并开始执行,通过这种方式线程充分利用他们的运行时间来提高应用系统的性能,
ForkJoin的局限性 :
由于ForkJoin框架使用了工作窃取算法所以执行的任务有一些局限性;
① 首先任务只能使用Fork和Join操作来实现同步机制,如果使用了其他同步机制,他们在工作时工作线程就不能执行其他任务了;比如在ForkJoin框架中使任务进入休眠状态,那么在休眠期间正在执行的工作线程就不会执行其他任务了;
② 我们拆分的任务不应该去执行IO操作(如读或者写数据文件);
③ 任务不能抛出检查异常,必须通过必要的代码来处理他们;
ForkJoin框架的核心 :
ForkJoinPool : 负责做实现(包括实现工作窃取算法),它管理工作线程和提供关于任务的状态以及执行信息;
ForkJoinTask : 则主要提供在任务中执行Fork和Join操作的机制;
代码演示:
// ForkJoinTask代码演示
@Slf4j
public class ForkJoinTaskExample extends RecursiveTask<Integer> {
public static final int threshold = 2;
private int start;
private int end;
public ForkJoinTaskExample(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
//如果任务足够小就计算任务
boolean canCompute = (end - start) <= threshold;
if (canCompute) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
// 如果任务大于阈值,就分裂成两个子任务计算
int middle = (start + end) / 2;
ForkJoinTaskExample leftTask = new ForkJoinTaskExample(start, middle);
ForkJoinTaskExample rightTask = new ForkJoinTaskExample(middle + 1, end);
// 执行子任务
leftTask.fork();
rightTask.fork();
// 等待任务执行结束合并其结果
int leftResult = leftTask.join();
int rightResult = rightTask.join();
// 合并子任务
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkjoinPool = new ForkJoinPool();
//生成一个计算任务,计算1+2+3+4
ForkJoinTaskExample task = new ForkJoinTaskExample(1, 100);
//执行一个任务
Future<Integer> result = forkjoinPool.submit(task);
try {
log.info("result:{}", result.get());
} catch (Exception e) {
log.error("exception", e);
}
}
}

5、BlockQueue
概述
BlockingQueue意思是阻塞队列,从阻塞这个词我们就可以看出来在某些情况下对阻塞队列的访问可能会造成阻塞;
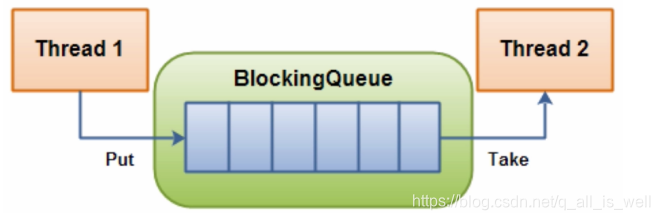
被阻塞的情况
① 当队列已经满了的情况下的入队列操作(除非有另一个线程进行了出队列操作);
② 当队列已经空了的情况下的出队列操作(除非有另一个线程进行了如队列操作);
适用场景
通过上边的介绍以及阻塞队列的特性我们可以得出阻塞队列是线程安全的,它主要使用在生产者消费者的场景;
阻塞队列的常用方法

它提供了4套方法,大家可以根据自己的实际场景来选择;
阻塞队列的实现类
① ArrayBlockingQueue : ArrayBlockingQueue是一个有界的阻塞队列,它的内部实现是一个数组,它的容量是有限的,我们必须在初始化的时候指定容量的大小且指定的大小值在指定以后就不能在更改,它是以先进先出的方式存储数据的,最新插入的对象是尾部最新移除的对象是头部;
② DelayQueue : DelayQueue阻塞的是内部元素,DelayQueue中的元素必须实现Delayed接口,Delayed接口继承了Comparable接口(因为DelayQueue中的元素需要进行排序),一般情况下都是按照元素的过期时间优先级进行排序,DelayQueue的应用场景比如定义关闭连接,缓存对象,超时处理等多种场景,它的内部实现用的是lock(锁)与PriorityQueue(排序)
③ LinkedBlockingQueue : 它的大小是可选的,如果初始化时指定了大小那么它就是有边界的如果不指定就是无边界的(其实使用的默认的最大的整型值),它内部实现是一个链表,处理底层的结构不一样其他的都与ArrayBlockingQueue一样;它也是以先进先出的方式存储数据,最新插入的对象在尾部最新移除的对象在头部,
④ PriorityBlockingQueue : 它是一个带有优先级的阻塞队列且它是一个没有边界的队列但是它是有排序规则的,PriorityBlockingQueue是允许插入null的,在使用的PriorityBlockingQueue的时候需要注意,所以插入的对象必须实现Compilable接口,队列优先级的排序规则就是按照我们对这个接口的实现来定义的,我们可以从PriorityBlockingQueue获取一个迭代器,但是这个迭代器并不保证按照我们的迭代器进行迭代;
⑤ SynchronousQueue : 这个队列内部仅允许容纳一个元素,当一个线程插入一个元素后就会被阻塞,除非这个元素被另一个线程消费,因此我们又称之为同步队列,它是一个无界非缓存的队列准确的说它不存储元素,放入的元素之后等待取走以后才能继续放入;
⑥ BlockingQueue总结
它不仅实现了一个完整队列所具有的基本功能同时在多线程环境下还自动了管理多线程间的自动等待 唤醒功能,从而使开发人员可以忽略这些细节关注更高级的功能;

















 1631
1631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









