









散列表
-
根据键(Key)直接访问在内存储存位置的数据结构。它通过计算出一个键值的函数,将key映射到表中一个位置来访问,这加快了查找速度。 这个映射函数称做散列函数,存放记录的数组称做散列表。
-
-
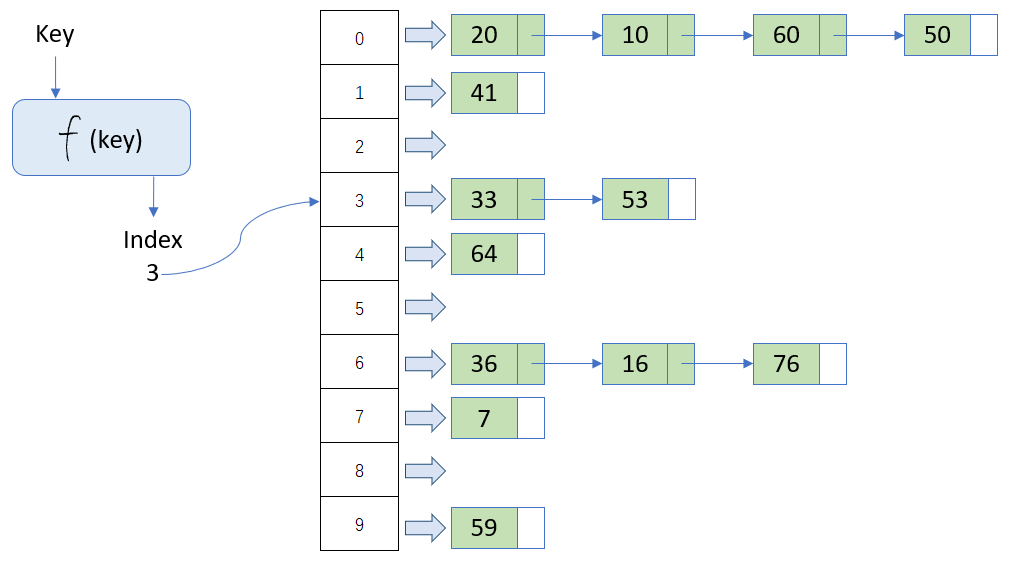
存储: 哈希表 使用 哈希函数 将键(key)转换成一个 哈希值。然后在数组中获取对应的值,如果有值就会用链表的形式存储。
查询: 存储的过程理解了,查询看着下面流程也应该能理解。
key->f(key)->index->list[index]->linked_list。
删除: 需要注意的是删除链表的第一条数据和,链表中的数据需要额外的逻辑判断。 -
package main import ( "fmt" ) type Bucket struct { HKey string Data string } type NoLinkHashTable struct { Capacity int32 Used int32 Buckets []*Bucket lock int32 } func NewNoLinkHashTable(length int32) *NoLinkHashTable { return &NoLinkHashTable{ Capacity: length, Buckets: make([]*Bucket, length), } } /** 设置节点 */ func (t *NoLinkHashTable) hSet(key string, value string) { bucket := &Bucket{key, value} hashCode := t.getHashCode(key) index := hashCode % (t.Capacity - 1) t.addBucket(index, key, bucket) } /** 查找节点 */ func (t *NoLinkHashTable) hGet(key string) *Bucket { hashCode := t.getHashCode(key) index := hashCode % (t.Capacity - 1) return t.findBucket(index, key) } /** 查找节点 */ func (t *NoLinkHashTable) findBucket(index int32, key string) *Bucket { if ok := t.Buckets[index]; ok != nil { if t.Buckets[index].HKey == key { return t.Buckets[index] } else { index++ } for { if ok := t.Buckets[index]; ok != nil { if t.Buckets[index].HKey == key { return t.Buckets[index] } else { index++ } } else { return nil } } } return nil } /** 增加节点 */ func (t *NoLinkHashTable) addBucket(index int32, key string, bucket *Bucket) { if t.Capacity == t.Used { panic("table is full") } fmt.Println("index:", index) if ok := t.Buckets[index]; ok != nil { //key已存在 if ok.HKey == key { //如果key相同 直接覆盖 t.Buckets[index] = bucket return } index++ for { if index >= t.Capacity { t.Capacity++ tmp := t.Buckets t.Buckets = make([]*Bucket, 0) t.Buckets = append(t.Buckets, tmp...) index = 0 } if ok := t.Buckets[index]; ok != nil { if ok.HKey == key { //如果key相同 直接覆盖 t.Buckets[index] = bucket return } index++ } } } else { t.Buckets[index] = bucket t.Used++ } } func (t *NoLinkHashTable) getHashCode(key string) int32 { sum := 0 for _, v := range key { sum += int(v) } return int32(sum) % t.Capacity } func main() { b := NewNoLinkHashTable(8) b.hSet("name", "xiaoGe") b.hSet("sex", "男") b.hSet("age", "30") fmt.Println(b.hGet("name").Data) fmt.Println(b.hGet("sex").Data) /** index: 1 index: 0 index: 5 xiaoGe 男 */ }


















 785
785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











