




 本文介绍了如何利用XPath技术抓取安居客网站的住房信息,同时提供了使用Ruby处理数据并将其保存到CSV和XLSX文件的方法。在操作过程中遇到的网址验证问题也进行了提示,只需手动验证即可解决。
本文介绍了如何利用XPath技术抓取安居客网站的住房信息,同时提供了使用Ruby处理数据并将其保存到CSV和XLSX文件的方法。在操作过程中遇到的网址验证问题也进行了提示,只需手动验证即可解决。


温馨提示:报错了就百分之九十九是网址需要手动验证,就请移步去点击验证啦!(这里用了csv跟xsxl两种保存方式,任选其一即可!)
# -*- coding: utf-8 -*-
"""
Created on Tue Oct 27 18:27:21 2020
@author: Yuka
利用Lxml库,爬取前10页的信息,具体信息如下:
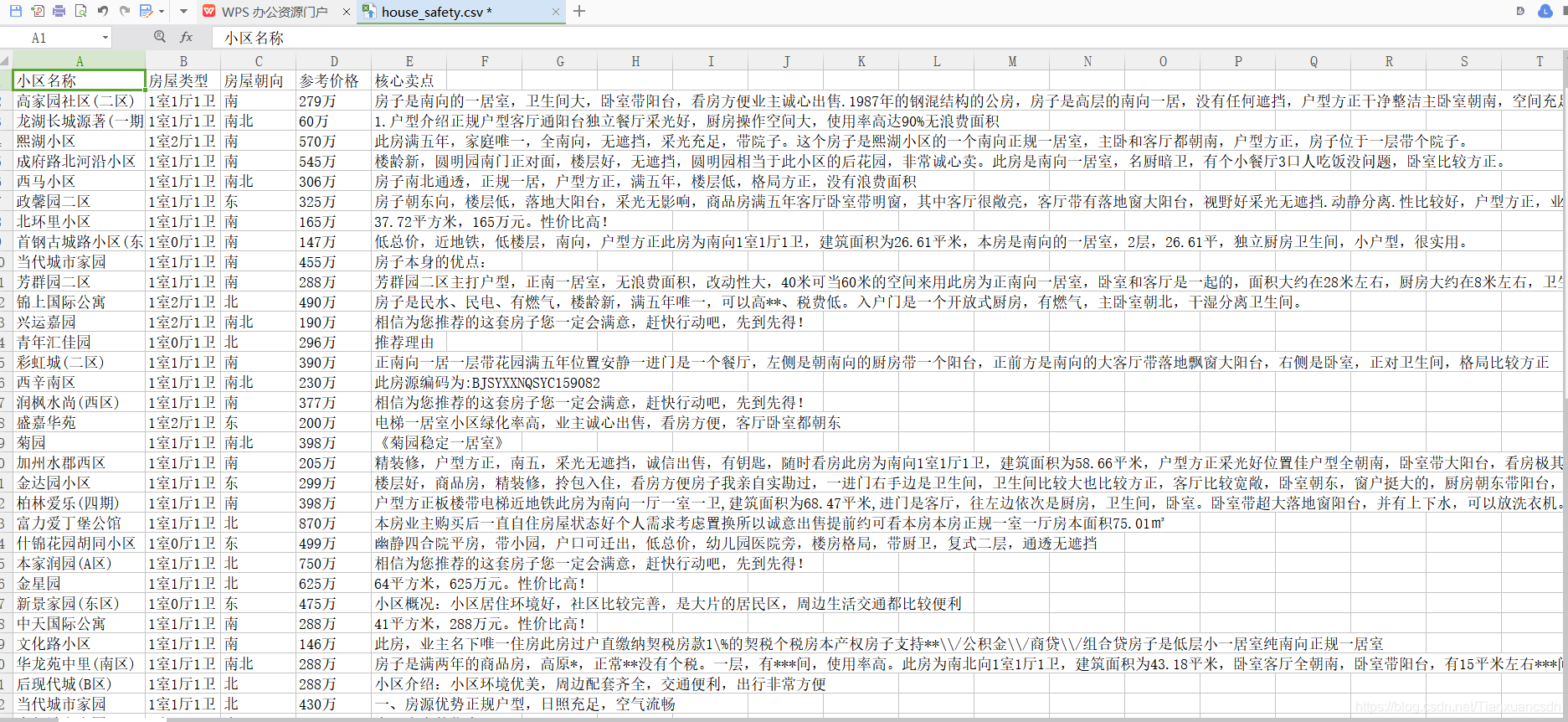
进入每个房源的页面,爬取小区名称、房屋类型、房屋朝向、参考月供和核心卖点,把它们存储到CSV文件中。
"""
from lxml import etree
import requests
import time
import re
import csv
import xlwt
lst = [['小区名称','房屋类型','房屋朝向','参考价格','核心卖点']]
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36"
}
def get_url(url):
res = requests.get(url=url,headers=headers).text
#print(res)
parse_url(res)
def parse_url(res):
html = etree.HTML(res)
links = html.xpath('//ul[@id="houselist-mod-new"]/li/div[2]/div[1]/a/@href')
get_info(links)
def get_info(urls):
for url in urls:
res = requests.get(url=url,headers=headers).text
links = etree.HTML(res)
address = links.xpath('//ul[@class="houseInfo-detail-list clearfix"]/li/div[@class="houseInfo-content"]/a/text()')[0]
if len(address) >= 1:
address = address
else:
address = "NAN"
house_type = links.xpath('//ul[@class="houseInfo-detail-list clearfix"]/li[2]/div[@class="houseInfo-content"]/text()')[0].replace('\n','').replace('\t','')
house_to = links.xpath('//ul[@class="houseInfo-detail-list clearfix"]/li[8]/div[2]/text()')
if len(house_to) >= 1:
house_to = house_to[0]
else:
house_to = "NAN"
house_month_pay = links.xpath('//div[@class="basic-info clearfix"]/span[1]//text()')[0] + "万"
sales_core = links.xpath('//div[@class="houseInfo-item-desc js-house-explain"]/span/text()')[0]
lst.append([address,house_type,house_to,house_month_pay,sales_core])
def save_xlsx(lst):
book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('sheet1')
for i in range(len(lst)):
for j in range(len(lst[i])):
sheet.write(i,j,lst[i][j])
book.save('C:/Users/小米帅哥/Desktop/house_safety.xlsx')
def save_csv(lst):
with open('C:/Users/小米帅哥/Desktop/house_safety.csv','w+',encoding='utf-8',newline='') as f:
writer = csv.writer(f)
writer.writerows(lst)
if __name__ == '__main__':
urls = ["https://beijing.anjuke.com/sale/p{}/".format(i) for i in range(1,11)]
for url in urls:
get_url(url)
print(url+"加载完毕")
save_csv(lst)
save_xlsx(lst)
time.sleep(2)
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172

















 602
602



 到【灌水乐园】发言
到【灌水乐园】发言







