






目录
2.3.2 Credit-based Flow Control
一、背景
《Flink核心技术源码剖析与特性开发》第八章数据传输,读书笔记,主要讲解TM之间的数据传输,包括反压的实现
基于Flink1.10,版本有点老,但思想是没变的
二、基本概念与设计思想
2.1 图讲解
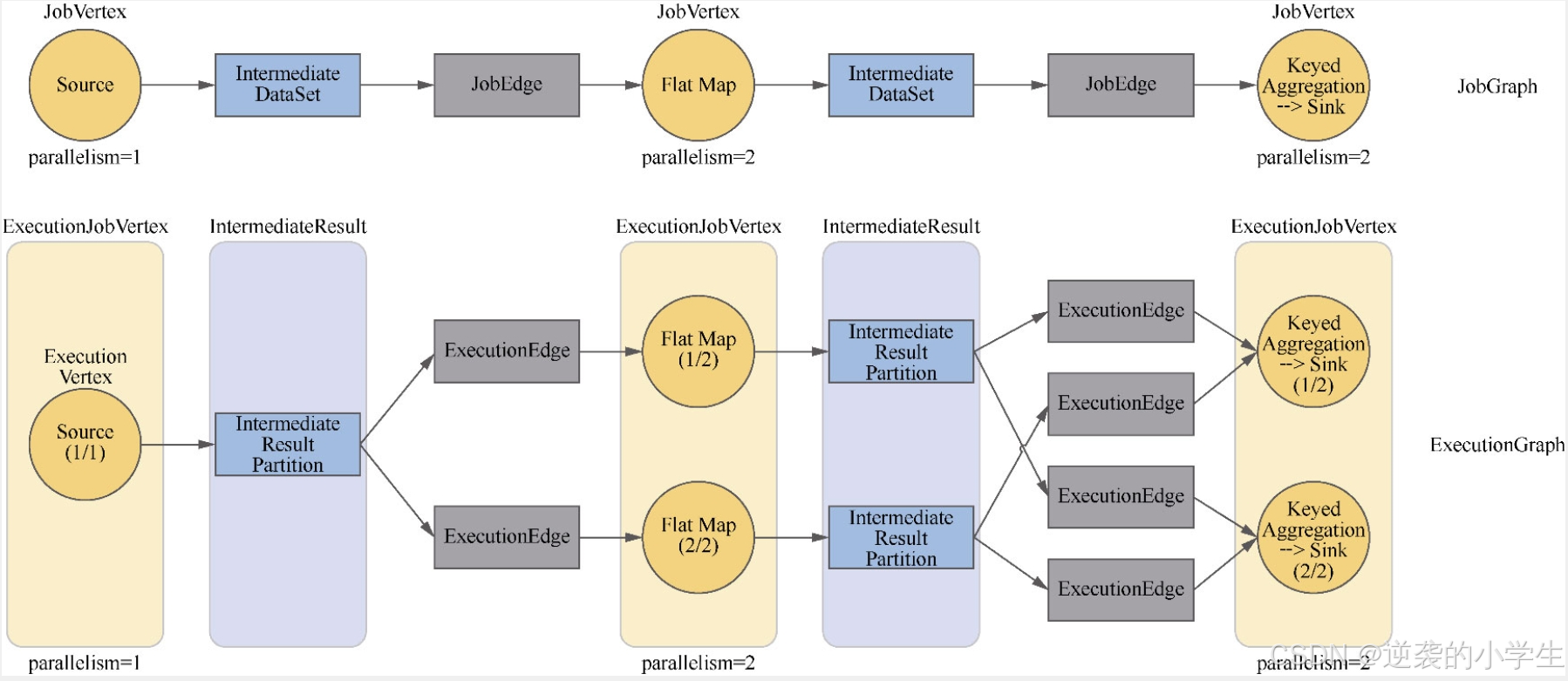
理解这个需要先了解下Flink的execution graph与物理执行图,有这个图才能理清每个类在物理传输之间的作用,这里给个书上的图:不清楚的也可以看我之前写的:

备注:
上面图节点的对应关系:
ExecutionVertex:IntermidateResultPartition:ResultPartition = 1:1:1
ExecutionEdge:InputChannel = 1:1
在execution graph中IntermidateResultPartition会连接多个ExecutionEdge,在物理执行图中,IntermidateResultPartition会生成对应个数的ResultSubPartition与Inputchannel一对一连接
Flink中ResultPartition负责数据的输出,InputGate负责数据的输入
数据的重分区发生在每个并行实例将数据写入ResultSubPartition的过程中
2.2 Shuffle
数据传输,要搞懂是谁与谁传输,所以要了解一下其Shuffle机制,可以看我写的
Hadoop、Spark、Flink Shuffle对比-优快云博客
字数较多,就不一一赘述了
2.3 流量控制(反压)
关于这块,书上说的一般,我参考了流处理框架反压机制-优快云博客来说一下
2.3.1 TCP-based Flow Control
Flink 1.5 版本之前基于TCP滑动窗口做反压,这里Flink并没有对TCP做什么特殊开发,只是基于TCP原本的机制
预备知识:InputGate向LocalBufferPool申请内存,LocalBufferPool向NetworkBufferPool申请内存
当数据处理不过来时
NetworkBufferPool内存耗尽
LocalBufferPool内存耗尽
InputGate打满,不再接受Netty数据
Netty内存打满,不再接受Socket数据
Socket内存打满,TCP通过ACK机制中的“窗口大小”通知发送端暂停发送(滑动窗口机制)

然后发送方的Socket、Netty、LocalBufferPool也依次耗尽,Task A阻塞
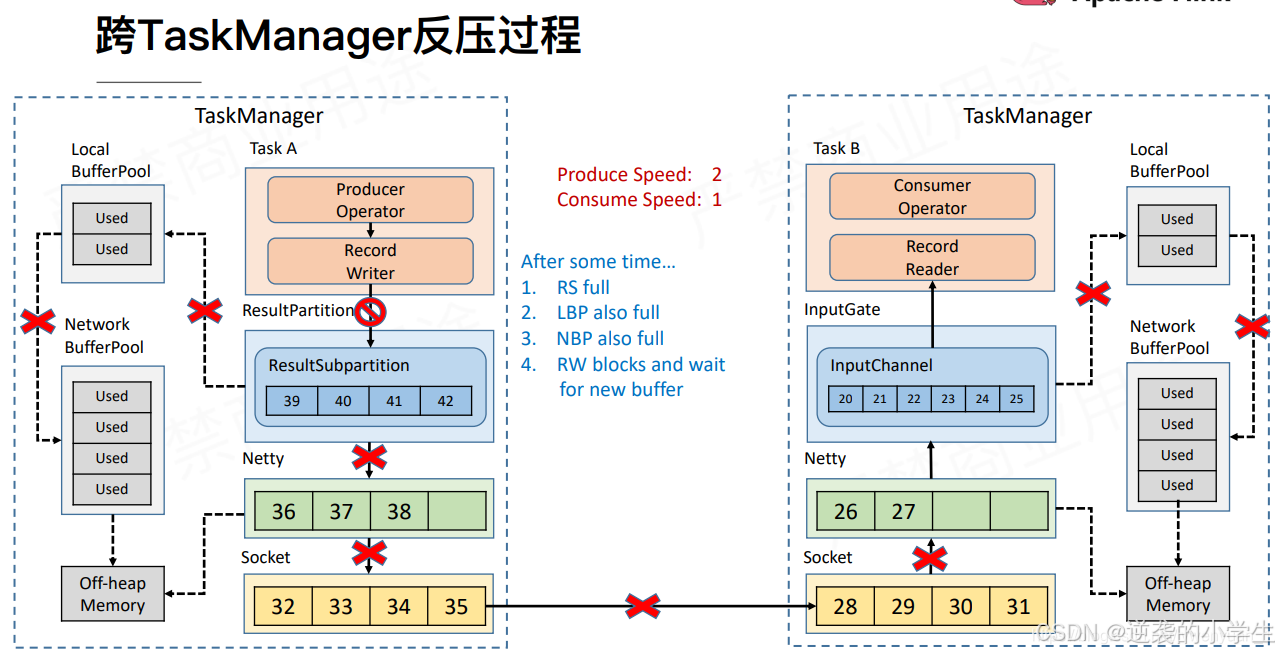
TaskManager反压内走的是一个线程,一块内存,所以结果见下图:

这样做有两个弊端
1. TM中可能有多个任务,一个任务出现问题,因为基于一个TCP,会影响其它任务
2. 缓存耗尽才会产生背压,并且缓存还有很多级,生效太慢
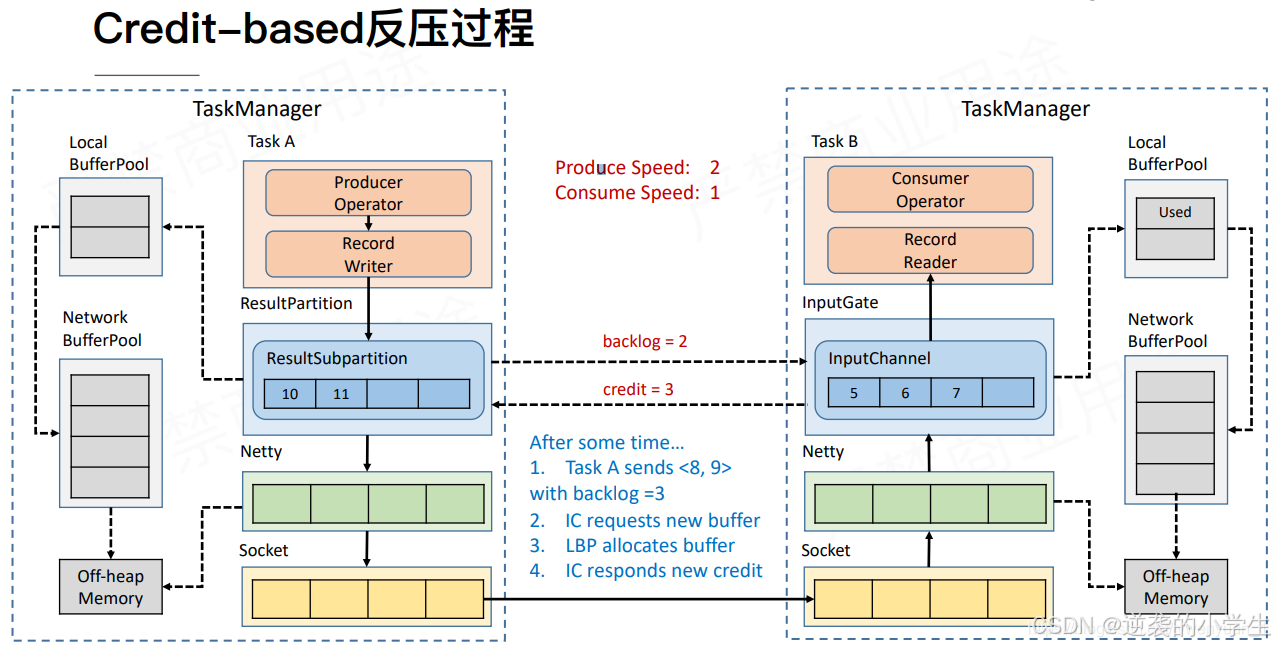
2.3.2 Credit-based Flow Control
大概是下面原理
ResultPartition会初始化一个值假设为a,表示InputGate的剩余量,每次发送数据a都会减一
InputGate同样也会告诉ResultPartition自动还能接收多少,自己的剩余,这个a也会每次更新
三、数据的输出源码分析
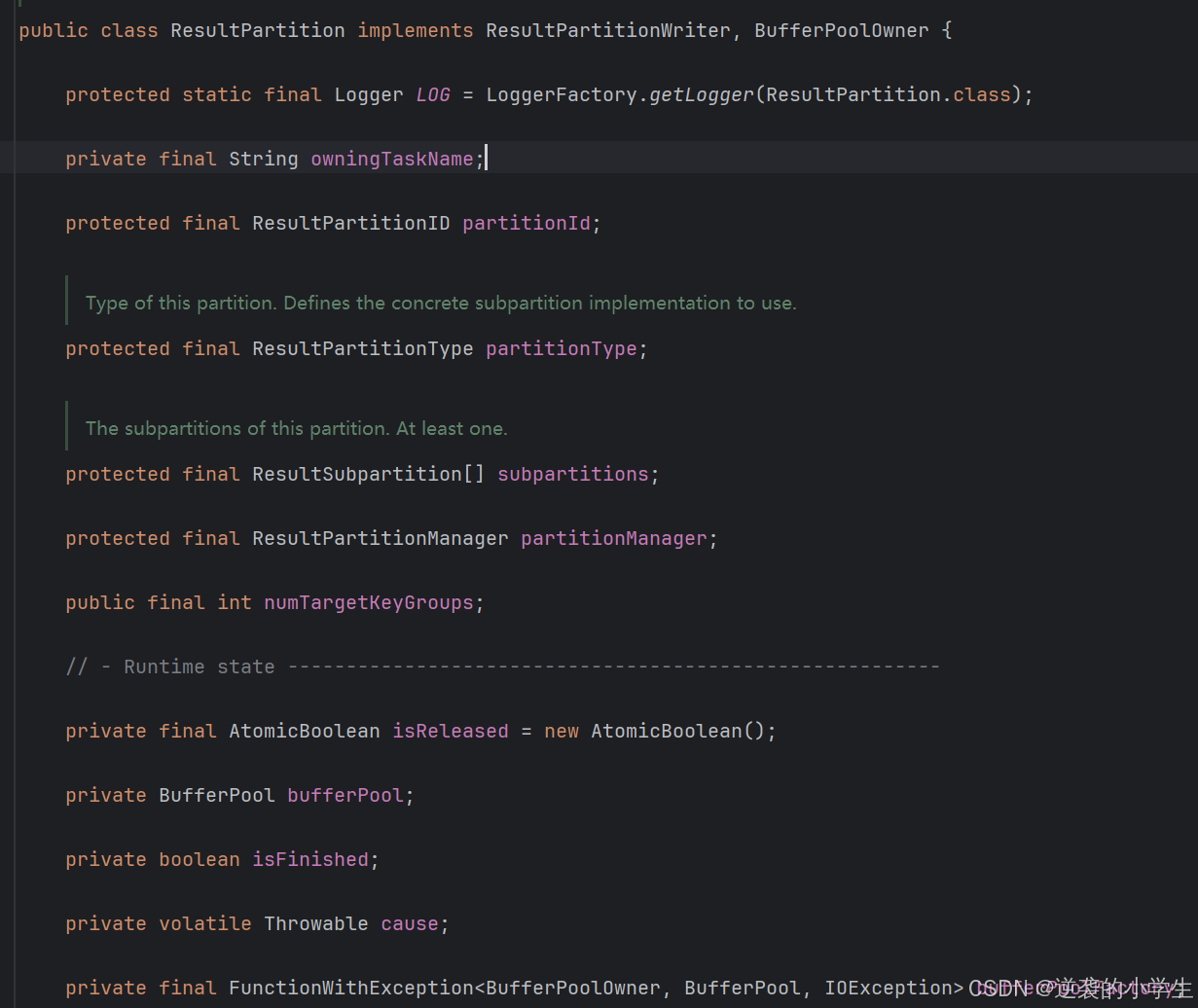
3.1 ReusltPartition
该类主要是做数据与内存的管理分配,主要讲解下bufferPool,篇幅较长,可以看下我写的:Flink TM数据传输时的内存分配-优快云博客
3.2 ResultSubpartition
可以看到ReusltPartition中有个ResultSubpartition数组,ResultSubpartition存储了该子分区的数据,以及读取的数据的视图
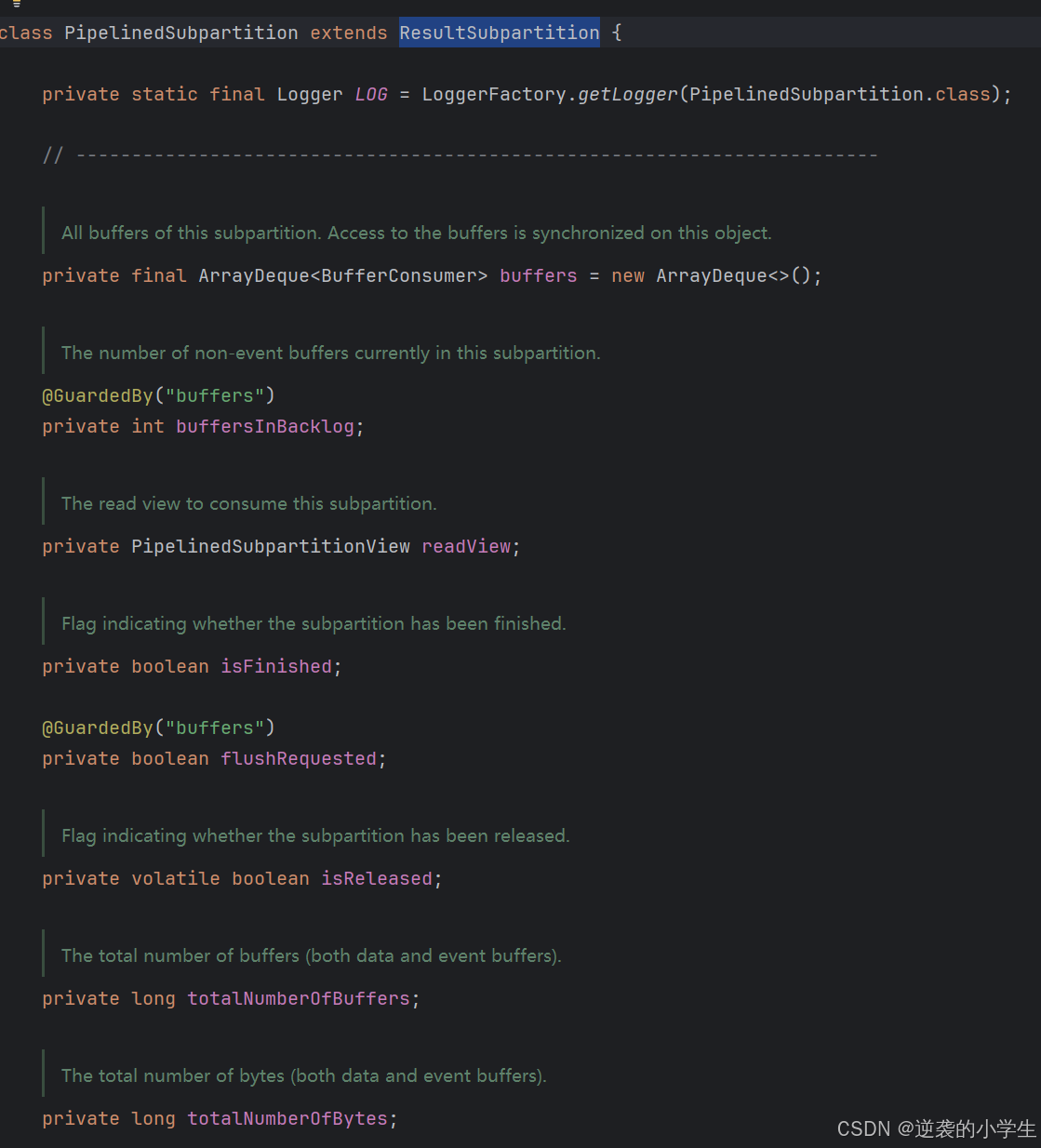
我们以实现类PipelinedSubpartition为例子
buffers是从ReusltPartition的LocalBufferPool申请到的内存,做了一些封装成BufferConsumer,BufferConsumer中存的是即将发送的序列化后的数据
buffersInBacklog的含义见注释
readView是用来读取数buffers中数据的
3.3 RecordWriter
flink一个任务中可能有多个连接在一起的算子,最后一个算子的输出依赖RecordWriter
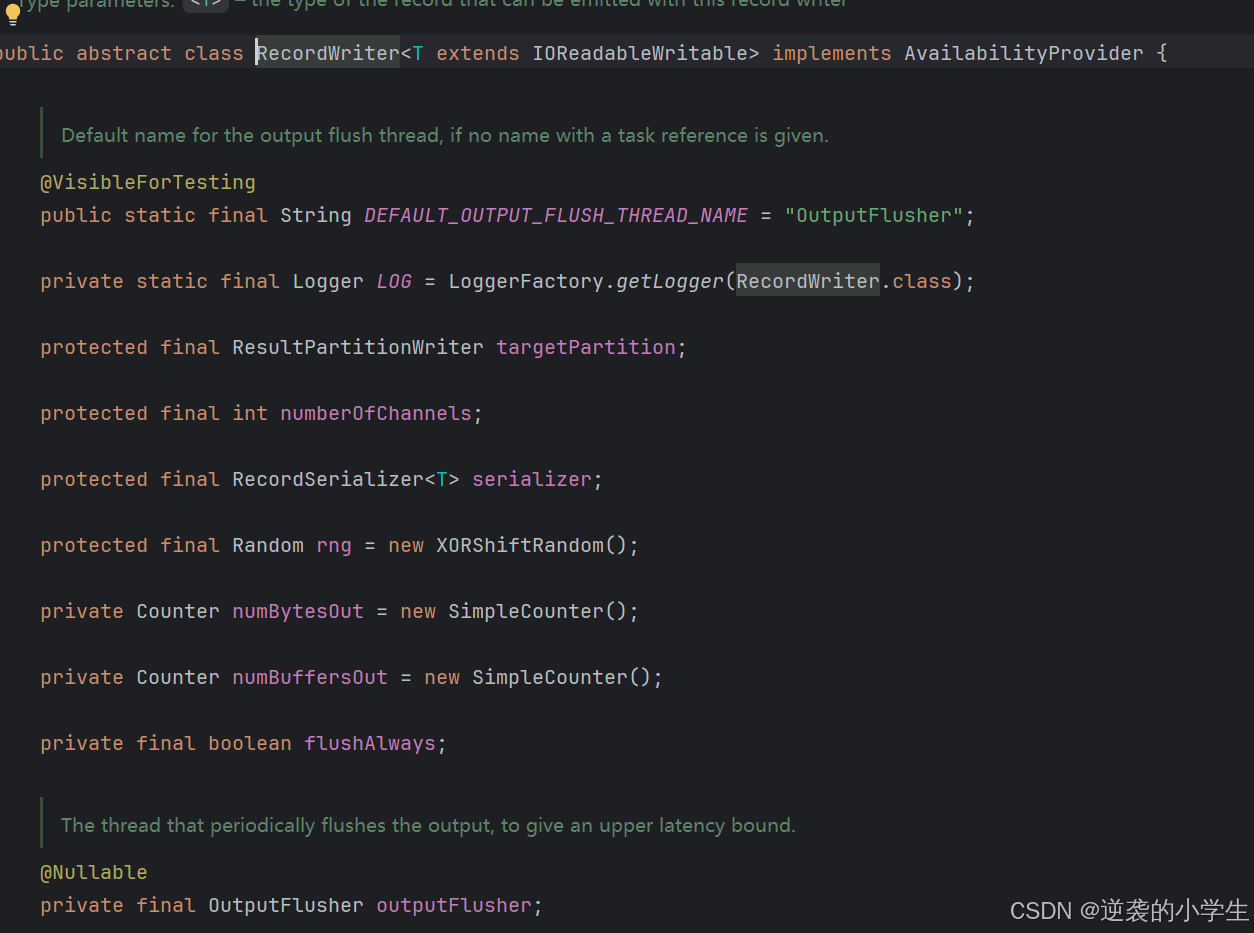
RecordWriter是一个抽象类,它的属性是如下图,可以看到有一个属性targetPartition,对应类是ResultPartitionWriter,而ResultPartitionWriter的实现类就是ReusltPartition
RecordWriter类的作用是数据的输出
RecordWriter有两个实现类,ChannelSelectorRecordWriter用于将数据写入特定子分区,BroadcastRecordWriter用于广播
我这里分析ChannelSelectorRecordWriter

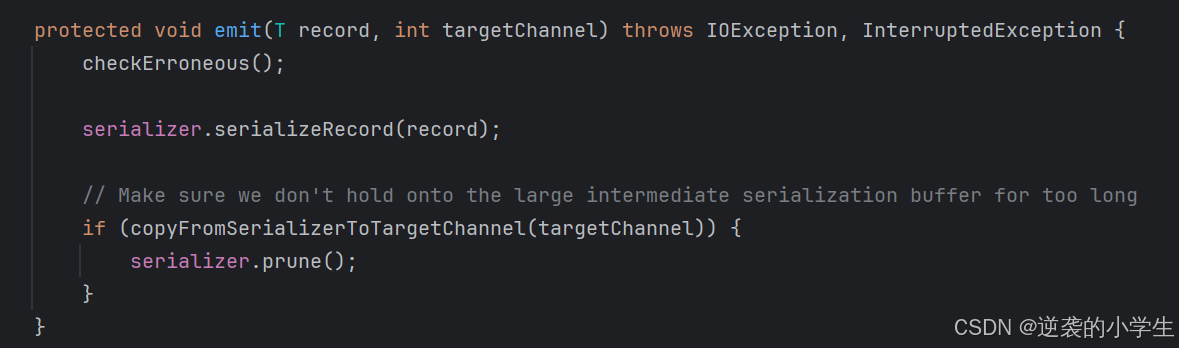
RecordWriter中最重要的是emit方法 ,将元素进行发送,代码如下:
在如下类中:
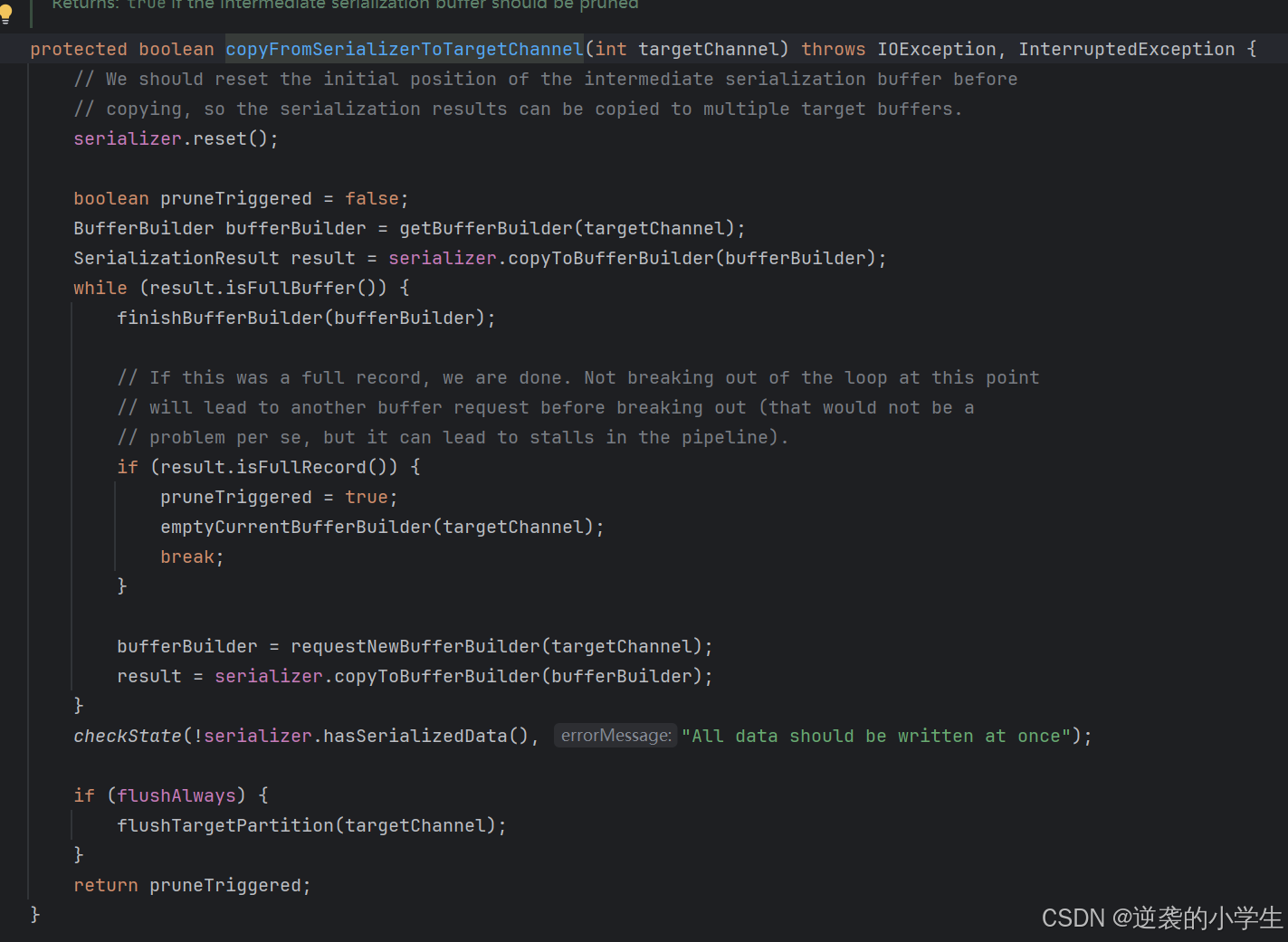
1. getBufferBuilder获取了ResultSubpartition中buffers队列中可写入的buffer,并把序列化后的数据copy拷贝其中
2. 如果内存池中申请的内存块用完了,还会通过requestNewBufferBuilder方法,在其中从LocalBufferPool申请新的内存,申请到的内存会加入对应的ResultSubpartition中的buffers队列中,并且也会保存其引用在ChannelSelectorRecordWriter的bufferBuilders中,方便后续使用
四、数据的读取源码分析
4.1 InputGate
InputGate它管理多个 InputChannel(输入通道),协调数据从生产者任务(如 Map)到消费者任务(如 Reduce)的传输过程。
我们这里分析它的实现类SingleInputGate
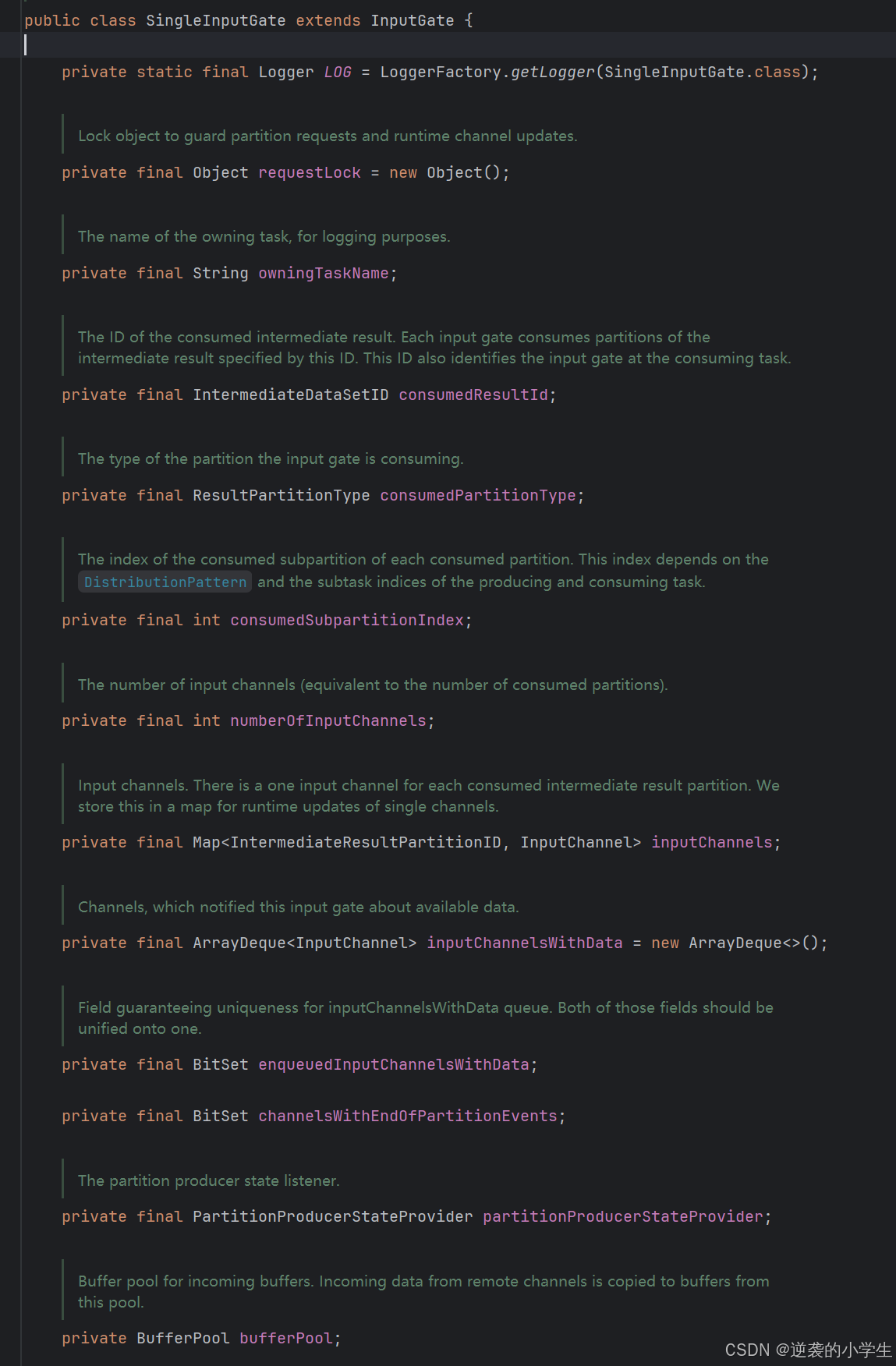
一些属性如上所示
inputChannelsWithData存储的是有数据的channel
consumedSubpartitionIndex是所有的subpartition数量
numberOfInputChannels是channel的数量
enqueuedInputChannelsWithData表示已进入inputChannelsWithData中的channel,避免inputChannelsWithData中有两个一样的channel
BufferPool实现类依旧是LocalBufferPool,和ResultPartition中的一样,主要用于存储算子网络间交互数据,在该类初始化时,除了申请bufferPool,还会创建与上游各个ResultSubpartition的视图,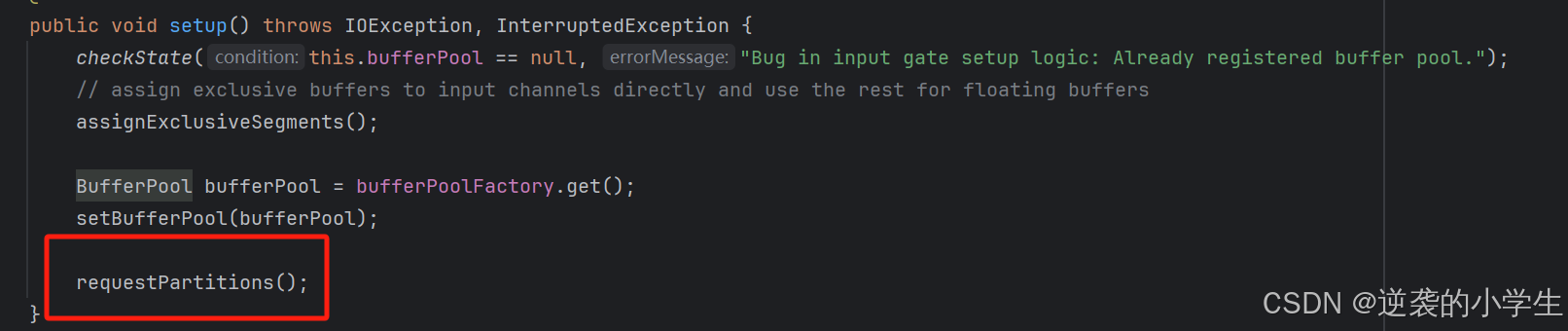
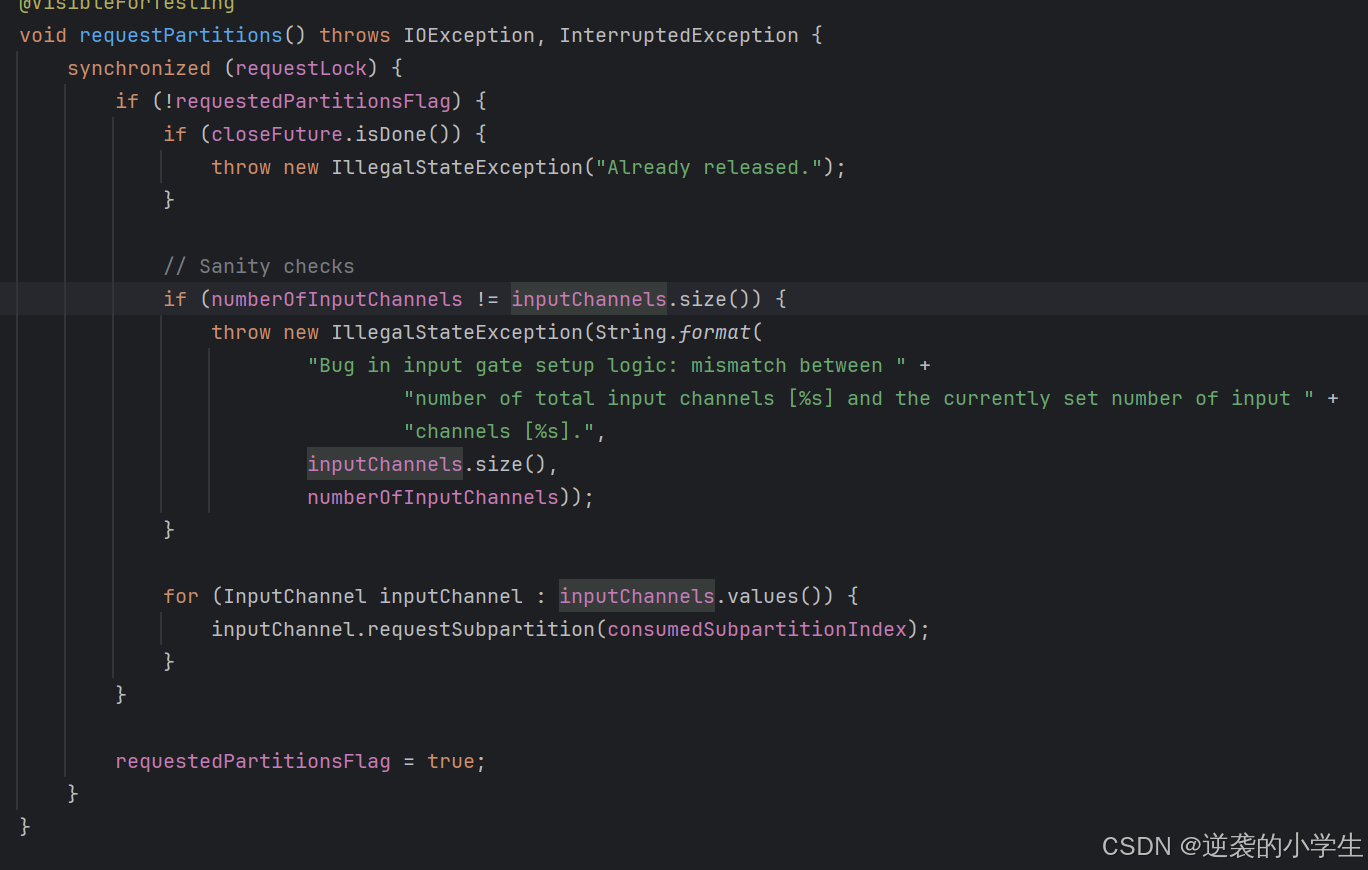
视图的作用是读取ResultSubpartition中的数据,以及提醒SingleInputGate有数据了,让SingleInputGate把有数据的channel放入inputChannelsWithData中
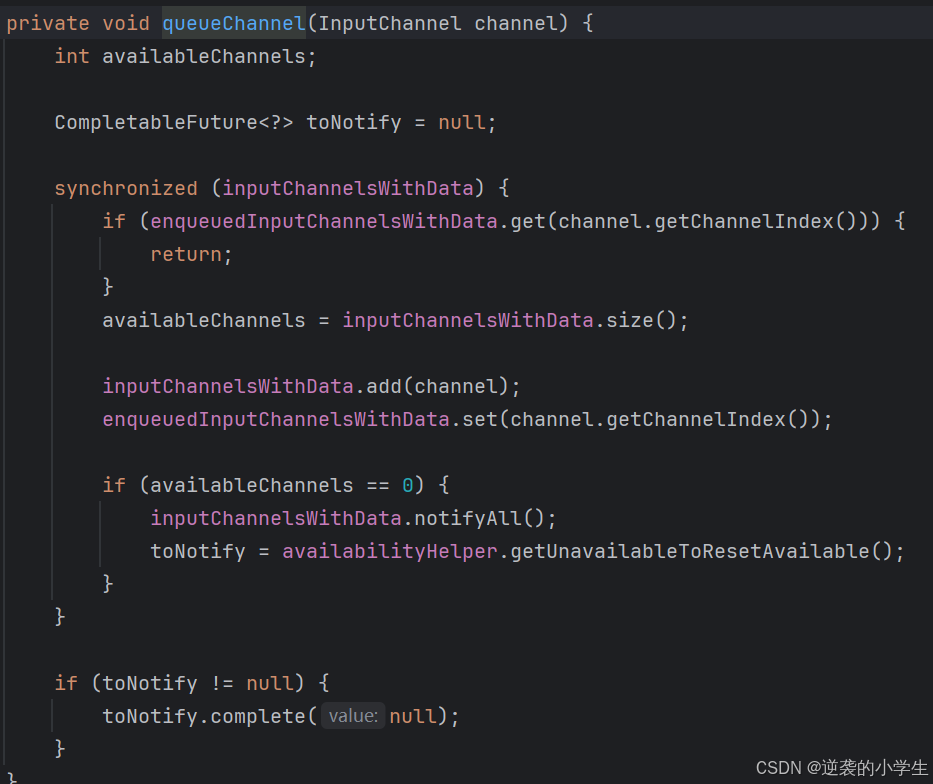
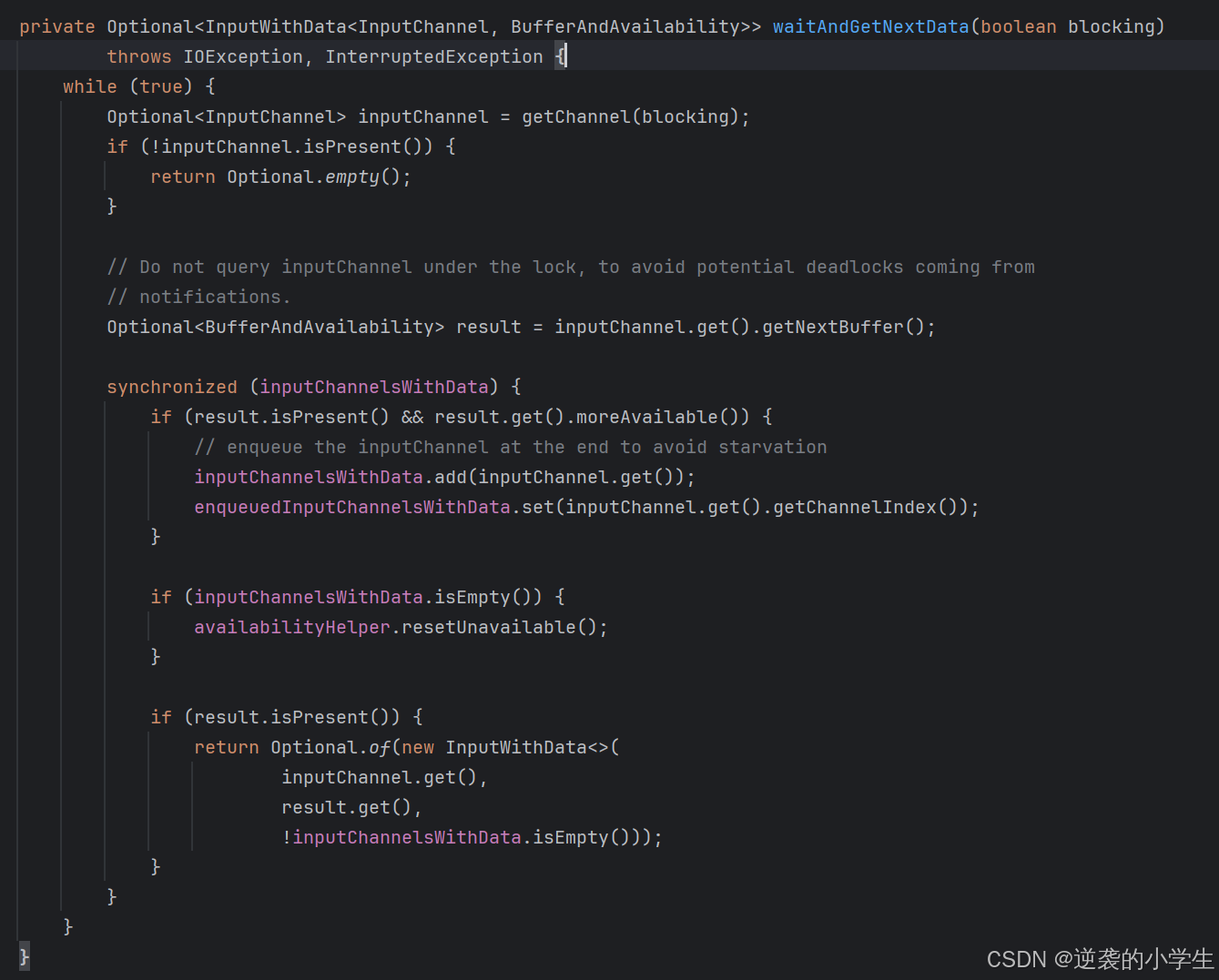
SingleInputGate对数据的获取通过waitAndGetNextData方法,具体如下图所示:
通过getChannel获取有数据的channel,如果没有且block为true则会阻塞
获取到数据后,会进行封装返回
应该是有一个方法在持续不断的调用waitAndGetNextData,来获取数据
4.2 InputeChannel
主要负责数据的获取
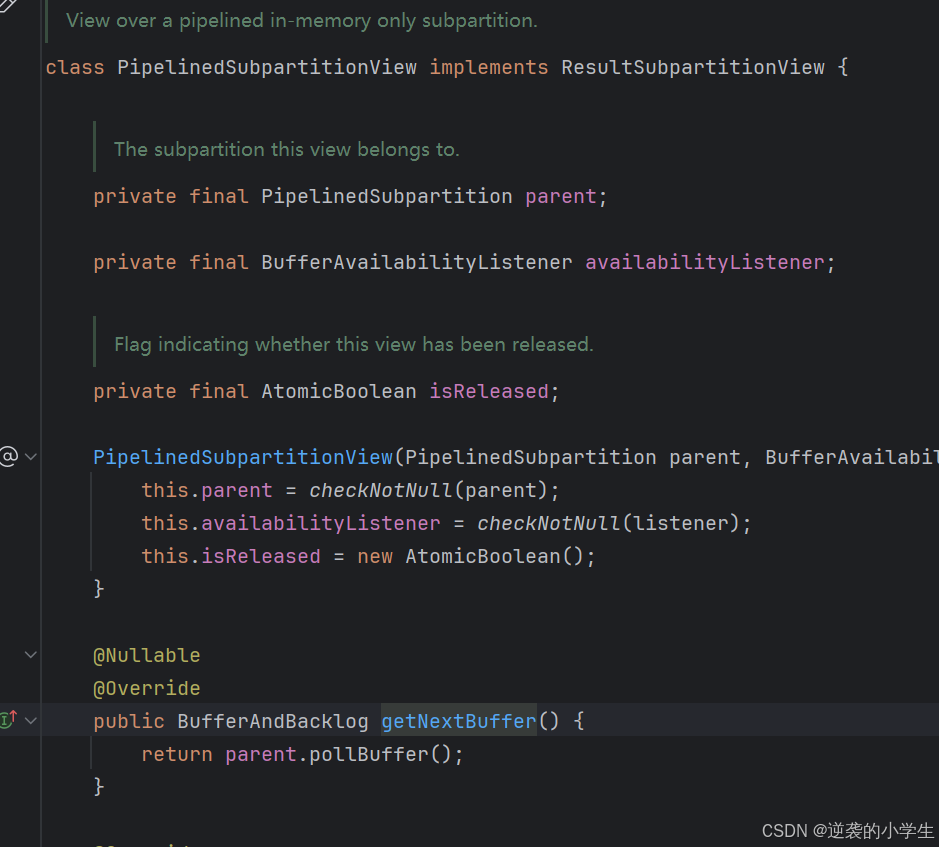
4.2.1 LocalInputChannel
看名字也知道,LocalInputChannel主要负责TM内算子的交互,具体代码如下图所示:
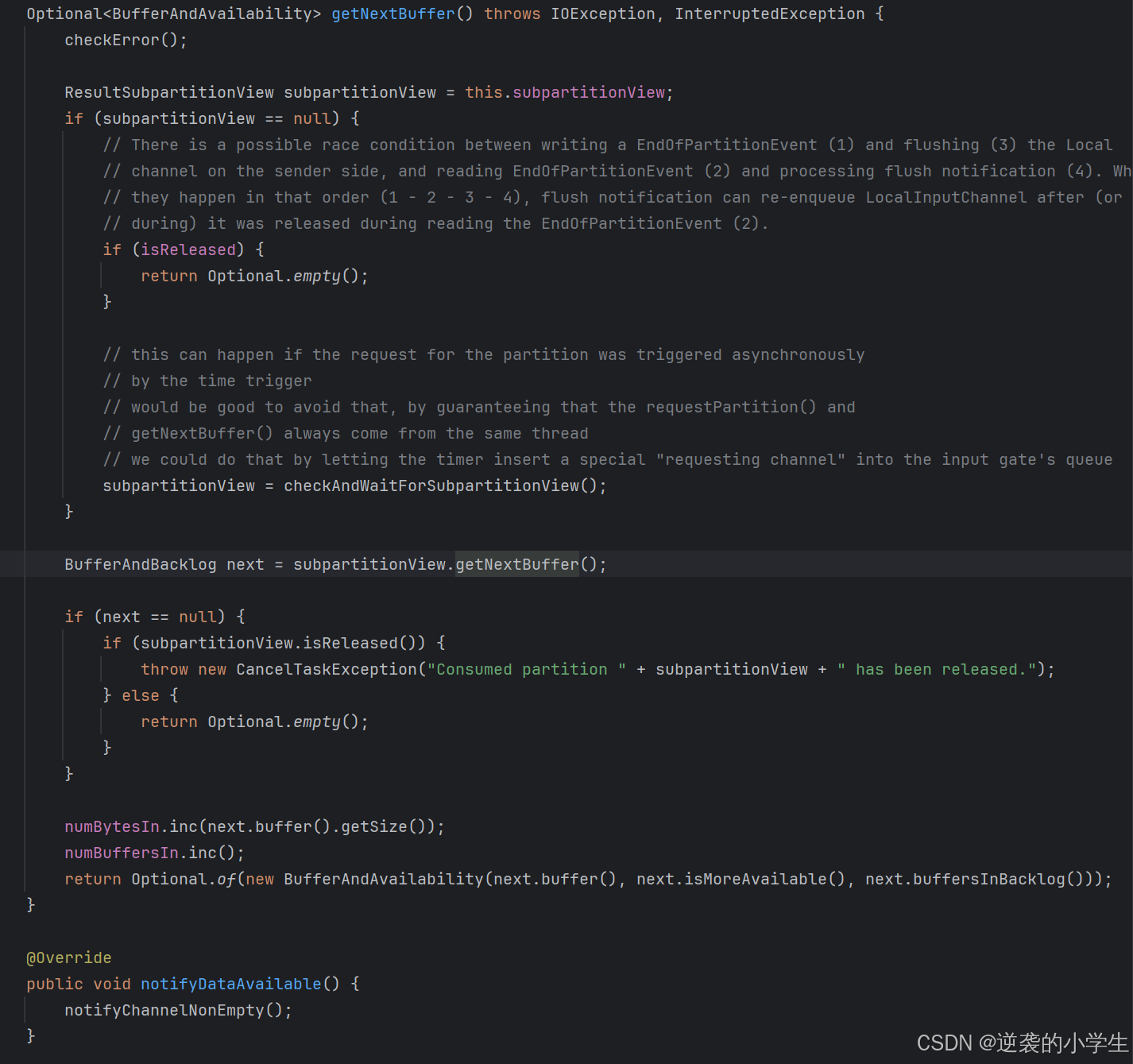
先获取视图,然后调用视图的getNextBuffer方法,视图的getNextBuffer方法调用ResultSubpartition的pollBuffer,ResultSubpartition返回buffers.peek()值,可以看出来,算子内是没有反压的,只有方法之间的相互调用
4.2.2 RemoteInputChannel
RemoteInputChannel主要负责TM之间的数据交互

收到的数据放在receivedBuffers中
bufferQueue代表的是可用内存,包括独占内存和浮动内存,RemoteInputChannel初始化时独占内存会从NetworkBufferPool中申请,数量为numberOfSegmentsToRequest
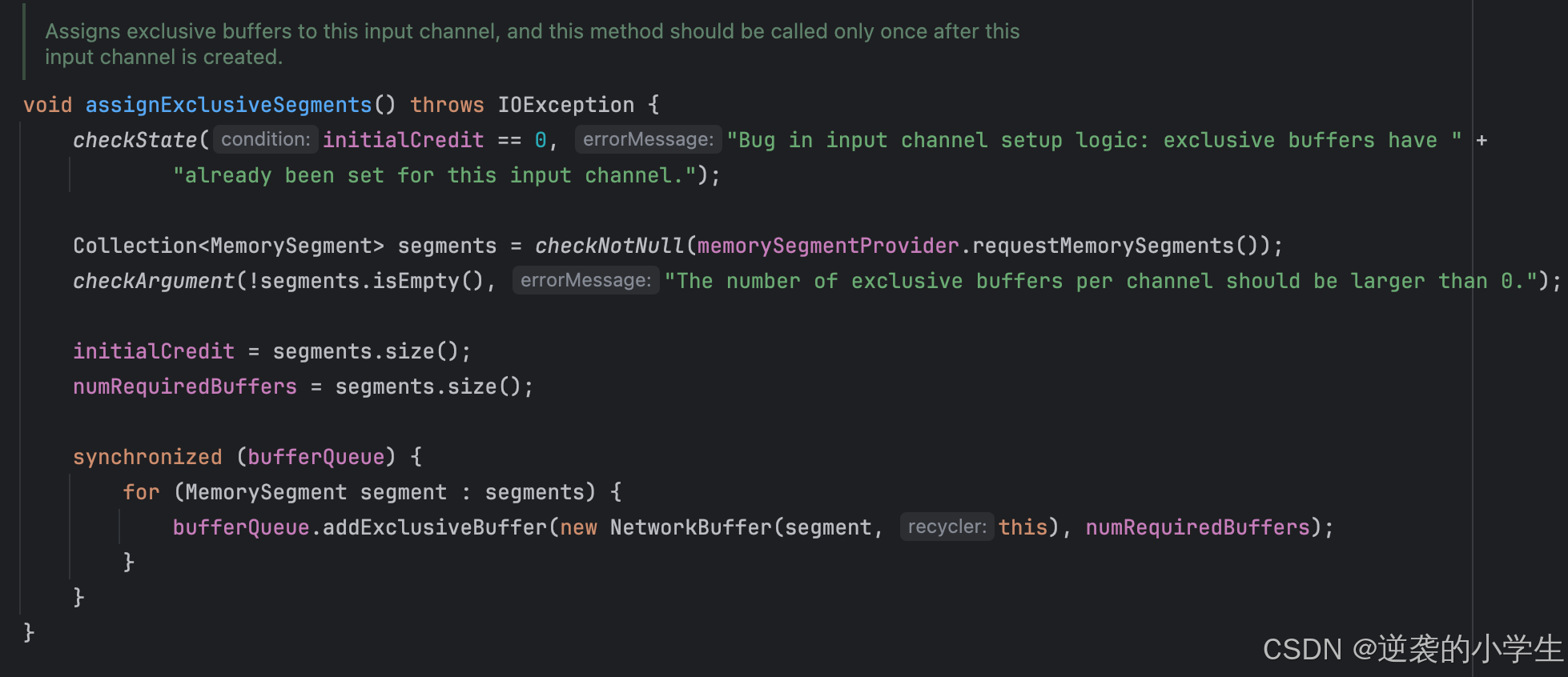
在NetworkBufferPool中,numberOfSegmentsToRequest的默认值由Flink的配置参数NettyShuffleEnvironmentOptions.NETWORK_EXCLUSIVE_BUFFERS_PER_REQUEST决定,默认值为2。该参数表示每次请求独占内存段的数量。
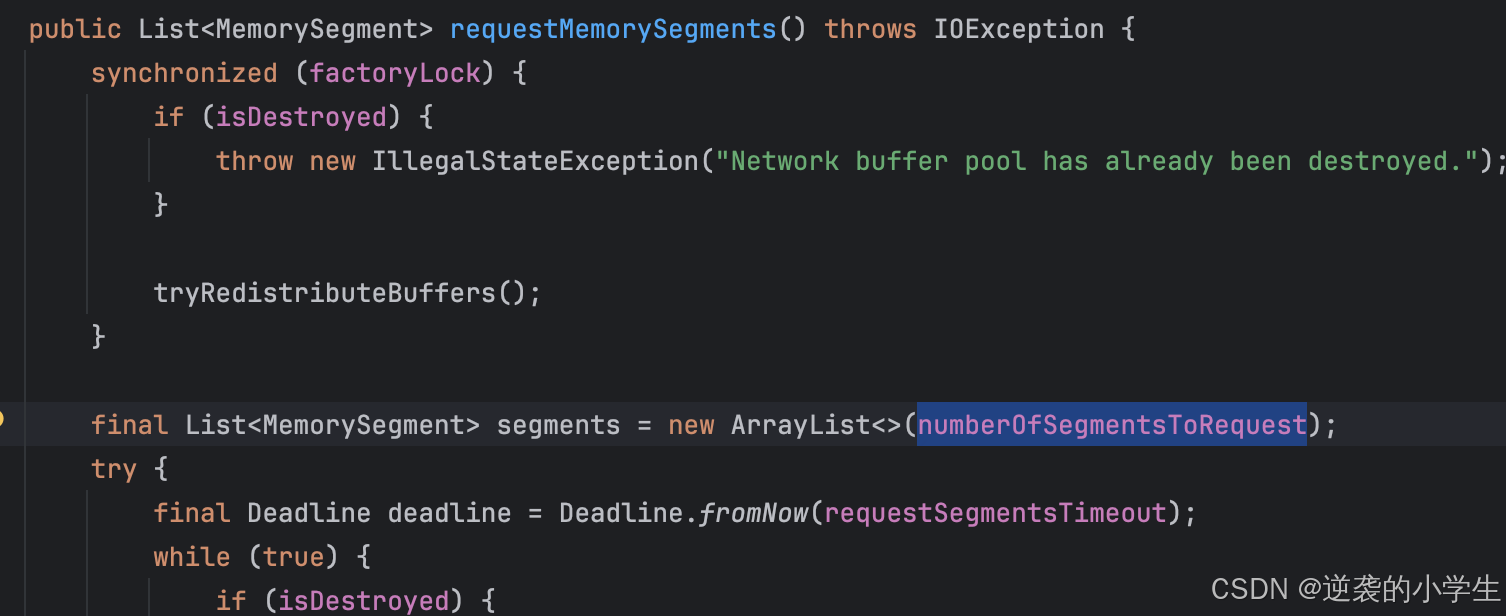
浮动内存是当bufferQueue中内存不够用时,小于 初始可用内存+生产者没法送的内存,就会从InputGate中去申请

收到数据代码如下:
首先requestBuffer,然后把请求内容拷贝到bufferQueue中,调用channel的onbuffer处理
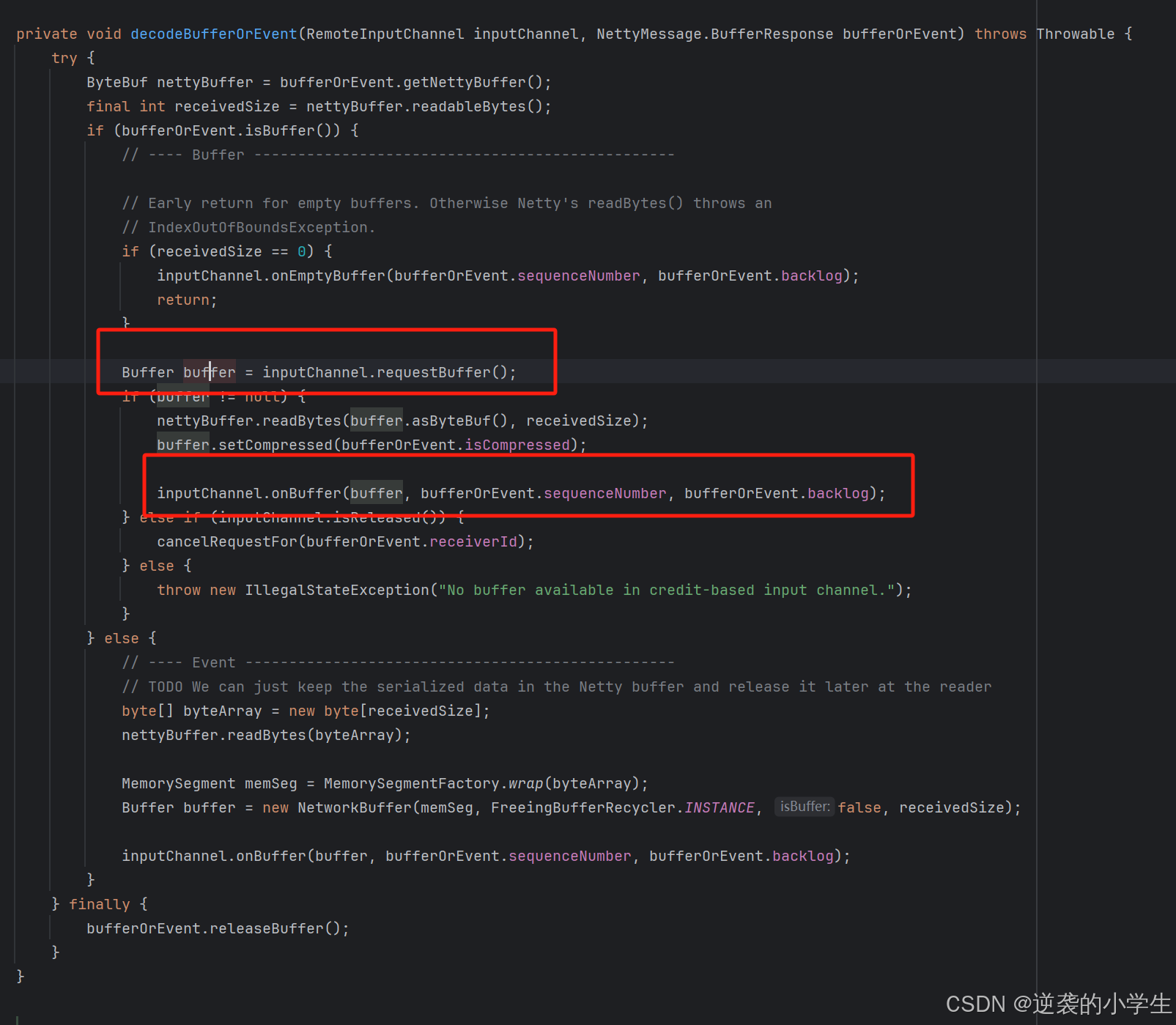
然后把buffer放入receivedBuffers中,并调用notifyChannelNonEmpty,提示SingleInputGate去读取数据
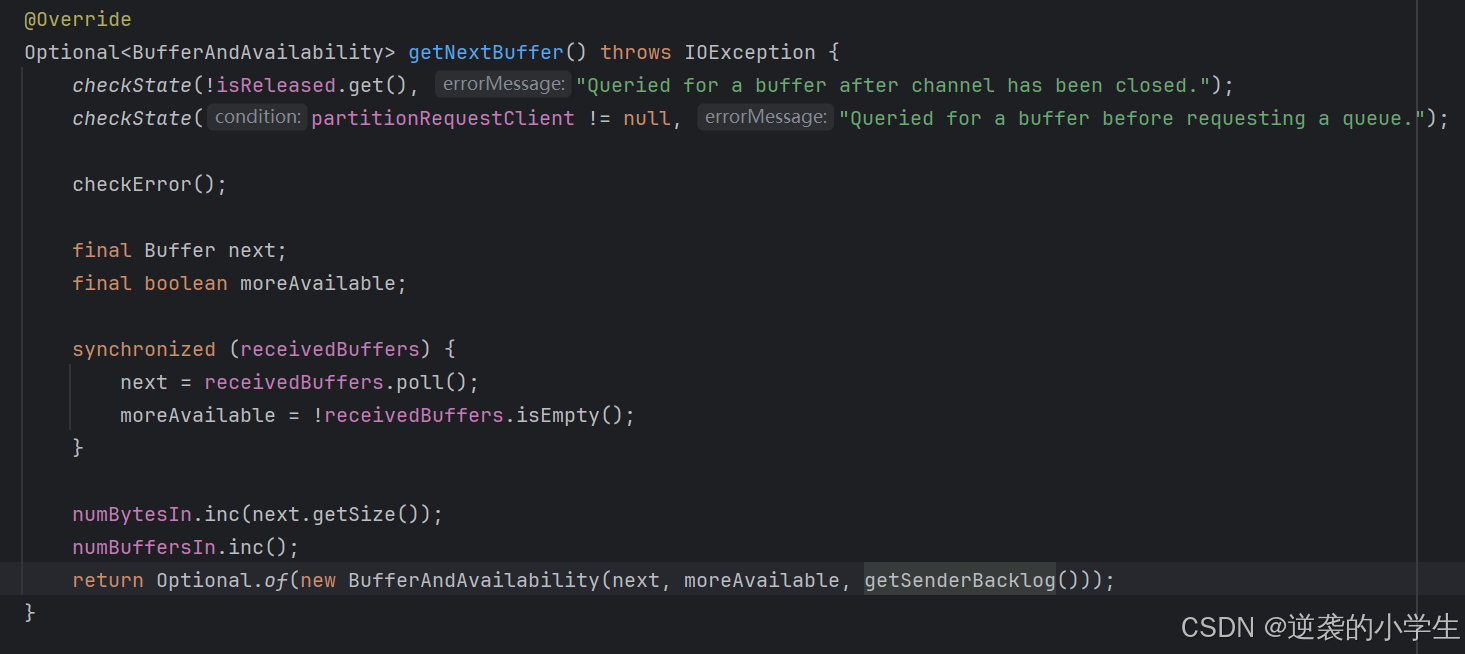
SingleInputGate收到数据后,通过视图,调用RemoteInputChannel的getNextBuffer读取数据,可以看到,是从receivedBuffers取出buffer,进行封装后返回
五、反压机制源码分析
5.1 基本思路
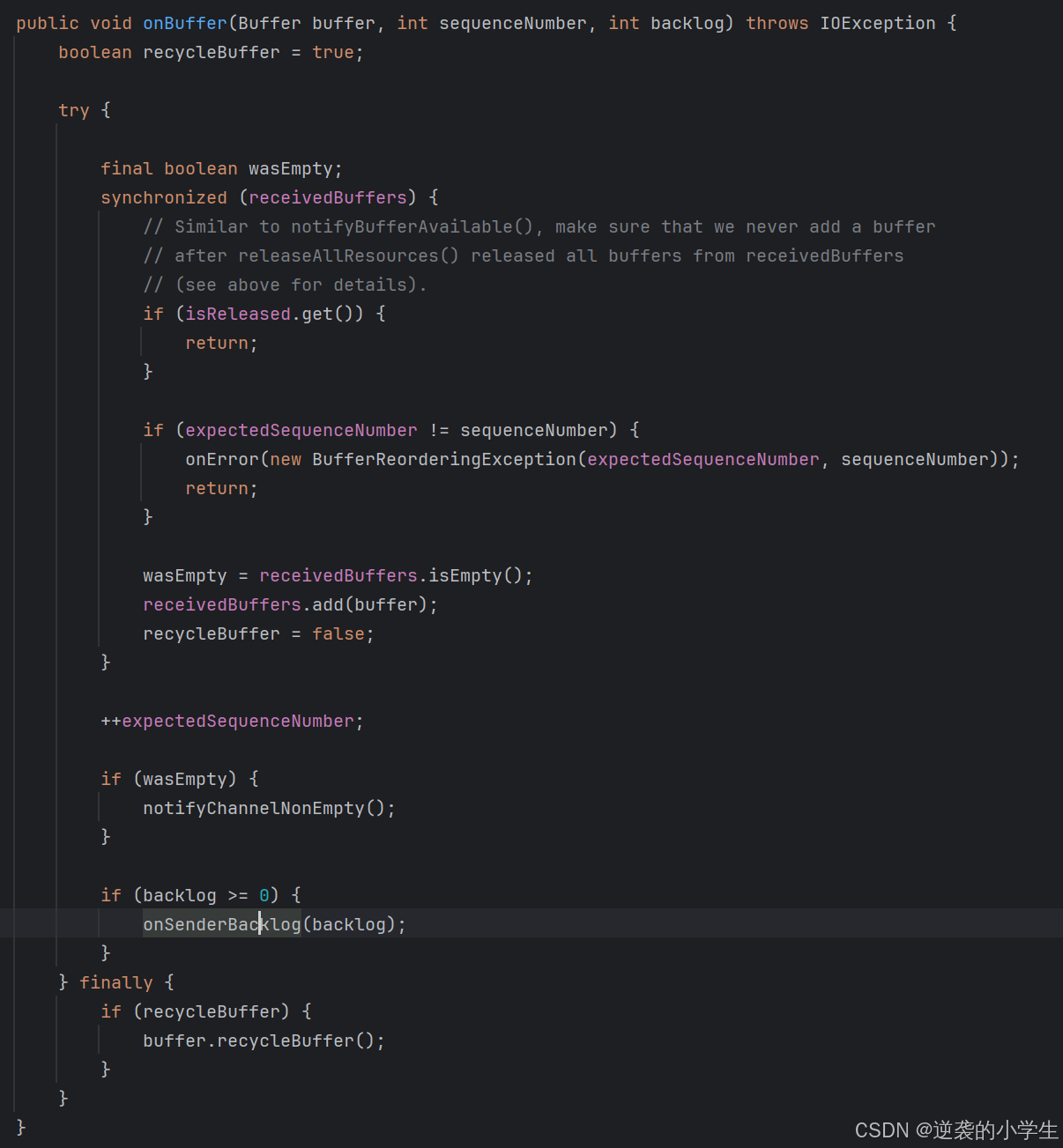
开始时,下游给上游初始化一个credit
上游每次向下游发送数据,该credit会减1,并且发送的数据中会附带自己的backlog(即还剩多少个buffer没发出去),如果credit减到0,上游将不会再将下游发送数据
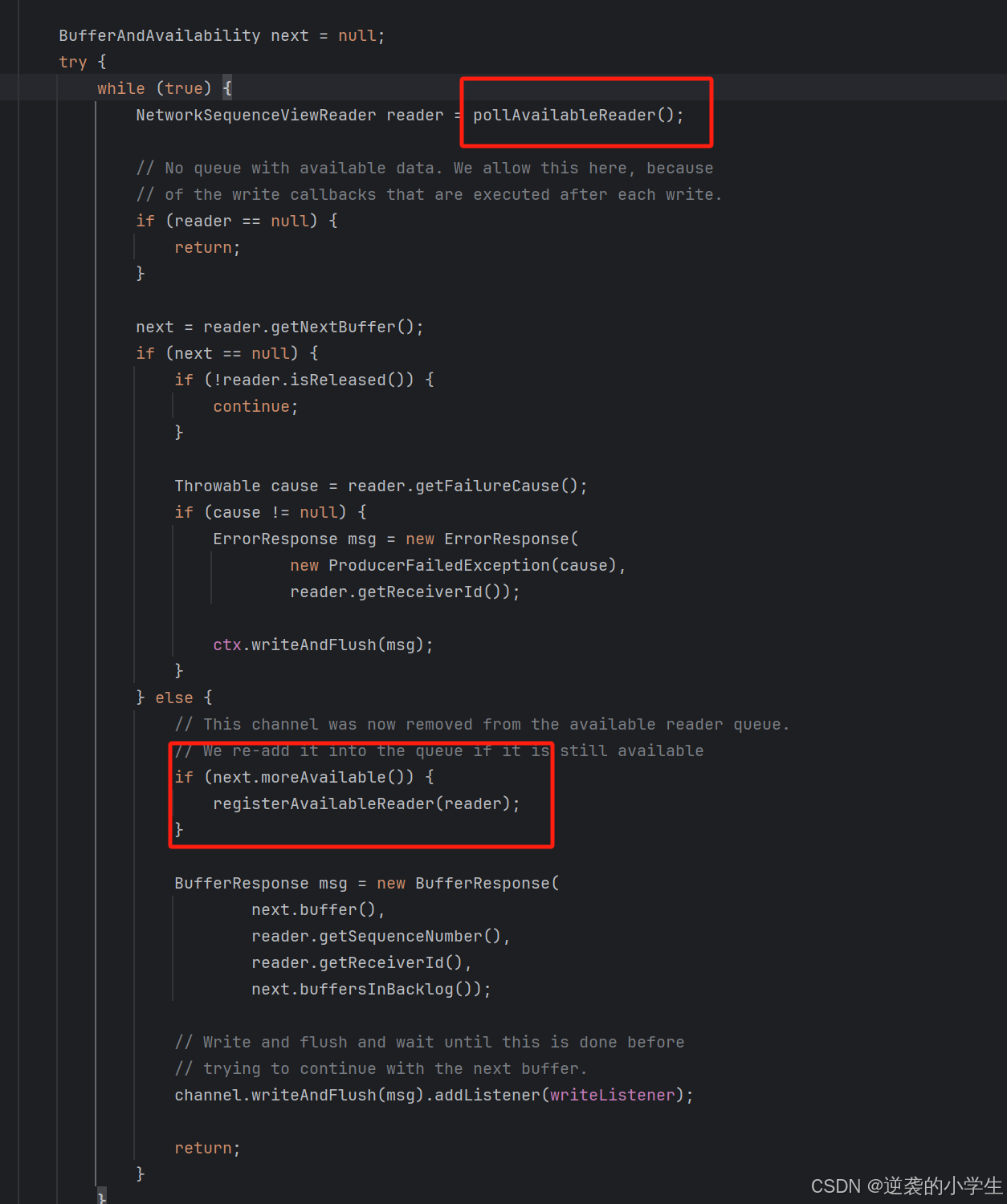
下游收到backlog后,计算自己的可用buffer和上游需要的backlog buffer哪个大,如果上游需要的大,从inputGate中申请buffer
然后下游把自己的新的credit发送给上游,上游更新credit
5.2 信用值发送具体实现
PipelinedSubpartition写入数据时会调用notifyDataAvailable()
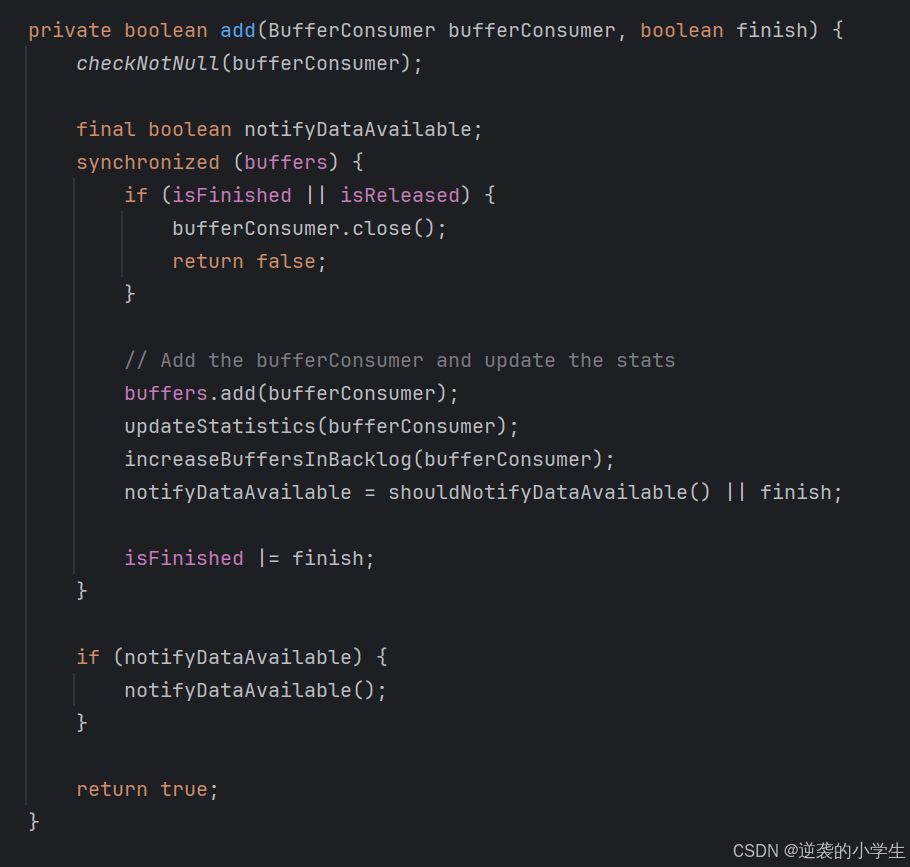
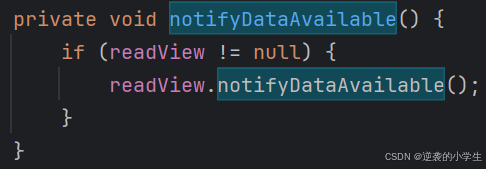
视图的notifyDataAvailable会调用CreditBasedSequenceNumberingViewReader类的notifyDataAvailable()方法,然后会调用userEventTriggered,最终会调用如下方法
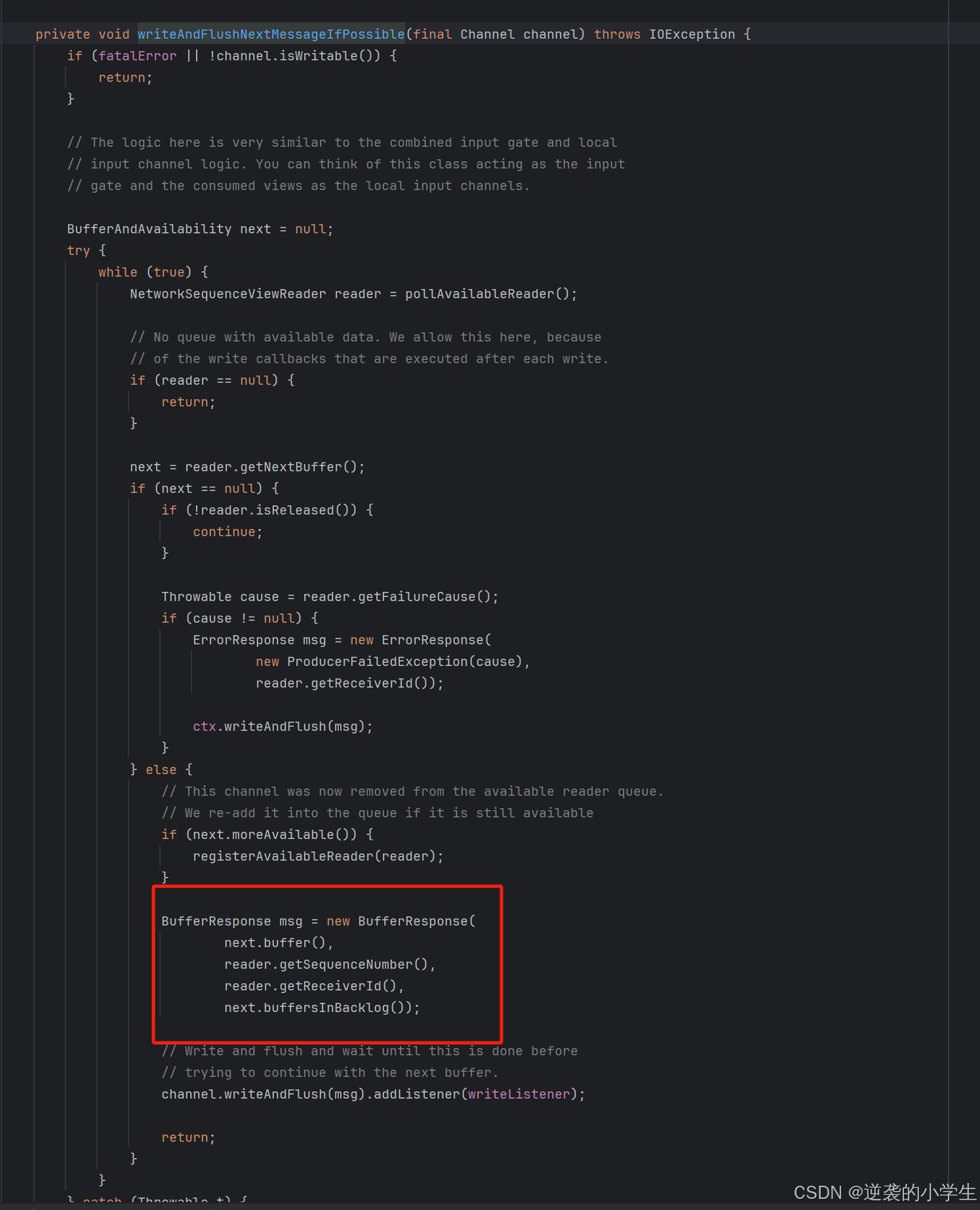
上图中的getNextBuffer进行发送时,会将信用值减少1
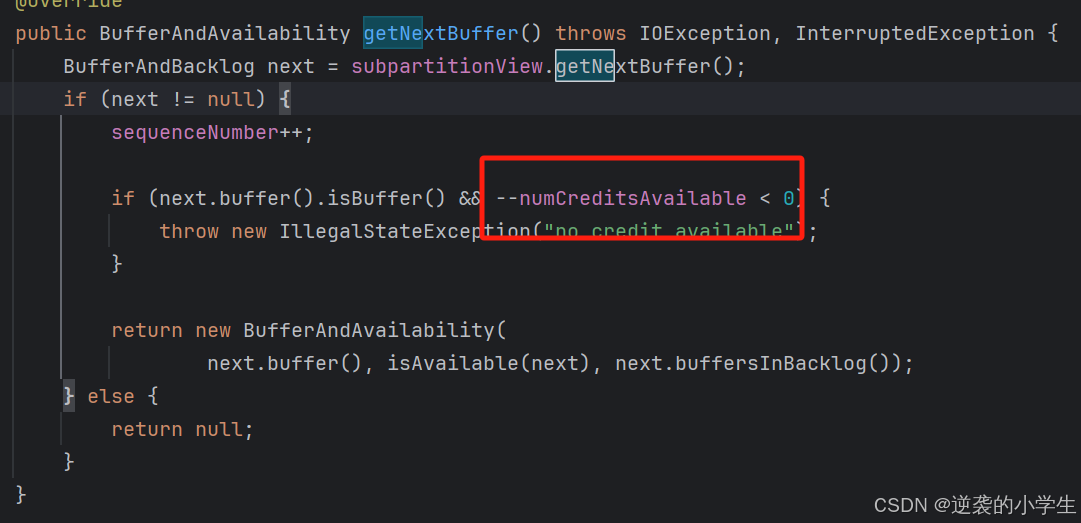
最后通过BufferResponse发送数据时,将backlog(剩余多少缓存未发出)等进行发送
5.3 信用值回传具体实现
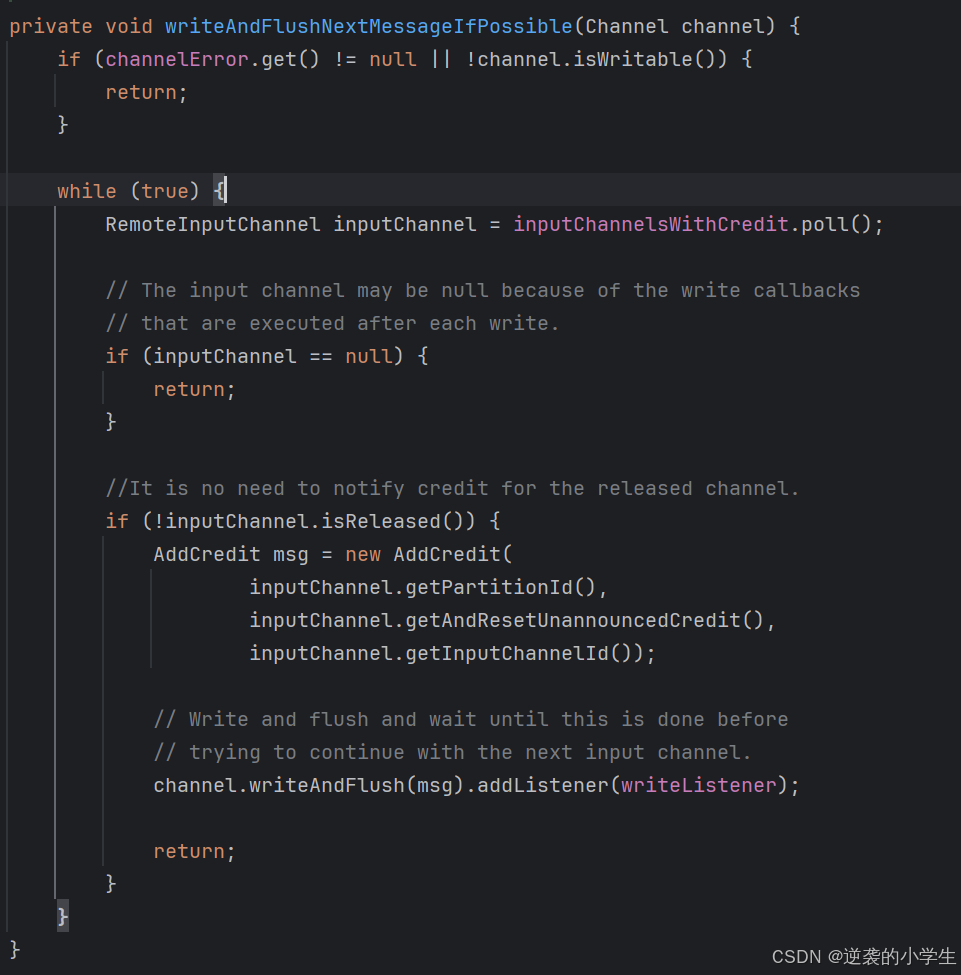
InputChannel收到数据backlog,计算自己的可用buffer和上游需要的backlog buffer哪个大,如果上游需要的大,从inputGate中申请buffer
然后把新的credit回传


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









