







目录
1.安装
1.下载
进入到官网http://zeppelin.apache.org/,手动下载或者通过命令方式下载
如果下载慢,可以通过迅雷下载
wget https://dlcdn.apache.org/zeppelin/zeppelin-0.10.0/zeppelin-0.10.0-bin-all.tgz
2.解压
tar -xzvf zeppelin-0.10.0-bin-all.tgz -C /usr/local
3.配置
进入到conf目录
cp zeppelin-env.sh.template zeppelin-env.sh
cp zeppelin-site.xml.template zeppelin-site.xml
vim zeppelin-env.sh //配置JAVA_HOME地址,如果JAVA_HOME已经在系统变量中设置过了则不用再设置
vim zeppelin-site.xml //改zeppelin.server.addr中的value为0.0.0.0和zeppelin端口号为8999(避免和其他端口冲突)
//创建zeppelin并将用户的组改为hadoop
useradd zeppelin -g hadoop
//将zeppelin安装目录拥有者改为zeppelin,组的改为hadoop
chown zeppelin -R zeppelin-0.10.0-bin-all
chgrp hadoop -R zeppelin-0.10.0-bin-all4.切换zeppelin用户并启动Zeppelin
su zeppelin
bin/zeppelin-daemon.sh start
此时可以通过jps命令看到ZeppelinServer进程
5.访问
2.集成spark
1.进入拦截器
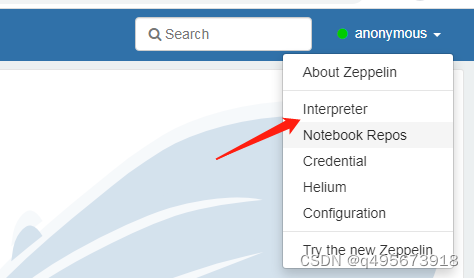
2.搜索spark相关配置
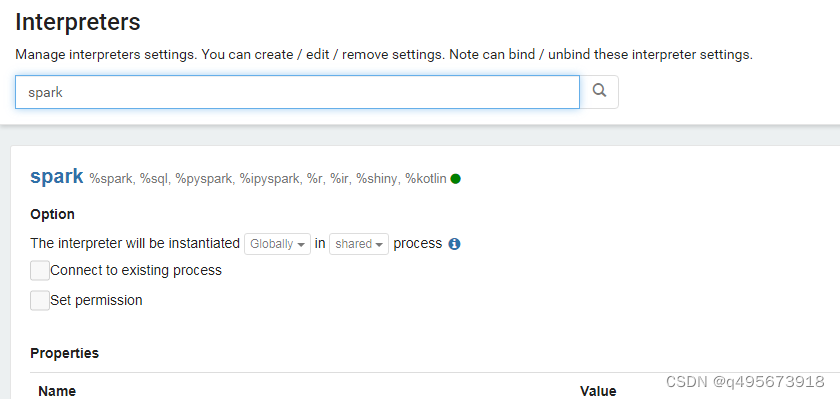
3.修改spark相关配置
指定spark_home,模式,启动用户等
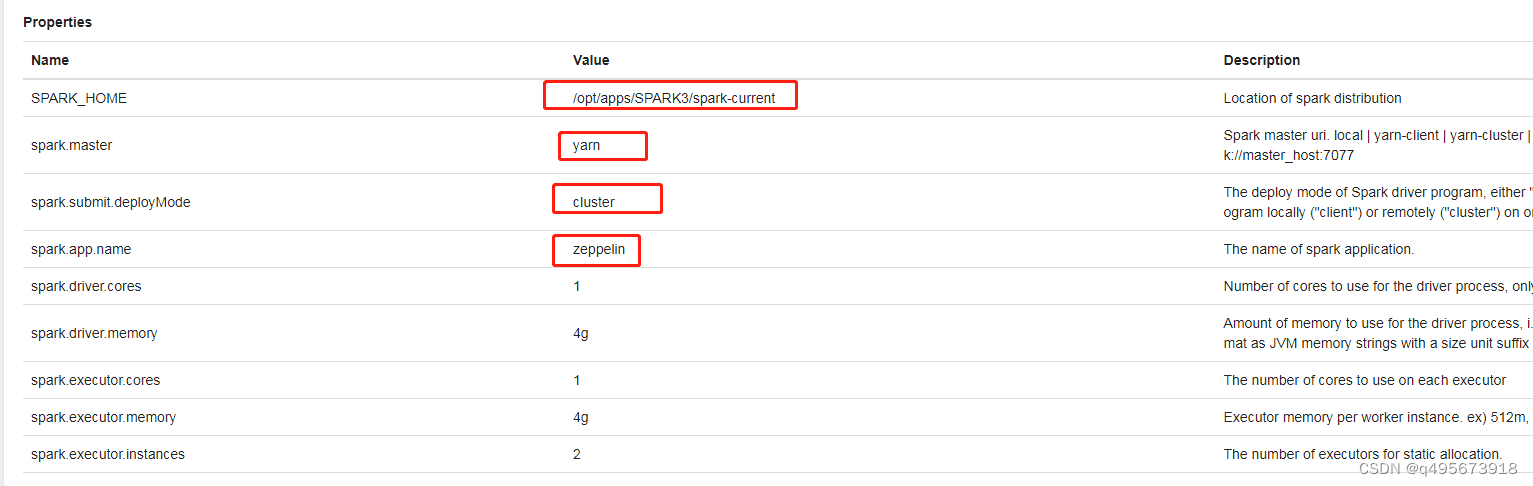
也可以添加属性spark.yarn.queue,设置使用队列
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 199
199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









