



 本文详细描述了配置淘宝双11数据分析环境的过程,包括Linux、JDK、Hadoop、Hive、Sqoop、Spark、Echarts等组件的版本和配置。在数据预处理阶段,删除了文件头并选取部分数据导入Hive。接着,数据从Hive导入到MySQL,并使用Spark进行回头客预测。最后,利用Echarts进行数据可视化,展示了不同维度的交易数据分布。
本文详细描述了配置淘宝双11数据分析环境的过程,包括Linux、JDK、Hadoop、Hive、Sqoop、Spark、Echarts等组件的版本和配置。在数据预处理阶段,删除了文件头并选取部分数据导入Hive。接着,数据从Hive导入到MySQL,并使用Spark进行回头客预测。最后,利用Echarts进行数据可视化,展示了不同维度的交易数据分布。
一、运行环境
至此“淘宝双 11 数据分析与预测课程案例”所需要的环境配置完成。另外实际操作中发现在案例教程中存在一些小问题,比如教程中 Eclipse 版本为 3.8,但是在配置 Tomcat Server 时又要求配置 v8.0 版本,然而 3.8 版本的 Eclipse 最多仅支持到 v7.0 版本的 Tomcat,所以实际操作时使用了更新的 Eclipse 版本。
实际配置环境结合了实际情况,没有和实验案例完全一致,不过整个功能正常实现。实际运行环境及版本如下所示。
Linux:
Ubuntu14.04
JDK:
Openjdk-1.7.0_181
Hadoop: 2.7.6
MySQL: 5.7.24
Hive: 1.2.2
Sqoop: 1.4.7
Spark: 2.1.0
Eclipse: 4.5.0
Echarts: 3.8.4
配置过程中截图如下所示,由于步骤较多,仅截取部分关键步骤。

图 1.1 创建 hadoop 用户,添加管理权限

图 1.2 安装配置 SSH

图 1.3 配置 Java

图 1.4 配置 Hadoop

图 1.5 运行 Hadoop

图 1.6 配置运行 MySQL

图 1.7 配置运行 Hive

图 1.8 配置运行 Sqoop

图 1.9 配置运行 Spark
至此“淘宝双 11 数据分析与预测课程案例”所需要的环境配置完成。另外实际操作中发现在案例教程中存在一些小问题,比如教程中 Eclipse 版本为 3.8,但是在配置 Tomcat Server 时又要求配置 v8.0 版本,然而 3.8 版本的 Eclipse 最多仅支持到 v7.0 版本的 Tomcat,所以实际操作时使用了更新的 Eclipse 版本。
二、本地数据集上传到数据仓库 Hive
实验数据集有 3 个文件,分别是用户行为日志文件 user_log.csv、回头客训练集 train.csv、回头客测试集 test.csv,以下是三个文件的数据格式及说明。
表 2.1 user_log 字段定义
字段名 | 字段含义 |
user_id | 买家 id |
item_id | 商品 id |
cat_id | 商品类别 id |
merchant_id | 卖家 id |
brand_id | 品牌 id |
month | 交易时间:月 |
day | 交易事件:日 |
action | 行为,取值范围{0,1,2,3},0 表示点击,1 表示加入购物车,2 表示购买,3 表示关注商品 |
age_range | 买家年龄分段:1 表示年龄 <18,2 表示年龄在[18,24],3 表示年龄在[25,29],4 表示年龄在[30,34],5 表示年龄在[35,39],6 表示年龄在[40,49],7 和 8 表示年龄 >=50,0 和 NULL 则表示未知 |
gender | 性别:0 表示女性,1 表示男性,2 和 NULL 表示未知 |
province | 收获地址省份 |
回头客训练集 train.csv 和回头客测试集 test.csv,训练集和测试集拥有相同的字段。
表 2.2 user_log 字段定义
字段名 | 字段含义 |
user_id | 买家 id |
age_range | 买家年龄分段:1 表示年龄 <18,2 表示年龄在[18,24],3 表示年龄在[25,29],4 表示年龄在[30,34],5 表示年龄在[35,39],6 表示年龄在[40,49],7 和 8 表示年龄 >=50,0 和 NULL 则表示未知 |
gender | 性别:0 表示女性,1 表示男性,2 和 NULL 表示未知 |
merchant_id | 卖家 id |
label | 是否是回头客,0 值表示不是回头客,1 值表示回头客,-1 值表示该用户已经超出我们所需要考虑的预测范围。NULL 值只存在测试集,在测试集中表示需要预测的值。 |
2.1 数据集的预处理
2.1.1 删除文件第一行记录(字段名称)
获取数据集并解压,可以看到 dataset 下有三个文件:test.csv、train.csv、user_log.csv。

图 2.1
查看前五条记录

图 2.2
删除第一行的字段名称,并确认是否删除

图 2.3
2.1.2 获取数据集中前 10000 条数据
建立脚本,编辑 predeal.sh 脚本文件

图 2.4
修改执行权限,执行脚本,输出 small_user_log.csv

图 2.5
2.1.3 把 small_user_log.csv 中的数据导入数据仓库 Hive
为此首先把这个文件上传到分布式文件系统 HDFS 中,然后在 Hive 中创建两个个外部表,完成数据导入
启动 Hadoop

图 2.6
把 user_log.csv 上传到 HDFS 中
在 HDFS 根目录下创建子目录

图 2.7
上传文件 small_user_log.csv

图 2.8
查看 HDFS 中的 small_user_log.csv 的前 10 条记录
图 2.9
在 Hive 上创建数据库
启动 MySQL

图 2.10
启动 Hive

图 2.11
这里启动时出现了一个小 bug,提示找不到 spark-assembly 集成包:

图 2.12
这是由于 hive 版本升级到 2.0 以上之后,spark-assembly 集成包被拆成分散的小 jar 包导致的,只需要编辑 bin/hive,将这个 spark-assembly-.jar` 替换成 jars/.jar 即可。
创建数据库 dbtaobao

图 2.13
创建外部表

图 2.14
查询数据

图 2.15
三、Hive 数据分析
3.1 查看 user_log 表
进入 hive shell,通过 show 指令查看表的属性和结构。如图 3.1。

图 3.1
显示结果如图 3.2。

图 3.2
3.2 查询条数及统计分析
3.2.1 计算表内数据行数
通过 select 指令结合 count 指令可以统计记录行数。

图 3.3
3.2.2 查询 uid 不重复的数据条数

图 3.4
3.2.3 查询不重复数据条数
主要为了排除客户刷单情况。

图 3.5
可以看出,排除掉重复信息以后,只有 4754 条记录。
3.2.4 统计男女买家购买商品数量
统计双十一当天男女购买数量,方便后面计算比例。

图 3.6 统计男买家

图 3.7 统计女买家
3.2.5 查询某一天在网站购买该数量商品的用户 id
给定购买商品的数量范围,查询某一天在该网站的购买该数量商品的用户 id.
通过 group by 和 having 结合,如查询购买商品超过 5 次的用户 id 指令:
selectuser_idfromuser_logwhereaction='2'groupbyuser_idhavingcount(action='2')>5;查询结果较长,此处不一一列出。
3.3 用户实时查询分析
3.3.1 创建新数据表
创建新的数据表 scan 进行存储,执行结果如图 3.8 所示。

图 3.8
3.3.2 导入统计后的数据
通过 insert 指令导入数据:
hive>insertoverwritetablescanselectbrand_id,count(action)fromuser_logwhereaction='2'groupbybrand_id;
图 3.9
3.3.3 显示统计结果
执行 select 指令:
Hive>select*fromscan;
图 3.10
四、将数据从 Hive 导入到 MySQL
4.1 Hive 预操作
4.1.1 创建临时表
创建临时表 inner_user_log 和 inner_user_info.

图 4.1
4.1.2 数据插入
将 user_log 表中的数据插入到 inner_user_log。

图 4.2
4.1.3 查看是否成功执行

图 4.3
4.2 使用 Sqoop 将数据从 Hive 导入 MySQL
4.2.1 创建数据库

图 4.4
4.2.2 创建表

图 4.5
4.2.3 导入数据
输入指令如图 4.6:

图 4.6
结果输出如图 4.7:

图 4.7
4.2.4 查看 MySQL 中 user_log 表中的数据

图 4.8
可以看到数据已经成功从 Hive 导入到 MySQL 中了。
五、利用 Spark 预测回头客
5.1 预处理 test.csv 和 train.csv 数据集
5.1.1 新建 predeal_test.sh 脚本文件
预先处理 test.csv 数据集,把这 test.csv 数据集里 label 字段表示-1 值剔除掉,保留需要预测的数据.并假设需要预测的数据中 label 字段均为 1,也就是对应回头客的数据。
其中 if($1 && $2 && $3 && $4 && !$5)对应 test.csv 中的五个字段值。

图 5.1
5.1.2 执行 predeal_test.sh 脚本
执行 predeal_test.sh 脚本文件,截取测试数据集需要预测的数据到 test_after.csv 文件。

图 5.2
5.1.3 train.csv 文件预处理
train.csv 的第一行都是字段名称,不需要第一行字段名称,这里在对 train.csv 做数据预处理时,删除第一行

图 5.3
5.1.4 新建 predeal_train.sh 脚本文件

图 5.4
5.1.5 执行 predeal_train.sh 脚本文件
执行脚本,截取测试数据集需要预测的数据到 train_after.csv 文件。

图 5.5
5.2 预测回头客
5.2.1 启用 Hadoop
通过 Hadoop 将 train_after.csv 和 test_after.csv 两个数据集分别存取到 HDFS 中。

图 5.6
5.2.2 进入 MySQL Shell

图 5.7
5.2.3 创建回头客预测表 rebuy

图 5.8
5.2.4 启动 Spark Shell
通过 JDBC 方式连接到 MySQL 数据库获取数据生成 DataFrame。

图 5.9
Spark 启动成功:

图 5.10
5.2.5 使用支持向量机 SVM 分类器预测回头客
导入所需的包
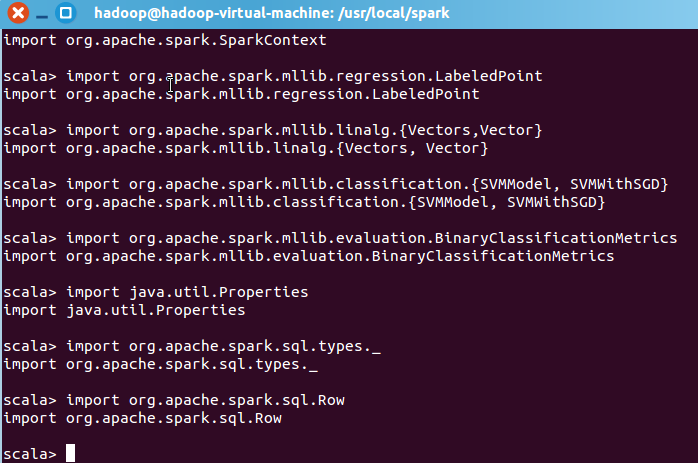
图 5.11
读取训练文本文件和测试文本文件

图 5.12
构建模型
构建数据集

图 5.13
这里通过 map 将每行的数据用“,”隔开,在数据集中,每行被分成了 5 部分,前 4 部分是用户交易的 3 个特征(age_range,gender,merchant_id),最后一部分是用户交易的分类(label)。把这里我们用 LabeledPoint 来存储标签列和特征列。LabeledPoint 在监督学习中常用来存储标签和特征,其中要求标签的类型是 double,特征的类型是 Vector。
构建模型 SVMWithSGD
SGD 即随机梯度下降算法,设置迭代次数为 1000。生成的模型用 model 变量保存。

图 5.14
评估模型
清除默认阈值,这样会输出原始的预测评分,即带有确信度的结果。

图 5.15
如果我们设定了阀值,则会把大于阈值的结果当成正预测,小于阈值的结果当成负预测。
比如我们设置阈值为 0.0:

图 5.16
此时输出结果:

图 5.17
将结果写入 MySQL 数据库
在不设置阈值的情况下将测试集结果存入到 MySQL 数据表 rebuy 中。通过以下步骤逐步完成。
清除阈值

图 5.18
将测试数据通过 map 使用 model 模型进行预测并存储在 scoreAndLabels 中

图 5.19
设置回头客数据,将数据集用空格分开

图 5.20
设置模式信息

图 5.21
创建 Row 对象,每个 Row 对象都是 rowRDD 中的一行

图 5.22
建立起 Row 对象和模式之间的对应关系,也就是把数据 rowRDD 和模式 schema 对应起来

图 5.23
创建一个 prop 变量用来保存 JDBC 连接参数,并设置驱动程序
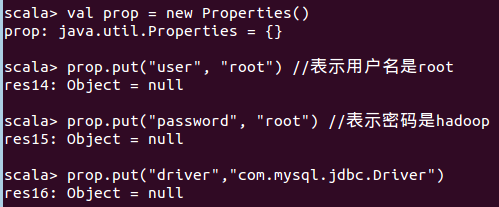
图 5.24
连接数据库,采用 append 模式,表示追加记录到数据库 dbtaobao 的 rebuy 表中
图 5.25
执行结果

图 5.26
六、利用 ECharts 进行数据可视化分析
ECharts 是一个基于 JavaScript 的数据可视化图表库,可以流畅的运行在 PC 和移动设备上,兼容当前绝大部分浏览器(IE8/9/10/11,Chrome,Firefox,Safari 等),提供直观,生动,可交互,可高度个性化定制的数据可视化图表。
由于 ECharts 是运行在网页前端,选用 JSP 作为服务端语言,读取 MySQL 中的数据,然后渲染到前端页面,因此还需要 Tomcat 作为 Web 服务器。
6.1 搭建 Tomcat+MySQL+JSP 开发环境
6.1.1 下载 Tomcat 安装包
案例中使用的是 v8.0.47,实际操作时选择的 Tomcat 版本为 8.0.53。
图 6.1
6.1.2 启动 MySQL

图 6.2
6.2 利用 Eclipse 新建可视化 Web 应用
6.2.1 在 Eclipse 中安装必要的 Web 组件

图 6.3
6.2.2 新建 Dynamic Web Project
配置 runtime 为 Tomcat v8.0。

图 6.4
6.2.3 添加 mysql-connector-java-5.1.47-bin.jar 连接驱动

图 6.5
6.2.4 利用 Eclipse 开发 Dynamic Web Project 应用
构建项目文件和代码,注意 MySQL 连接参数配置正确

图 6.6
关键功能代码:
数据库连接通过 JDBC,获取需要的数据则通过 select 指令配合 group by 完成。
连接 MySQL 数据库
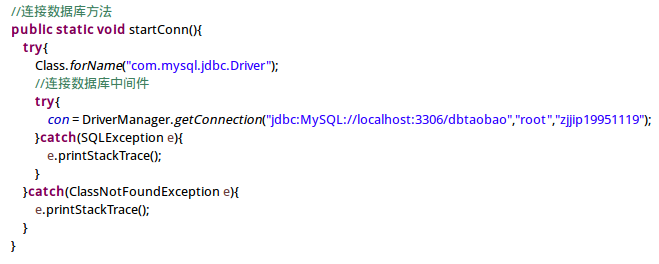
图 6.7
所有买家不同消费行为比例

图 6.8
男女买家交易量对比

图 6.9
男女买家各个年龄段交易对比
图 6.10
销量前十的商品类别对比

图 6.11
各年龄段交易比例

图 6.12
各个省份的的总成交量对比

图 6.13
6.3 启动项目
6.3.1 启动 Server
双击 index.jsp,选择 run as->run on server 开始运行项目。
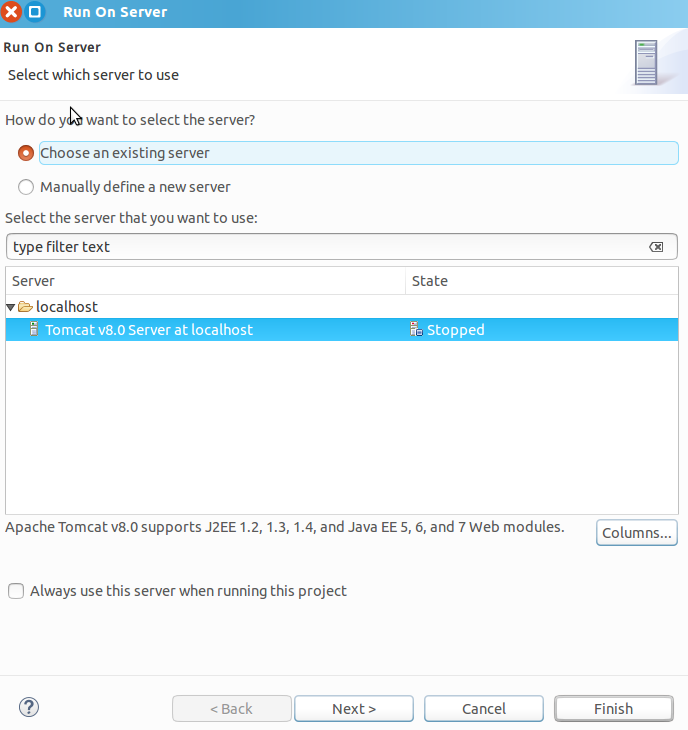
图 6.14
6.3.2 在 Web Browser 浏览运行结果
这里进行了五种统计,分别展示了所有买家消费比例、男女买家交易量比例、男女买家各年龄段交易对比、各年龄段交易比例、销量前十商品对比、全国各省成交量分布。
其中销量前十商品图相比案例中稍作了一点修改,各年龄段交易比例和全国各省成交量分布则是自己实现的,所以着重写一下这 3 个。
所有买家消费行为比例图
使用饼图进行展示,通过查询 action 字段获取,包含点击、添加购物车、特别关注、购买四种行为,其中点击比例达到八成,占绝大多数。

图 6.15
男女买家交易对比图
使用饼图展示,通过查询 gender 字段获取,包含男性、女性、未知三种分布。

图 6.16
男女买家各个年龄段交易对比图
使用散点图展示,并将男性和女性用两种颜色的图例区分开,通过查询 gender 字段、age_range 字段获取,横轴是不同年龄段,纵轴是交易记录数。

图 6.17
销售前十商品类别图
使用柱状图展示,案例教程中是只获取了销售前五的商品数据,这里为了对比更加清晰鲜明,获取的是前十的数据,在柱状图上方加了图例,并将数据按降序全部展示出来,数据通过 cat_id 字段结合 select、group by、limit 等指令完成:
select cat_id,count() num from user_log group by cat_id order by count() desc limit 10;
横轴展示的是商品 id,纵轴是销售量。可以看到第一的商品和第十的商品销量差距接近一倍,还是差别挺大的。

图 6.18
各年龄段交易比例
这个是自己根据需求实现的,案例教程中没有。主要目的是想看一下买家中什么年龄段在双十一那天最活跃,因而选择了环形图,比较清晰。获取的方式也是通过 age_range 字段:
selectage_range,count(*)numfromuser_loggroupbyage_rangedesc;由于截取的数据记录量只有 10000 条,所以差距不是很大,不过也可以看出 18~24 岁年龄段相对更活跃,这也和大学生消费需求较大有关;另外 25~29 岁年龄段也很活跃,这可能因为这部分人都工作了几年,有了一定的消费力,同时又比较年轻,接受能力强,所以消费力比较高。

图 6.19
各省份成交量对比
案例教程中有提到这个分布图,不过没有给出代码,此处自己进行了实现。主要目的是看一下全国双十一活跃度分布情况,通过 province 字段获取数据。
首先左下角是一个连续型的 visualMap 视觉映射组件,代码中会实时根据数据的分布改变 max 值和 min 值。另外为了和 china.js 的地图数据匹配,代码中也将四个直辖市(上海市、重庆市、北京市、天津市)中的“市”截掉,从而与地图中的(上海、重庆、北京、天津)匹配。
关键代码如下:

图 6.20
通过分布看出,南方的活跃度还是相对高于北方,沿海活跃度相对高于内陆,这可能和省市的经济发展状况以及人们的平均生活水平有关。

图 6.21



















 2555
2555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











