






我的疑问
不知道各位有没有观察过:在数据库启动以后,内存会一直缓慢增长(废话!),但是这里有个细节。
sga的固定区域不说了。
pga的大小是个target值,正常情况下应该是结果集大的超过pga的值后,就会触发进程的收缩回收,这样就把target值控制到目标了,然后也不影响超大结果集膨胀uga的情况。这个也是常见oom的原理。
但是还有一种情况,在连接数和pga都维持在稳定状态时。内存仍然会缓慢增高,然后达到一个值以后平稳下去。这个问题一直困扰着我,不仅在数据库视图都显示正常,从系统进程上观察也都是正常的。
我的答案
我在一次case中发现了这个问题
使用top 大写M,可以看到进程的内存使用,其中free -g的物理内存使用,是通过res(又叫rss或rsz)来计算的,这个部分会有一个shr共享内存段。
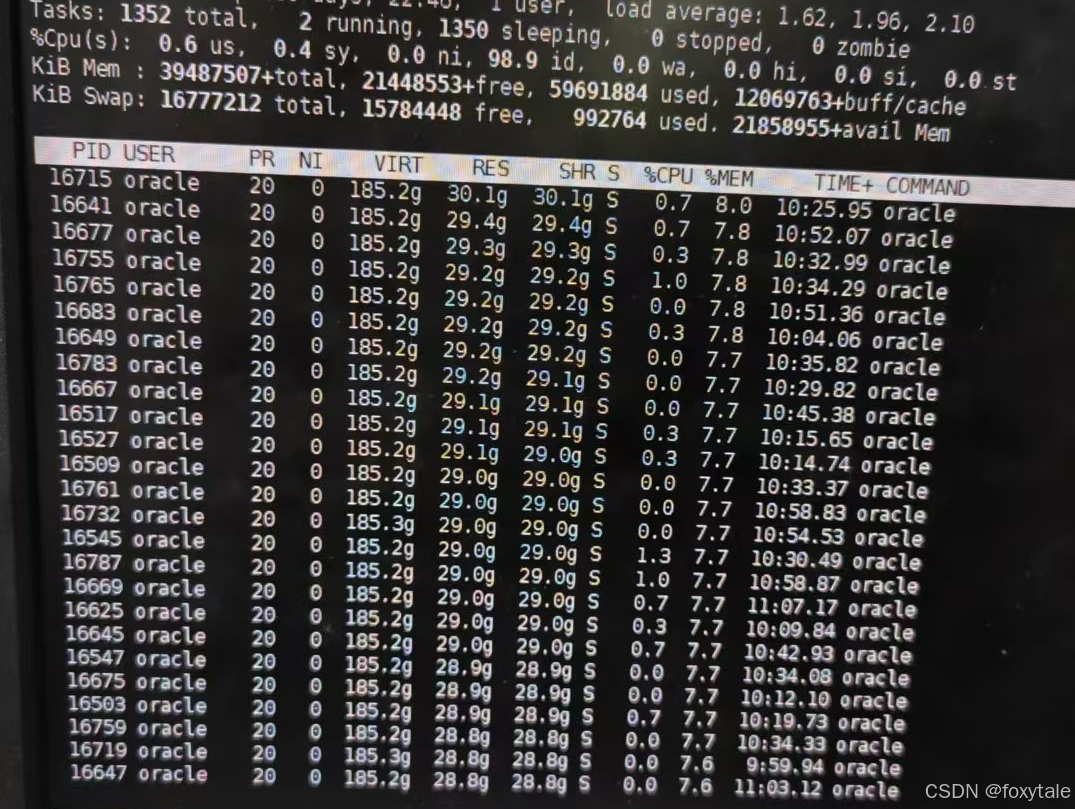
我对这个shr是谁的共享段,其实一直有疑问。我在其他的环境上,很少能看到占用shr这么大的。
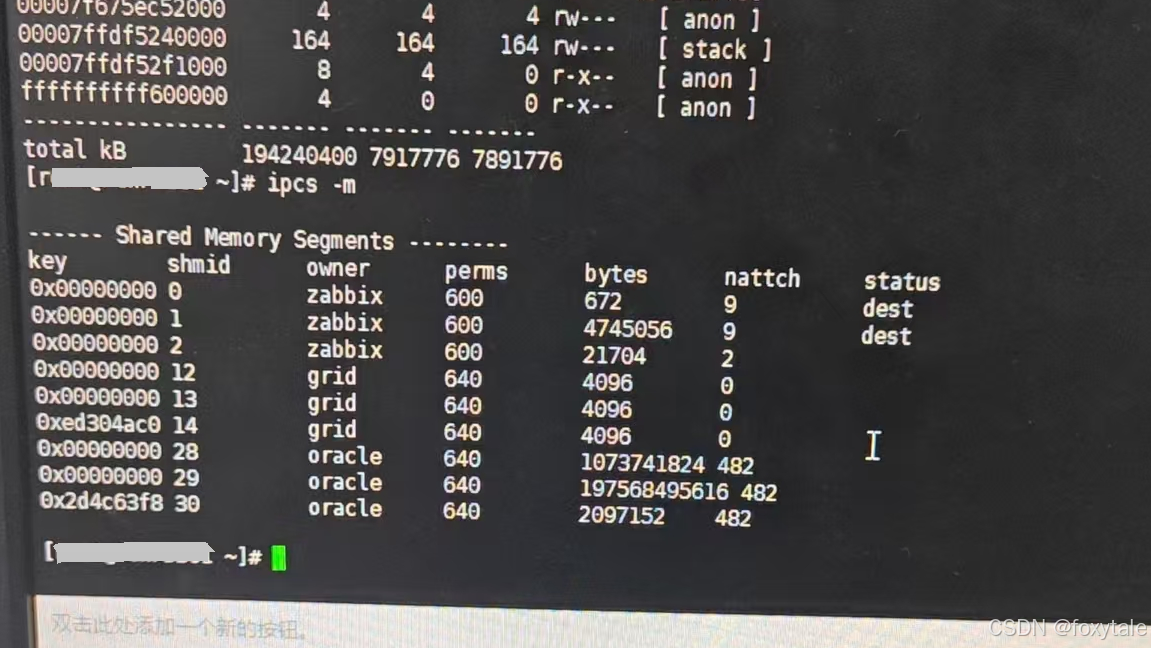
但是通过pmap查看进程共享段的shmid是0x1d(换10进制就是29)
通过ipcs可以看到,该共享段就是数据库的sga的共享段
因为该系统没有使用hugepage。当进程的rss越来越大,他的对应的pagetable也会变大
这里转个计算公式
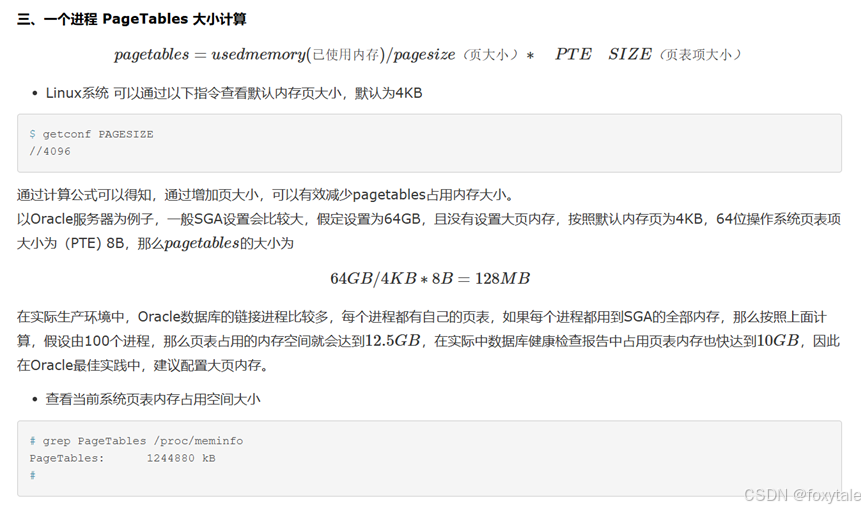
速算一下,这种rss有28g的进程,他的pagetable就有60m,而且这部分内存是无法被数据库的视图监控到的!因为这是操作系统虚拟内存的映射。
当连接一直不清理的情况下,因为sql和内存地址的随机性,逐渐访问的共享内存会变多,导致持有的pagetable增大
当连接一直不清理的情况下,各个连接逐渐访问全部能访问的共享内存。会逐渐达到一个稳定的内存使用
我的思考
1、如果数据库的连接有新晨代谢,应用连接池初始值给的较小,他会在峰值后随机清理掉连接,这样就能将进程持有的页表释放掉。
2、这个pagetable因为是来自于共享内存段的虚拟地址映射,会有上限。保证操作系统的20%空闲空间可以避免这个事。
3、页表占用的内存是无法算到pga中的,这个又跟进程连接数正相关,不过hugepage倒是可以极大减少页表的大小。如果你的数据库会有极高的连接数,需要设置一些参数维持连接的新晨代谢。像是expire_time这样的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









