 Spark电影数据分析与推荐系统
Spark电影数据分析与推荐系统








博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈:
大数据、Hadoop、Spark、Hive、虚拟机、python语言、Django框架、MySQL数据库、
猫眼电影、电影票房、协同过滤推荐算法、电影推荐、机器学习、票房预测
1、预测总票房----机器学习随机森林回归模型 (machine文件夹)
2、电影推荐----机器学习之基于用户协同过滤推荐算法 (recommend文件夹)
(1)机器学习部分:cosine_similarity 是一个用于计算两个向量之间相似度的函数,属于 sklearn.metrics.pairwise 模块,它在机器学习、数据挖掘和推荐系统中广泛使用。
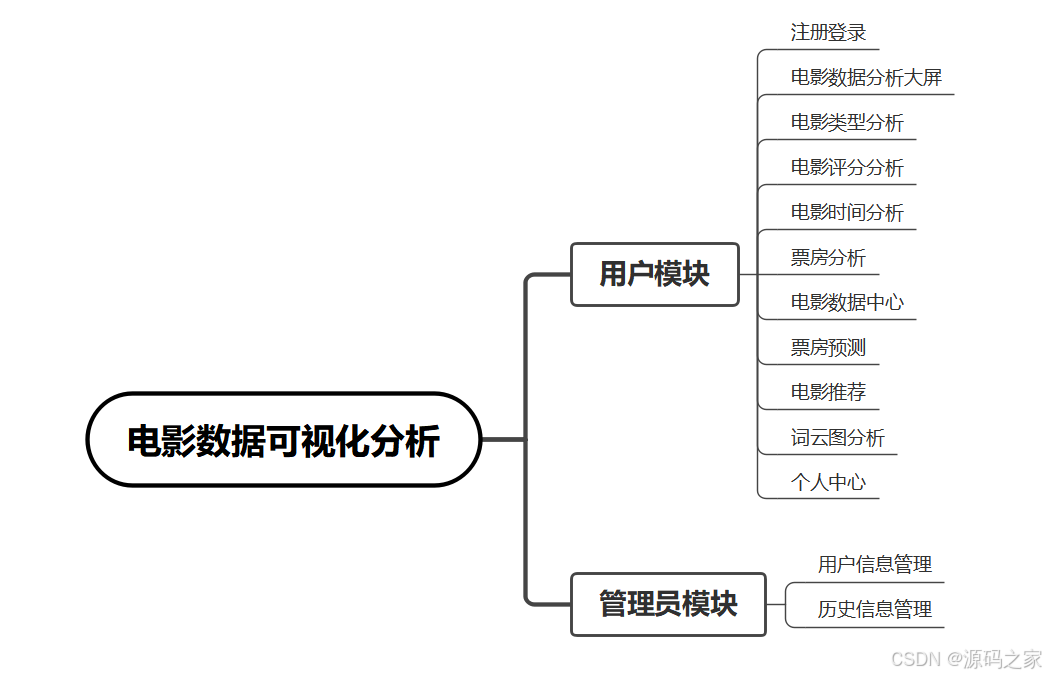
2、项目界面
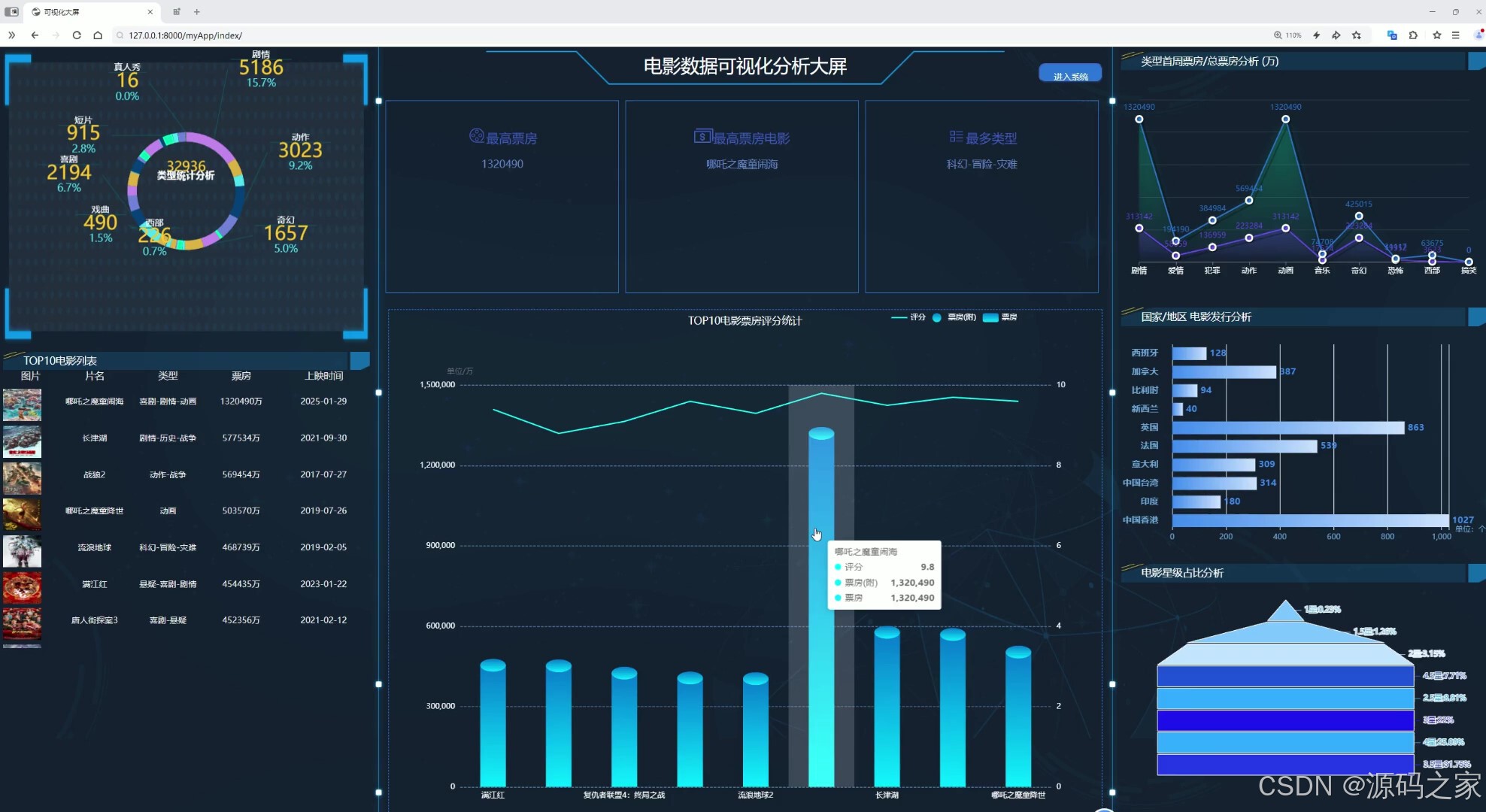
(1)电影数据大屏
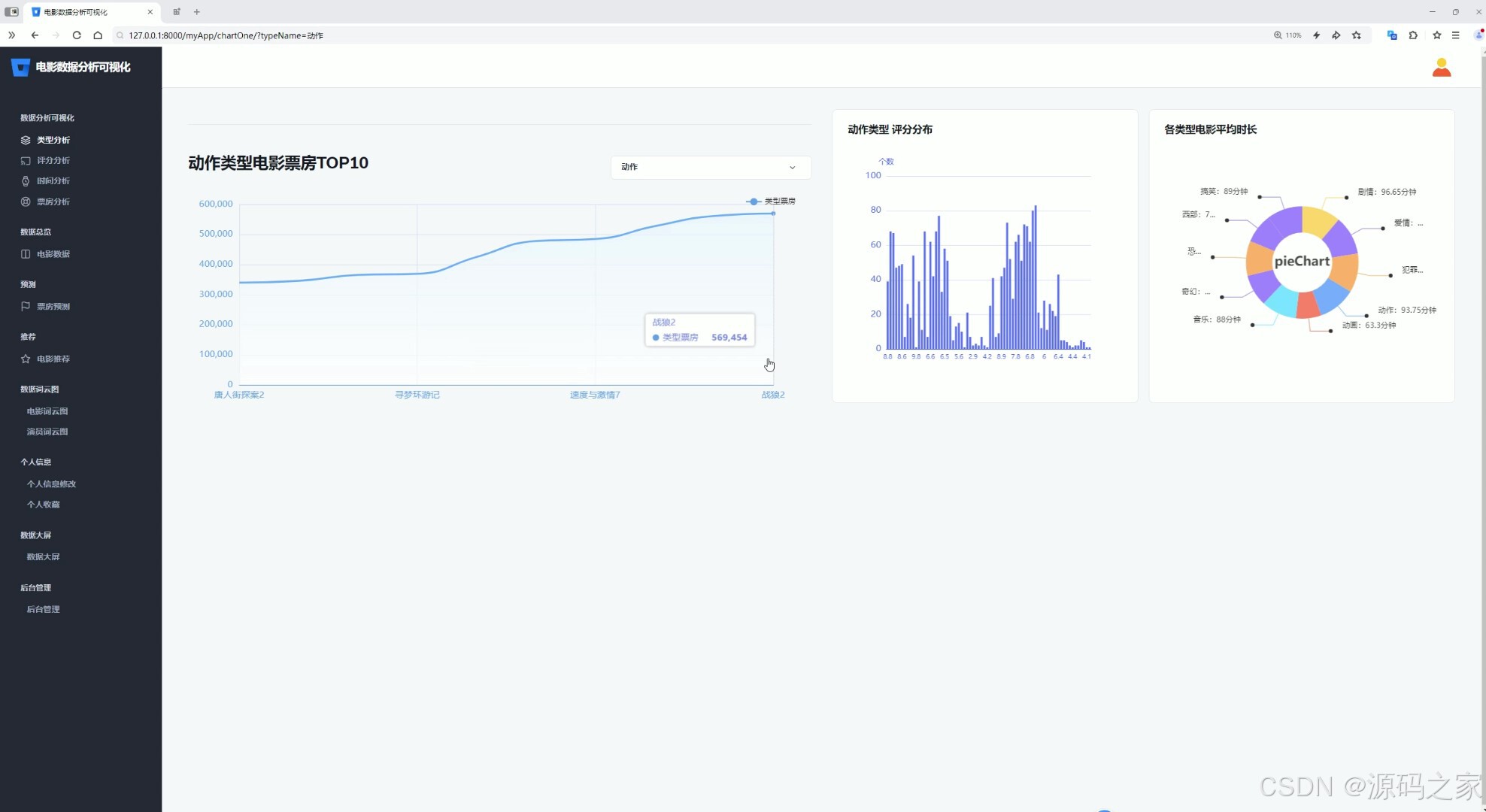
(2)电影类型分析
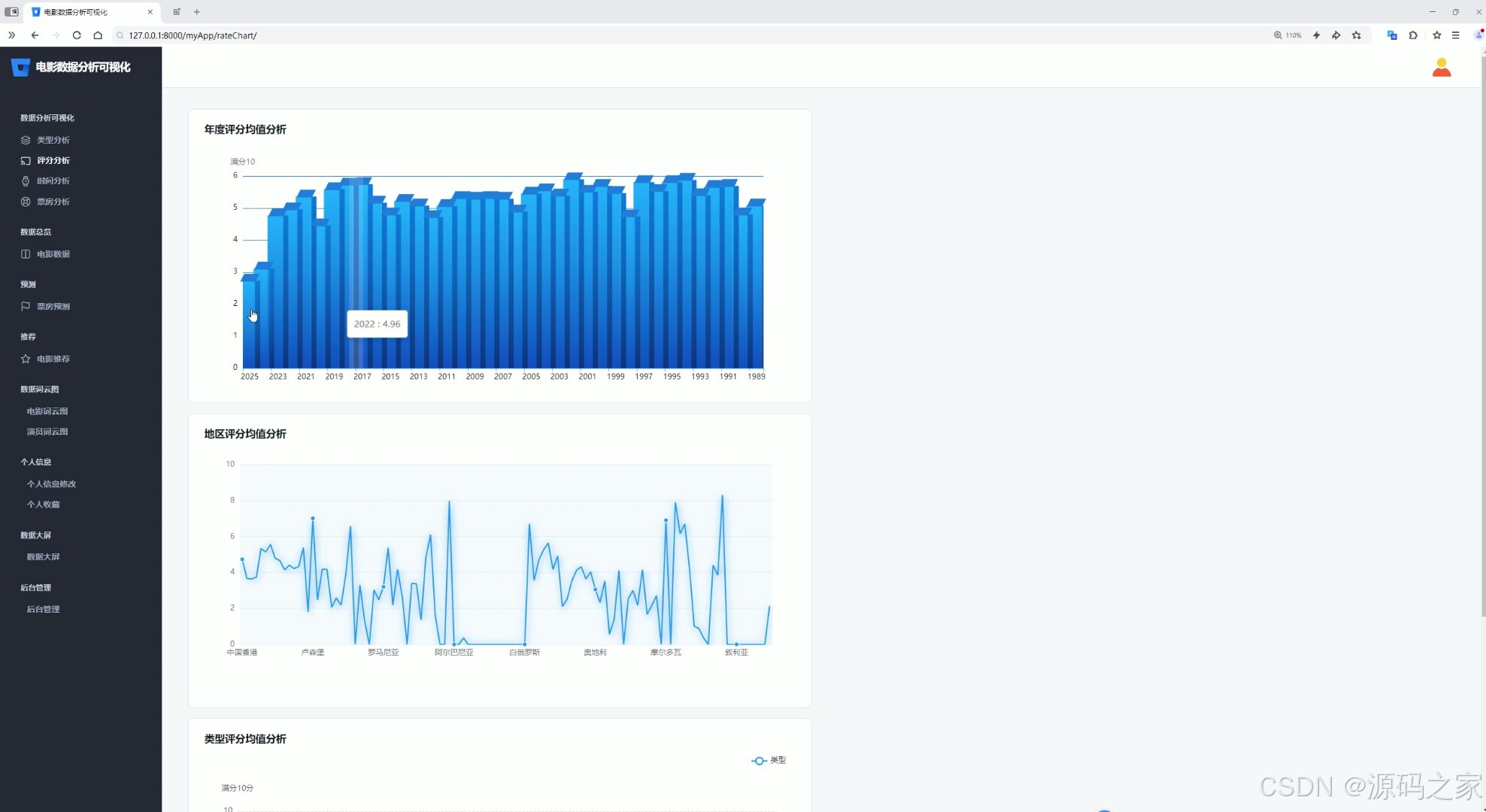
(3)电影评分分析
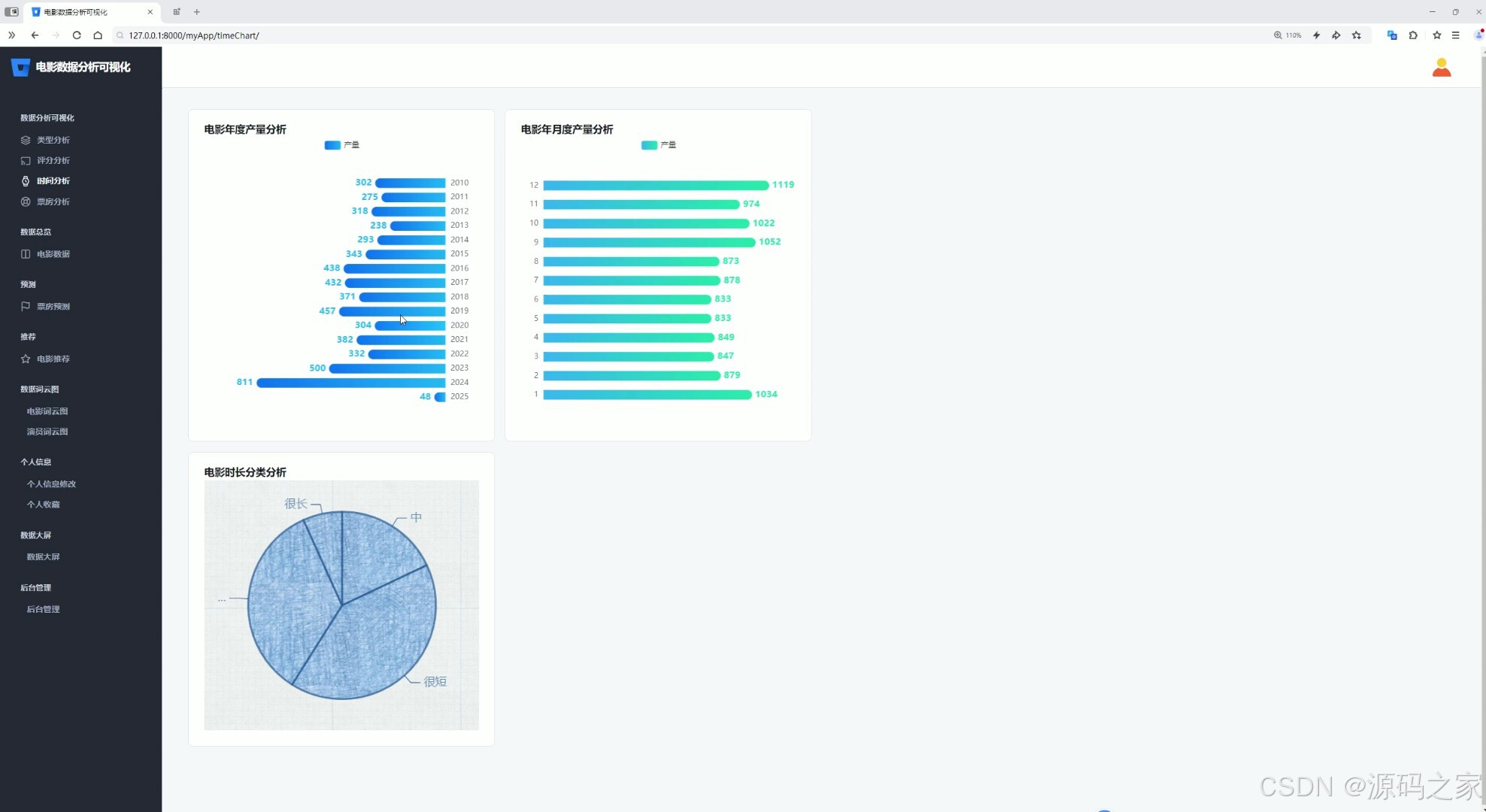
(4)电影时间分析
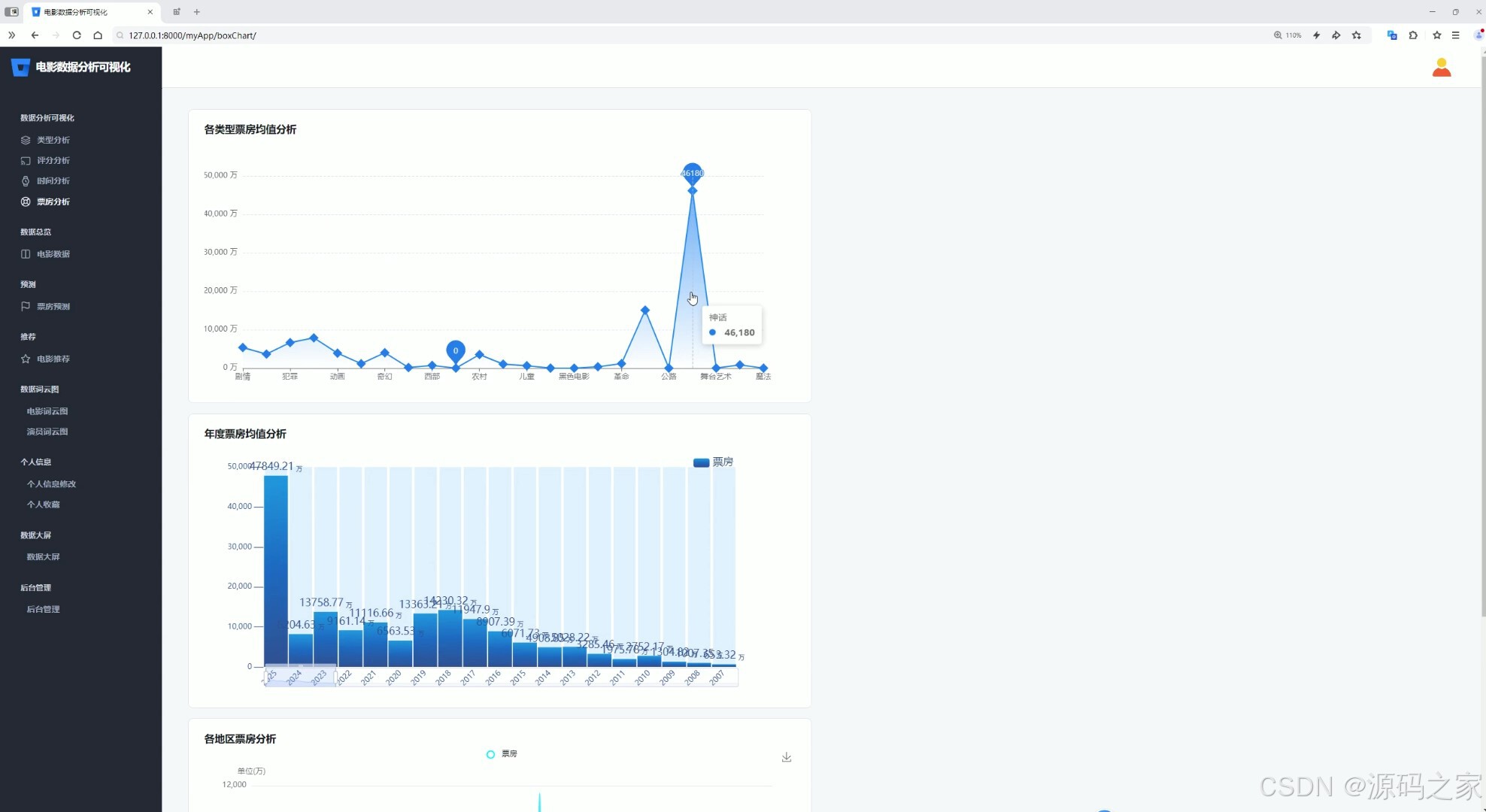
(4)票房分析
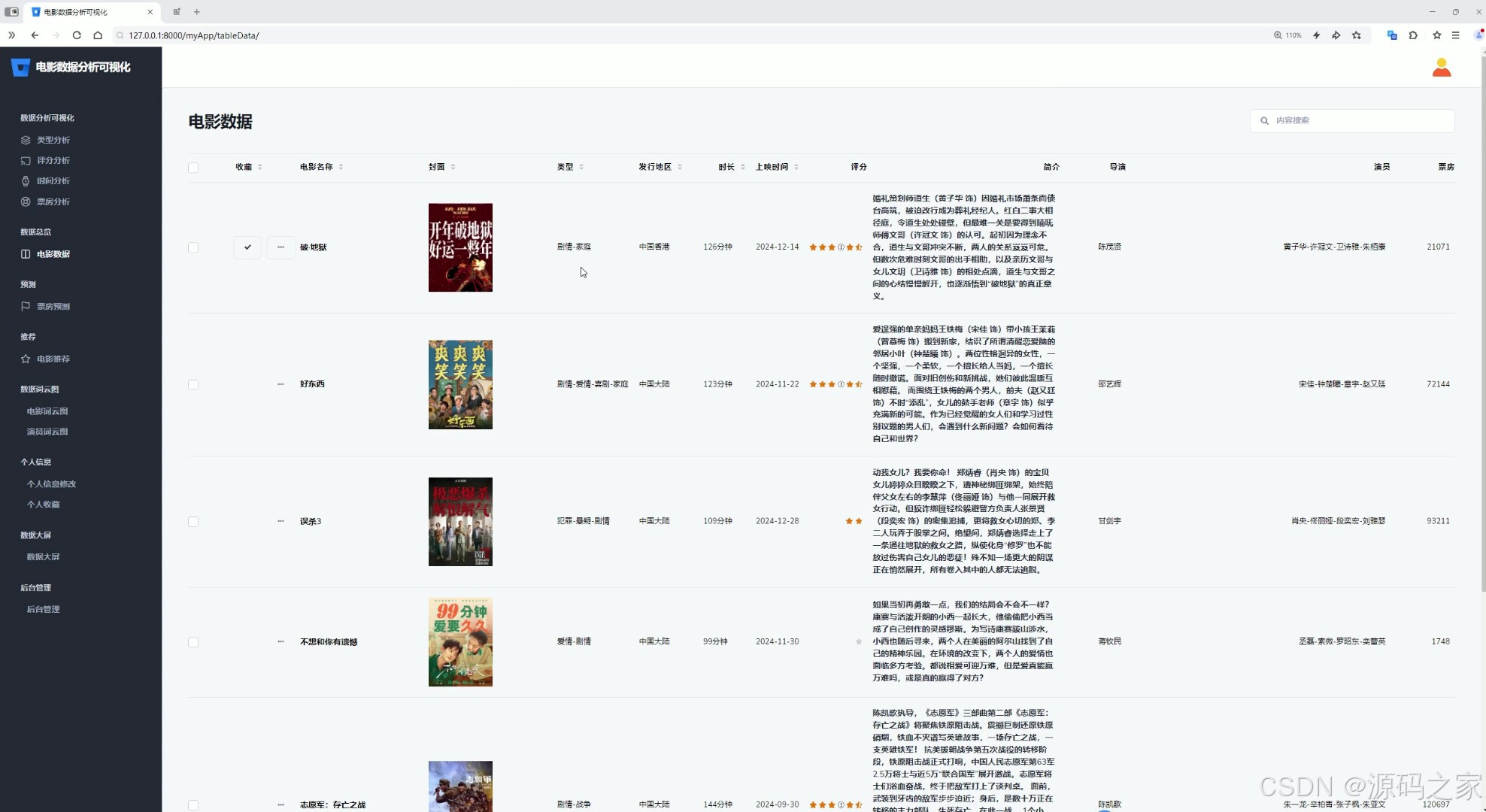
(5)数据中心
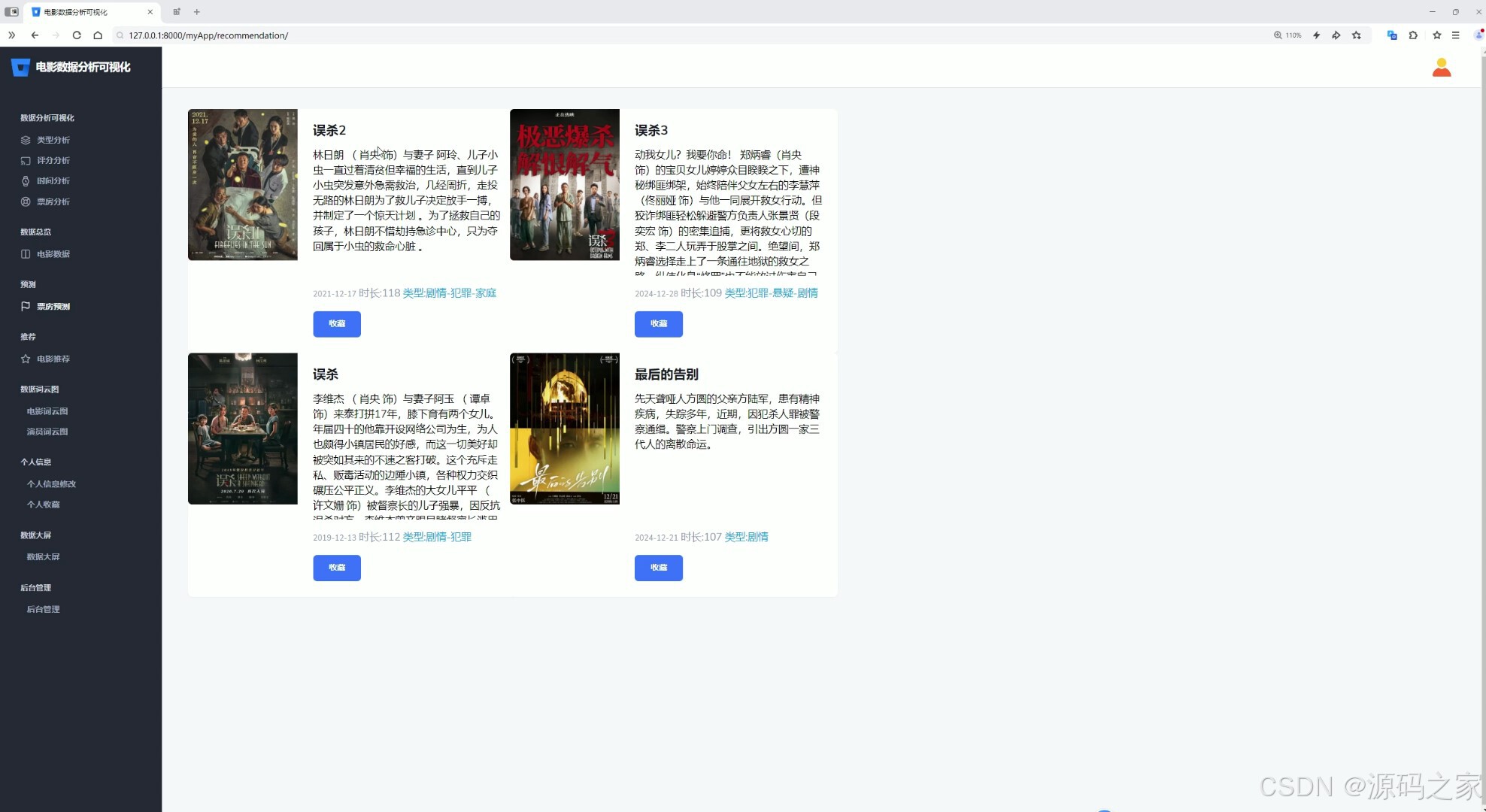
(6)电影推荐
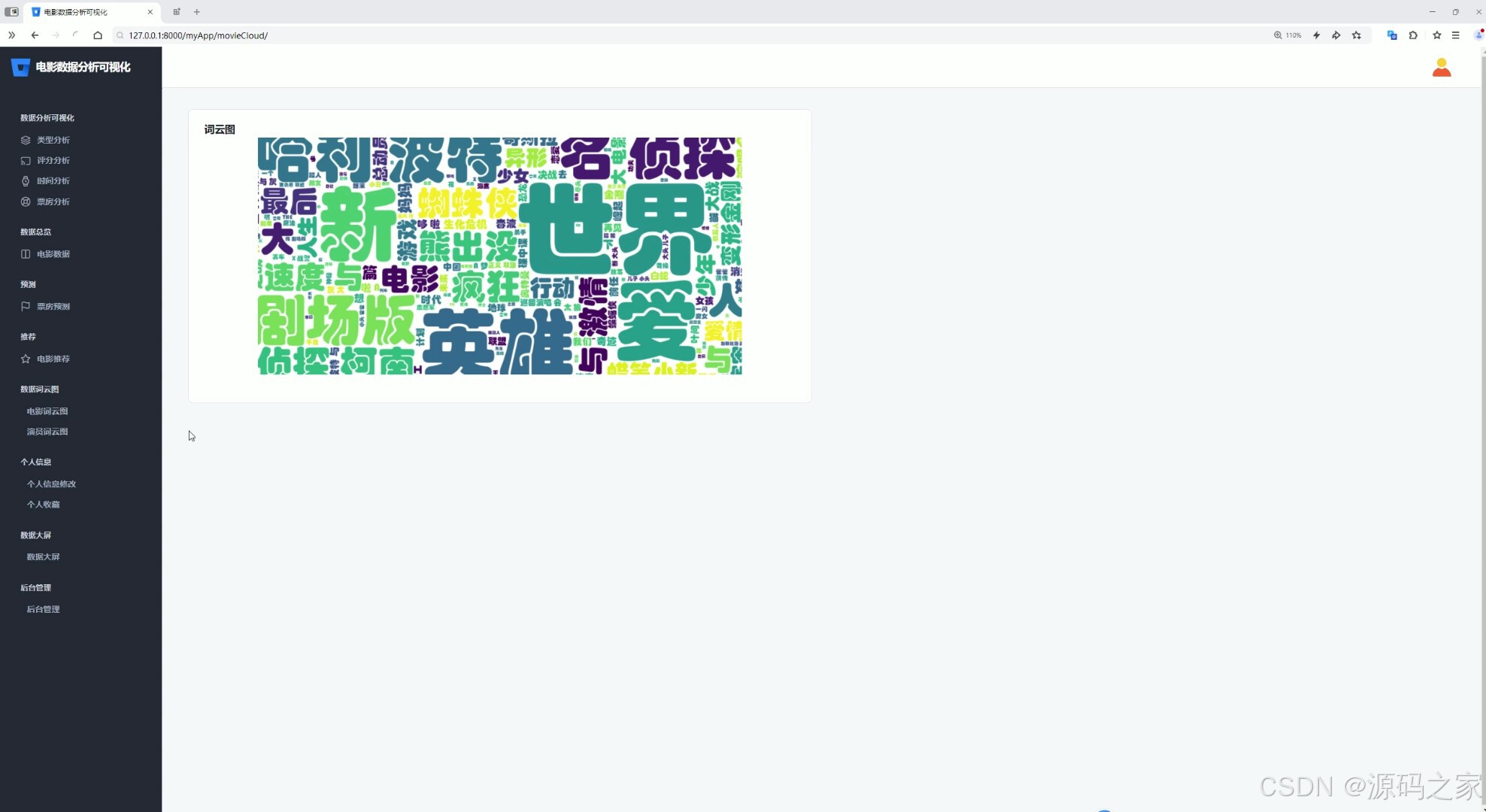
(7)词云图分析
(8)票房预测
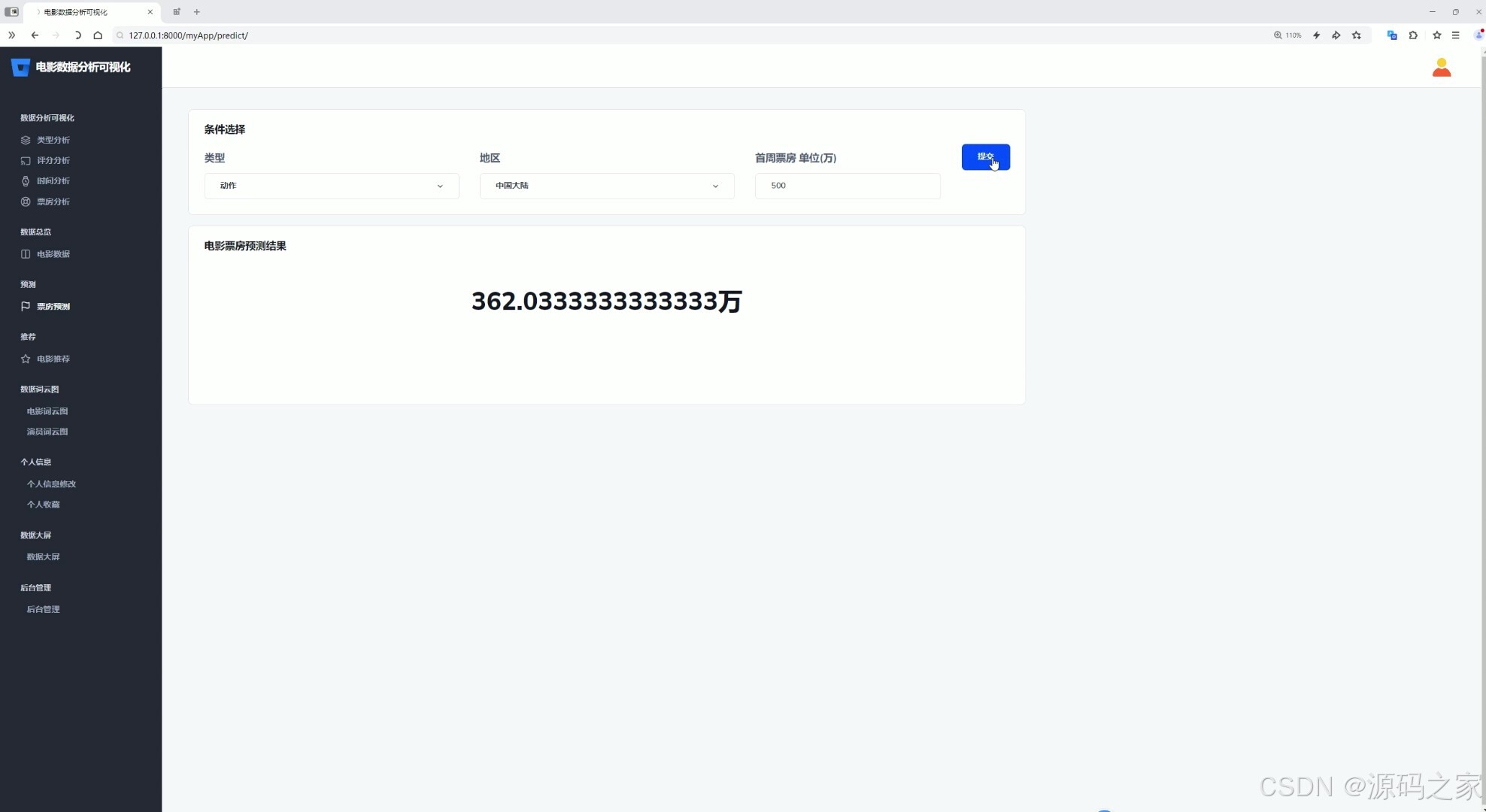
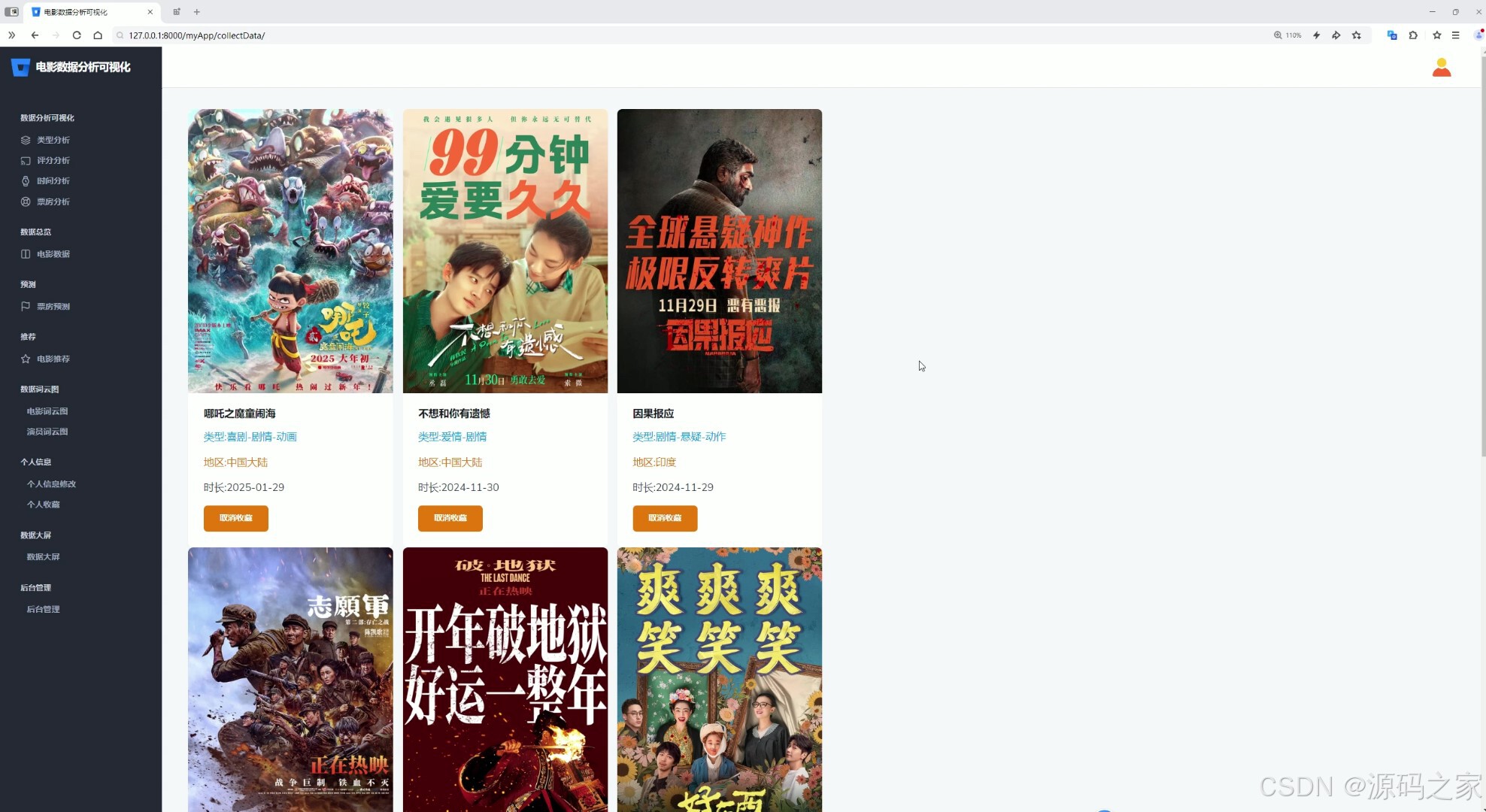
(9)我的收藏
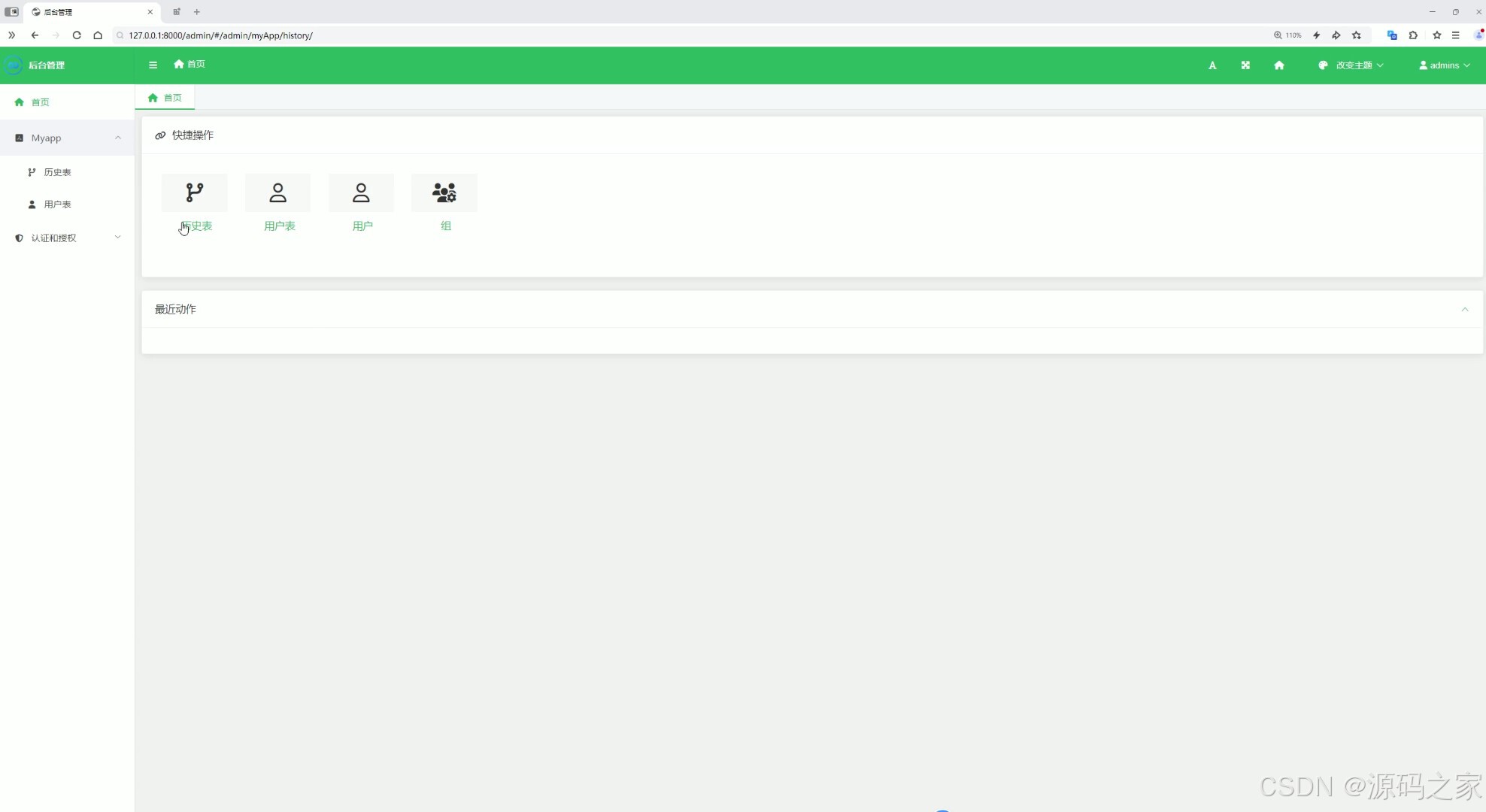
(10)后台管理
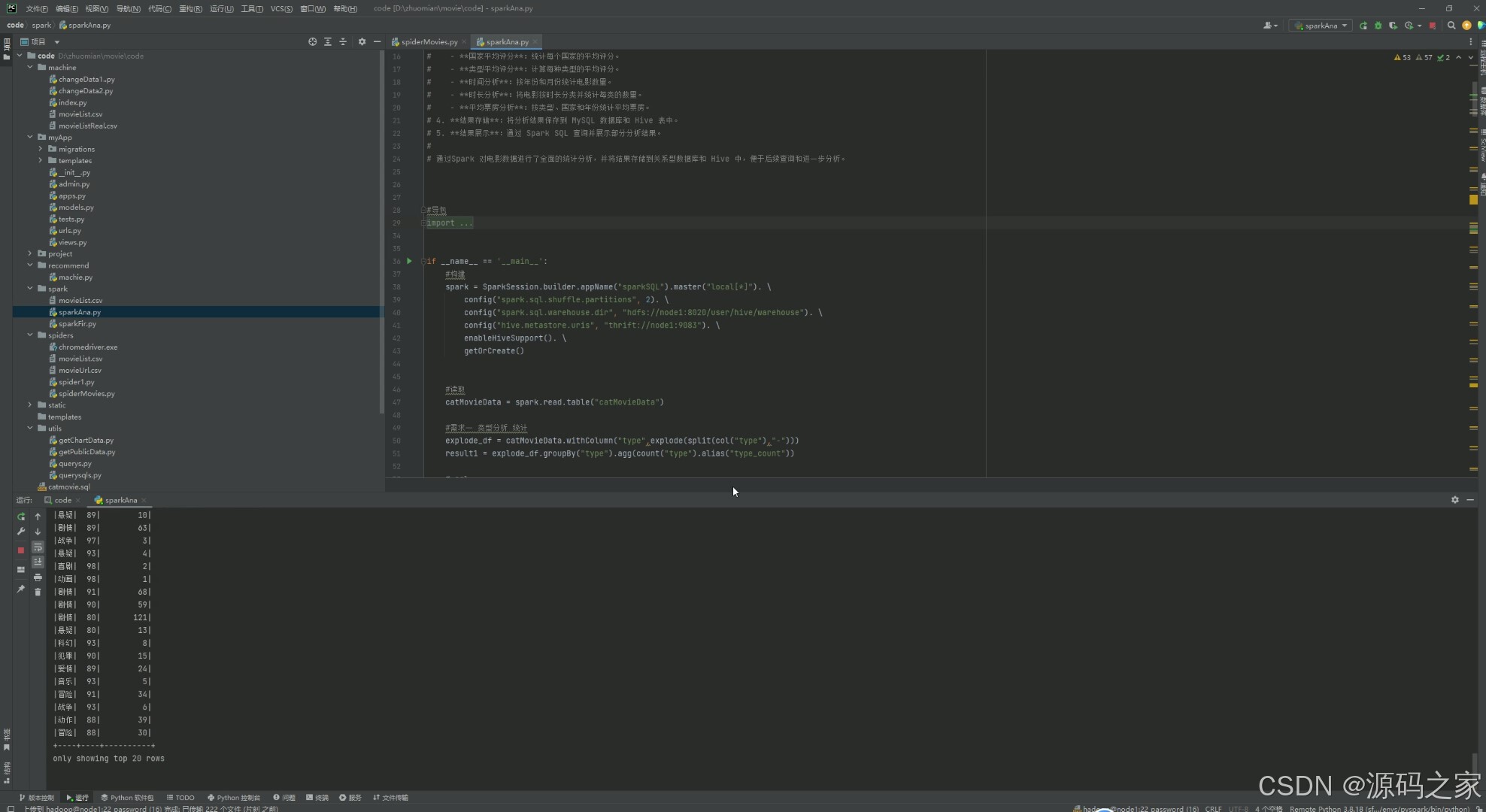
(11)spark数据分析
(12)数据采集
3、项目说明
摘 要
在电影产业规模持续扩张、市场竞争日益激烈的背景下,电影数据已成为驱动行业发展的核心要素。从电影项目的前期策划、中期发行,到观众的观影决策,再到行业趋势研究,精准且深入的数据分析都发挥着关键作用。本研究基于Spark技术开发的电影数据分析系统,深度融合大数据处理与机器学习算法,致力于为电影行业全链条提供高效、精准的数据支持与决策依据。
系统以Python作为核心开发语言,结合Django框架搭建起稳定、高效的Web应用架构,确保系统具备良好的扩展性与交互性。MySQL数据库用于存储结构化数据,保障数据的安全性与便捷查询;Hadoop、Spark和Hive构成大数据处理核心,实现海量电影数据的分布式存储与高效计算,能够快速完成复杂的数据清洗、转换和分析任务;Echarts可视化库则将分析结果以直观、美观的折线图、柱状图、饼图等形式呈现,助力用户快速理解数据背后的规律。
系统功能全面且实用,涵盖数据采集、多维度分析、票房预测、电影推荐等多个模块。数据采集模块采用Selenium爬虫技术,实时获取猫眼电影网站数据,确保数据的时效性与准确性;多维度分析模块从电影类型、评分、时间、票房等多个角度展开深度剖析,挖掘电影市场潜在规律;票房预测模块基于机器学习随机森林回归模型,结合电影类型、发行地区、首周票房等关键因素,输出可靠的票房预测结果;电影推荐模块运用协同过滤推荐算法,根据用户观影历史和行为数据,实现个性化电影推荐。
经严格测试与优化,系统在功能完整性、数据准确性、运行稳定性及性能表现上均达到预期标准。无论是高并发场景下的响应速度,还是复杂数据处理任务的执行效率,都能满足用户需求。未来,系统将持续优化算法模型,提升预测与推荐的精准度;拓展数据采集维度,纳入更多元化数据源;并探索与人工智能前沿技术的深度融合,进一步增强系统的智能化水平,为电影行业的数字化、智能化发展提供更强大的助力。
关键字:电影数据分析;Spark;机器学习;协同过滤推荐算法;数据可视化;Python 语言
4、核心代码
#导包
from pyspark.sql import SparkSession
from pyspark.sql.functions import monotonically_increasing_id
from pyspark.sql.types import StructType,StructField,IntegerType,StringType,FloatType
from pyspark.sql.functions import count,mean,col,sum,when,max,min,avg,explode,split,row_number,year,month
from pyspark.sql.window import Window
if __name__ == '__main__':
#构建
spark = SparkSession.builder.appName("sparkSQL").master("local[*]"). \
config("spark.sql.shuffle.partitions", 2). \
config("spark.sql.warehouse.dir", "hdfs://node1:8020/user/hive/warehouse"). \
config("hive.metastore.uris", "thrift://node1:9083"). \
enableHiveSupport(). \
getOrCreate()
#读取
catMovieData = spark.read.table("catMovieData")
#需求一 类型分析 统计
explode_df = catMovieData.withColumn("type",explode(split(col("type"),"-")))
result1 = explode_df.groupBy("type").agg(count("type").alias("type_count"))
# sql
result1.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "movieTypeCount"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result1.write.mode("overwrite").saveAsTable("movieTypeCount", "parquet")
spark.sql("select * from movieTypeCount").show()
#需求二 票房TOP10
sorted_df =catMovieData.orderBy(col("allBoxOffice").desc())
result2 = sorted_df.limit(10)
# sql
result2.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "boxTopMovie"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result2.write.mode("overwrite").saveAsTable("boxTopMovie", "parquet")
spark.sql("select * from boxTopMovie").show()
#需求三 类型最大票房
result3 = explode_df.groupBy("type").agg(
max("firstBoxOffice").alias("max_firstBoxOffice"),
max("allBoxOffice").alias("max_allBoxOffice")
)
# sql
result3.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "typeMaxBox"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result3.write.mode("overwrite").saveAsTable("typeMaxBox", "parquet")
spark.sql("select * from typeMaxBox").show()
#需求四 国家统计
explode_df2 = catMovieData.withColumn("country",explode(split(col("country"),",")))
result4 = explode_df2.groupBy("country").agg(count("country").alias("country_count"))
# sql
result4.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "mcountryCount"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result4.write.mode("overwrite").saveAsTable("mcountryCount", "parquet")
spark.sql("select * from mcountryCount").show()
#需求五 评分分类
catMovieData = catMovieData.withColumn(
"rateCategory",
when(col("rate") == 0, None).otherwise(
when((col("rate") >= 10) & (col("rate") < 20), "半星").
when((col("rate") >= 20) & (col("rate") < 30), "1星").
when((col("rate") >= 30) & (col("rate") < 40), "1.5星").
when((col("rate") >= 40) & (col("rate") < 50), "2星").
when((col("rate") >= 50) & (col("rate") < 60), "2.5星").
when((col("rate") >= 60) & (col("rate") < 70), "3星").
when((col("rate") >= 70) & (col("rate") < 80), "3.5星").
when((col("rate") >= 80) & (col("rate") < 90), "4星").
when((col("rate") >= 90) & (col("rate") < 100), "4.5星")
)
)
filter_df = catMovieData.filter(col("rate") != 0)
result5 = filter_df.groupBy("rateCategory").count()
# sql
result5.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "starCategory"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result5.write.mode("overwrite").saveAsTable("starCategory", "parquet")
spark.sql("select * from starCategory").show()
#需求6 按类型票房分析
grouped_df = explode_df.groupBy("type","title").agg({"allBoxOffice":"sum"})
grouped_df = grouped_df.withColumnRenamed("sum(allBoxOffice)","allBoxOffice")
window = Window.partitionBy("type").orderBy(col("allBoxOffice").desc())
ranked_df = grouped_df.withColumn("row_num",row_number().over(window))
#过滤出每组的前十
result6 = ranked_df.filter(col("row_num") <= 10).drop("row_num")
# sql
result6.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "perTypeBox"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result6.write.mode("overwrite").saveAsTable("perTypeBox", "parquet")
spark.sql("select * from perTypeBox").show()
#需求7 按类型评分
filter_df2 = explode_df.filter(col("rate") != 0)
result7 = filter_df2.groupBy("type","rate").agg(count("rate").alias("rate_count"))
# sql
result7.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "perTypeRate"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result7.write.mode("overwrite").saveAsTable("perTypeRate", "parquet")
spark.sql("select * from perTypeRate").show()
#需求8类型平均时长
result8 = explode_df.groupBy("type").agg(avg("duration").alias("avg_duration"))
# sql
result8.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "typeAvgTime"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result8.write.mode("overwrite").saveAsTable("typeAvgTime", "parquet")
spark.sql("select * from typeAvgTime").show()
#需求9 年度平均评分分析
time_df1 = catMovieData.withColumn("releaseTime",col("releaseTime").cast("date"))
time_df2 = catMovieData.withColumn("year",year(col("releaseTime")))
result9 = time_df2.groupBy("year").agg(avg("rate").alias("year_rate"))
# sql
result9.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "mYearRate"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result9.write.mode("overwrite").saveAsTable("mYearRate", "parquet")
spark.sql("select * from mYearRate").show()
#需求十 国家平均
result10 = explode_df2.groupBy("country").agg(avg("rate").alias("avg_rate"))
# sql
result10.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "mCountryRate"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result10.write.mode("overwrite").saveAsTable("mCountryRate", "parquet")
spark.sql("select * from mCountryRate").show()
#需求十一 类型
result11 = explode_df.groupBy("type").agg(avg("rate").alias("avg_rate"))
# sql
result11.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "mTypeRate"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result11.write.mode("overwrite").saveAsTable("mTypeRate", "parquet")
spark.sql("select * from mTypeRate").show()
#需求十二 时间分析
result12 = time_df2.groupBy("year").agg(count("year").alias("year_count"))
# sql
result12.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "mYearCount"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result12.write.mode("overwrite").saveAsTable("mYearCount", "parquet")
spark.sql("select * from mYearCount").show()
#月度
time_df3 = time_df1.withColumn("month",month(col("releaseTime")))
result13 = time_df3.groupBy("month").agg(count("month").alias("year_count"))
# sql
result13.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "mMonthCount"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result13.write.mode("overwrite").saveAsTable("mMonthCount", "parquet")
spark.sql("select * from mMonthCount").show()
#时长分析
catMovieData = catMovieData.withColumn(
"durationCategory",
when(col("duration") == 0, None).otherwise(
when((col("duration") >= 0) & (col("rate") < 50), "很短").
when((col("duration") >= 50) & (col("rate") < 80), "较短").
when((col("duration") >= 80) & (col("rate") < 120), "中").
when((col("duration") >= 120) & (col("rate") < 150), "较长").
otherwise('很长')
)
)
filter_df4 = catMovieData.filter(col("duration") != 0)
result14 = filter_df4.groupBy("durationCategory").count()
# sql
result14.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "mTimeCategory"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result14.write.mode("overwrite").saveAsTable("mTimeCategory", "parquet")
spark.sql("select * from mTimeCategory").show()
#需求15 各类型平均票房
result15 = explode_df.groupBy("type").agg(
avg("allBoxOffice").alias("avg_allBoxOffice")
)
# sql
result15.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "mTypeAvgBox"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result15.write.mode("overwrite").saveAsTable("mTypeAvgBox", "parquet")
spark.sql("select * from mTypeAvgBox").show()
#各国家票房
result16 = explode_df2.groupBy("country").agg(
avg("allBoxOffice").alias("avg_allBoxOffice")
)
# sql
result16.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "mCountryAvgBox"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result16.write.mode("overwrite").saveAsTable("mCountryAvgBox", "parquet")
spark.sql("select * from mCountryAvgBox").show()
#年度平均票房
result17 = time_df2.groupBy("year").agg(
avg("allBoxOffice").alias("avg_allBoxOffice")
)
# sql
result17.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "mYearAvgBox"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result17.write.mode("overwrite").saveAsTable("mYearAvgBox", "parquet")
spark.sql("select * from mYearAvgBox").show()
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻


















 961
961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









