







前言:之前看过JVM的内存模型,无非是方法区、堆、本地栈、程序计数器、虚拟机栈,然后区别哪个是线程私有,哪个是线程共享,大概是干什么的,存的是什么,其余的似乎没了解太多,如看常量池到底存储在哪?什么样的东西会存储在常量池?类的元信息存储在元空间,类的元信息包括什么?所以今天重新学了一下JVM内存模型,说点高级内容,知识来源于网络,不保证一定没问题,这块网上好像也没个准信,等以后有机会再深入一下吧。
目录
第一章 JVM内存模型概要
根据 JVM 规范,JVM 内存共分为程序计数器,虚拟机栈、本地方法栈,堆、方法区、五个部分,值得注意是这仅仅是JVM规范,最后的实现还有所不同。
在规范中,方法区应该存储静态变量 + 常量 + 类信息(构造方法/接口定义) + 运行时常量池 (参考:https://www.jianshu.com/p/7d9e64973444)。

第二章 随版本变更的方法区
参考:https://www.jianshu.com/p/59f98076b382
方法区自动规范定义以来,存储的信息一直在更改
2.1 JDK6
- Klass 元数据信息
- 每个类的运行时常量池(字段、方法、类、接口等符号引用)、编译后的代码
- 静态字段(无论是否有final)在 instanceKlass 末尾(位于 PermGen 内)
- oop(Ordinary Object Pointer(普通对象指针)) 其实就是 Class 对象实例
- 全局字符串常量池 StringTable,本质上就是个 Hashtable
- 符号引用(类型指针是 SymbolKlass)
2.2 JDK7
- Klass 元数据信息
- 每个类的运行时常量池(字段、方法、类、接口等符号引用)、编译后的代码
- 静态字段从 instanceKlass 末尾移动到了 java.lang.Class 对象(oop)的末尾(位于 Java Heap 内)
- oop 与全局字符串常量池移到 Java Heap 上
- 符号引用被移动到 Native Heap 中
2.3 JDK8
- 移除永久代
- Klass 元数据信息
- 每个类的运行时常量池、编译后的代码移到了另一块与堆不相连的本地内存 -- 元空间(Metaspace)
第三章 JDK1.8中方法区的实现
参考:https://www.jianshu.com/p/7d9e64973444
在jdk1.8中,元空间是方法区的实现,但具体细节又有不同,根据上面我们也可以看出,元空间存储了class的相关信息,包括class的method与field等,使用的是本地内存,不是JVM内存,常量池已被移动到堆中,
根据第二章、第三章内容来说,静态变量+常量+运行时常量池这些原本定义该存储在方法区中的东西,在JDK1.8中已经保存到了堆中,只剩类信息还存储在方法区的实现即元空间中。
第四章 类的相关信息
参考:
https://www.jianshu.com/p/7d9e64973444
https://www.jianshu.com/p/68520593b999
上面说到,元空间存储了类的相关信息,那么类的相关信息包括什么呢。
我们写的每一个Java类被编译后,就会形成一份class文件,class文件中除了包含类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池(constant pool table)。
第五章 常量池
参考:https://blog.youkuaiyun.com/qq_26222859/article/details/73135660
上面提到了常量、常量池,我所了解的还有运行时常量池,它们有什么区别呢?
5.1 全局字符串池
全局字符串池里的内容是在类加载完成,经过验证,准备阶段之后在堆中生成字符串对象实例,然后将该字符串对象实例的引用值存到string pool中(记住:string pool中存的是引用值而不是具体的实例对象,具体的实例对象是在堆中开辟的一块空间存放的。)。 在HotSpot VM里实现的string pool功能的是一个StringTable类,它是一个哈希表,里面存的是驻留字符串(也就是我们常说的用双引号括起来的)的引用(而不是驻留字符串实例本身),也就是说在堆中的某些字符串实例被这个StringTable引用之后就等同被赋予了”驻留字符串”的身份。
5.2 class文件常量池
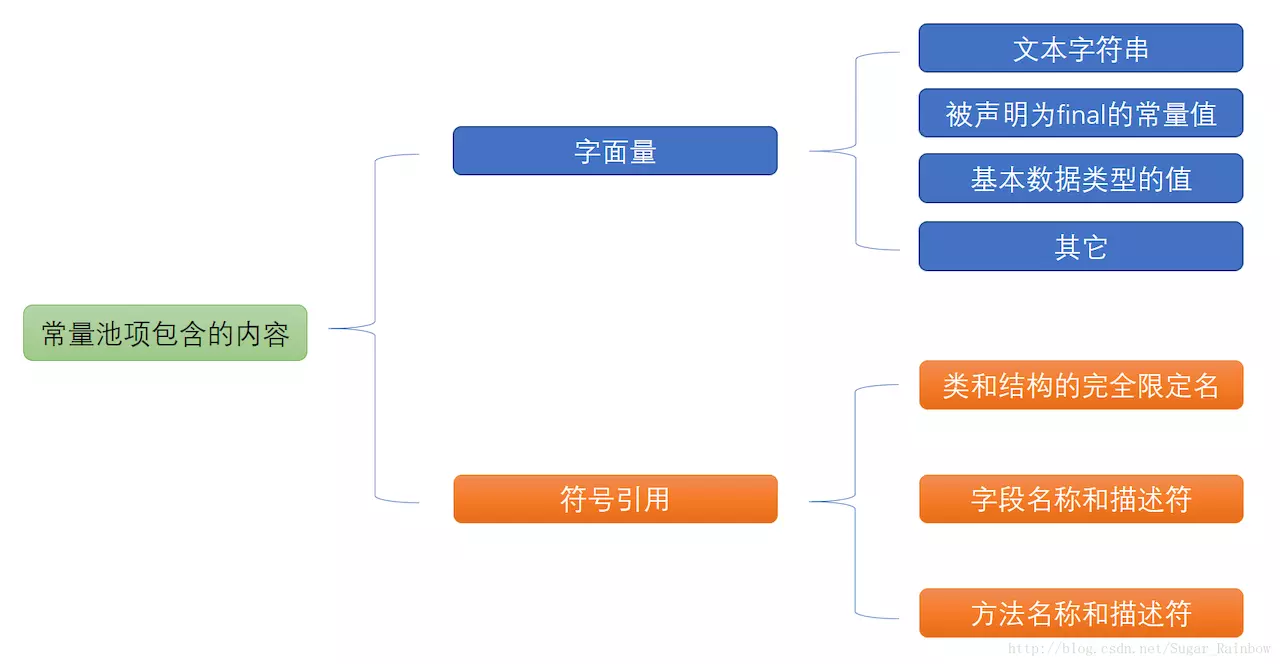
class文件中除了包含类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池(constant pool table),用于存放编译器生成的各种字面量(Literal)和符号引用(Symbolic References);
字面量就是我们所说的常量概念,如文本字符串、被声明为final的常量值等。
符号引用是一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可(它与直接引用区分一下,直接引用一般是指向方法区的本地指针,相对偏移量或是一个能间接定位到目标的句柄)。一般包括下面三类常量:
- 类和接口的全限定名
- 字段的名称和描述符
- 方法的名称和描述符
5.3 运行时常量池
jvm对某个类加载完全完成后(经过加载、连接、初始化三个阶段后),jvm就会将class常量池中的内容存放到运行时常量池中,由此可知,运行时常量池也是每个类都有一个。在上面也说了,class常量池中存的是字面量和符号引用,也就是说他们存的并不是对象的实例,而是对象的符号引用值。而经过解析(resolve)之后,也就是把符号引用替换为直接引用,解析的过程会去查询全局字符串池,也就是我们上面所说的StringTable,以保证运行时常量池所引用的字符串与全局字符串池中所引用的是一致的。
5.4 例子
public class HelloWorld {
public static void main(String []args) {
String str1 = "abc";
String str2 = new String("def");
String str3 = "abc";
String str4 = str2.intern();
String str5 = "def";
System.out.println(str1 == str3);//true
System.out.println(str2 == str4);//false
System.out.println(str4 == str5);//true
}
}首先,在堆中会有一个”abc”实例,全局StringTable中存放着”abc”的一个引用值。
然后在运行第二句的时候会生成两个实例,一个是”def”的实例对象,并且StringTable中存储一个”def”的引用值,还有一个是new出来的一个”def”的实例对象,与上面那个是不同的实例。
当在解析str3的时候查找StringTable,里面有”abc”的全局驻留字符串引用,所以str3的引用地址与之前的那个已存在的相同。
str4是在运行的时候调用intern()函数,返回StringTable中”def”的引用值,如果没有就将str2的引用值添加进去,在这里,StringTable中已经有了”def”的引用值了,所以返回上面在new str2的时候添加到StringTable中的 “def”引用值。
最后str5在解析的时候就也是指向存在于StringTable中的”def”的引用值。
那么这样一分析之后,下面三个打印的值就容易理解了。上面程序的首先经过编译之后,在该类的class常量池中存放一些符号引用,然后类加载之后,将class常量池中存放的符号引用转存到运行时常量池中,然后经过验证,准备阶段之后,在堆中生成驻留字符串的实例对象(也就是上例中str1所指向的”abc”实例对象),然后将这个对象的引用存到全局String Pool中,也就是StringTable中,最后在解析阶段,要把运行时常量池中的符号引用替换成直接引用,那么就直接查询StringTable,保证StringTable里的引用值与运行时常量池中的引用值一致,大概整个过程就是这样了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









