






大数据软件生态系统
一 概况
1
数据采集
数据存储与管理—集群分布式存储–分布式存储—分布式数据库BigTable\分布式文件系统GFS
数据处理与分析—分布式处理—分布式并行处理技术MapReduce
数据隐私与安全
不同的计算模式需要使用不同的分布式处理产品:批处理【MapReduce是批处理计算模式的典型代表】【Spark】、实时计算–流计算【流计算代表产品:S4,Storm,Flume】、图计算【处理图结构数据{社交网络数据},代表软件:Google Pregel】、交互计算【即交互式查询,代表产品Hive】
2 云计算解决了什么核心问题?
分布式存储、分布式处理
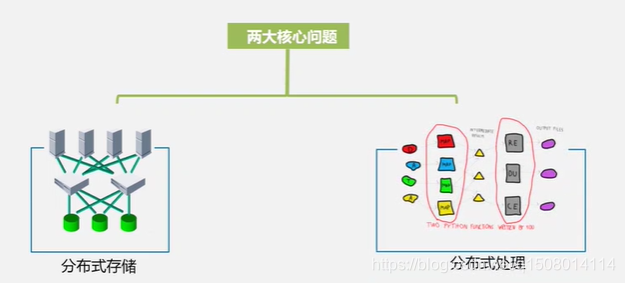
云计算是通过网络以服务的方式为用户提供非常廉价的IT资源。
3 物联网
识别技术:条形码
感知技术:公交卡(RFID公交卡)
零 基础知识
1 OS:操作系统
FS文件系统:基于硬盘 之上的一个文件管理的工具
DFS分布式文件系统:数据存放在多台电脑上存储
2 Block拆分的标准【数据拆分在不同电脑上】
文件可视为字节数据,即数组切分
拆分的数据块等大
真实情况下,会根据文件大小和集群节点的数量综合考虑块的大小
注意:HDFS中一旦文件被存储,数据不允许被修改。可以追加数据,但是不推荐。一般HDFS存储的都是历史数据,所以将来hadoopMapReduce都用来进行离线数据的处理。
3 Block数据安全
会对存储数据进行备份
备份的数据肯定不能存放在一个节点上
使用数据的时候
二 大数据处理架构Hadoop
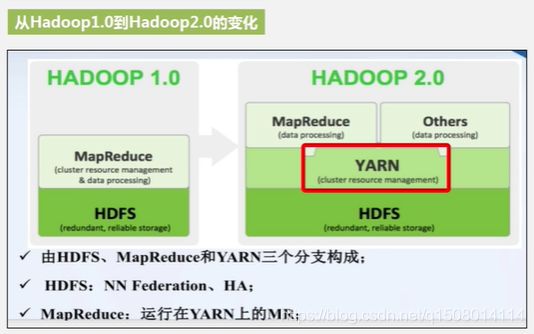
1 发展历程
由APACHE软件基金会旗下开源软件
两大框架: 海量数据的分布式存储—HDFS
海量数据的分布式处理—MapReduce分布式处理框架
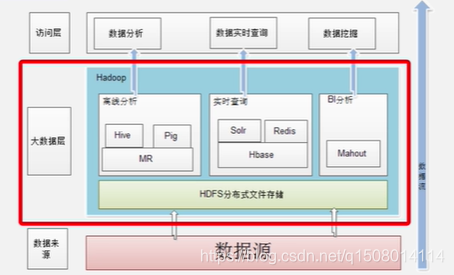
皆为hadoop的组件。
在最旧的版本中,MapReduce负责两个任务:数据处理-数据分析;集群资源调度;—导致工作效率低下。
在改进中,引入YARN负责集群资源调度
HA,设置两个NameNode
2 各个组件及其功能
Hadoop项目结构
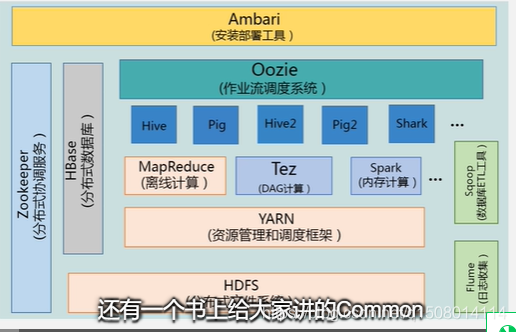
MapReduce基于磁盘计算,即把数据写到磁盘当中取,处理结束后,再写入分布式文件系统中。
Spark基于内存计算,
Hive为数据仓库,用于企业决策分析。可以把大量历史数据都保存在数据仓库中,建立各种维度,从而进行批量数据处理分析,来满足企业的一些要求。例如:判断过去12个月的销售走势。因为在hadoop平台上更容易实现大量数据存储,所以现在很多数据平台仓库转化为hadoop平台。Hive为之一,可以利用SQL语句进行分析。
Pig,流数据处理。提供了类似SQL语句的语法,
Hbase,hadoop平台上的分布式数据库
Flume:专门帮实时收集流数据,—日志【例如访问淘宝记录】【美团利用Flume进行实时日志收集】
Sqoop:用于数据导入导出的,
因为大数据在hadoop平台上进行分析处理,故需要将许多关系型数据库【MYSQL、Oracle】导入到hadoop平台上来。故Sqoop工具可以将系型数据库中的数据直接导入到hadoop平台–可以导入HDFS当中
可以导入HBase当中
可以导入Hive当中
也可以将hadoop平台上的数据导入到关系型数据库
Ambari工具,在一个集群上,智能的去部署和管理一整套Hadoop平台上的各个套件
三 分布式文件系统HDFS
1
一个计算机视为单个节点
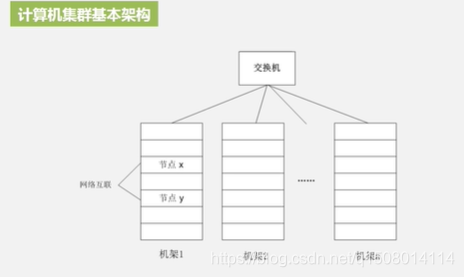
计算机集群结构
机架内部的机器之间是通过光纤高速交换机进行连接;机架与机架之间用带宽更高的几个光纤交换机完成彼此之间的交互与连接。
主节点,从节点
2HDFS 自身局限性
-不适合低延迟数据访问,它面对大规模数据集的流式读写,是为 了批量读全部或大部分数据;而不是非常精确地定位到某一个数据。如果需要读取某一条数据,需要把整个数据读取出来再将其筛选出来。HBse可满足随机读写特性,可以满足实时性处理需求。
-无法高效存储大量 小文件
四 分布式数据库HBase
1
Big Table是架构在谷歌分布式文件系统GFS上的,它的相关存储是通过分布式文件系统GFS去完成存储的。具有非常好的性能【支持PB级别的数据】;具有非常好的可扩展性【用集群去存储几千台服务器完成分布式存储】。
HBase是Big Table的开源实现。—分布式数据库,用来存储非结构化和半结构化的松散数据。 —底层分布式文件系统,存储完全 非结构化的数据。
HBase是可以支持实时****交互式查询的数据库,弥补HDFS的一个缺陷。

2 为什么设计HBase这么一个数据库产品?
HDFS,MapReduce,但是Hadoop主要是解决大规模数据离线批量处理,没有办法办法满足大数据实时处理。传统的数据库扩展能力非常有限。
3 HBase与传统的关系数据库比较
异: 数据类型 -传统的关系数据库用的是关系数据模型;
数据操作-关系数据库当中定义了好多操作【更新、查询、删除】;HBase无法进行多表连接查询。
存储模式-关系数据库行模式存储,HBase基于列存储
数据索引
可伸缩方面-关系数据库很难实现水平扩展,最多可以实现
纵向扩展;HBase不是单台机器,它是完全借助于整个分布式集群,来存储海量数据,故水平扩展性很好
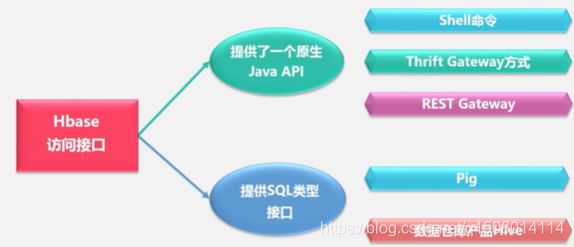
4 HBase 访问接口
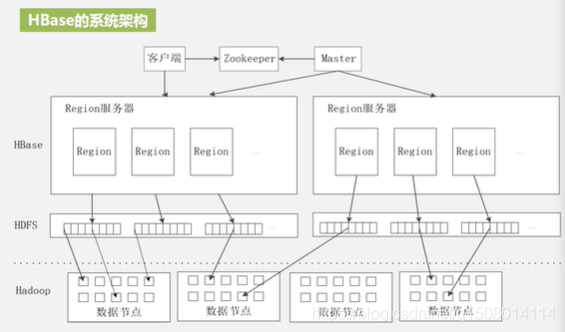
5HBase 的系统架构
五NOSQL数据库
1
具有灵活的水平扩展性、数据模型较灵活、可以利用云计算基础设施
利用传统的关系型数据库对海量数据进行管理,效率比较低下;无法满足高并发需求【高并发需求:】

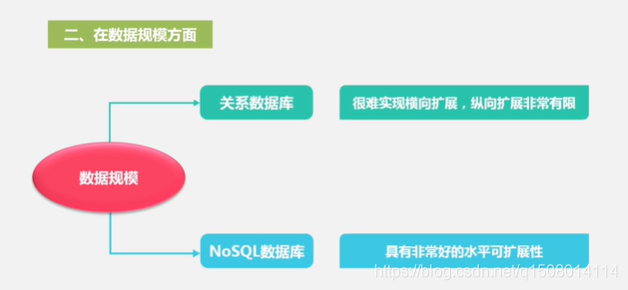
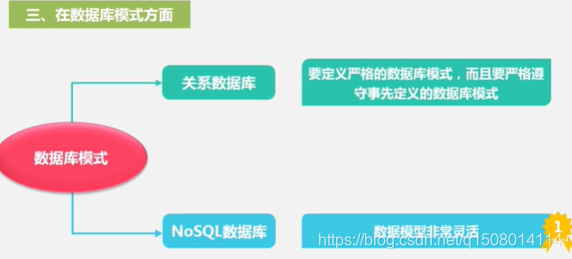
2 NOSQL与关系数据库的比较
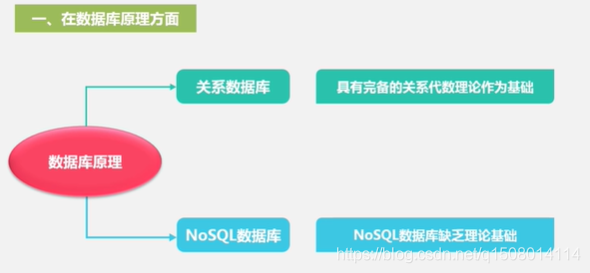
因为NOSQL数据库分为不同的产品大类,这些NOSQL数据库产品没有统一的理论基础。
NOSQL类型
六云数据库
动态可扩展【底层是架构在云计算基础设施之上的,当数据库负载增加的时候,就可以往集群里增加更多的节点】、高可用性
云数据库采用的数据技术还是关系型数据库、NOSQL;只不过是把这些数据库在云端实现;以服务的方式通过网络提供给用户使用;没有自己专有的数据模型。
七 数据仓库Hive【over】
1
数据仓库:一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。
Hive提供了一系列对数据进行提取、转换、加载【ETL】的工具,一般由pig工具完成。
数据源中的数据经过抽取、转换、加载到数据仓库当中以后,很多情况下只读,对它不执行其他的变更操作。故数据仓库中存储大量的历史数据。
为构建在hadoop上的数据仓库工具
Hive本身不支持数据存储、也不支持数据处理;把它看作一个面向用户的编程接口,架构在Hadoop核心组件基础 之上【组件HDFS大规模数据存储;MapReduce大规模数的分布式并行计算】。Hive为用户提供了简单的查询语句,与SQL类似—HiveQL,用户通过编写具体的代码来运行具体的MapReduce任务,来完成数据分析任务。
2 Hive两个特性
采用批处理方式处理海量数据【即HiveQL语句转换为MapReduce任务进行运行】
存储的是静态数据,对静态数据的分析适合采用批处理方式,不需要快速响应给出结果,而且数据本身也不会频繁变化。

Pig与Hive有些类似,不同之处在于:Pig比较适合做实时交互式分析;而不是做大规模数据的批处理。
八 MapReduce
九Spark
1 优点
Spark 基于内存的大数据计算框架,这个采用的是有向无环图DAG的方式
提供了交互式查询语言
通用性,提供了很多软件套装:支持内存计算的Spark Core;完成SQL查询分析的Spark SQL;可以完成流式计算的Spark Streaming;完成机器学习的组件Spark MLlib;完成图计算的软件GraphX;
运行模式多样;可以运行于独立的集群模式;也可以部署在Hadoop上,利用YARN进行资源调度,利用HDFS进行存储;还可以托管在云环境中,
Spark 提供了多种数据类型,比MapReduce更灵活。
基于内存计算
采用的是有向无环图DAG的方式
Hadoop 基于磁盘的大数据计算框架,MapReduce采用的是迭代计算
2 生态系统
Spark是一个生态系统,有多个组件,满足企业不同的应用需求。
复杂的批量处理,即对数据进行处理,给出一个结果,时间可以在数几小时
MapReduce
基于历史数据的交互式查询,计算人员输入一条语句,计算机很快返回结果,数几秒到几分钟可以接受
Impala
基于实时数据流的数据处理,一般需要即使给出结果
Storm
依据上述分析,不同场景,应用不同的框架(即不同厂家开发的产品),输入输出数据无法做到无缝共享,通常需要进行数据格式的转换。
不同的软件需要不同的维护团队,
比较难以对同一集群中的各个系统及进行统一的资源协调与分配。
故Spark的设计理念
遵循“一个软件栈满足不同应用场景”的理念
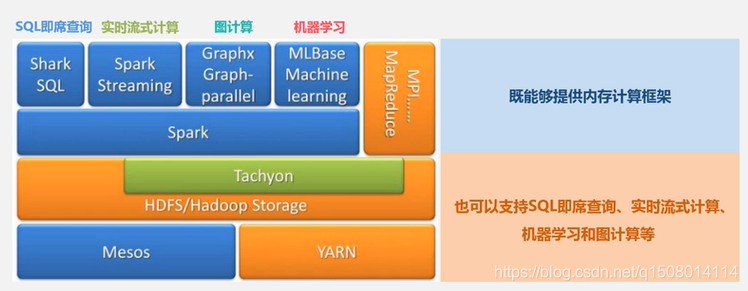
Spark可以部署在YARN上,因为YARN是比较主流的资源调度框架

支持内存计算的Spark Core;完成SQL查询分析的Spark SQL;可以完成流式计算的Spark Streaming;完成机器学习的组件Spark MLlib;完成图计算的软件GraphX;
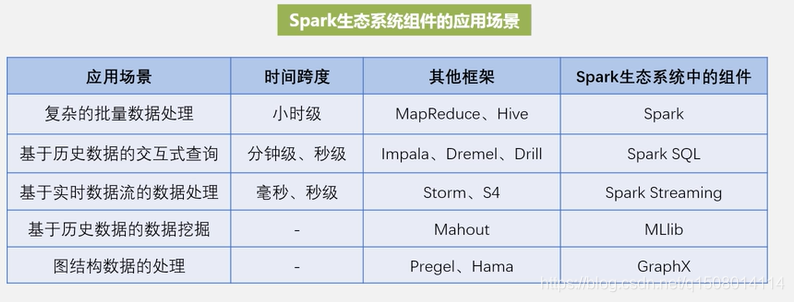
3 生态架构
十流计算
1 两大大数据类型
静态数据 批量计算
流数据:电商平台数据–实时计算
Hadoop 离线数据的批量处理
Spark Storming 批量数据实时处理
Storm 流数据实时处理
2
海量数据的实时捕获、海量数据数据的实时处理、实时的结果反馈
流计算系统
2.1 传统的数据处理流程
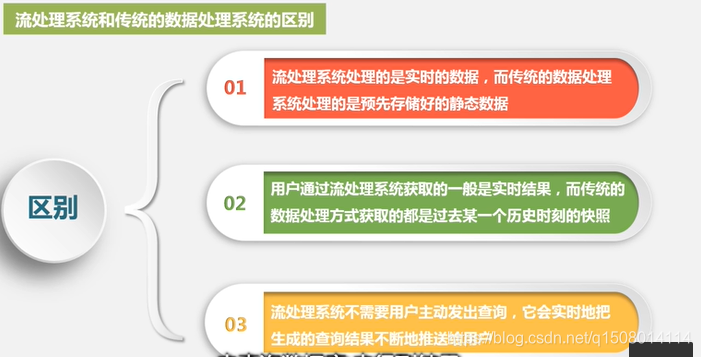
采集数据,把数据存储在数据库管理系统当中,用户通过查询操作和关系数据库管理系统进行交互,去获取结果。
即存储的数据不是实时数据,需要用户主动查询数据结果
2.2流计算的数据处理流程
数据实时采集—开源分布式日志采集系统,例如:Flume
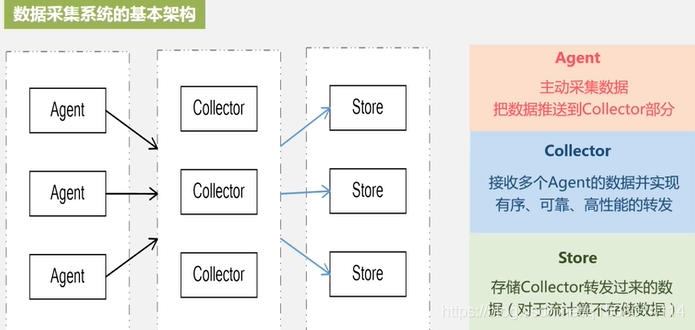
collector收集到数据后,把它转发给Store进行相关存储;对于流计算应用场景,collector收集到数据后,无需存储到具体的Store存储当中,可以直接扔给相关组件进行实时处理分析。
数据实时计算
对采集的数据进行实时的分析和计算并反馈实时结果
数据经流处理系统处理后的数据,可以流出给下一个环节继续处理,可以把相关结果处理完以后就丢弃掉,或者存储到相关的存储系统当中。
实时查询服务
3 流处理系统和传统的数据处理系统的区别
十一 图计算
图结构数据:社交网络数据、传染病传播途径、交通事故对路况影响


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









