 爬虫实战:解析豆瓣Top250电影
爬虫实战:解析豆瓣Top250电影





 本文介绍如何使用Python进行网页爬取,具体案例为爬取豆瓣Top250电影的相关信息,包括电影名称、评分、推荐语等,并通过分析网页结构确定爬取策略。
本文介绍如何使用Python进行网页爬取,具体案例为爬取豆瓣Top250电影的相关信息,包括电影名称、评分、推荐语等,并通过分析网页结构确定爬取策略。
第一、找到下厨房的主页
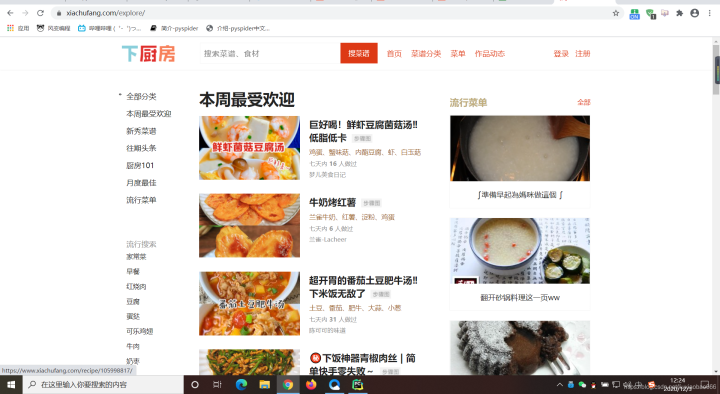
这类网址比较多,可以根据自己需要来操作。 第二、分析我们的网页,按F12进入下面页面
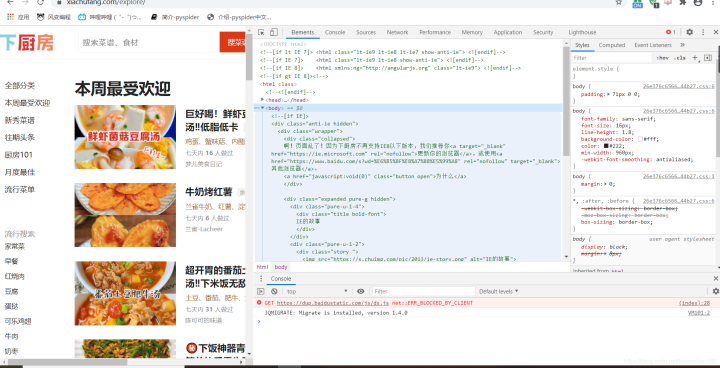
第四、定位菜单属性 找到左上角的小箭头,并点击,然后根据我们要爬取的菜品,点击即可定位到代码位置
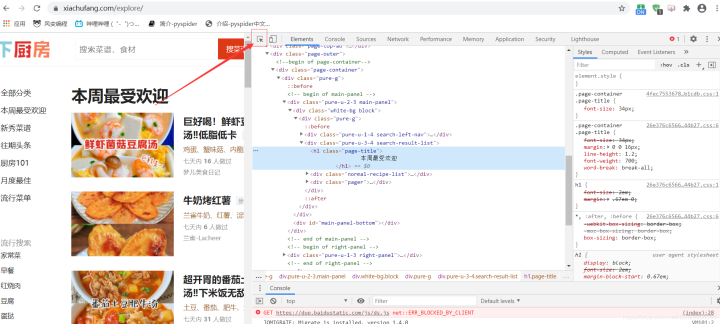
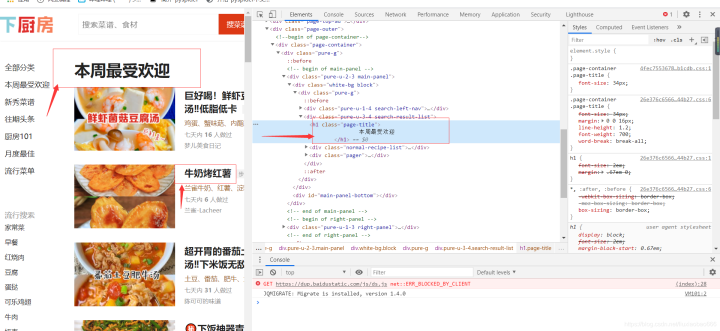
第五、接下来我们一起分析网页吧~ 进入首页 https://movie.douban.com/top250?start=0&filter= ,打开检查工具,在Elements里查看这个网页,是什么结构。点击开发者工具左上角的小箭头,选中“肖申克的救赎”,这样就定位了电影名的所在位置,审查元素中显示:标签内的文本,class属性;推荐语和评分也是如此,,;序号:,标签内的文本,class属性;推荐语;链接是标签里href的值。最后,它们最小共同父级标签,是
-
。 我们再换个电影验证下找的规律是否正确。 check后,我们再看一共10页,每页的url有什么相关呢? 第1页:https://movie.douban.com/top250?start=0&filter= 第3页:https://movie.douban.com/top250?start=50&filter= 第7页:https://movie.douban.com/top250?start=150&filter= 发现只有start后面是有变化哒,规律就是第N页,start=(N-1)*25 基于以上分析,我们有两种写爬虫的思路。 思路一:先爬取最小共同父级标签,然后针对每一个父级标签,提取里面的序号/电影名/评分/推荐语/链接。 思路二:分别提取所有的序号/所有的电影名/所有的评分/所有的推荐语/所有的链接,然后再按顺序一一对应起来。 第六、书写代码
-
# 引用requests库
import requests
# 引用BeautifulSoup库
from bs4 import BeautifulSoup
# 获取数据
res_foods = requests.get('http://www.xiachufang.com/explore/')
# 解析数据
user_agent=r'Mozilla/5.0(Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3766.400 QQBrowser/10.6.4163.400'
headers={r'User-Agent': user_agent}
res_foods = requests.get('http://www.xiachufang.com/explore/',headers=headers)
# 获取数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')
# 查找包含菜名和URL的<p>标签
tag_name = bs_foods.find_all('p',class_='name')
# 查找包含食材的<p>标签
tag_ingredients = bs_foods.find_all('p',class_='ing ellipsis')
# 创建一个空列表,用于存储信息
list_all = []
# 启动一个循环,次数等于菜名的数量
for x in range(len(tag_name)):
# 提取信息,封装为列表。注意此处使用的是<p>标签,而之前是<a>
list_food = [tag_name[x].text.strip(),tag_name[x].find('a')['href'],tag_ingredients[x].text.strip()]
# 将信息添加进list_all
list_all.append(list_food)
# 打印
print(list_all)
# 以下是另外一种解法
# 查找最小父级标签
list_foods = bs_foods.find_all('div',class_='info pure-u')
# 创建一个空列表,用于存储信息
list_all = []
for food in list_foods:
# 提取第0个父级标签中的<a>标签
tag_a = food.find('a')
# 菜名,使用strip()函数去掉了多余的空格
name = tag_a.text.strip()
# 获取URL
URL = 'http://www.xiachufang.com'+tag_a['href']
# 提取第0个父级标签中的<p>标签
tag_p = food.find('p',class_='ing ellipsis')
# 食材,使用strip()函数去掉了多余的空格
ingredients = tag_p.text.strip()
# 将菜名、URL、食材,封装为列表,添加进list_all
list_all.append([name,URL,ingredients])
# 打印
print(list_all)
第七、展示运行结果 当然这里我们可以把它保存下来,这里信息量不是特别大,也可以不用保存,减少操作 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
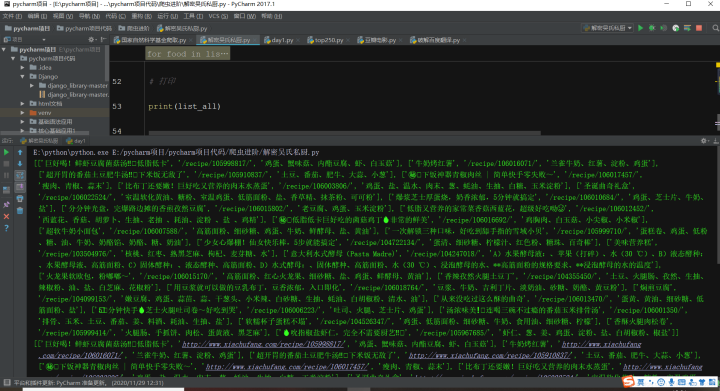

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









