




一、数据库介绍
1、定义:数据库是存放数据的电子仓库。
2、是以某种方式存储百万条,上亿条数据,提供多个用户访问共享。
3、每个数据有一个或多个api用于创建,访问,管理和复制所保存的数据。*api就是接口
如:例如注册:输入名字,手机等通过接口传输到数据库中保存
4、系统中很多动态数据都存储在数据库中,需要通过访问数据库才能显示
二、数据库的类型
1、关系型数据库
定义:数据库中表与表之间存在某种关系,数据存储在不同的表中
常见的关系型数据库:
(1)db2 IBM 公司
(2)oracle oracle 公司
(3)mysql oracle公司收购 (我们学习的mysql)
(4)sql server
特点:
a、安全
b、保持数据的一致性
c、实现对表与表进行复杂的数据查询
2、非关系型数据库
定义:通常数据是以对象的形式存储在数据库中
常见的非关系性数据库:
1、hbase (列模型)
2、redis (键值对存储)用的比较多
3、mongodb (文档类型)
特点:
a、效率高
b、容易扩展
c、使用更加灵活
=========================
三、mysql介绍
1、定义
mysql是关系型数据库管理系统,我们常说的xxx数据库就是指xx数据库管理系统。
2、来源
mysq数据库是有瑞典mysql db公司开发,目前属于oracle 公司,(甲骨文)
3、优势
在web应用方面(bs架构上),mysql是最好的关系型数据管理系统
4、特点:
a、体积小
b、开源,免费
c、使用c++编写
d、支持多系统
e、支持多引擎
f、msyql与其他工具组合可以搭建免费的网站系统
lamp=linux+apache+mysql+java ;
lnmp=linux+nginx+mysql+php
5、mysql的应用结构:
(1)单点数据库:使用于小规模应用(我们现在学的)
(2)复制:适用于中小规模的应用
(3)数据库集群,适合大规模的应用
比如:mgr集群,三主三从,一主三从;
6、数据库中术语:
(1)数据库
(2)数据表
(3)列
(4)行
(5)值
(6)字段名
(7)字符类型
(8)冗余
(9)主键
(10)外键
(11)视图
(12)索引
(13)单表
(14)多表
(15)存储过程
四、mysql安装
1、格式:rpm -qa|grep 服务名称
命令:rpm -qa|grep mysql 查询mysql包
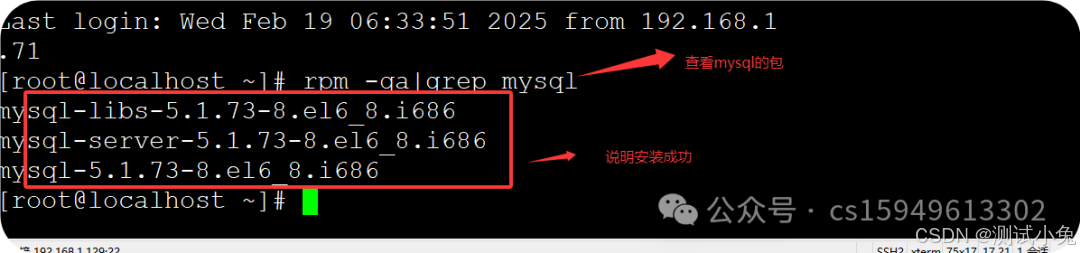
2、删除所有msyql包
删除的方法二种:
(1)yum remove mysql *
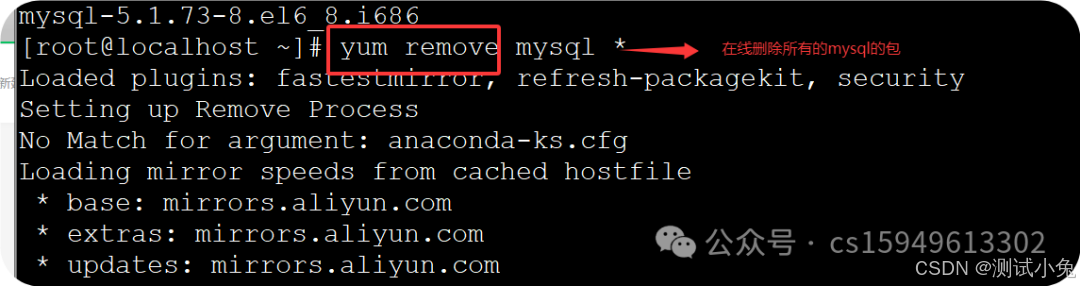
(2)rpm -e --nodeps 安装包
案例:rpm -e --nodeps mysql-libs-5.1.73-8.el6_8.i686
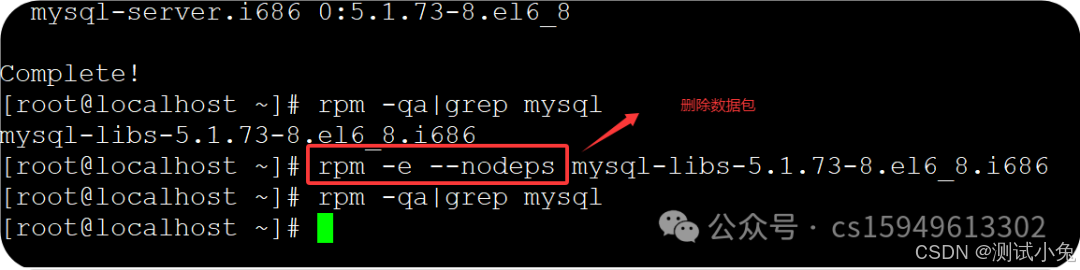
3、安装mysql
(1)yum install msyql 客户端
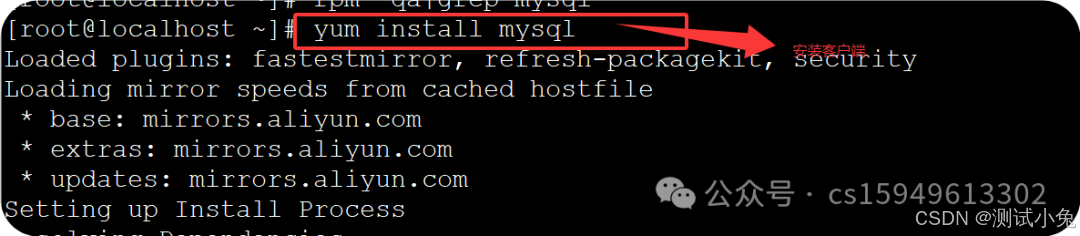
(2)yum install msyql-server服务端
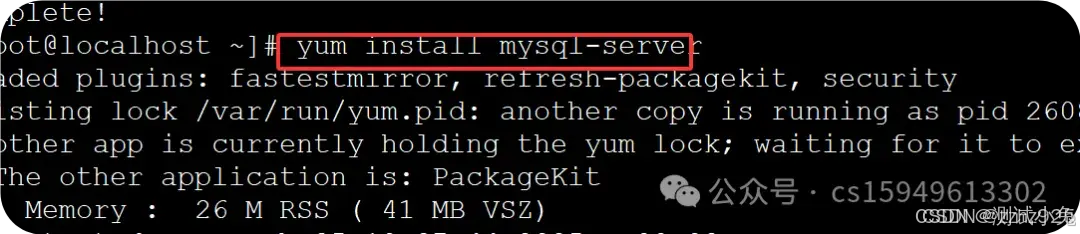
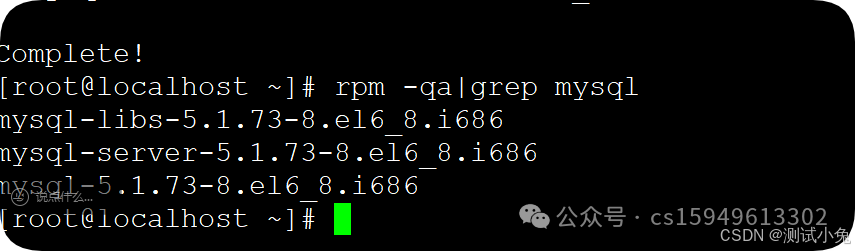
查询显示如下三个包,表示安装成功
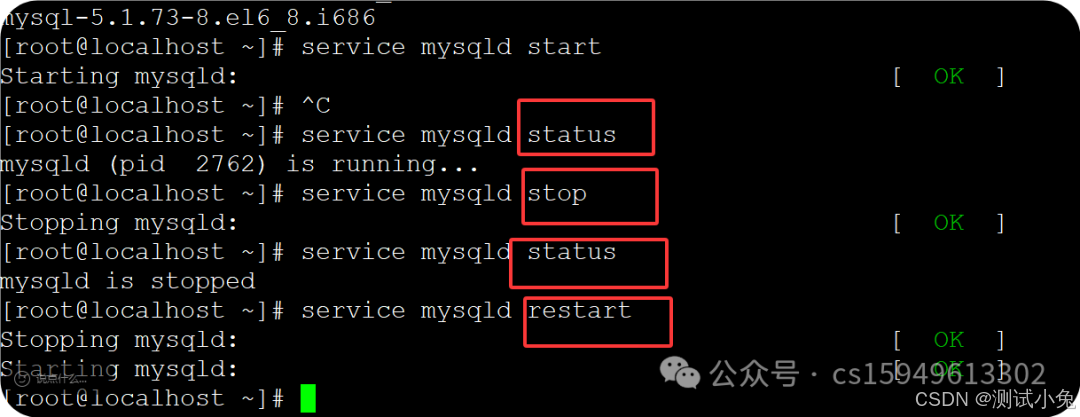
4、数据库启动
service mysqld start开启数据库
service mysqld stop 关闭书库
service mysqld restart 重启数据库
service mysqld status 查看数据库状态

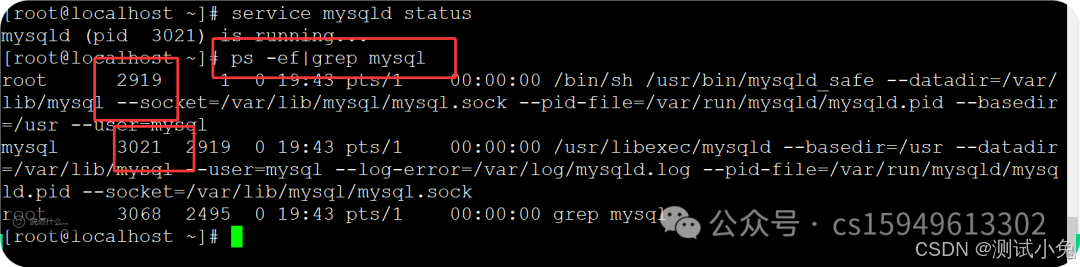
 查看数据库服务
查看数据库服务
ps -ef|grep 服务名称
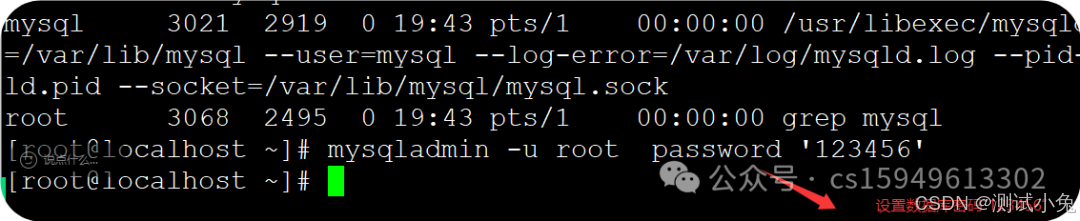
5、设置密码
mysqladmin -u 用户名 password 密码
案例:mysqladmin -u root password '123456'
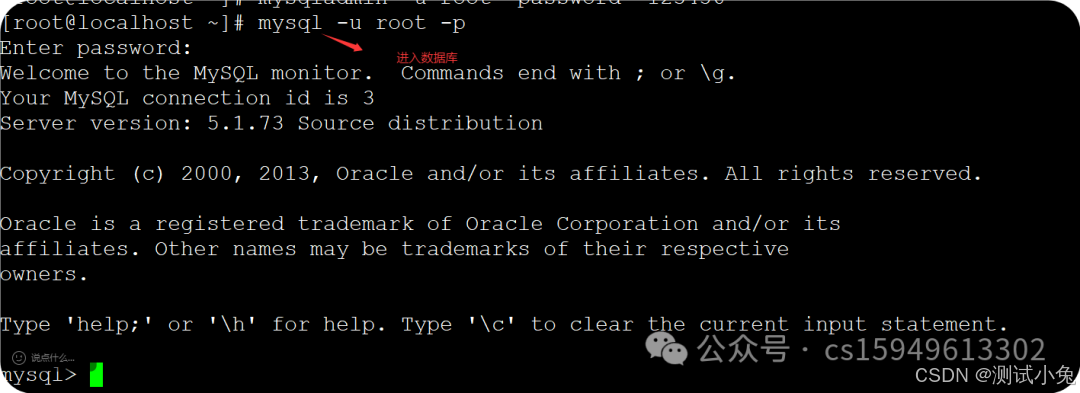
6、进入数据库
mysql -u root -p 敲回车 ,输入密码
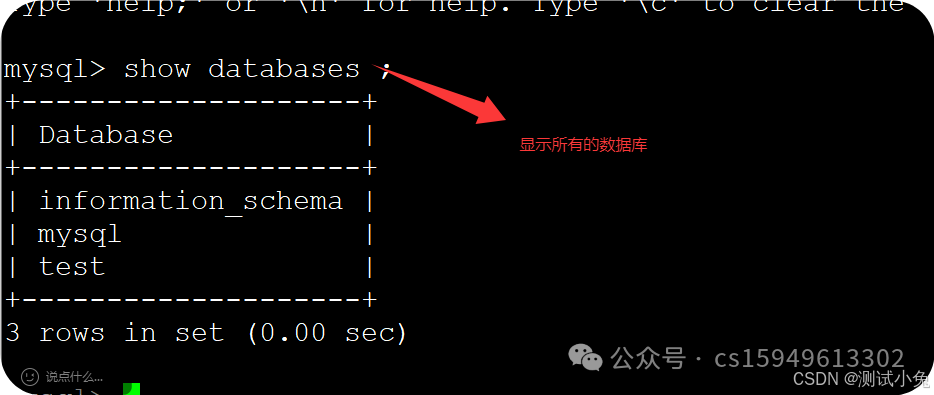
7、显示所有的数据库
show databases ;
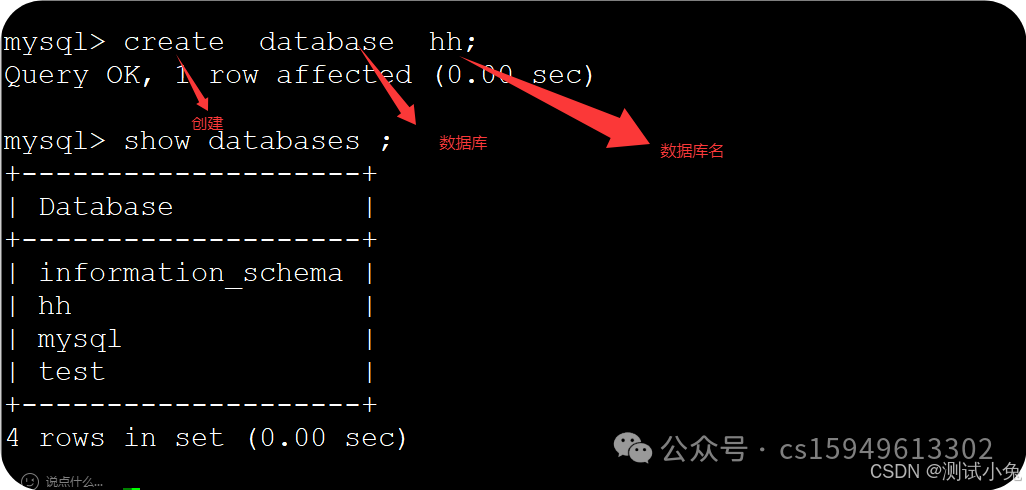
8、创建数据库
create database 库名;
9、use 库名
使用库
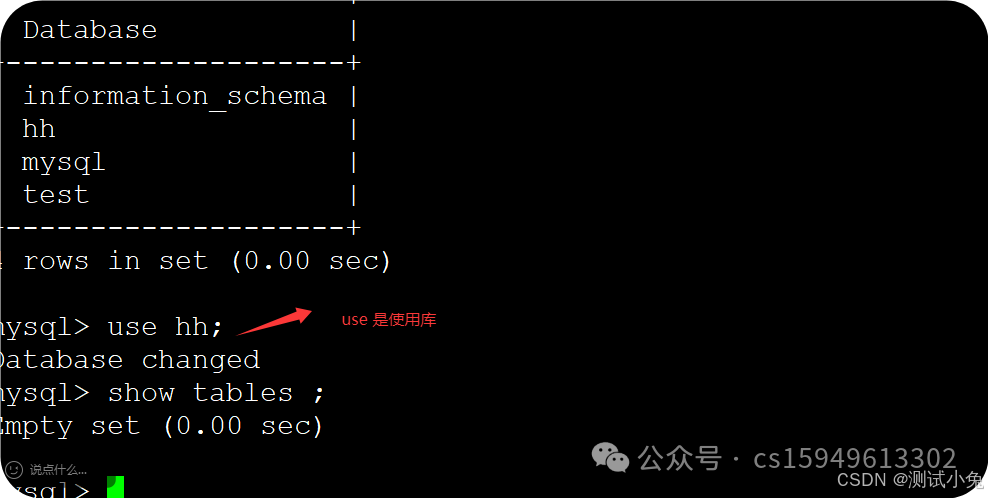
10、显示库中所有的表
show tables 显示所有的表

11、建表:
建表语句:create table aa(id int(10),name char(20));

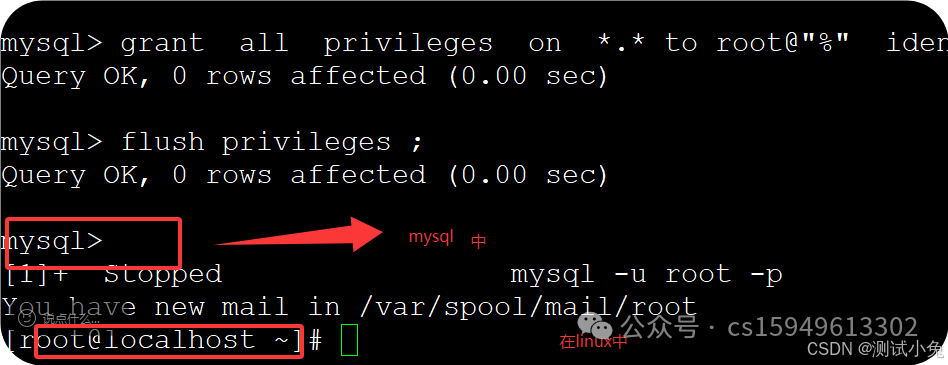
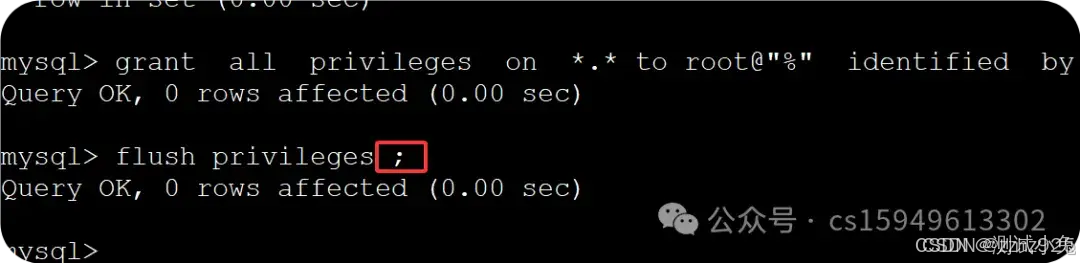
12、授权
grant all privileges on *.* to root@"%" identified by "123456";

刷新授权:
flush privileges ;

13、ctrl+z 退出mysql界面
13、注意点:命令后面都要借上分号(;)
五、navicat
1、下载navicat 包
![]()
2、解压
![]()
3、找到navicat.exe
4 .密钥
NAVH-WK6A-DMVK-DKW3
5、查看ip地址
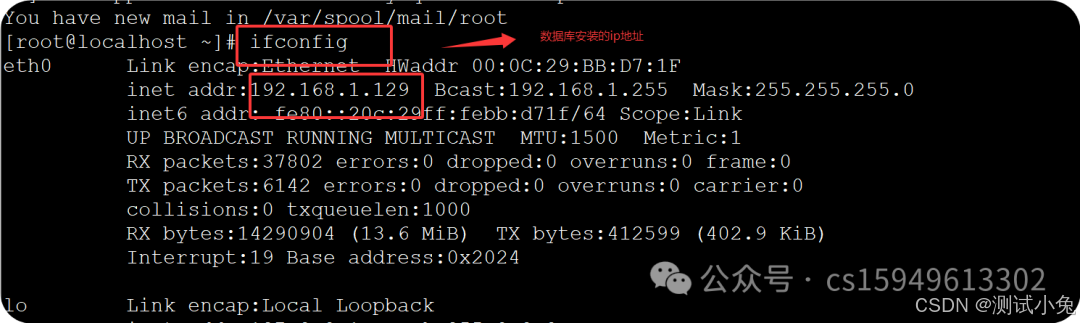
6、关闭防火墙
ervice iptables stop

7、连接配置编写
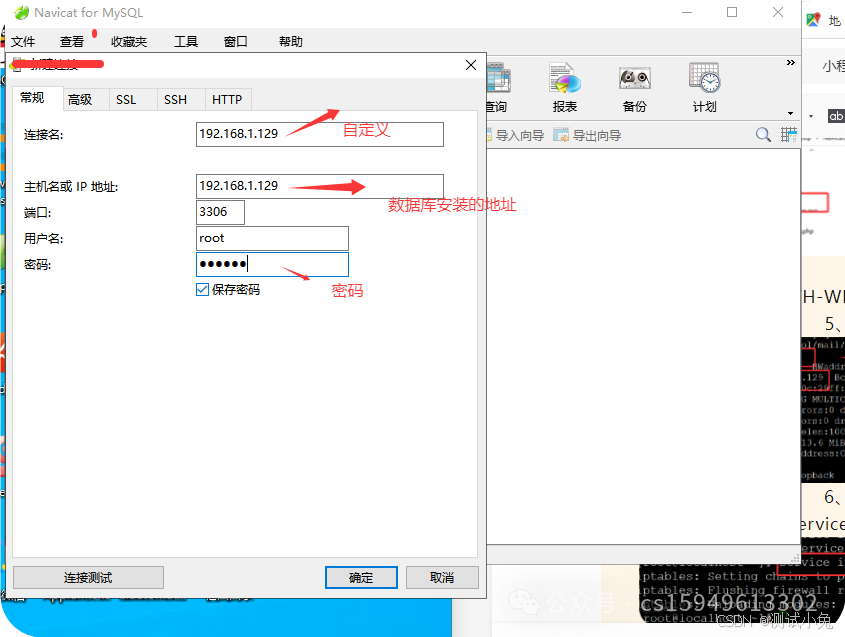
8、点击确定连接,显示如下
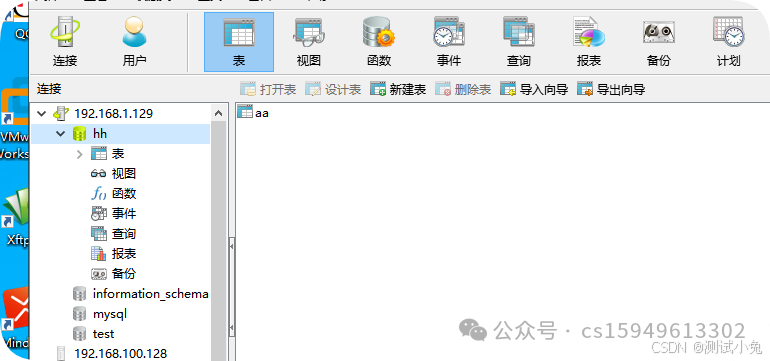
以上表示连接成功
9、打开查询中,新建查询
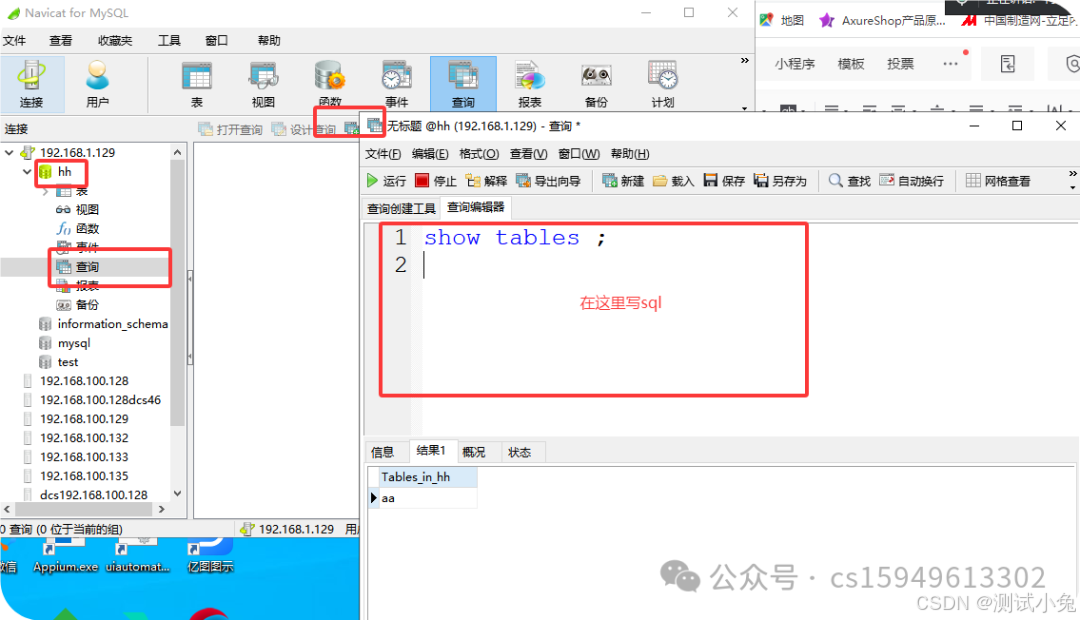
10、解决问题:
注意点:如果连接不上
1、关闭防火墙 service iptables stop (在linux中操作)
2、 开启数据库 service mysqld start (在linux中操作)
3、授权(在mysql中操作)
grant all privileges on *.* to root@'%' identified by "123456"
4、授权以后要刷新
flush privileges (在mysql中操作)
5、检查连接数据库的参数的正确性如:ip地址,密码,用户名等
6、密码设置错误:
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YSE)
(1)也是修改密码
解决办法
第一步:关闭mysql
第二步:mysqld_safe --user=mysql --skip-grant-tables --skip-networking &
mysql -u root mysql
第三步: UPDATE user SET Password=PASSWORD('123456') where USER='root';
第四步: FLUSH PRIVILEGES;
(在linux中操作)
六、mysql数据类型
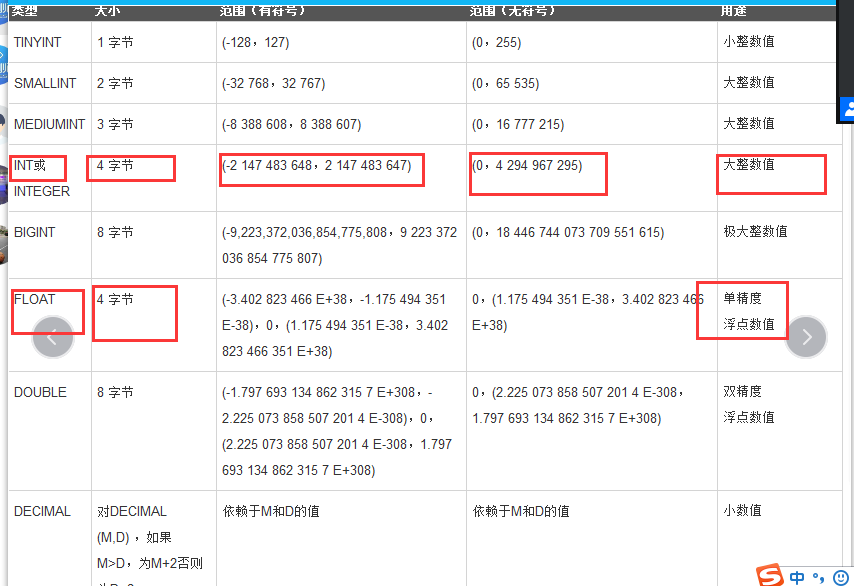
1、数值类型
int 大整数类型 4个字节
float 4个字节
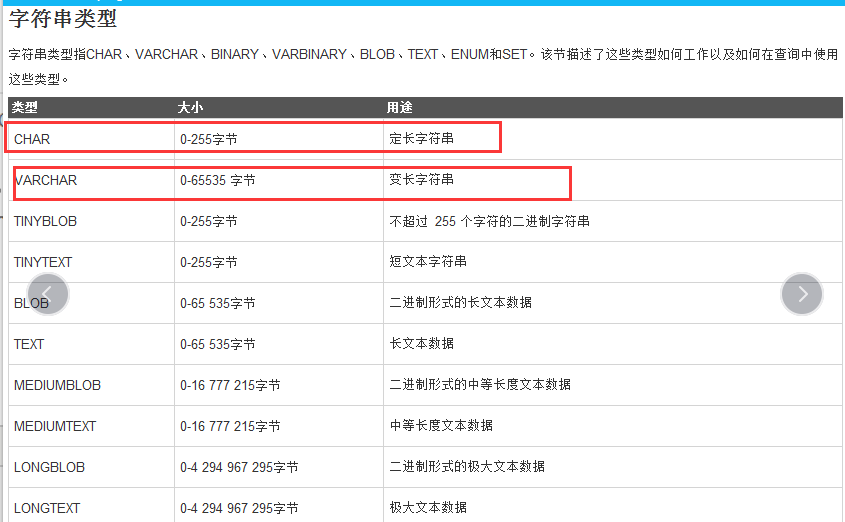
2、字符类型
char 定长字符串
varchar 变长字符串
3、时间类型
data 日期值 年月日
time 时分秒
year 年
datataim 年月日时分秒

七、mysql语句
1.基础语句
(1)进入数据库的方法
1、mysql -u root -p 进入数据库
2、通过navicat连接数据库
(2)建表语句
格式:create TABLE 表名(字段名1 字符类型(字符长度1),字段名1 字符类型(字符长度2));
案例1:create TABLE a1(id int(10),name varchar(10));
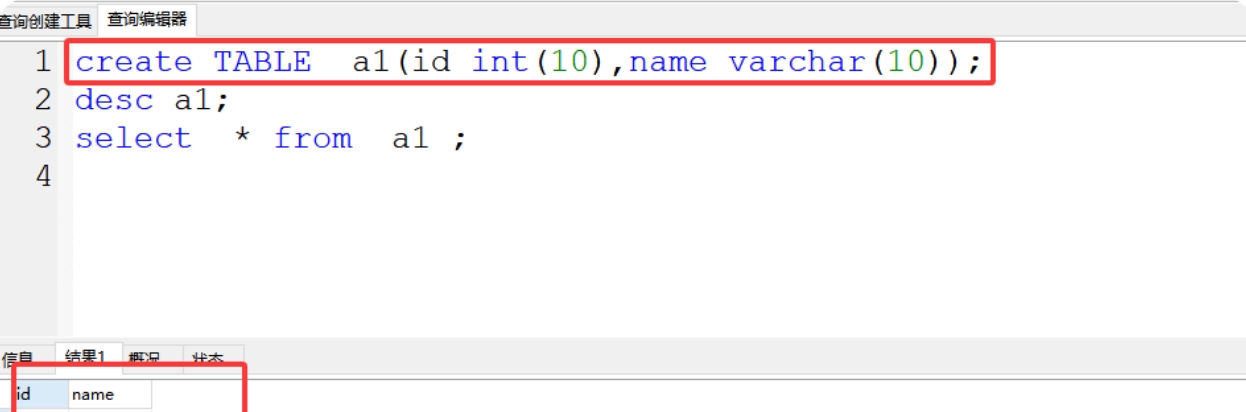
(3)desc 查看表结构
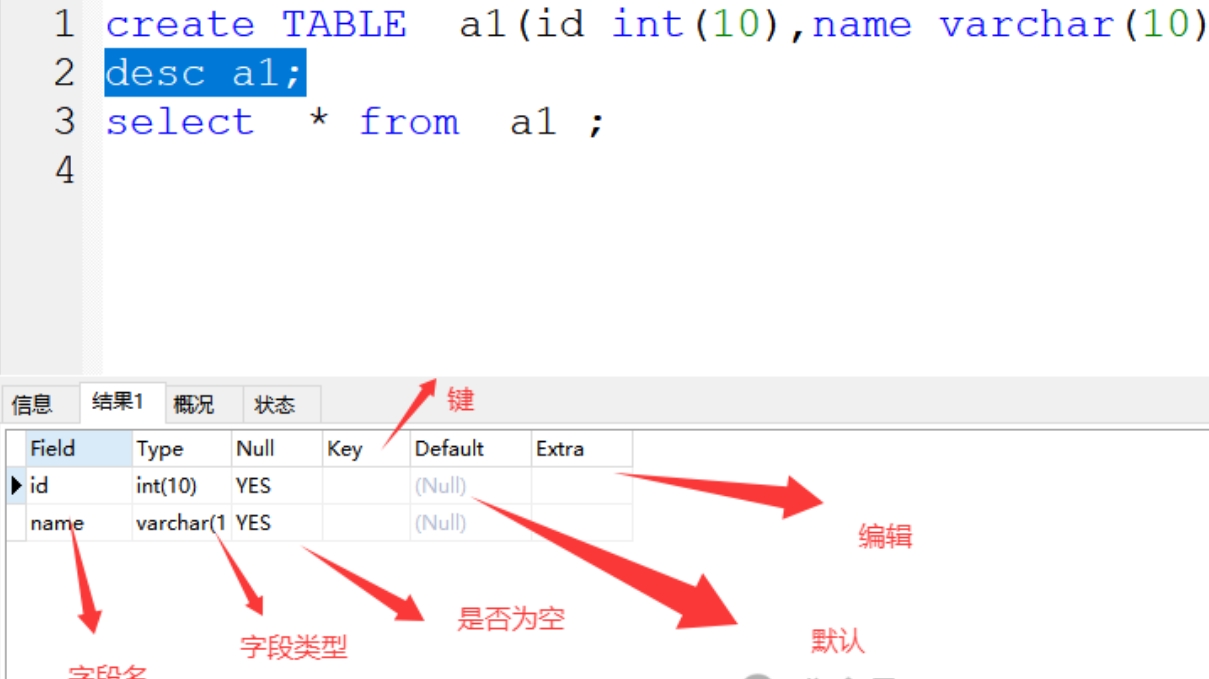
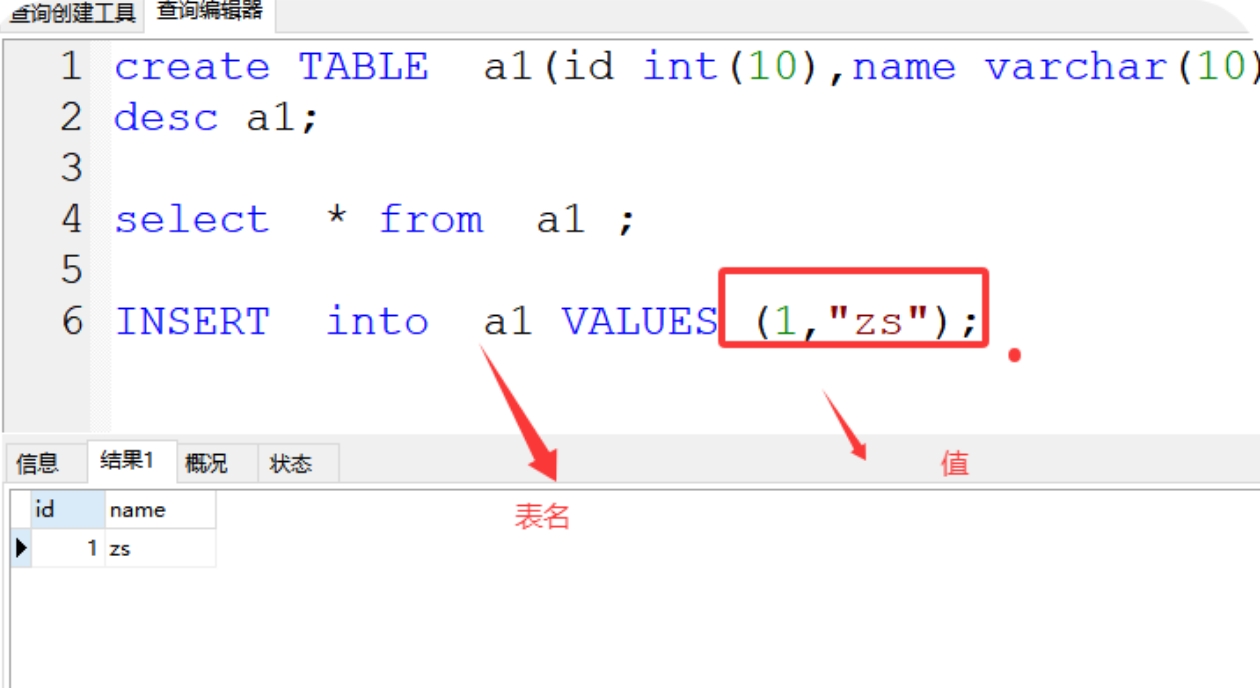
(4)insert into 插入数据
1、插入全部字段:INSERT into a1 VALUES (1,"zs");
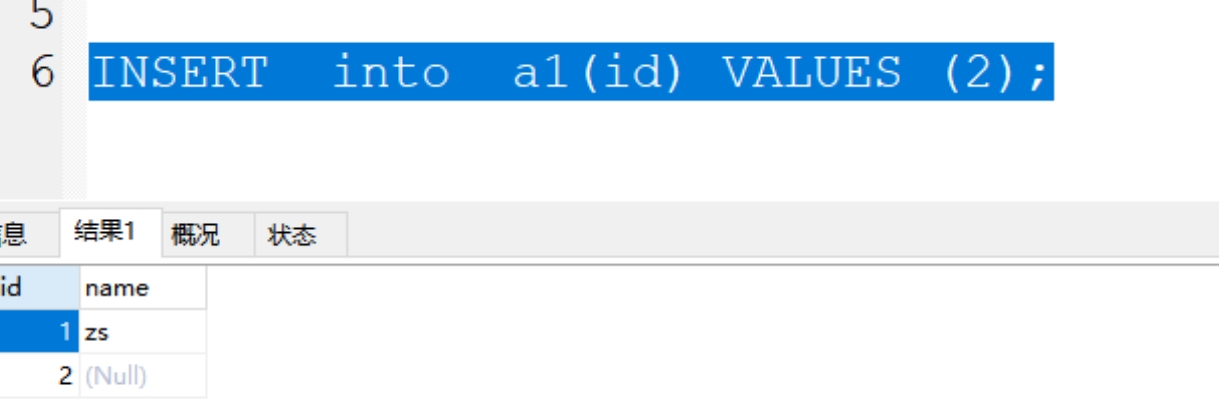
2、插入部分字段值
格式”:INSERT into 表名(字段名) VALUES (值);
案例:INSERT into a1(id) VALUES (2);
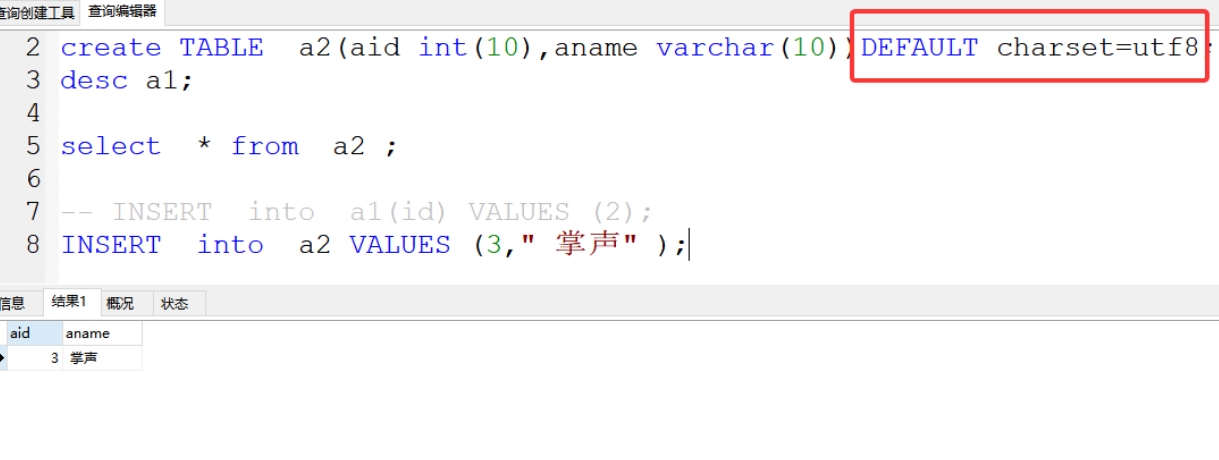
3、解决插入中文出现?的方式:
解决方法:DEFAULT charset=utf8;
(5)删除表
格式:drop table 表名;
案例:drop table a2;

(6)删除表内数据
格式:DELETE FROM a2;
(7)约束
定义:约束是对表中字段进行限制,保证表中数据的而正确性和唯一性
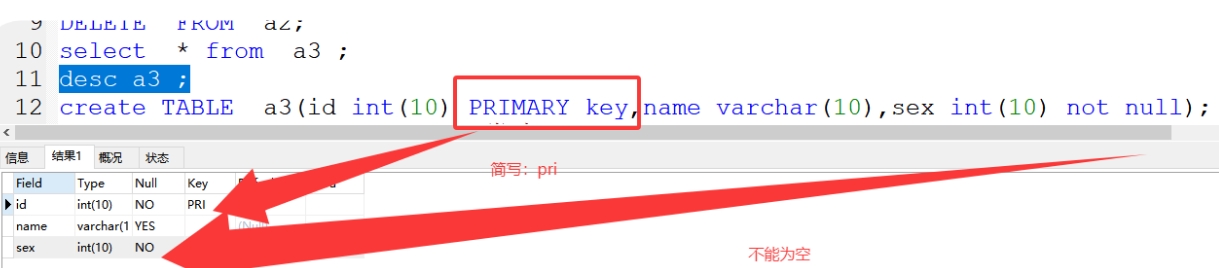
1、PRIMARY key 主键;简写:pri
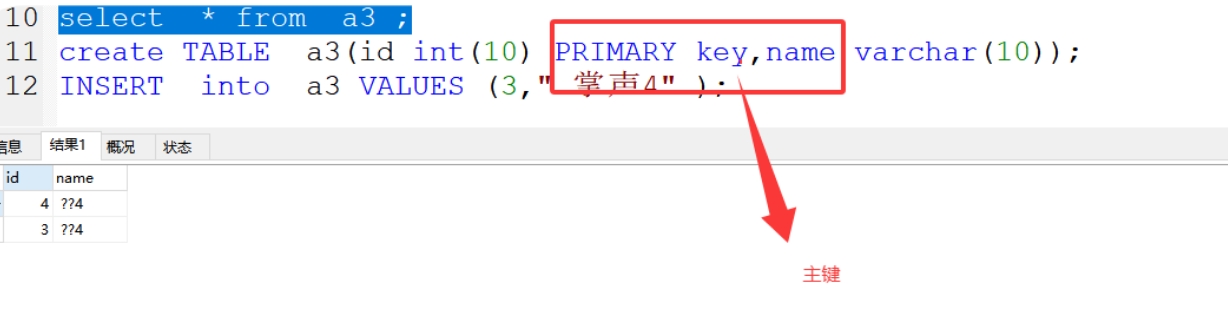
2、not null 非空约束
非空,唯一,用于唯一标识记录,类似身体证
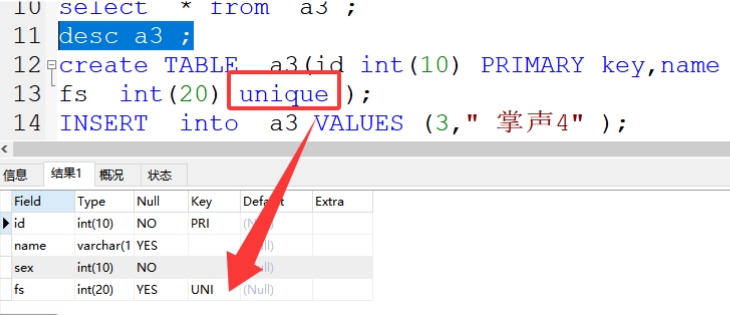
3、unique 唯一索引
唯一、能为空,一个表可以有多个唯一索引
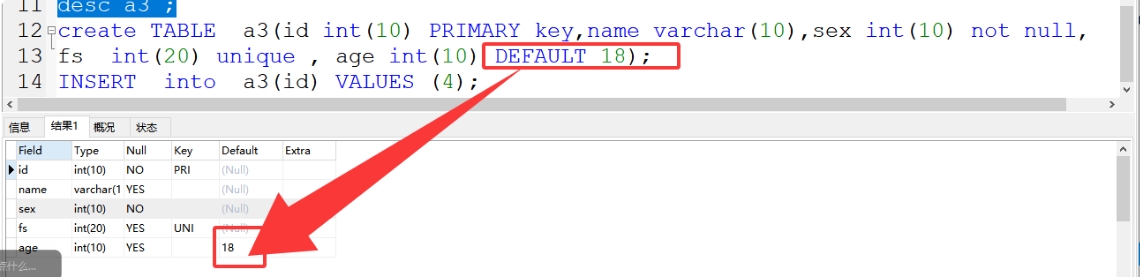
4、default 默认值
5、auto_increnment 自增长约束(一般和主键同时使用
作用:在整数类型,字段值默认从1开始自增
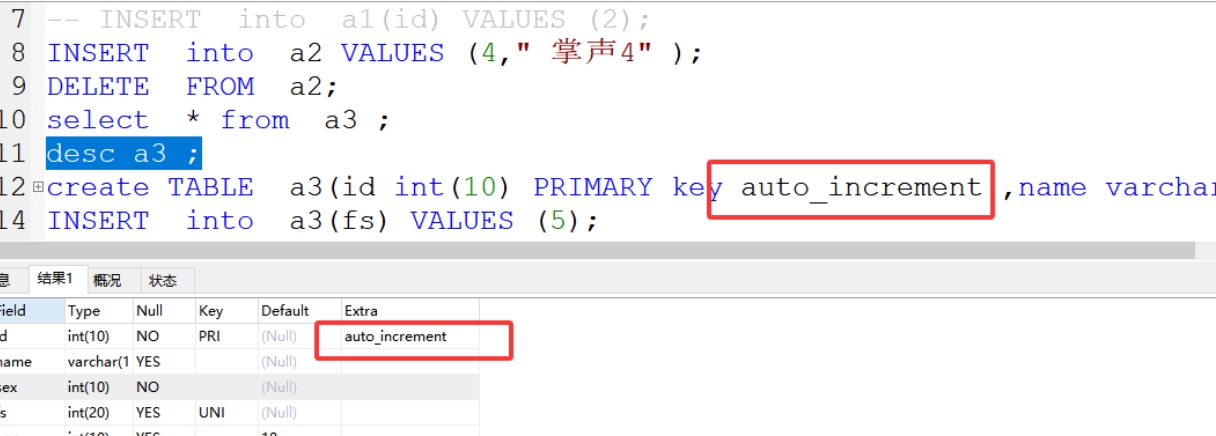
2.单表查询
1、新建表
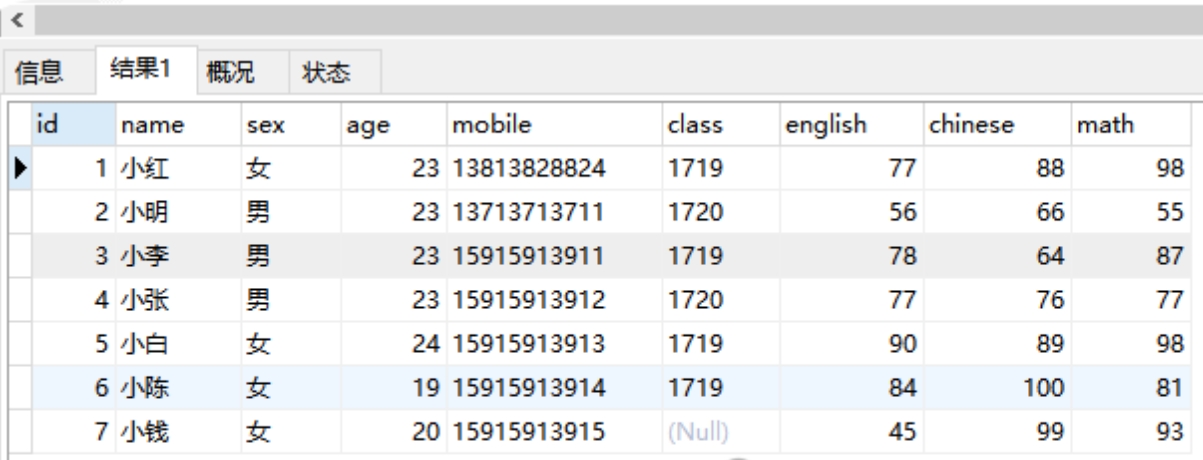
2、建表语句
create table student( id int primary key , name char(20), sex char(10), age int(3), mobile char(20), class char(10), english int(10), chinese int(10), math int(10) )engine=innodb default charset=utf8;
insert into student values (1,'小红','女',23,'13813828824','1719',77,88,98), (2,'小明','男',23,'13713713711','1720',56,66,55), (3,'小李','男',23,'15915913911','1719',78,64,87), (4,'小张','男',23,'15915913912','1720',77,76,77), (5,'小白','女',24,'15915913913','1719',90,89,98), (6,'小陈','女',19,'15915913914','1719',84,100,81), (7,'小钱','女',20,'15915913915',null,45,99,93);
3、操作语句(表结构)
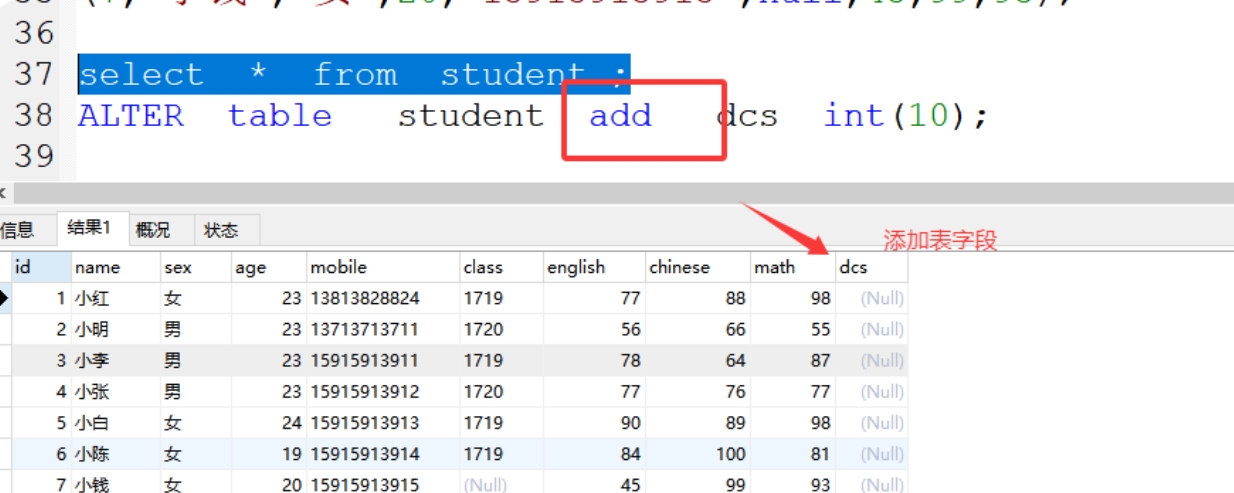
(1)add 添加字段
格式:alter table 表名 add 字段名 字符类型(字符长度);
案例:alter table student add dcs int(10);
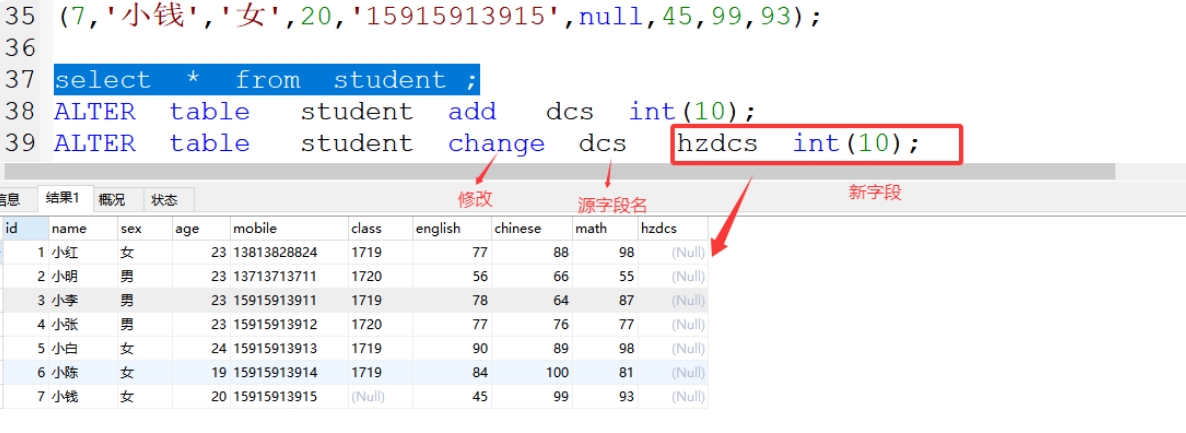
(2)change 修改字段
格式:alter table 表名 change 源字段名 新字段名 字符类型(字符长度);
案例:alter table student change dcs hzdcs int(10);
(3)drop 删除字段
格式:alter table 表名 drop 字段名;
案例:ALTER table student drop hzdcs ;
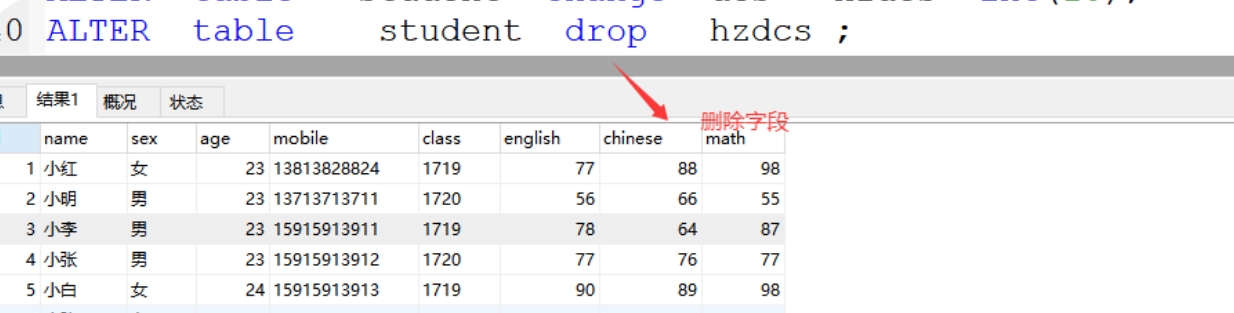
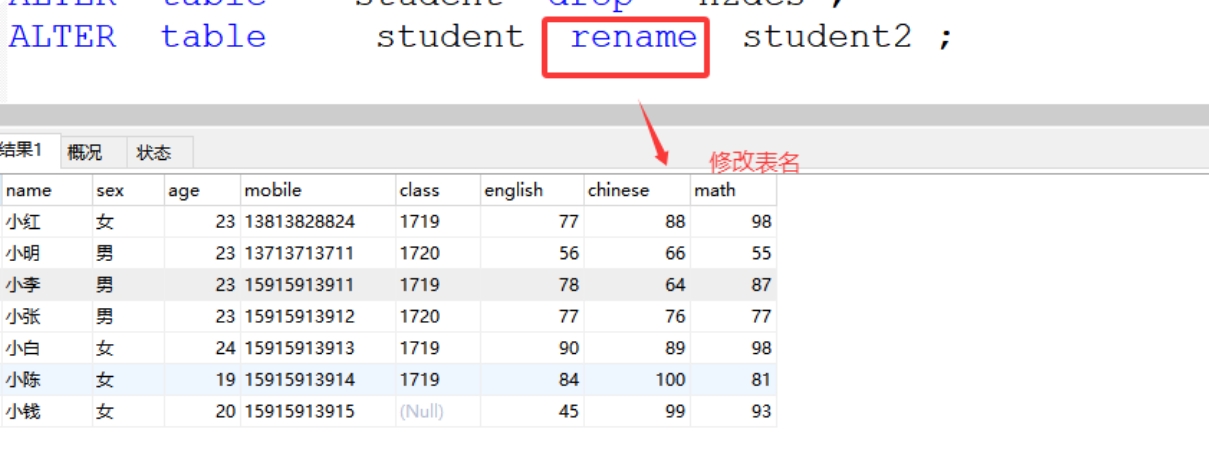
(4)rename 修改表名
格式:ALTER table 表名 rename 新表名 ;
案例:ALTER table student rename student2 ;
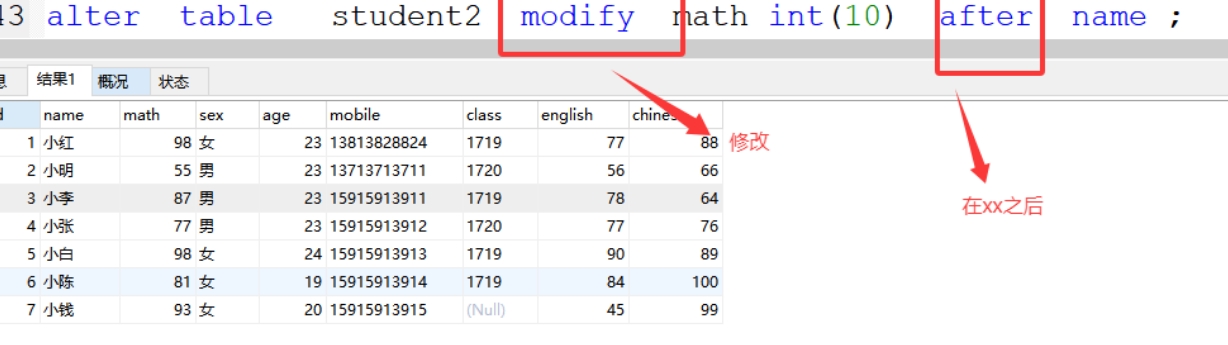
(5)modify after 字段的调换
格式:alter table 表名 modify 源字段名 字符类型(字符长度) after 表中字段名;
案例:alter table student2 modify math int(10) after name ;
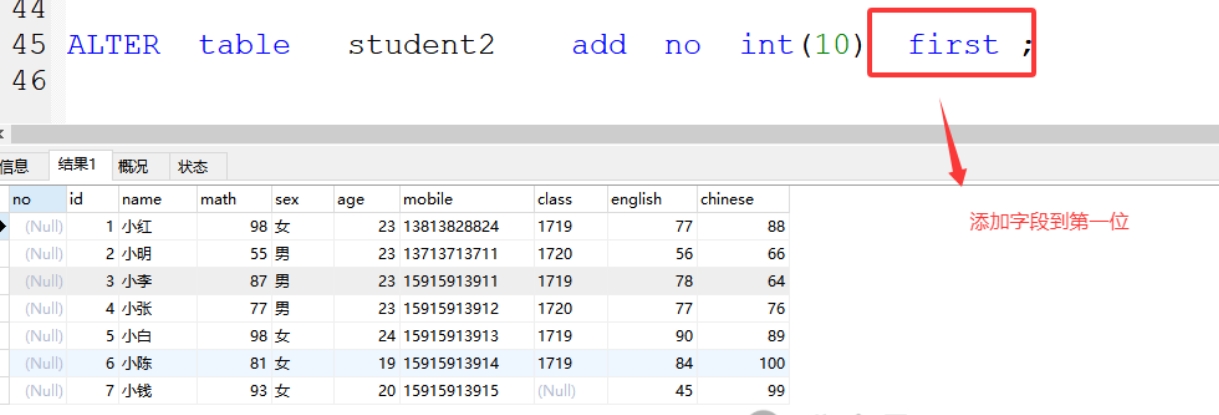
(6)first 添加字段到第一位
格式:ALTER table 表名 add 新字段名 字符类型(字符长度) first ;
案例:ALTER table student2 add no int(10) first ;
(7)select 查询所有数据
格式:select * from 表名;
案例:select * from student2;

(8)查询部分数据
格式:select 字段1,字段2 from 表名;
案例:select name,math from student2 ;
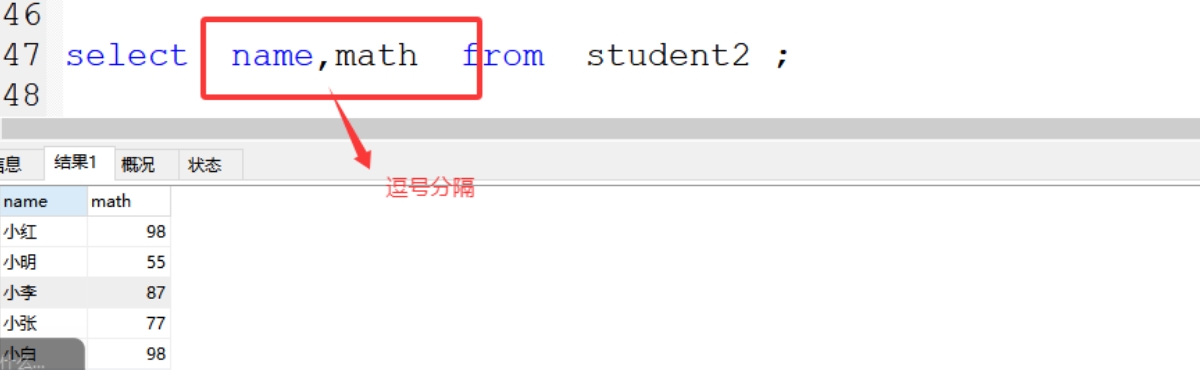
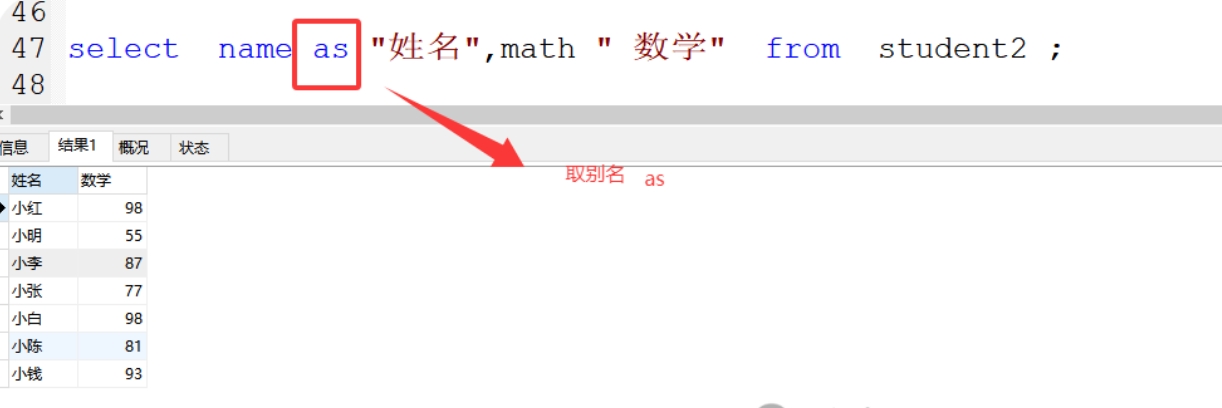
(9)查询字段可以用as取别名
格式:select 字段1 as "别名名称",字段2 " 别名名称2" from 表名 ;
(备注:as也可以省略不写)
案例:select name as "姓名",math " 数学" from student2 ;
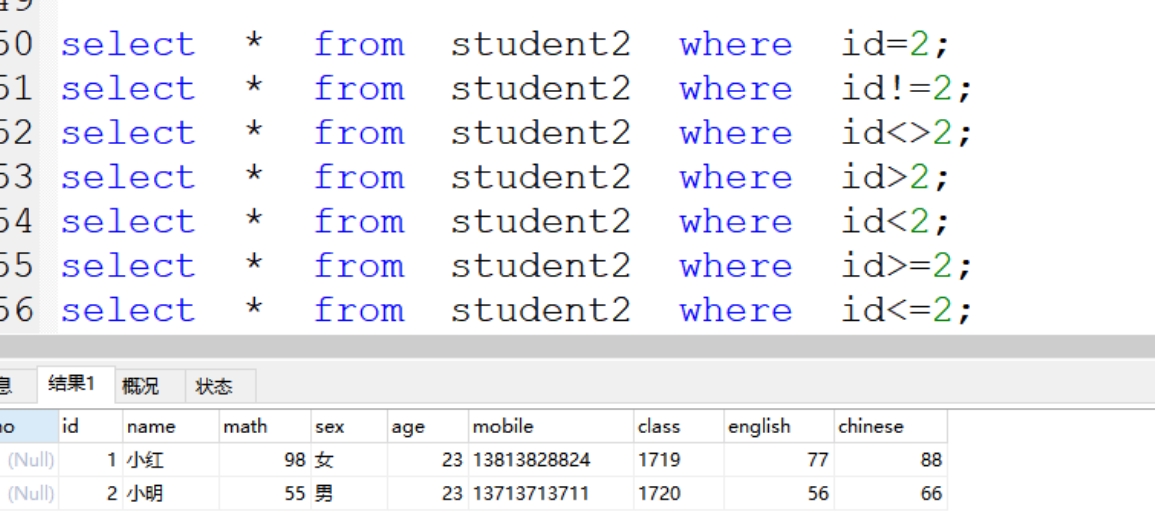
(10)where接指定条件查询内容
(1)比较运算符:>,<,=,!=,<>,>=,<=
*案例:
1)=等于:select * from student2 where id=2;
2)!=不等于:select * from student2 where id!=2;
3)<>不等于:select * from student2 where id<>2;
4)大于:select * from student2 where id>2;
5)小于:select * from student2 where id<2;
6)大于等于:select * from student2 where id>=2;
7)小于等于:select * from student2 where id<=2;
(2)and 同时满足
案例:select * from student2 where id>3 and math>90;
(3)or 满足其中一个条件就能查询出数据
案例:select * from student2 where id>6 or math>97;
(4)beteen ... and ... 在什么范围之间
案例:select * from student2 where id BETWEEN 2 and 5;
(5)in 在一组数据中匹配
案例:select * from student2 where id in (2,8,6)
(6)not in 在一组数据中匹配
案例:select * from student2 where id not in (2,8,6)
(7)is null 为空
案例:select * from student2 where class is null;
(8)is not null 不为空
案例:select * from student2 where class is not null;
(9)like 模糊查询
%:通配符
_:代表一个字符
1)查找8开头的数据:select * from student where english like "8%";
2)查找包含8的数据:select * from student2 where math like "%8%";
3)查找8结尾的数据:select * from student2 where math like "%8";
4)查看指定字符的数值:select * from student where english like "8___";
(11)order by排序
(1)order by
a.升序:asc 可以省略不写(从小到大)
b.降序:desc(从大到小)
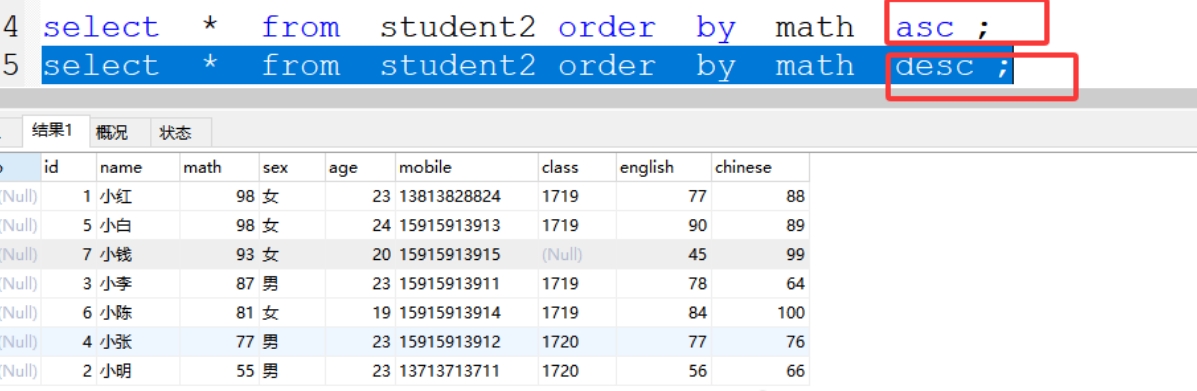
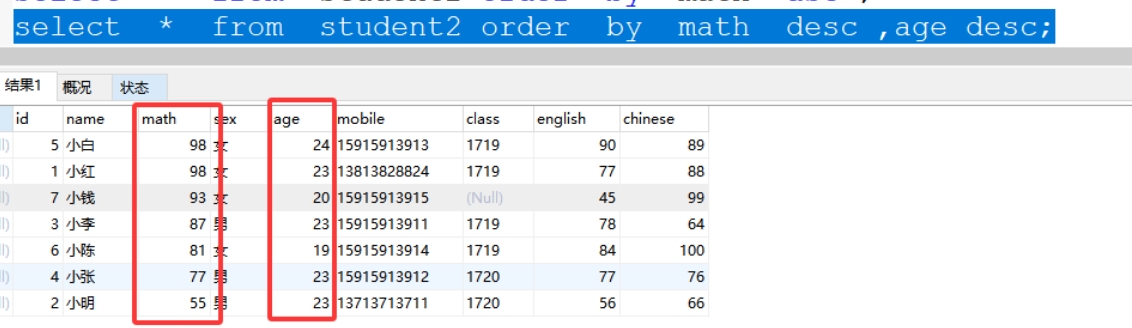
(2)二次排序
select * from student2 order by 字段1 desc ,字段2 desc;
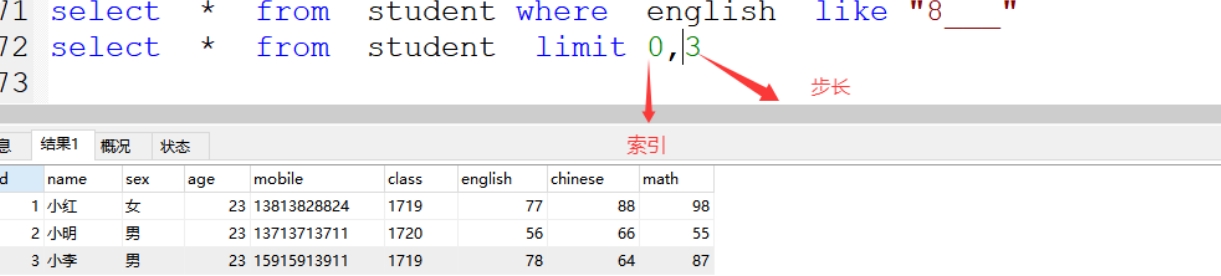
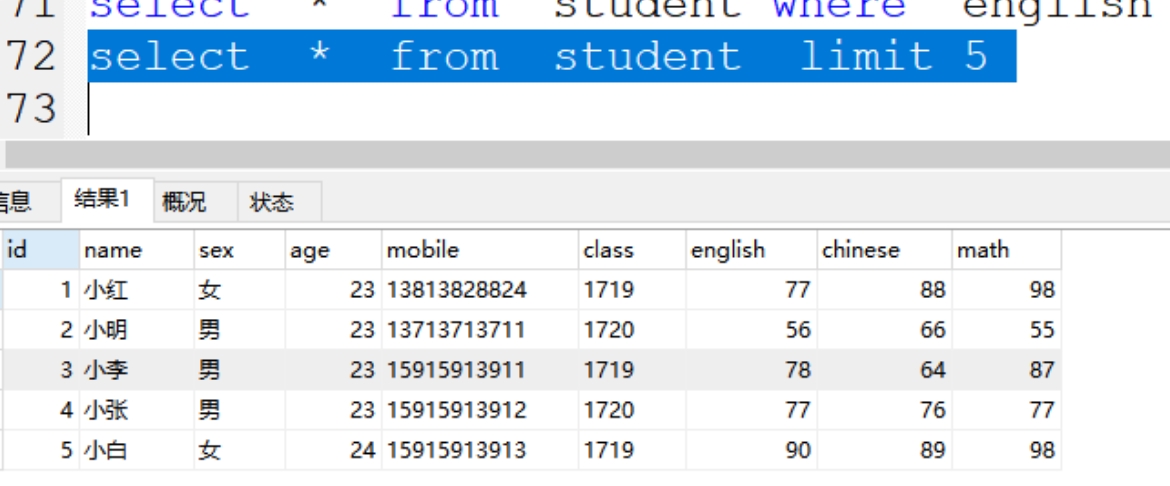
(12)limit 查询指定的数据,限制
根据索引来取值,从0开始,一个表的第一行就是哦,第二数字,行数(3行)
案例:select * from student limit 0,3
(13)聚合函数
(1)max 最小值:select max(math) from student
(2)min 最大值:select min(math) from student
(3)sum 总数:select sum(math) from student
(4)avg平均数:select avg(math) from student
(5)count 统计个数:select count(math) from student
(6)DISTINCT 去重:select DISTINCT(math) from student
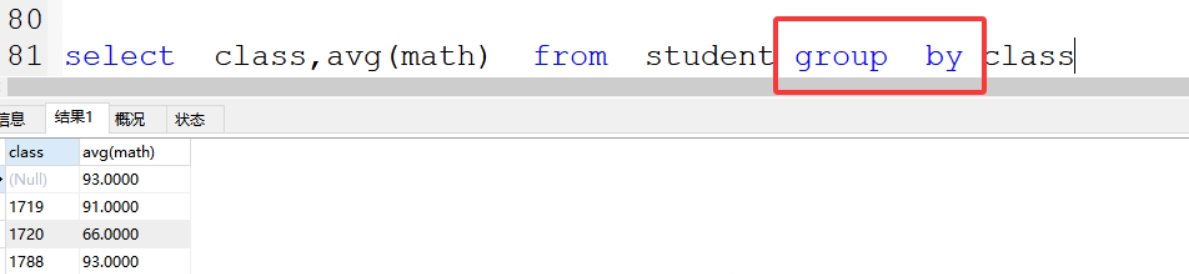
(14)group by 分组
*分组后的函数,智能分组的字段,一起显示,其他字段显示就是默认取第一行*
案例1:分组求出每个班级的平均数
select class,avg(math) from student group by class
having+条件
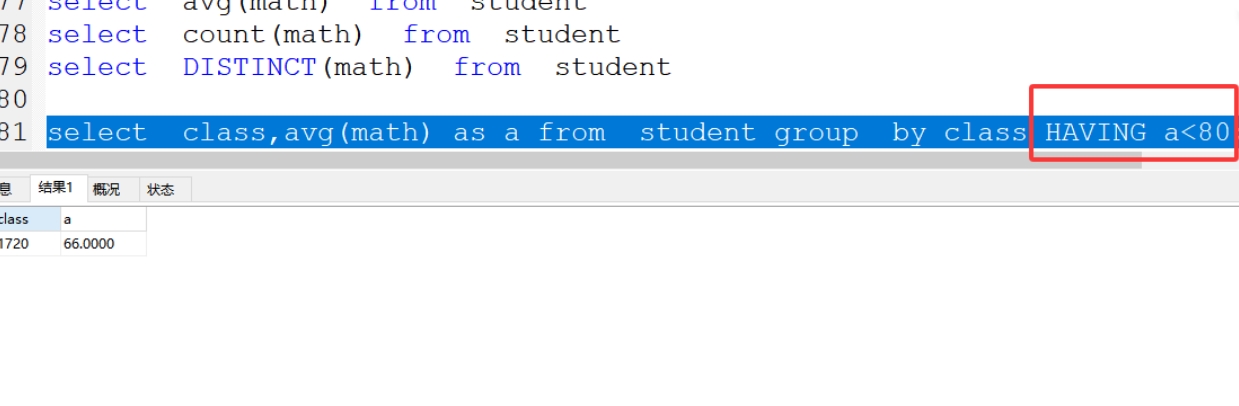
案例:分组求出每个班级的平均数小于80分
select class,avg(math) as a from student group by class HAVING a<80;
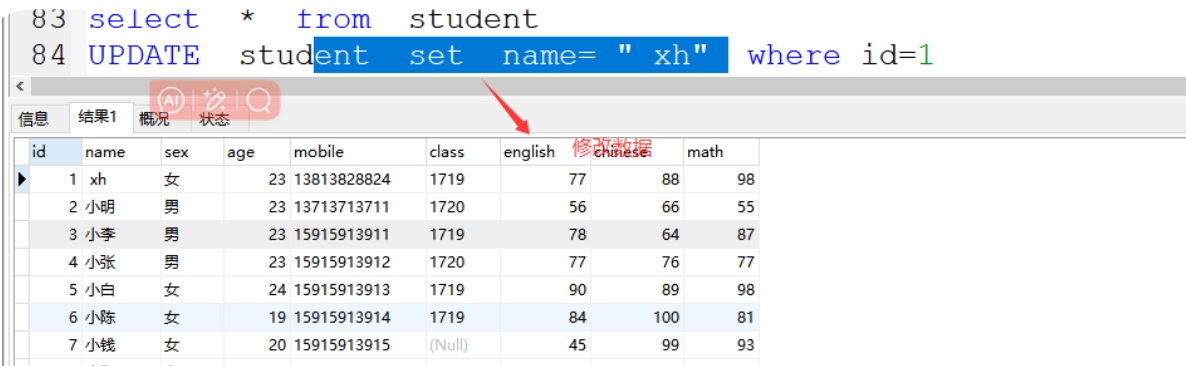
(15)update...set...更新数据/修改数据
案例:UPDATE student set name= " xh" where id=1
(16)删除数据
(1)delete
案例1:delete from student
案例2:DELETE from student where id=1
(2)drop
案例:drop table student
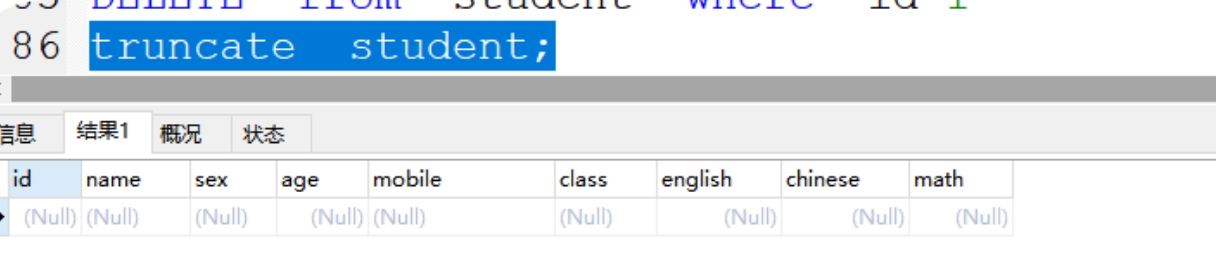
(3)truncate
案例:truncate student
(17)-快捷方式-
注释:ctrl+/
取消注释:shift+ctrl+/
单行注释:#
(18)-备份-
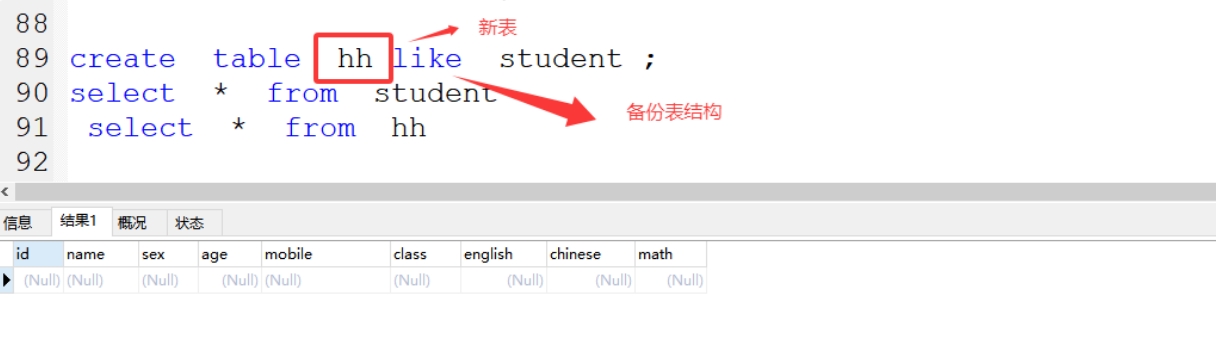
(1)在数据库中备份
1、备份表结构:create table 新表 like 旧表;
2、备份表数据:
insert into 新表 select * from 旧表;
insert into 新表(字段1,字段2) selcet 字段1,字段2 from 旧表;
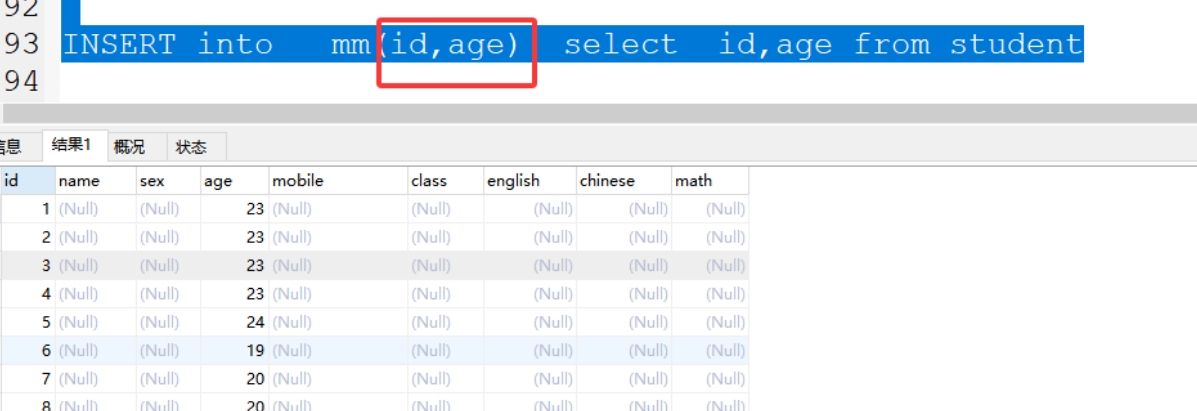
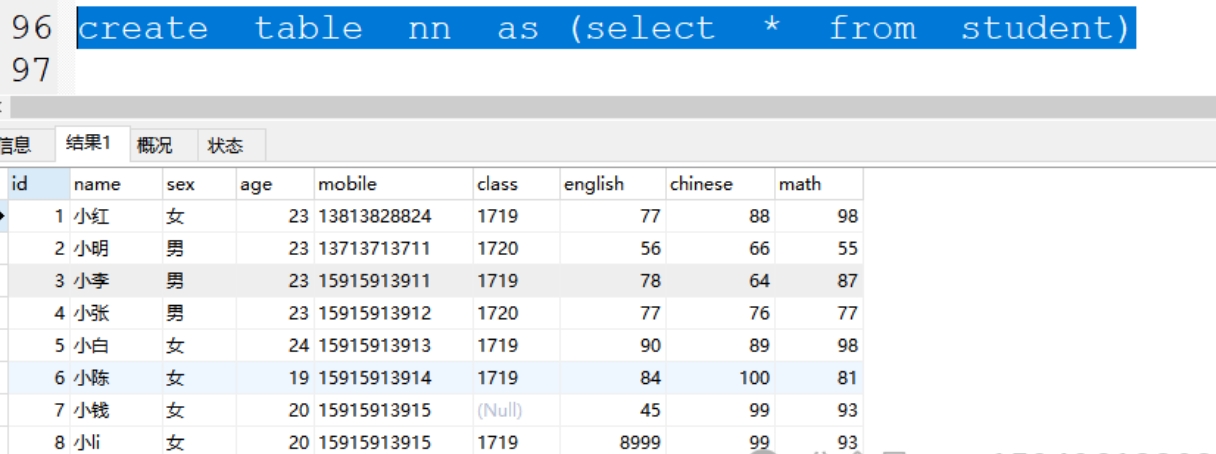
3、备份表结构和表数据:create table 新表 as( select * from 旧表);
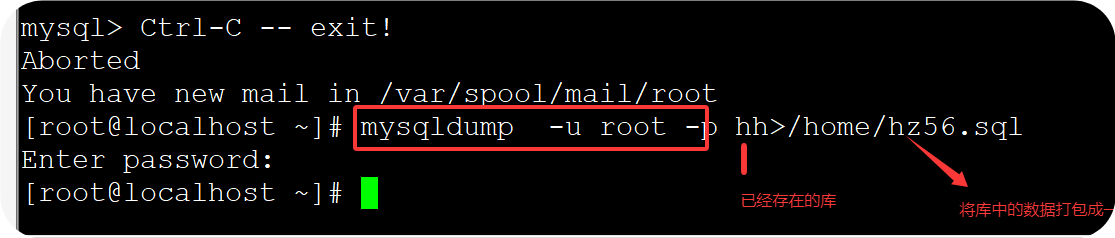
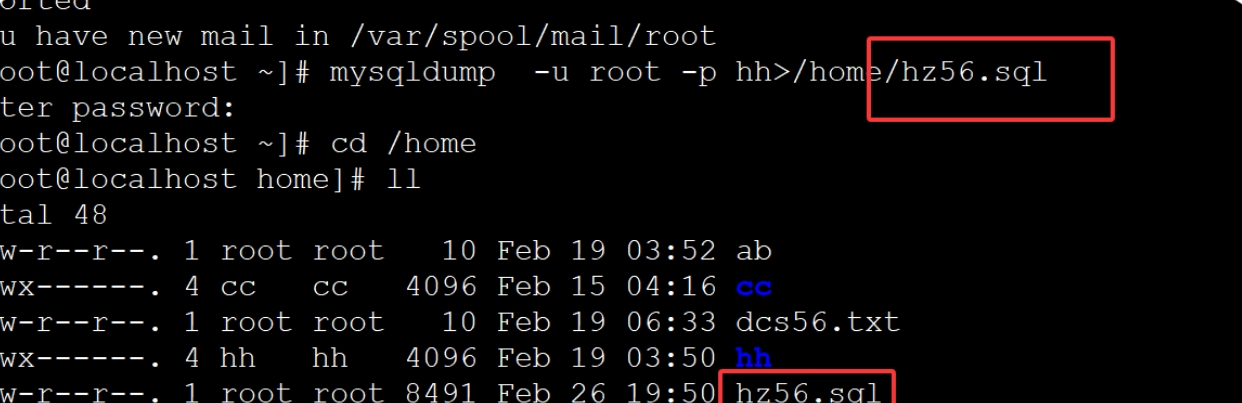
(2)自Linux中备份
1、备份数据
语句:mysqldump -u root -p hh>/home/hz56.sql
2、还原数据
a.新建数据库
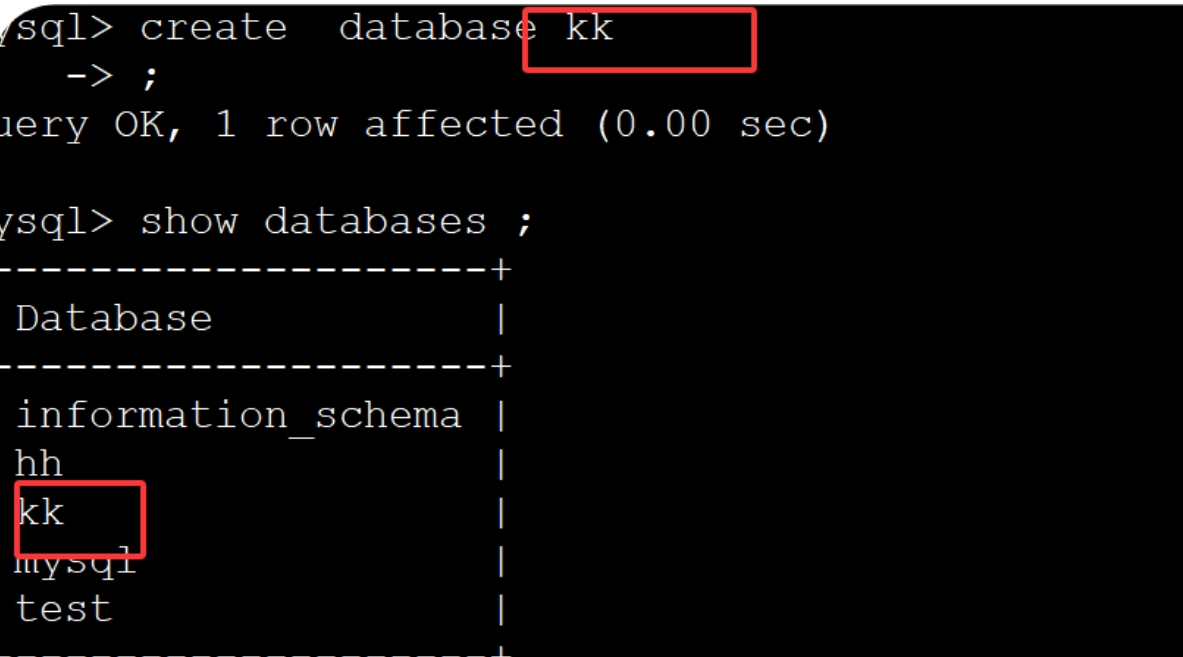
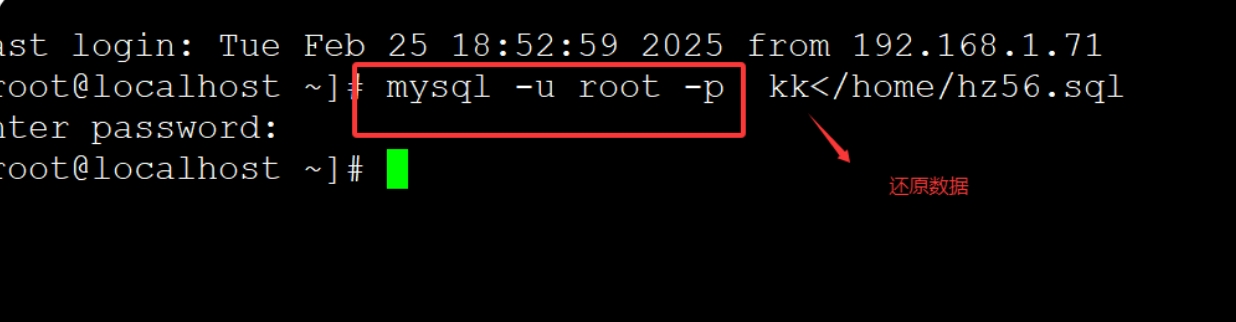
b.还原数据库
语句:mysql -u root -p kk</home/hz56.sql
3.多表查询
建表
员工表:sid:员工编号、name:姓名、age:年龄
woektime_start 入职时间,incoming工资
dept2 部门编号
部门表:dept1 部门编号,dept_name 部门名称
定义:
(1)2个表或者更多的表中查询我们要的数据
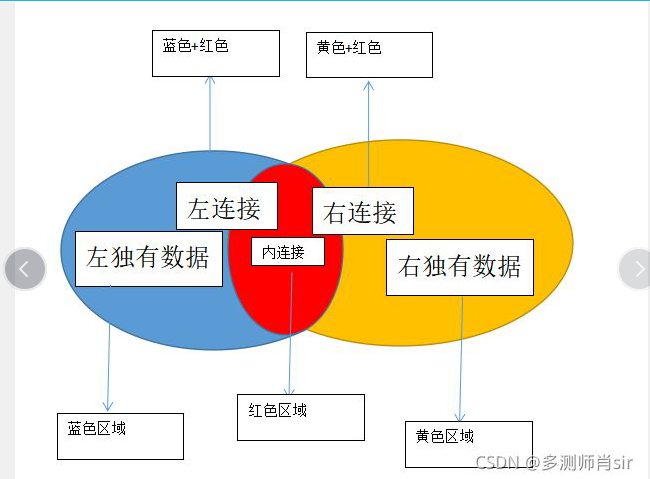
(2)多表连接的关系
a、内连接
b、左连接
c、右连接
e、左独有数据
f、右独有数据
g、全外连接
-比如: a 表:1,2,3 b 表:1,2,4
内连接:显示左边12和右边12关联 显示:12,不显示3,4
左连接:显示左边1,2,3,右 边12 关联 123 4不显示
右连接: 显示右边1,2,4全部显示,左 边12关联 124, 3不显示
左独有数据:显示3
右独有数据:显示4
全外连接:显示1,2,3,4
1、内连接
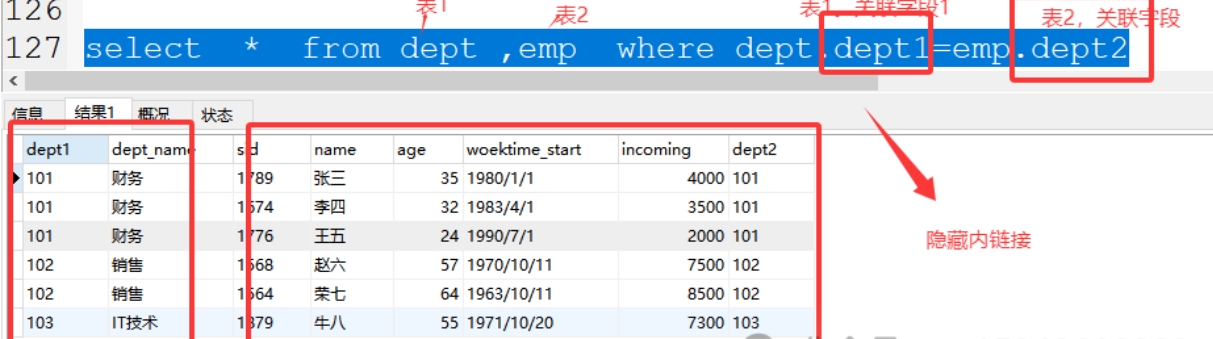
(1)隐藏内连接
格式:select * from 表1,表2 where 表1.关联字段=表2.关联字段
案例:select * from dept,emp where dept.dept1=emp.dept2;
(2)普通内连接
格式:select * from 表1 INNER JOIN 表2 on 表1.关联字段=表2.关联字
案例:select * from dept inner join emp on dept.dept1=emp.dept2;
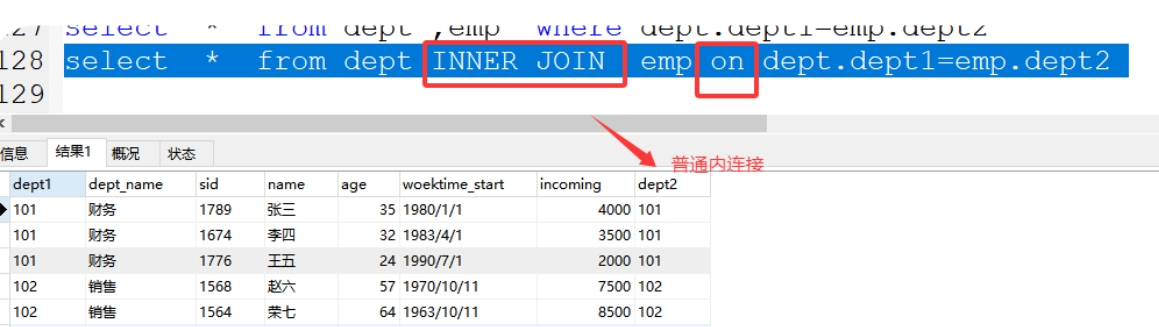
2、左连接:left join
格式:select * from 表1 left JOIN 表2 on 表1.关联字段=表2.关联字
案例:select * from dept left join emp on dept.dept1=emp.dept2;
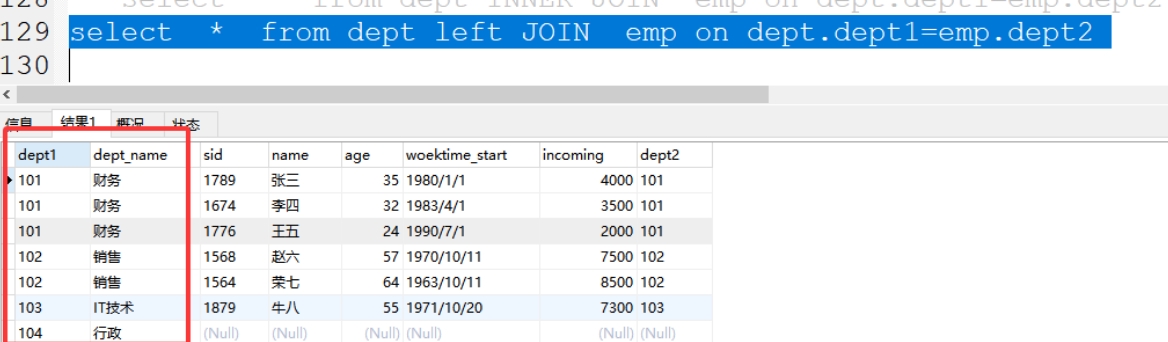
3、右连接:right join
格式:select * from 表1 right JOIN 表2 on 表1.关联字段=表2.关联字
案例:select * from dept right join emp on dept.dept1=emp.dept2;
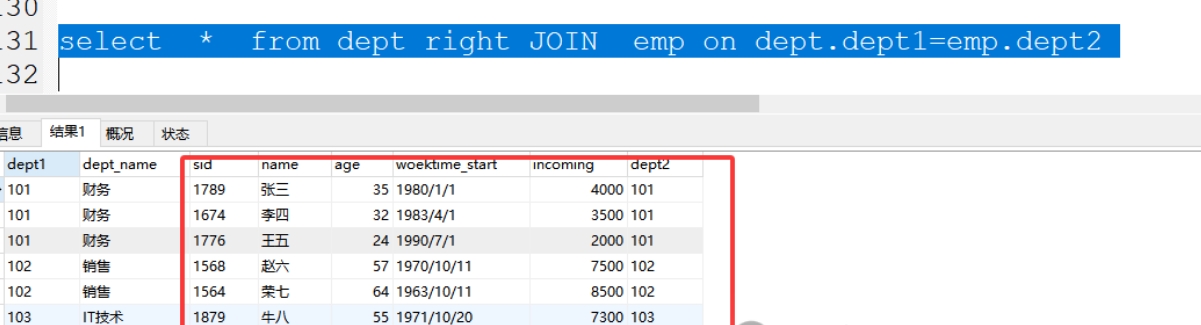
4、左独有数据
格式:select * from 表1 left JOIN 表2 on 表1.关联字段=表2.关联字 where 右表字段 is null
案例:select * from dept left join emp on dept.dept1=emp.dept2 where name is null;

5、右独有数据
格式:select * from 表1 right JOIN 表2 on 表1.关联字段=表2.关联字 where 左表字段 is null
案例:select * from dept right join emp on dept.dept1=emp.dept2 where dept_name is null;

6、全外连接
(1)内连接+左独有数据+右独有数据
案例:select * from dept inner join emp on dept.dept1=emp.dept2
union
select * from dept left join emp on dept.dept1=emp.dept2
union
select * from dept right join emp on dept.dept1=emp.dept2;
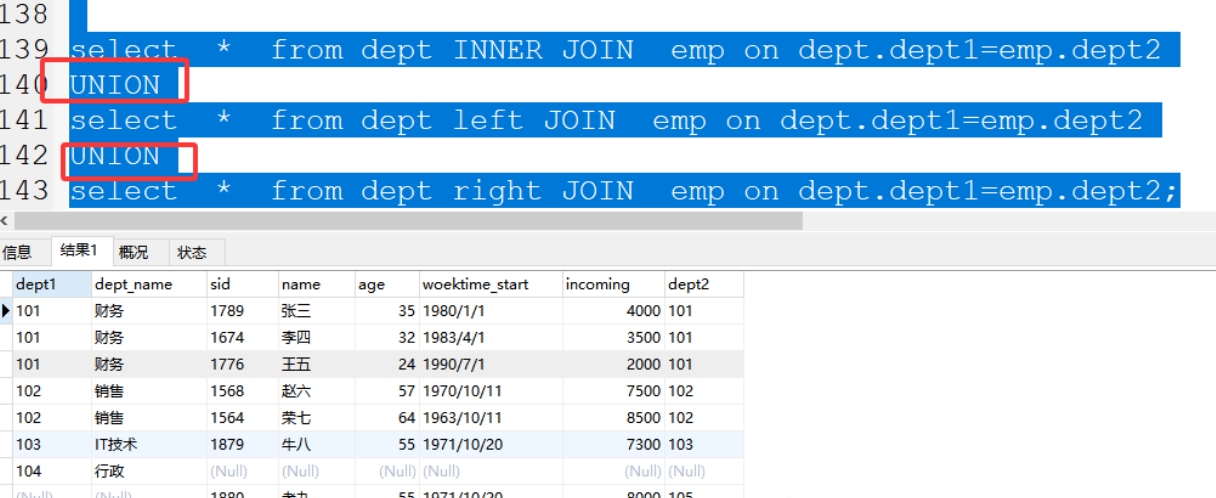
(2)左连接+右独有数据
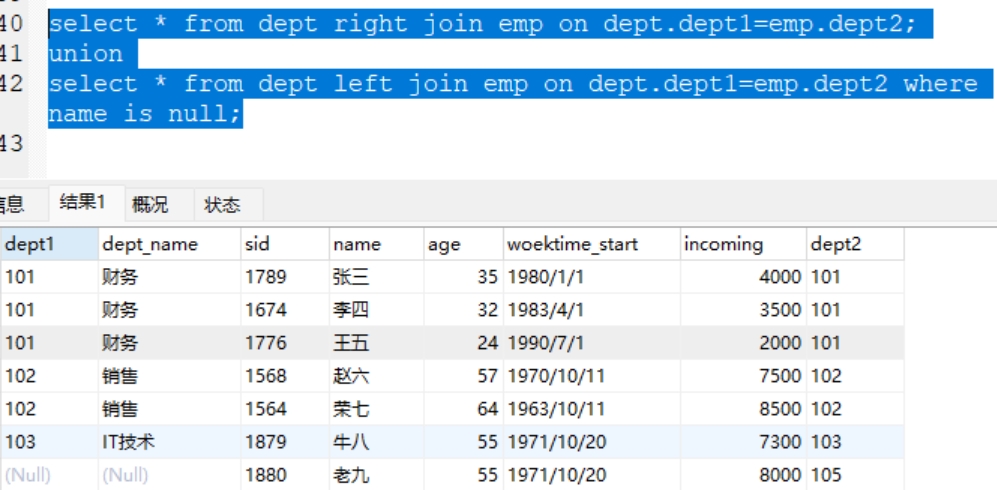
案例:select * from dept left join emp on dept.dept1=emp.dept2
union
select * from dept right join emp on dept.dept1=emp.dept2 where dept_name is null;
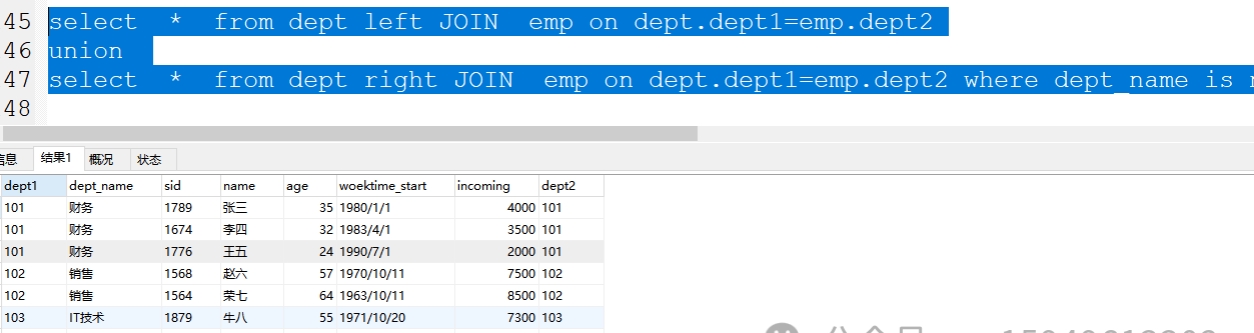
(3)右连接+左独有数据
案例:select * from dept right join emp on dept.dept1=emp.dept2
union
select * from dept left join emp on dept.dept1=emp.dept2 where name is null;
4、子查询
1、定义:一个查询中嵌套另一个查询
2、子查询的分类
(1)标量子查询
(2)列子查询
(3)行子查询
(4)表子查询(运用多)
3、子查询详解
(1)标量子查询(返回一个值)
-把一个sql 执行返回的一个值,作为另一个sql的条件,得到的结果是一行一列,一般出现在where之后-
备注:
标量子查询允许使用的比较运算符号:=,!=,>,<,>=,<=,<>
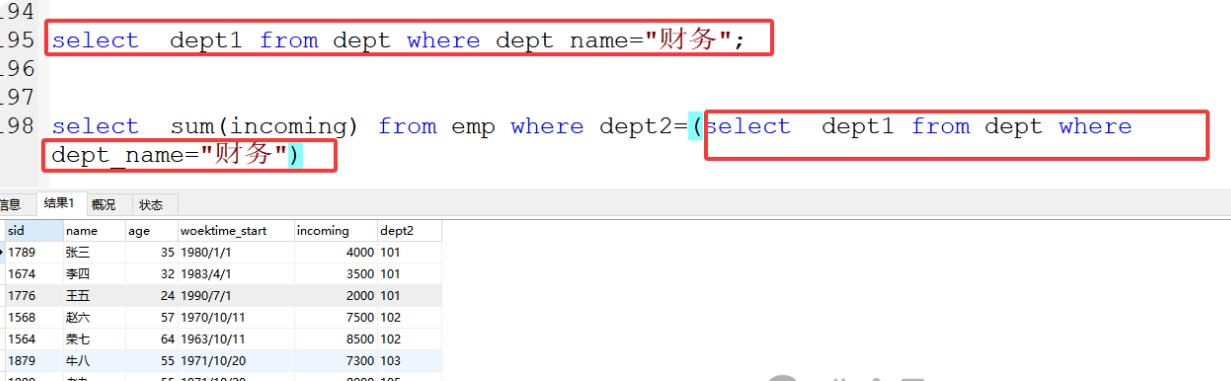
案例:财务部门的收入总和
步骤1:查询财务部门的编号
select dept1 from dept where dept_name='财务';
步骤2:将查询出来的一行一列作为条件
select sum(incoming) from emp where dept2=(select dept1 from dept where dept_name='财务' );
-注意点:判断能不能使用子查询,查看结果是否涉及两个表的字段
如:a、不能用子查询

b、可以用子查询

(2)列子查询(返回的结果是一个列)
定义:返回的是一列值
注意点:通常在where 之后使用,使用是in 或not in ,不运行使用比较运算符,因为它有多个值
案例:It技术部和财务部门入职员工的员工号
步骤1:SELECT dept1 from dept where dept_name='财务' or dept_name='销售';
步骤2:SELECT sid from emp where dept2 in (SELECT dept1 from dept where dept_name='财务' or dept_name='销售')

(3)行子查询
定义:返回的结果是一行多列,一般出现在where 的后面
案例:找出与牛八 年龄和入职时间一样的员工姓名
步骤1:找老九的年龄 和入职时间 :
select age,woektime_start from emp where name="老九" ;

步骤2:在emp中找到年里和入职时间相同的数据
select name from emp where (age,woektime_start) in (select age,woektime_start from emp where name="牛八" ) ;

(4)表子查询
-定义:返回的是多行多表 (返回的就是一个表),一般接在from 的后面,返回的是一个表
-临时表:as 临时表名
-步骤:
a、select * from (合表) where 条件
案例1:
select a.name from (select * from dept INNER JOIN emp on dept.dept1=emp.dept2) as a WHERE a.dept_name="财务"

案例2:
SELECT name,dept_name from emp left join dept on emp.dept2 = dept.dept1 where (age,dept1) in (SELECT max(age),dept2 from emp GROUP BY dept2);
b、select * from 表1 inner join ( )
案例:It技术部和财务部门入职员工的员工号
select sid from emp INNER JOIN (select * from dept where dept_name='财务' or dept_name='IT技术' )c ON emp.dept2=c.dept1
5、三表查询
1、三表连接
格式:select * from 表1,表2,表3 where 表1.关联字段1=表3.关联字段3 AND 表2.关联字段2=表3.关联字段 3;
案例:select * from student as a ,course as b,sc as c where a.stu_no=c.stu_no AND b.c_no=c.c_no ;
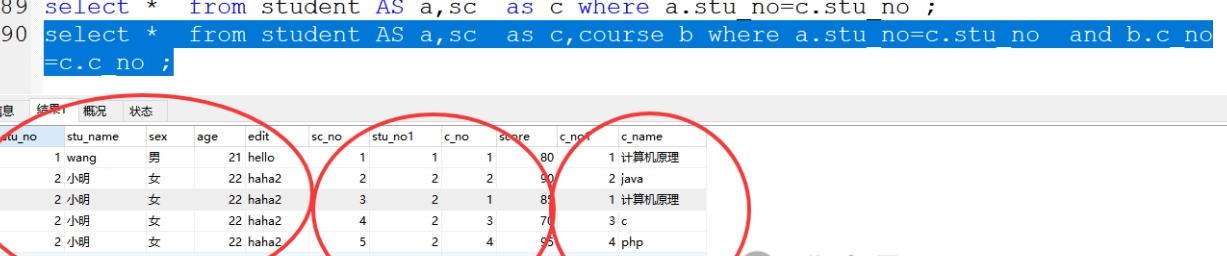
2、三表内连接
格式:select * from 表1 INNER JOIN 表3 on 表1.关联字段1=表3.关联字段3 INNER JOIN表2 on 表2.关联字段2=表3.关联字段3
案例:select * from student as a INNER JOIN sc as c on a.stu_no=c.stu_no INNER JOIN course as b on b.c_no=c.c_no

3、三表左连接
格式:select * from 表1 left JOIN 表3 on 表1.关联字段1=表3.关联字段3 left JOIN表2 on 表2.关联字段2=表3.关联字段3
案例:select * from student as a left JOIN sc as c on a.stu_no=c.stu_no left JOIN course as b on b.c_no=c.c_no
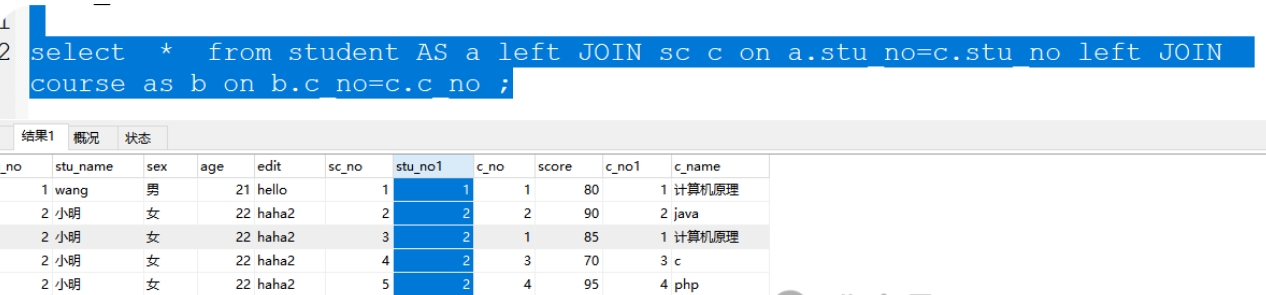
4、三表右连接
格式:格式:select * from 表1 right JOIN 表3 on 表1.关联字段1=表3.关联字段3 right JOIN表2 on 表2.关联字段2=表3.关联字段3
案例:select * from student as a right JOIN sc as c on a.stu_no=c.stu_no right JOIN course as b on b.c_no=c.c_no
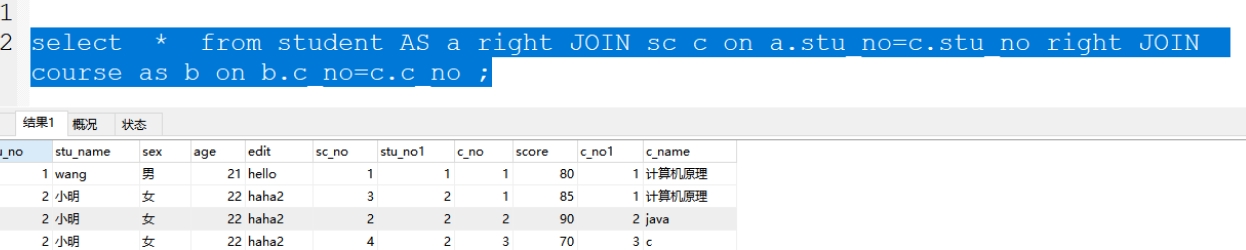
5、先合两表在和一表
格式:select * from (select * from 表1 right JOIN 表3 on 表1.关联字段1=表3.关联字段3 ) 临时表s iner join 表2 on 临时表. 字段3=表2.字段2
案例:select * from (select a.*,c.sc_No,c.c_no,c.score from student AS a right JOIN sc c on a.stu_no=c.stu_no)as s INNER JOIN course as b on s.c_no=b.c_no
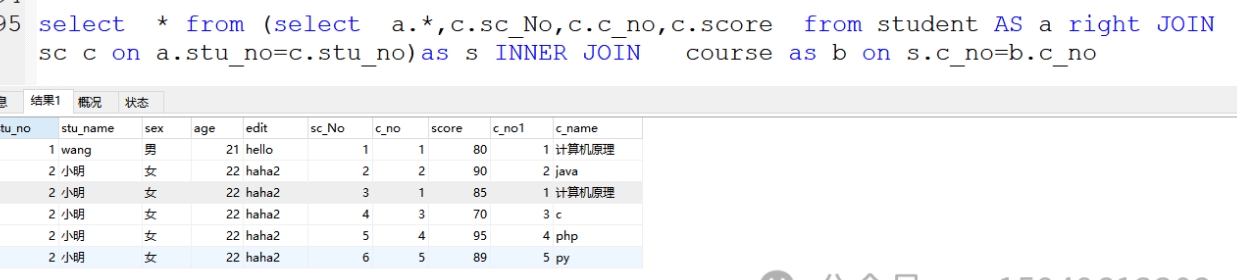
-注意:重复列的错误-

6、去除重复字段
案例:select * from (select a.* ,b.*,c.sc_no,c.score from student AS a right JOIN sc c on a.stu_no=c.stu_no right JOIN course as b on b.c_no=c.c_no) s

4.视图
1、视图的定义
-视图是一个虚拟表,它是一个虚拟表,它不在数据库中以存储的形式保存(本身不包含数据),是在使用视图的时候动态生成
2、视图的优缺点
a、优点:
1)提高查询效率:数据库中的数据查询非常复杂,可以简化sql语句
2)安全:有些保密字段,可以通过创建视图限制用户对某些字段进行操作
3)简单:不需要关心后面对应的表结构
b、缺点:
1)性能差:把视图查询结果转换成对表的查询
2)修改限制:修改视图数据,必须把它转化为对基础表的修改
3、视图的应用
1)创建视图
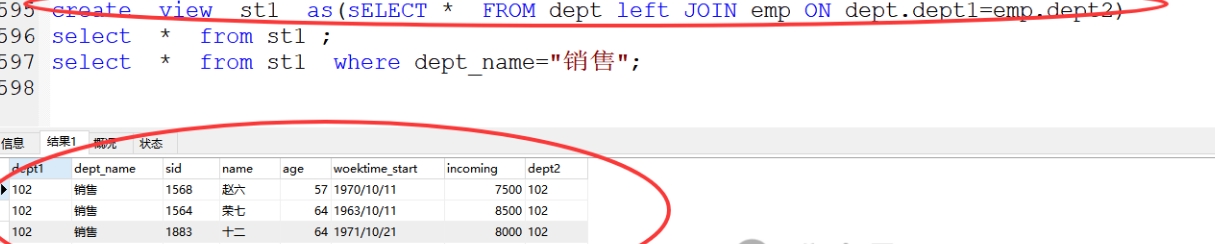
格式:create view 视图名 as (sql语句)
案例:create view st1 as(sELECT * FROM dept left JOIN emp ON dept.dept1=emp.dept2)
2)查询数据库中所有的表 (物理表中是没有视图)
格式:show tables
3)查看视图名
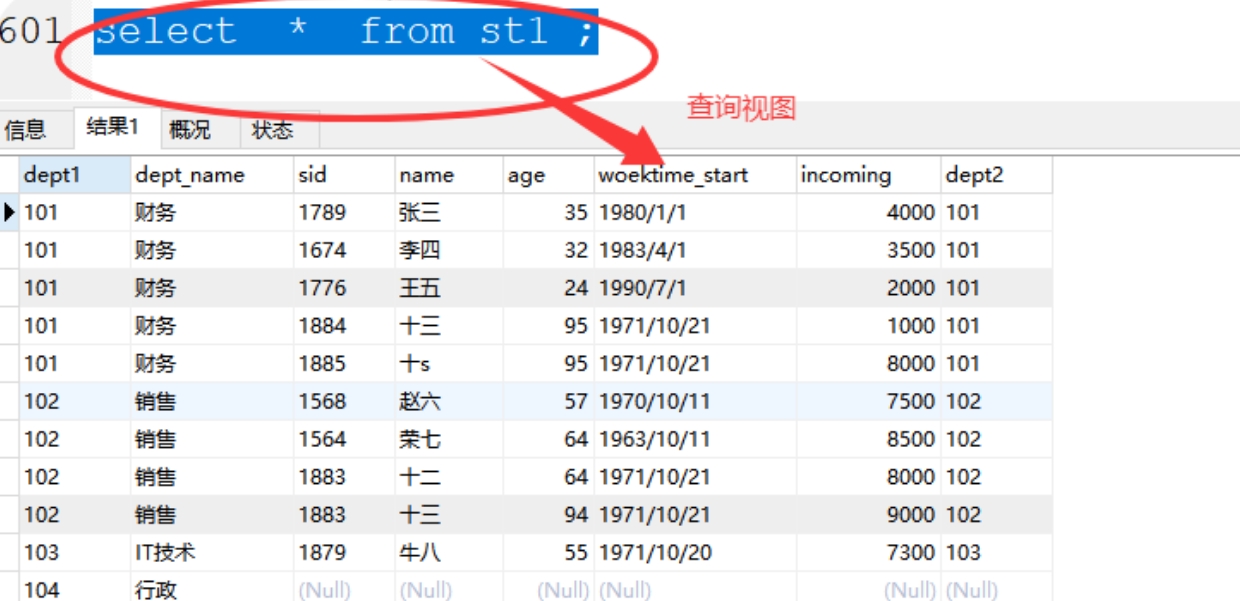
格式:select * from 视图名
案例:SELECT * from st1 ;
4)查看创建的视图(包含创建语句和视图名称,编码格式)
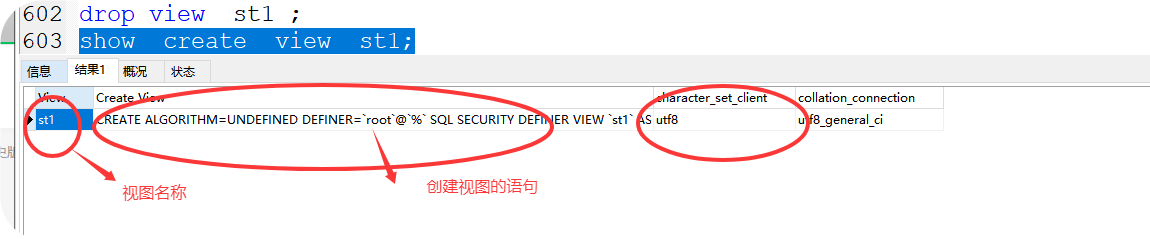
格式:show create view 视图名
案例:show create view sth1;
5)删除视图
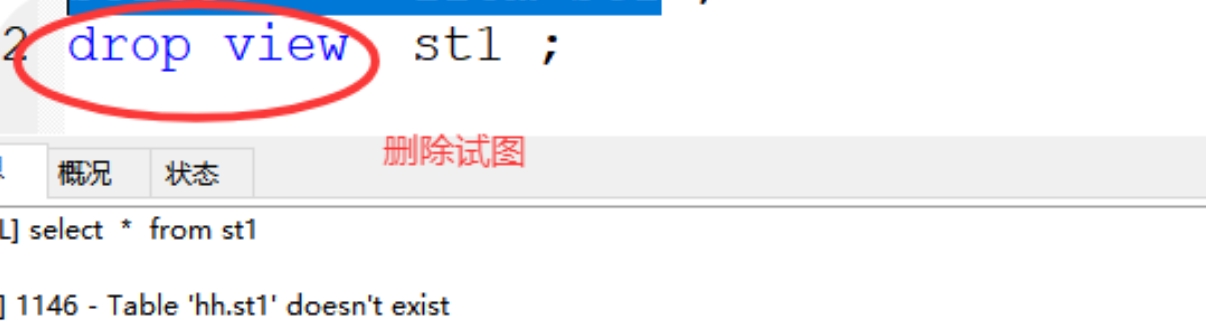
格式:drop view 视图名 ;
案例 :drop view st1;
4、视图特点:
1)视图是由基础表产生的虚拟表
2)视图的创建不影响基础表
3)删除视图不影响基础表
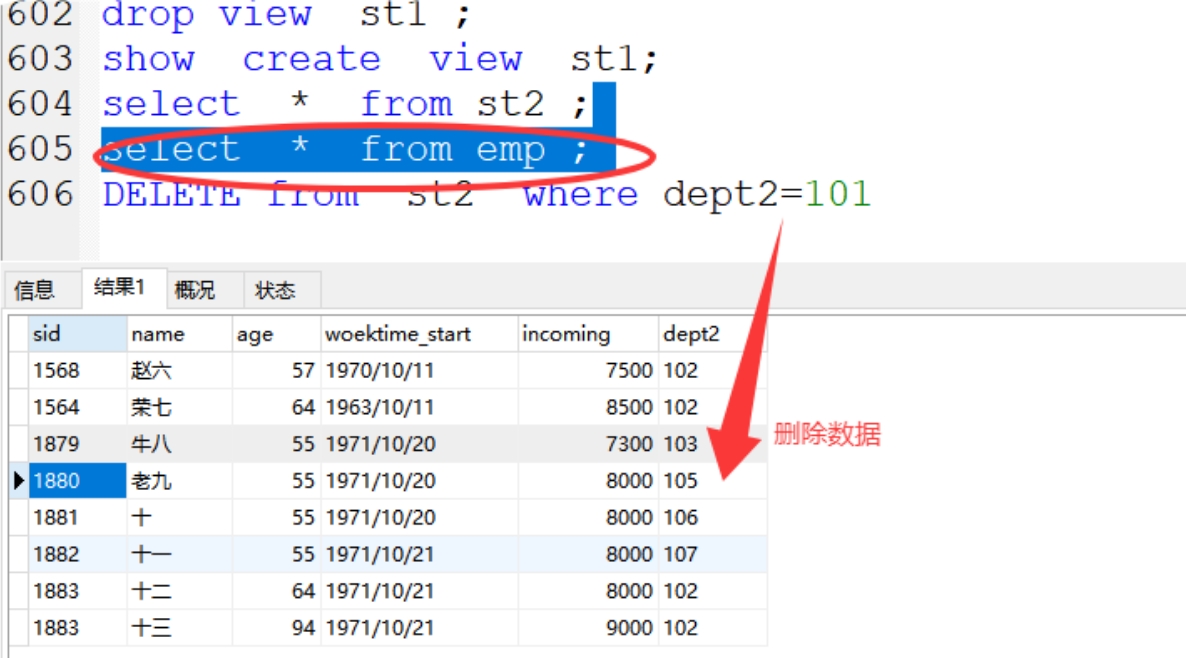
4)视图删除数据,基础表也同时删除数据(合表的表无法删除,单表可以删除)
5)基础表删除数据,视图也同时删除
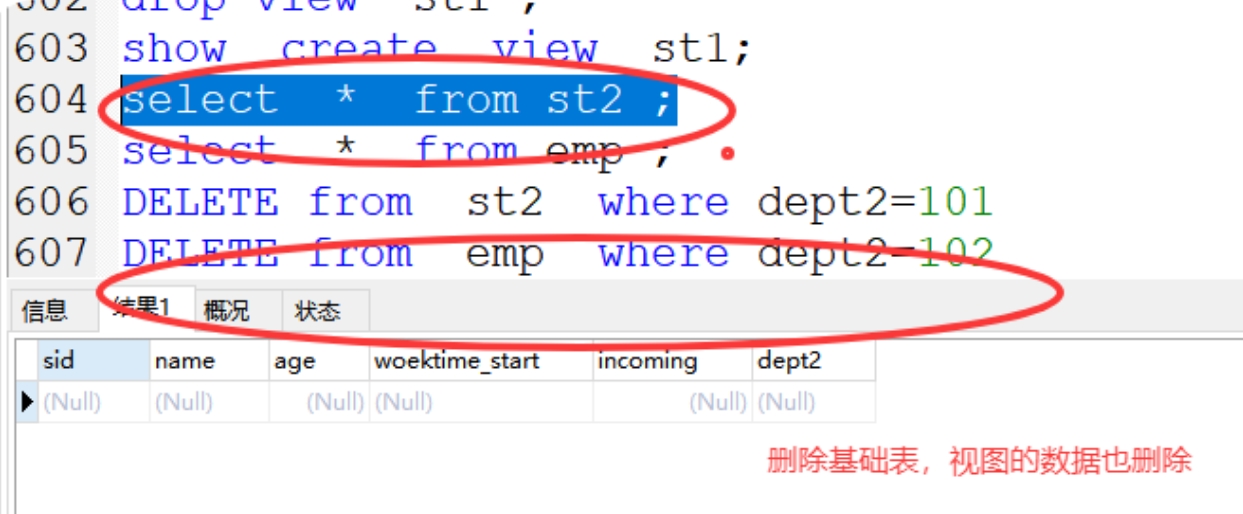
6)视图不能修改表字段,不能对表字段删除
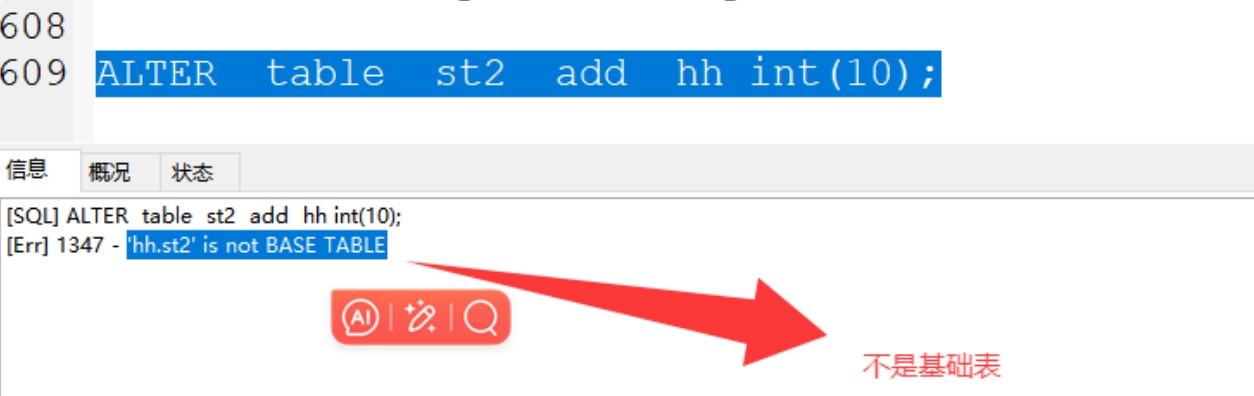
5.索引
1、什么是索引?
(1)定义:索引是一种数据结构
一个索引在存储的表中约束数据结构;
a、索引是在表的字段上创建的
b、索引包含了一列值,这个值保存在一个数据结构中
2、索引的作用
(1)保证数据记录的唯一性
(2)实现表与表之间的参照性
(3)减少排序和分组的时间(例如在使用order by ,group by 查询语句中进行数据检索)
(4)可以使用索引快速访问数据库中指定信息
3、索引的缺点
(1)索引要占物理内存
(2)索引对表进行增删改查,索引要动态维护,降低数据的维护速度
4、索引的分类
(1)普通索引:index
简称:mul;最基本的索引,没有任何限制
(2)主键索引:primary key
简称:pri;是一种唯一索引,不能为空
(3)唯一索引:unique
简称:uni;是一种唯一索引,可为空,一个表中可以有多个唯一索引
5、操作讲解
(1)查看索引
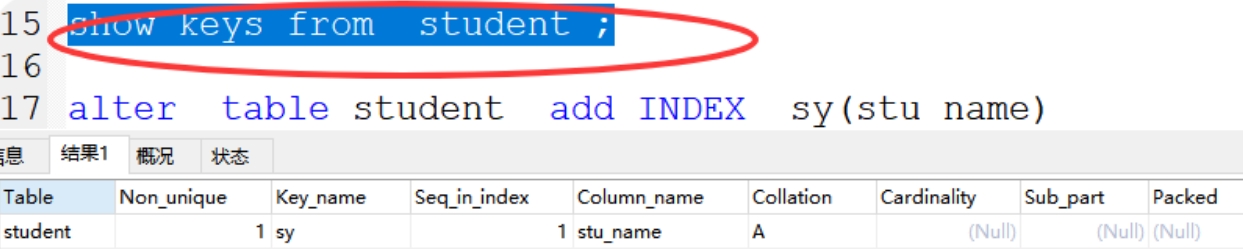
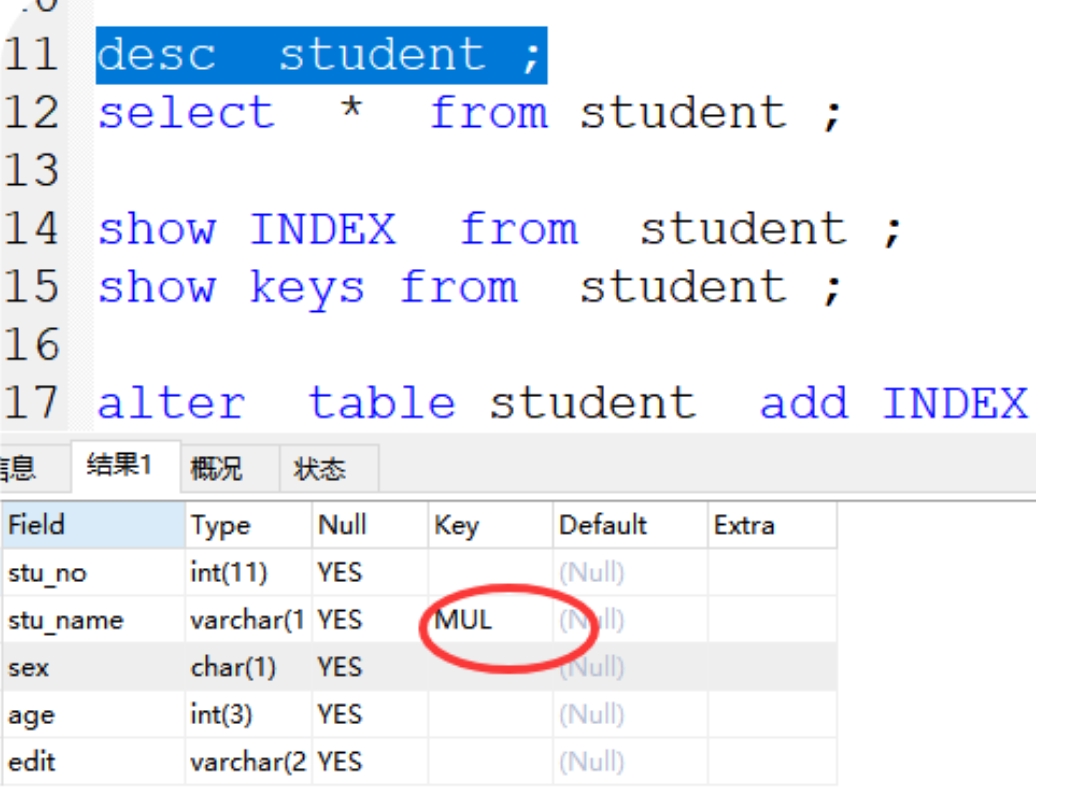
方法1:show INDEX from student ;
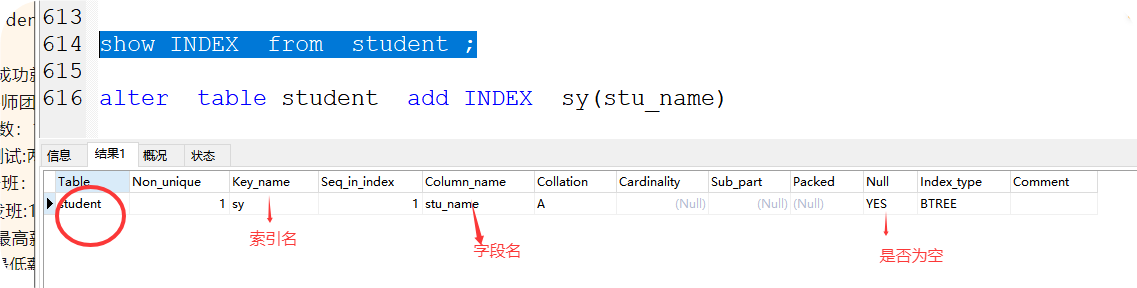
方法2:show keys from student ;
(2)通过查看表结构,是否有索引:desc student ;
(3)创建普通索引
a、创建普通索引 的简写是mul
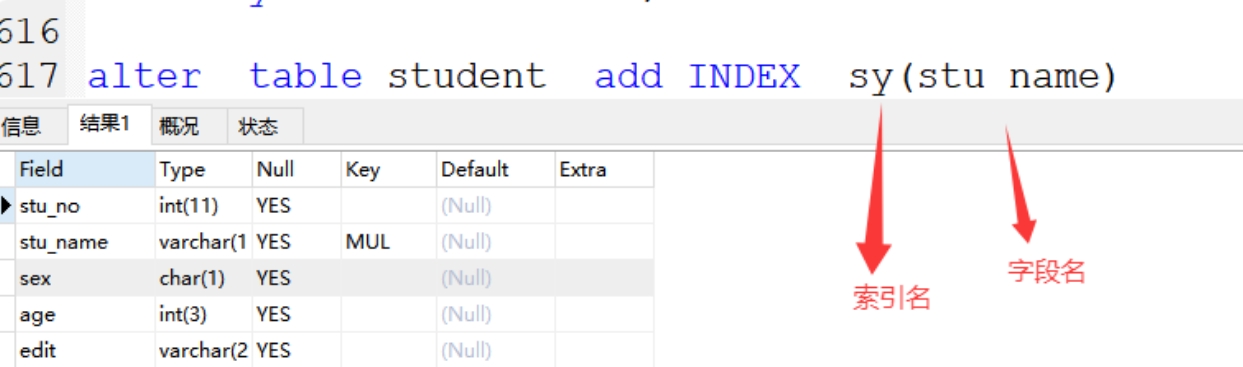
-索引名和字段名不一样-
格式:alter table 表名 add INDEX 索引名(字段名)
案例:alter table student add INDEX sy(stu_name)
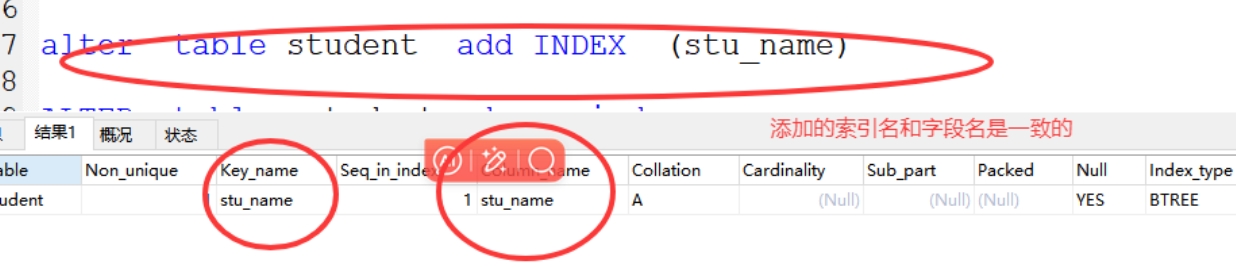
b、创建索引索引名和字段一致
格式:alter table 表名 add INDEX (字段名)
案例:alter table student add INDEX (stu_name)
(4)删除普通索引
格式:ALTER table 表名 drop index 索引名;
案例:ALTER table student drop index sy;

(5)创建主键索引(主键简写:pri)
格式:ALTER table 表名 add PRIMARY key(字段名)
案例:ALTER table student add PRIMARY key(stu_no)

(6)删除主键索引
格式:ALTER table 表名 drop PRIMARY key
案例:ALTER table student drop PRIMARY key

(7)添加唯一索引(unique ;唯一索引简写:uni)
a、添加唯一索引:索引名和字段名不一致
格式:ALTER table 表名 add unique 索引名(字段名)
案例:ALTER table student add unique yy(age)
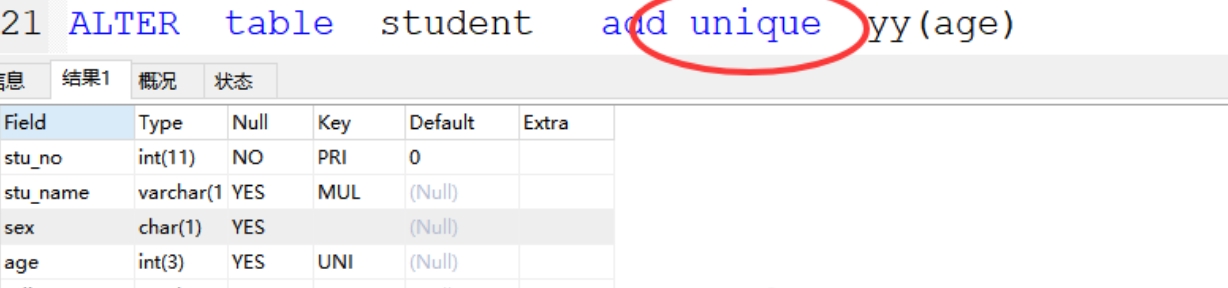
b、添加唯一索引:索引名和字段名一致
ALTER table student add unique (edit)
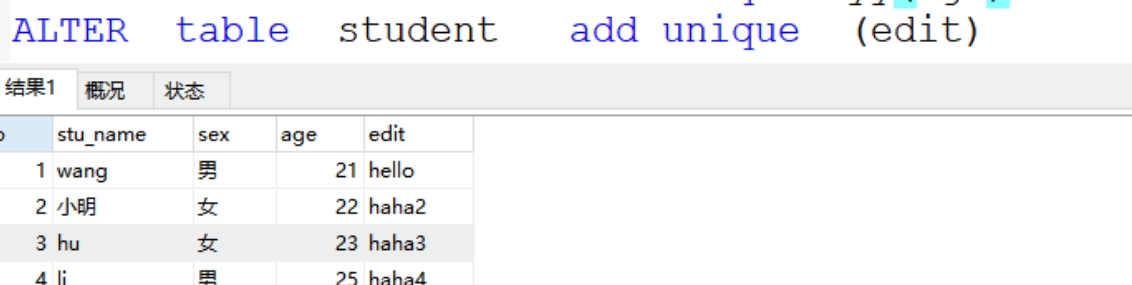
6.外键
1、外键的定义
让一张表记录的数据不要太过于冗余,在数据库中对表的关系进行解耦,尽量让表的数据单一化。
2、外键的作用
保持数据的一致性和完整性
3、msyql 数据库中的存储引擎?
myisam (默认)
innodb (外键需要用到innodb存储格式)
4、查看存储引擎
格式:show table status from 库名 where name='表名' ;
案例:show table status from hh where name='student' ;
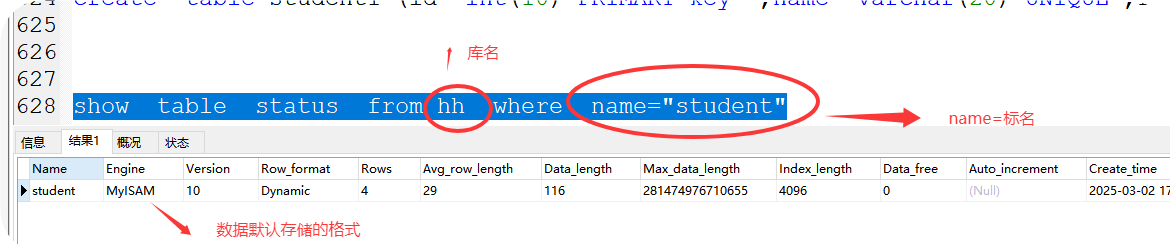
5、存储方式:myisam(默认)
6、查看外键方法:
(1)在navicat中查看
(2)查看外键
show create table student;
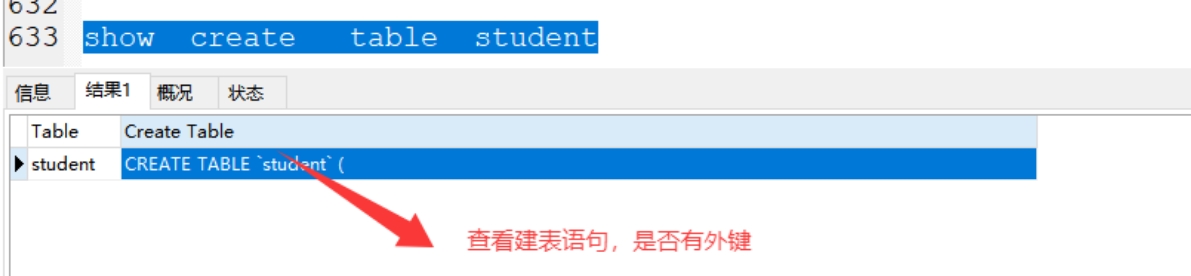
7.操作讲解
1、建表时创建外键
(1)创建 engine=INNODB 格式
格式:CREATE table 表名 (字段名 字段类型(字符长度) PRIMARY key , 字段名 字符类型(字符长度) ,constraint 外键名 FOREIGN key(子表字段)REFERENCES 父表(父表字段)) engine=INNODB ;
案例:
#父表
create table ss (id int(10) PRIMARY key, name varchar(20) )ENGINE=INNODB ;
#子表
CREATE table cc (cid int(10) PRIMARY key ,cname VARCHAR(20) ,constraint wj FOREIGN key(cid)REFERENCES ss(id)) engine=INNODB ;
constraint:外键名(指定外键名)
foreign key:子表字段(指定字段)
references:父表(父表字段)——引用外部表的主键

2、建表以后再添加外键
格式:alter TABLE 子表 add CONSTRAINT 外建名 FOREIGN key (子表字段) REFERENCES 父表(父表字段)
#父表
create table xx (id int(10) PRIMARY key ,name varchar(20))engine=INNODB ;
#子表
create table yy (yid int(10) PRIMARY key ,yame varchar(20))engine=INNODB ;
添加外键:alter TABLE yy add CONSTRAINT wjm FOREIGN key (yid) REFERENCES xx(id)
-格式:show create table 表名;-
-案例:show create table cc-
3、删除外键
格式:ALTER TABLE 表名 drop FOREIGN key 外键名;
案例:ALTER TABLE yy drop FOREIGN key wj1;
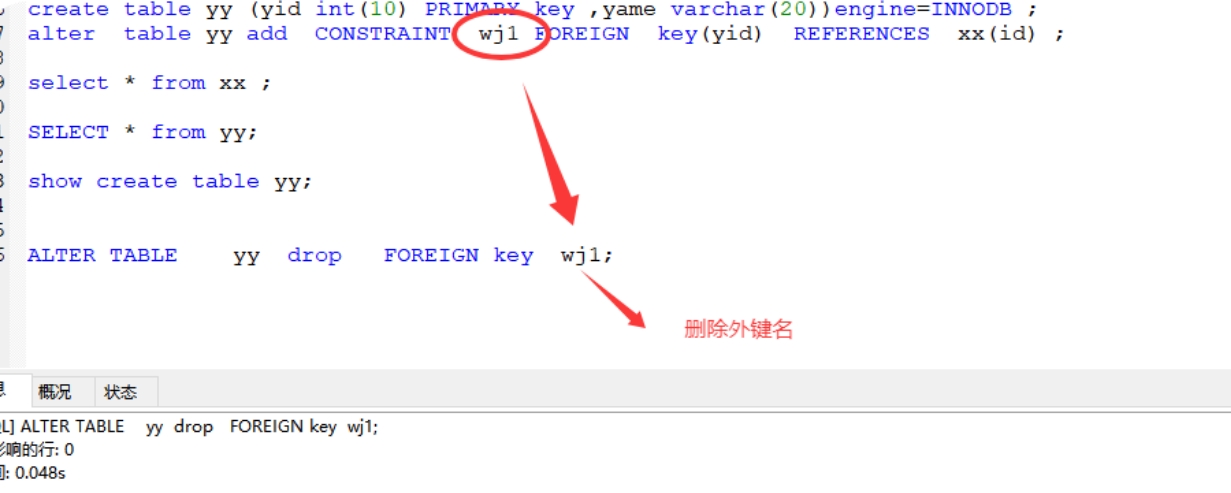
4、外键的特点
(1)当父表不存在的数据,子表也无法插入数据(子表无法插入数据)

(2)父表中存在的数据,子表就可以插入数据(插入数据)
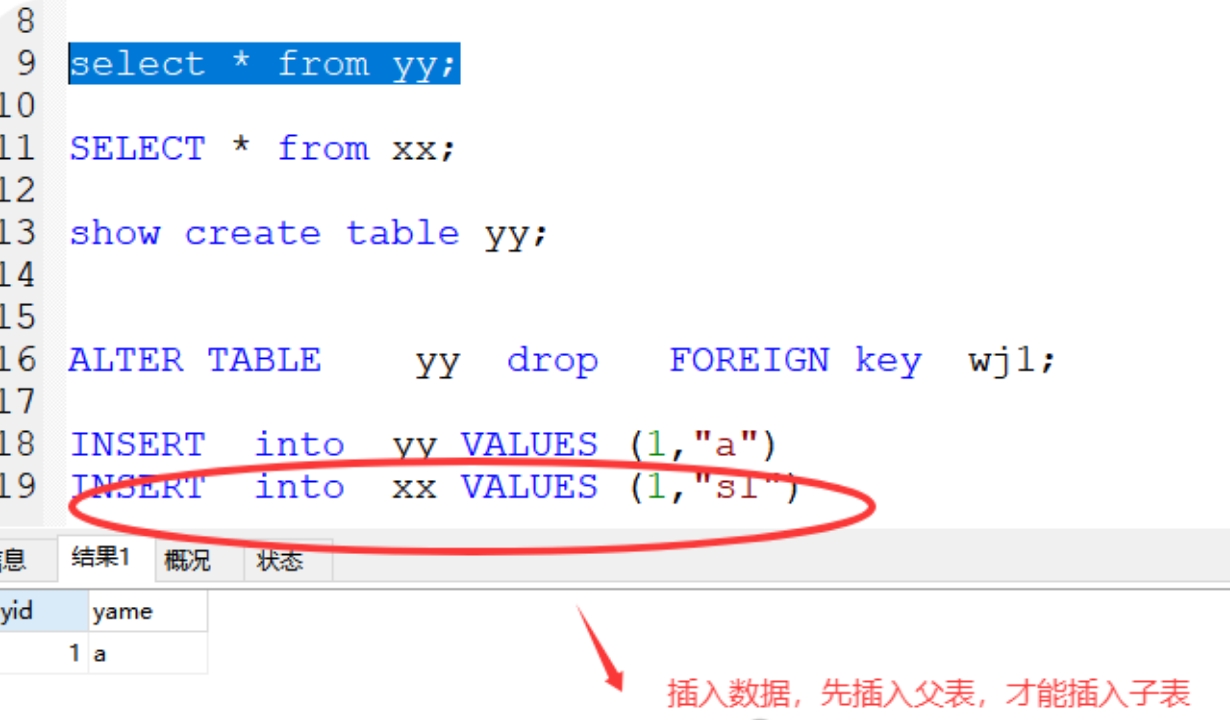
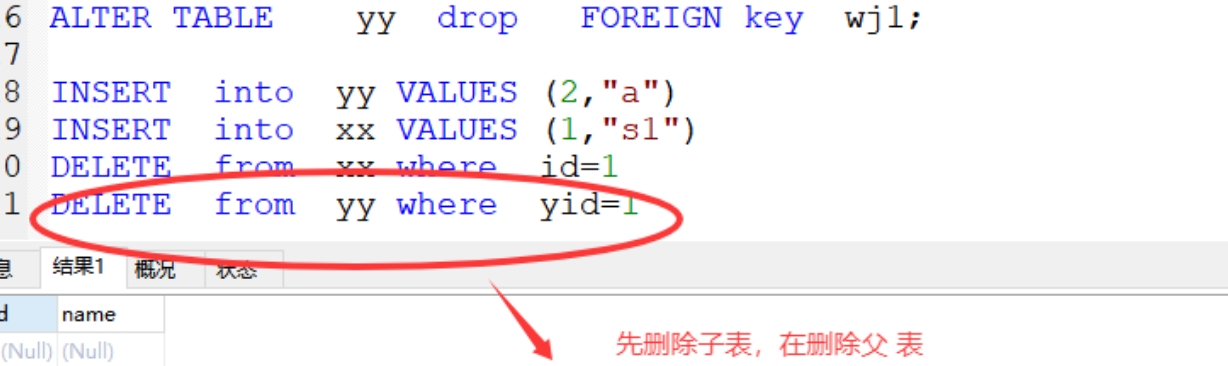
(3)删除数据,子表中存在的数据,直接删除父表是无法删除 (要先删除子表数据,再删除父表数据)

(4)删除父表的数据,先删除子表,再删除父表
7.存储
1、什么是存储过程?
存储过程是实现某个特点功能的sql语句的集合,编译后的存储过程会保存在数据中,通过存储过程的名称反复的调用执行。
2、存储过程的优点?
(1)存储过程创建后,就可以反复地调用和使用,不需要重新写复杂的语句
(2)创建,修改存储过程不会对数据有任何的影响
(3)存储过程可以通过输入参数返回输出值
(4)通过存储过程中加入控制语句,可以加强sql语句的功能性和灵活性
(5)对于单个语句增删改查,可以直接封装一个集合中,存储过程一旦创建就可以直接调用,且可以重复调用
(6)单个sql语句每一次执行都需要对数据进行编译,而存储过程被创建只需要编译一次,后续即可调用
(7)创建的存储过程,可以重复进行调用,可以减少数据库开发人员的工作量
(8)防止sql 注入
(9)造数据(重点)
3、mysql5.0版本之后就支持存储过程,存储过程是由sql语句和控制语句组成的
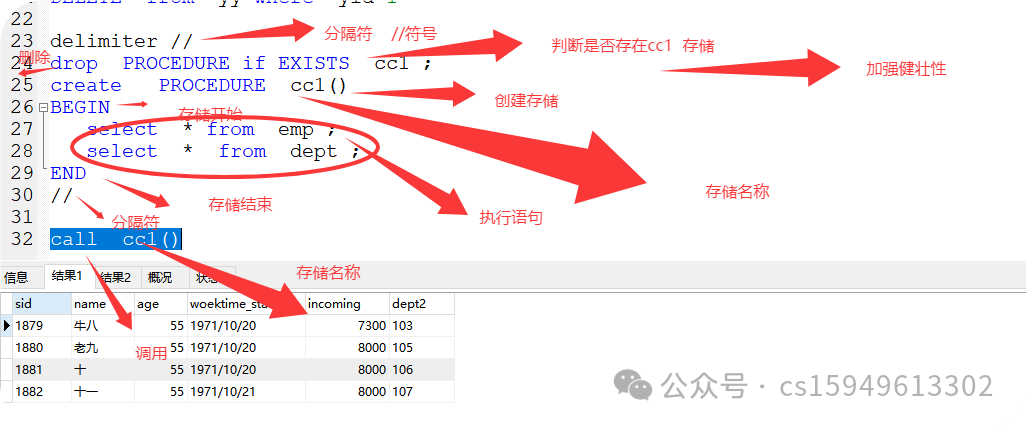
3.存储的操作及格式
1、基本格式(不带参数):
delimiter // 分隔符
drop (删除) PROCEDURE (存储) if EXISTS(判断是否存在) cc1 存储;
create创建 PROCEDURE存储 cc1() 存储名称
BEGIN 开始
select * from emp ; 存储体1
select * from dept ;存储体2
END 结束存储
// 分割符
call cc1() 调用 存储名称
案例:
delimiter //
drop PROCEDURE if EXISTS cc1 ;
create PROCEDURE cc1()
BEGIN
select * from emp ;
select * from dept ;
END
//
call cc1()
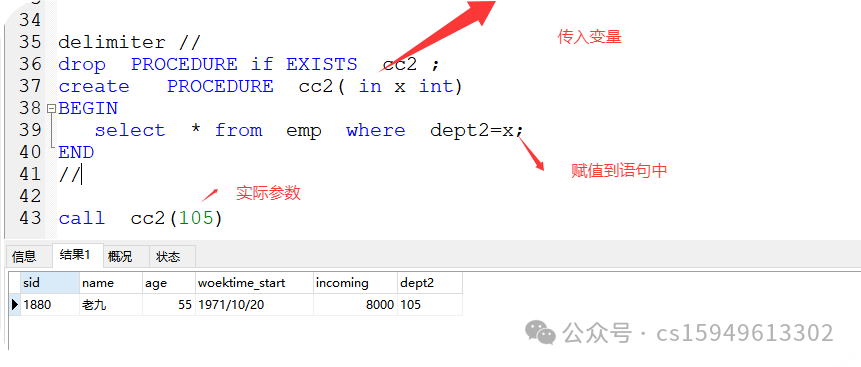
2、带传入参数(in)
格式:
delimiter //
drop PROCEDURE if EXISTS 存储名称;
create PROCEDURE 存储名称( in x int)
BEGIN
语句1
END
//
call 存储名(实际参数)
案例:
delimiter //
drop PROCEDURE if EXISTS cc2 ;
create PROCEDURE cc2( in x int)
BEGIN
select * from emp where dept2=x;
END
//
call cc2(105)
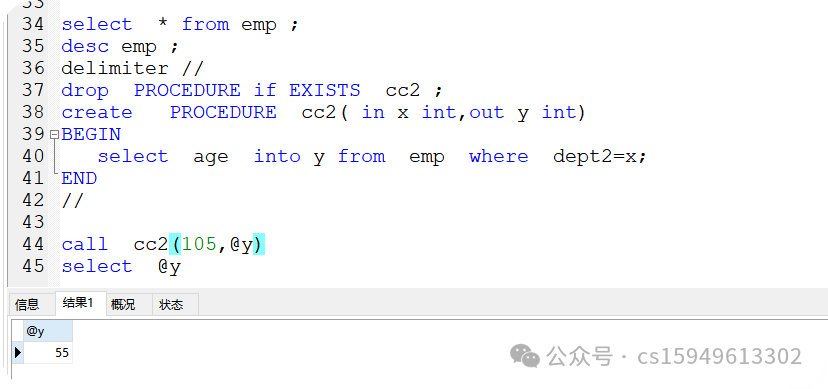
3、in输入值、out 返回值
select * from emp ;
desc emp ;
delimiter //
drop PROCEDURE if EXISTS cc2 ;
create PROCEDURE cc2( in x int,out y int)
BEGIN
select age into y from emp where dept2=x;
END
//
call cc2(105,@y)
select @y
4、inout 一个变量是输入值也是输出值
案例:
delimiter //
drop PROCEDURE if EXISTS cc2 ;
create PROCEDURE cc2( inout x int)
BEGIN
set x=x+1;
END
//
set @x=1
call cc2(@x)
select @x

5、设置变量方法:
set @ 变量名
赋值的方法:
(1)方式一
set @ 变量名:=值 设置一个变量值
select @变量名 显示所有数据
(2)方式二
通过查询结果为变量赋值:
select 字段 into 变量名 from 表名 where 条件
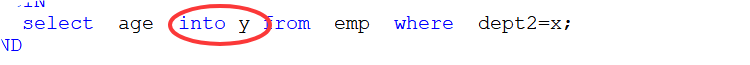
6、循环语句while
while 循环语句:
格式
while 条件 do
sql语句
end while
7、造数据场景
(1)传入固定值
create table m1 (id int(10) PRIMARY key ,name varchar(20));
delimiter //
drop PROCEDURE if EXISTS cc2 ;
create PROCEDURE cc2( )
BEGIN
INSERT into m1(id) VALUES(2);
SELECT * from m1;
END
//
call cc2()
(2)出入变量值的数据
案例
delimiter //
drop table if EXISTS m1;
create table m1 (id int(10) PRIMARY key ,name varchar(20));
drop PROCEDURE if EXISTS cc2 ;
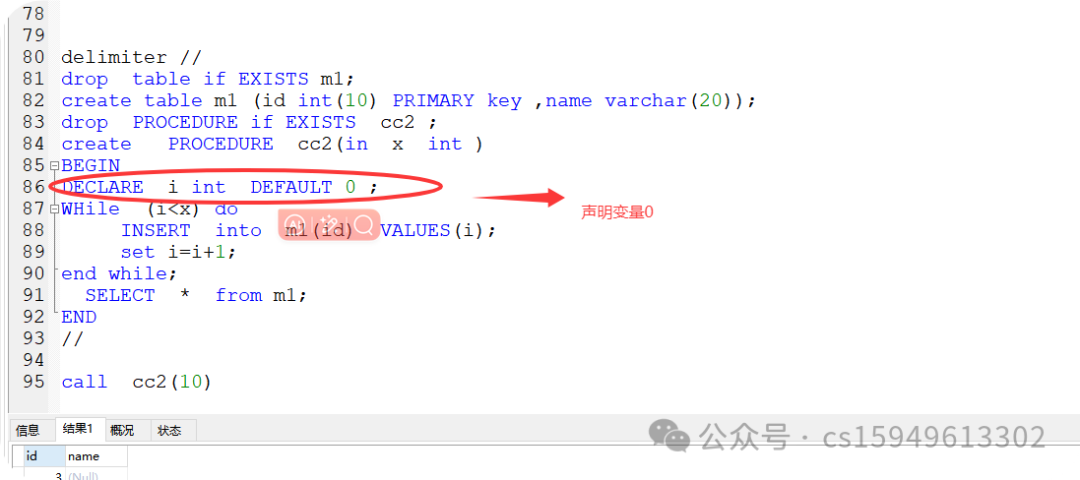
create PROCEDURE cc2(in x int )
BEGIN
DECLARE i int DEFAULT 0 ;
WHile (i<x) do
INSERT into m1(id) VALUES(i);
set i=i+1;
end while;
SELECT * from m1;
END
//
call cc2(10)
(3)先统计总数量,再插入传入的值
delimiter //
drop table if EXISTS m1;
create table m1 (id int(10) PRIMARY key ,name varchar(20));
drop PROCEDURE if EXISTS cc2 ;
create PROCEDURE cc2(in x int )
BEGIN
DECLARE i int DEFAULT (select count(*) from m1) ;
WHile (i<x) do
INSERT into m1(id) VALUES(i);
set i=i+1;
end while;
SELECT * from m1;
END
//
call cc2(10)
(4)每次删除表,再重新插入数据
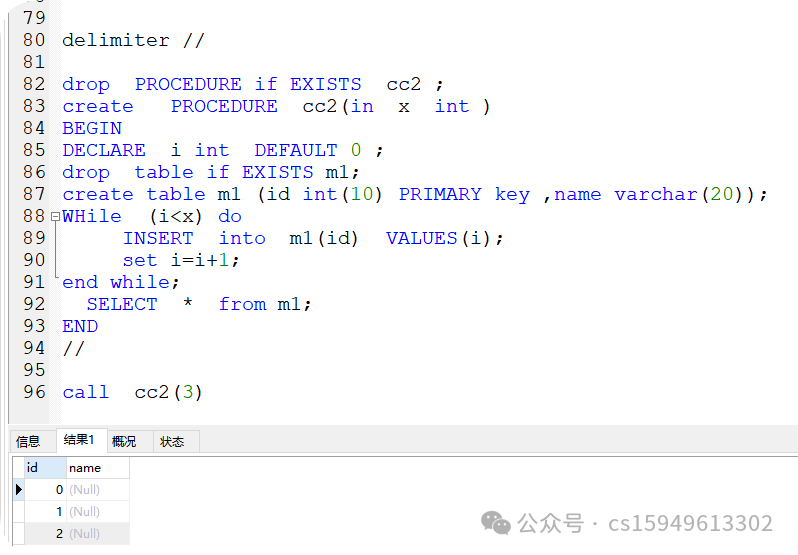
delimiter //
drop PROCEDURE if EXISTS cc2 ;
create PROCEDURE cc2(in x int )
BEGIN
DECLARE i int DEFAULT 0 ;
drop table if EXISTS m1;
create table m1 (id int(10) PRIMARY key ,name varchar(20));
WHile (i<x) do
INSERT into m1(id) VALUES(i);
set i=i+1;
end while;
SELECT * from m1;
END
//
call cc2(3)
8、if判断语句
(1)if单分支
格式“:
if 条件 then
sql1
ELSE
sql2
end if; #结束if语句
案例:
delimiter //
drop PROCEDURE if EXISTS cc2 ;
create PROCEDURE cc2(in x int )
BEGIN
if x>2 THEN
select * from emp ;
ELSE
select * from dept ;
end if;
END
//
call cc2(5)

(2)if多分支
格式:
if 条件1 THEN
slq1
ELSE if 条件2 then
slq2
ELSE if 条件3 then
sql3
ELSE
sql4
end if;
end if;
end if;
案例
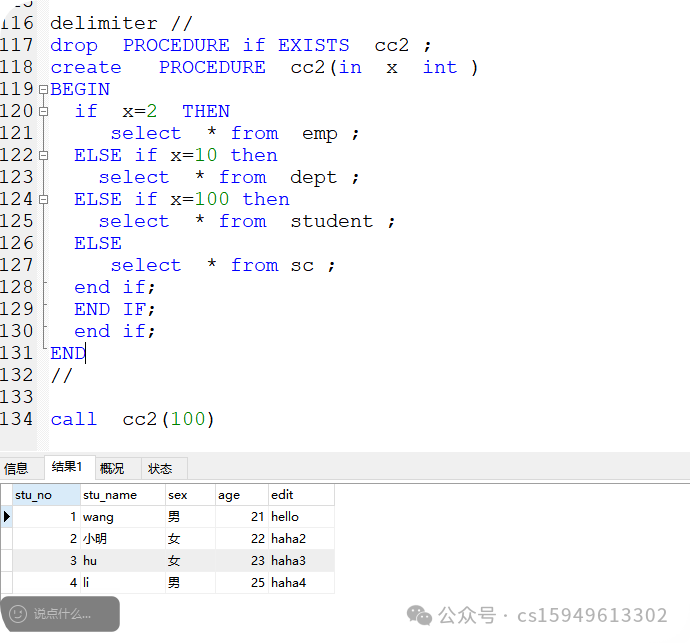
delimiter //
drop PROCEDURE if EXISTS cc2 ;
create PROCEDURE cc2(in x int )
BEGIN
if x=2 THEN
select * from emp ;
ELSE if x=10 then
select * from dept ;
ELSE if x=100 then
select * from student ;
ELSE
select * from sc ;
end if;
END IF;
end if;
END
//
call cc2(100)
练习:
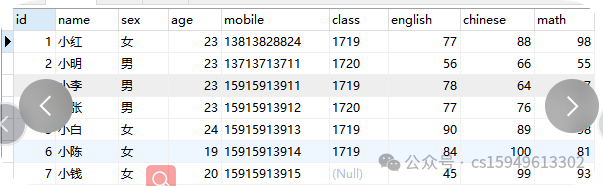
建表语句:
create table student2(
id int primary key ,
name char(20),
sex char(10),
age int(3),
mobile char(20),
class char(10),
english int(10),
chinese int(10),
math int(10)
)engine=innodb default charset=utf8;
insert into student2 values(
(1,'小红','女',23,'13813828824','1719',77,88,98),
(2,'小明','男',23,'13713713711','1720',56,66,55),
(3,'小李','男',23,'15915913911','1719',78,64,87),
(4,'小张','男',23,'15915913912','1720',77,76,77),
(5,'小白','女',24,'15915913913','1719',90,89,98),
(6,'小陈','女',19,'15915913914','1719',84,100,81),
(7,'小钱','女',20,'15915913915',null,45,99,93);
)
面试题:根据student学生表去写
1.当传入的参数(大于0)小于等于表里面数据的条数时,则根据分组显示班级的总成绩
2.当传入的参数大于表里面数据的条数时,则统计表里面的数据有多少条
3.当传入其他,则查询表里面的所有数据
案例:
delimiter //
drop procedure if exists cc2 ;
create PROCEDURE cc2(in x int )
BEGIN
DECLARE i int DEFAULT (select count(*) from student2); #声明变量
if x<=i and x>0 THEN
select sum(english+chinese+math) from student2 group by class ;
ELSE IF x>i THEN
select count(*) from student2;
ELSE
select * from student2;
end if;
end if;
END
//
call cc2(-1)

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









