






 本文详细介绍了在Ubuntu系统上配置PyTracking系列跟踪算法(如LWL、KYS、PrDiMP等)的步骤,包括Python和Torch版本选择、conda安装、CUDA环境设置、模型训练(涉及COCO数据集和HOT数据集)、以及测试和可视化过程。
本文详细介绍了在Ubuntu系统上配置PyTracking系列跟踪算法(如LWL、KYS、PrDiMP等)的步骤,包括Python和Torch版本选择、conda安装、CUDA环境设置、模型训练(涉及COCO数据集和HOT数据集)、以及测试和可视化过程。
一、环境配置及测试
参考 pytracking系列跟踪算法的配置(LWL, KYS, PrDiMP, DiMP and ATOM Trackers)(Ubuntu版本)-优快云博客
几个注意事项
1、python版本选择了3.7,torch版本选择了1.7.0。之前尝试了python=3.9,torch=1.13.0,后来各个库之间出现了版本冲突,舍弃了。
2、安装pytorch使用conda安装
3、即使用conda安装torch也会报错RuntimeError: Error building extension '_prroi_pooling'
解决办法为添加环境变量
vim ~/.bashrc
export CUDA_HOME=/usr/local/cuda-11.1
source ~/.bashrc
4、需要运行可视化服务器,否则会报错
二、训练模型
1、默认的是coco2014,服务器里存的是2017,把/ltr/dataset/coco.py和coco_seq.py里的version从2014改为2017
三、训练HOT数据集
1、在/ltr/dataset/__init__.py中添加
from .hot_false import HOT_False
2、在/ltr/dataset/中仿照Got10K处理方式,创建hot_false.py
3、修改 /ltr/train_settings/bbreg/atom.py
Train dataset s中将其它数据集注释掉,添加 hot_false_train = HOT_False(settings.env.hot_false_dir, split='train')
Validation datasets 中 hot_false_val = HOT_False(settings.env.hot_false_dir, split='test')
dataset_train、dataset_val 中只保留一个训练集
backbone_pretrained 可以设为False
settings.batch_size 由默认64改为1024
加入代码块以开启多卡训练
from ltr import MultiGPU
settings.multi_gpu = True
if settings.multi_gpu:
net = MultiGPU(net, dim=1)
三、测试
1、把保存的 checkpoint 文件复制到 /pytracking/networks/ 中
2、修改 /pytracking/parameter/atom/default.py 中加载的权重文件名称
3、在 /pytracking/evaluation/datasets.py 中加入 hot_false
4、在 /pytracking/evaluation/ 中新建一个 hot_falsedataset.py
5、修改 /pytracking/utils/load_text.py,加入适用于 HOT_False 和 HOT 数据集的函数
6、在 HOT 的一个序列上测试,并可视化跟踪结果
运行 python -m visdom.server
运行 python pytracking/run_tracker.py atom default --runid 1 --dataset_name hot_false --sequence ball --debug 1 --threads 0
7、在 HOT 的全部序列上逐个可视化
在 /pytracking/experiments/myexperiments.py 中添加
def atom_hot_false()
运行 python pytracking/run_experiment.py myexperiments atom_hot_false --runid 1 --debug 1 --threads 0
8、绘图
要先运行 run_tracker.py 或 run_experiment.py,这里 debug=0,用来保存结果
根据 /pytracking/notebooks/analyze_results.ipynb 在 /pytracking/ 下创建 run_analyze.py
注意 runid 的设置,以对应到某一个具体的保存路径下
结果包含三部分:一个精度表、一个precision曲线、一个success曲线(结果是随便训的,以便快速得到结果)

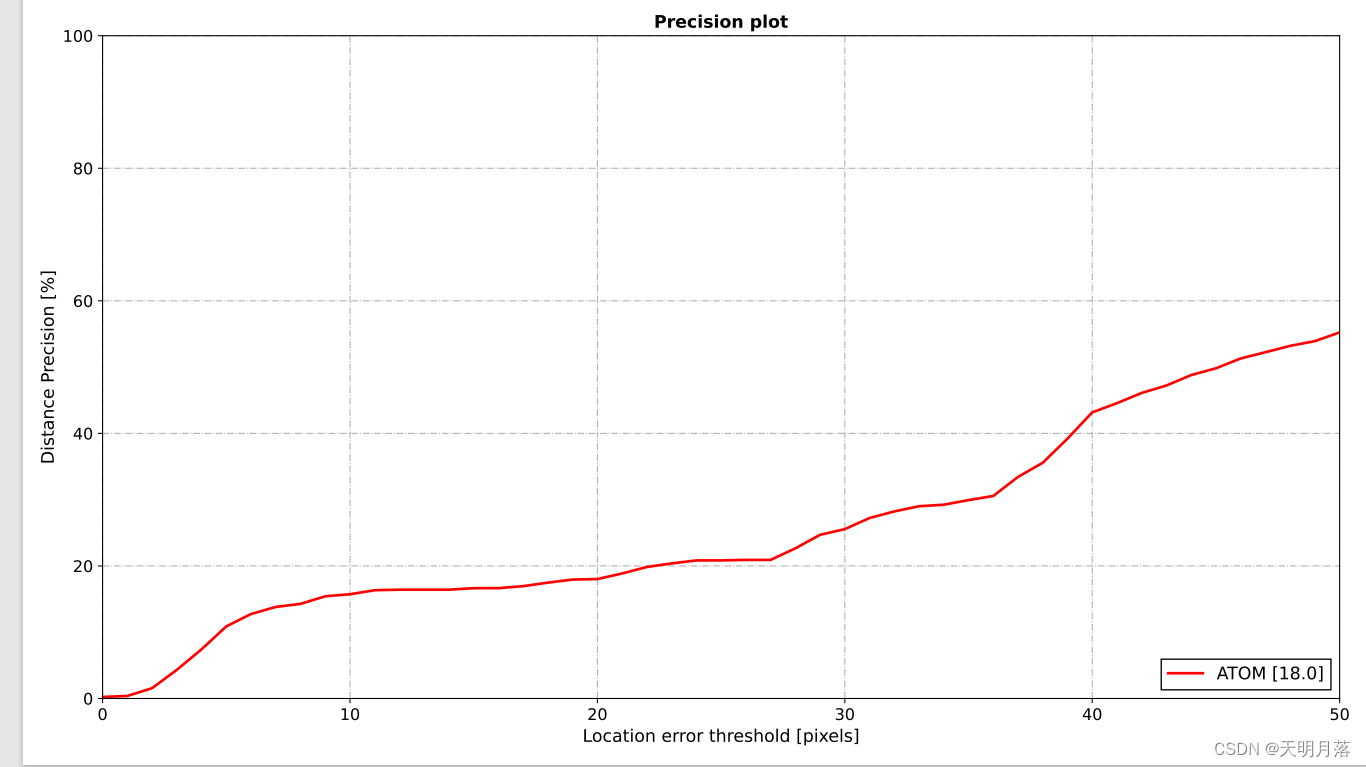
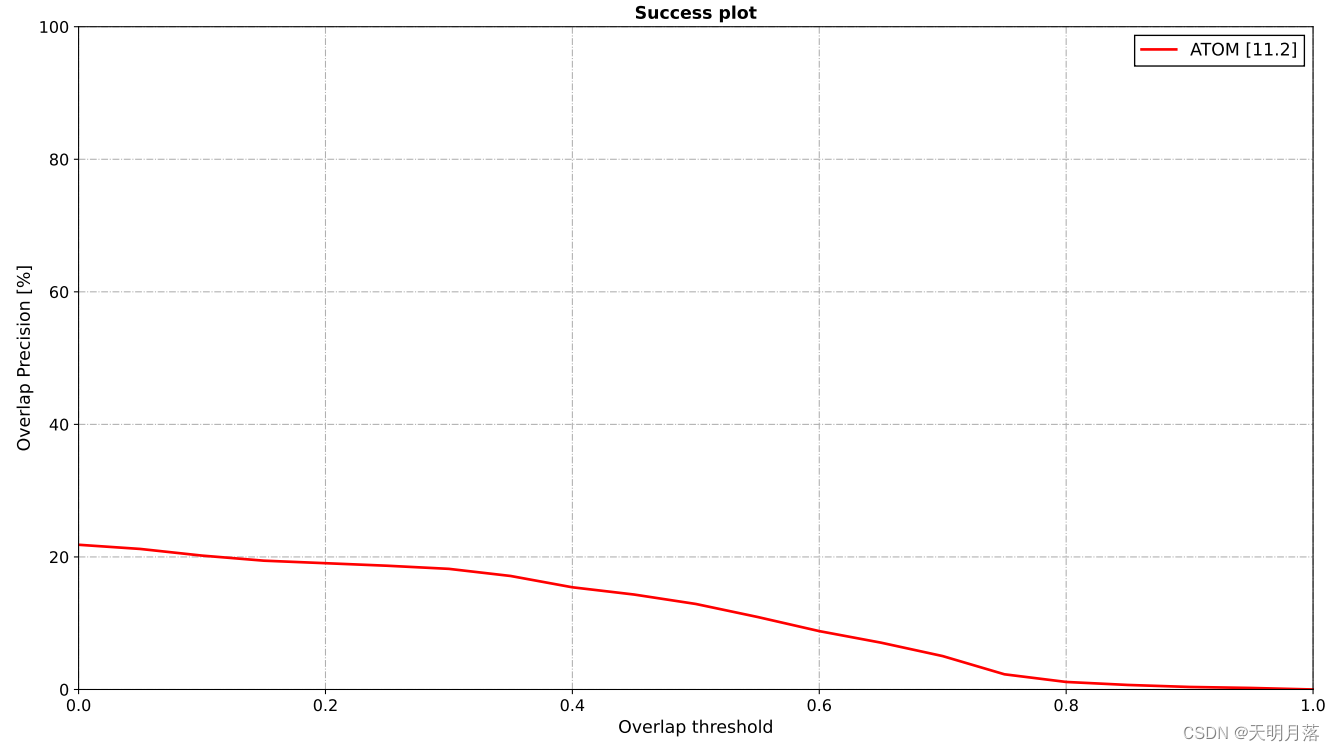

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









