




 本文介绍了如何使用Python3和Anaconda搭建环境,解决环境变量和网络问题。详细讲解了如何手动获取微博cookie并设计代码爬取文字、图片和表情。提供了完整的使用说明和效果展示,包括修改cookie、设置爬取范围以及保存结果的步骤。
本文介绍了如何使用Python3和Anaconda搭建环境,解决环境变量和网络问题。详细讲解了如何手动获取微博cookie并设计代码爬取文字、图片和表情。提供了完整的使用说明和效果展示,包括修改cookie、设置爬取范围以及保存结果的步骤。
- 搭建环境
- 代码设计
- 使用说明及效果展示
一、搭建环境
1. 软件版本
Python3.7.4
Anaconda3
2. 环境搭建问题
- 配置Anaconda环境变量
问题:anaconda未设置在环境变量里,导致使用pip下载python自带的库时无法下载到对应的路径进行使用。
解决:在电脑的环境变量中添加anaconda的路径。 - 使用pip网络问题
问题:因为网速过慢的原因导致无法正常使用pip进行更新以及python库的下载。
WARNING: pip is configured with locations that require TLS/SSL,however the ssl module in Python is not available.
解决:输入命令改为pip install xxx -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com,使用豆瓣源进行下载。
二、代码设计
1. 获取cookie
在网上查阅了很多的资料之后,我实现了模拟登陆获取cookie的方法,但是目前仍不能通过模拟登陆获取的cookie进行微博平台的连接和数据获取,所以在此我们的cookie是通过手动登陆微博平台后所获得的。
(模拟登陆获取cookie的方法网上很多,在此不做具体说明了)
爬取平台:微博 www.weibo.cn
获取cookie:使用用户名+密码登录www.weibo.cn 后,点击键盘F12 进入控制台界面。在network中找到名为weibo.cn的记录,点击查看里面的cookies。
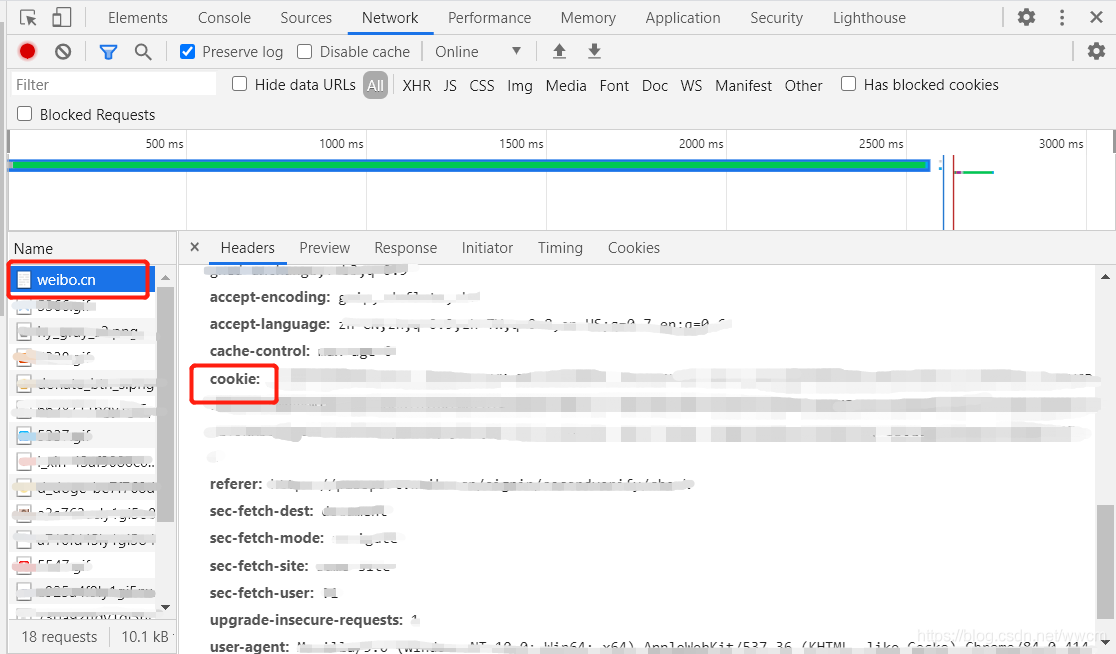
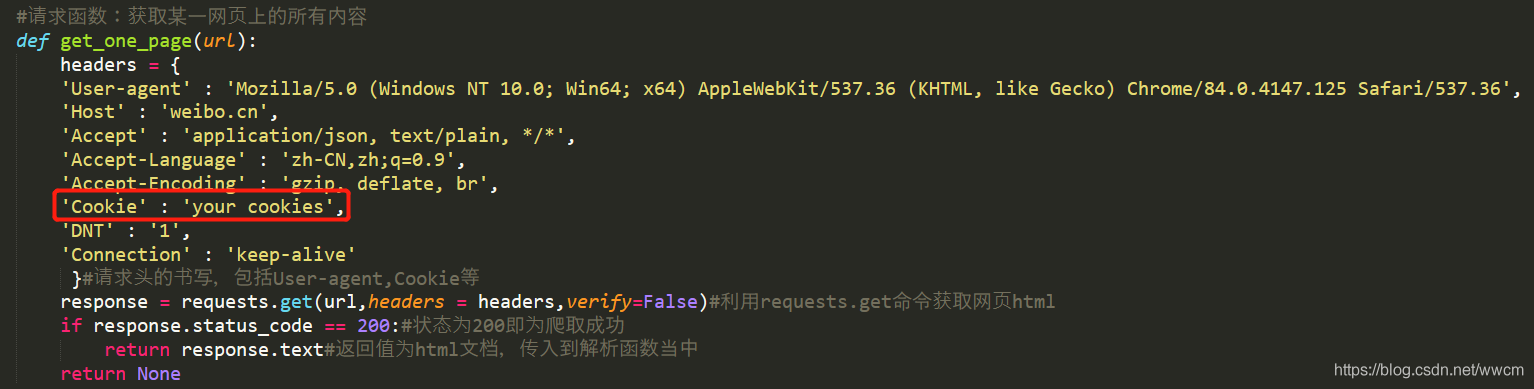
2. 爬取数据
- 爬取文字
该函数主要是用来爬取文字内容,其中省略了部分对于冗余字符的处理。
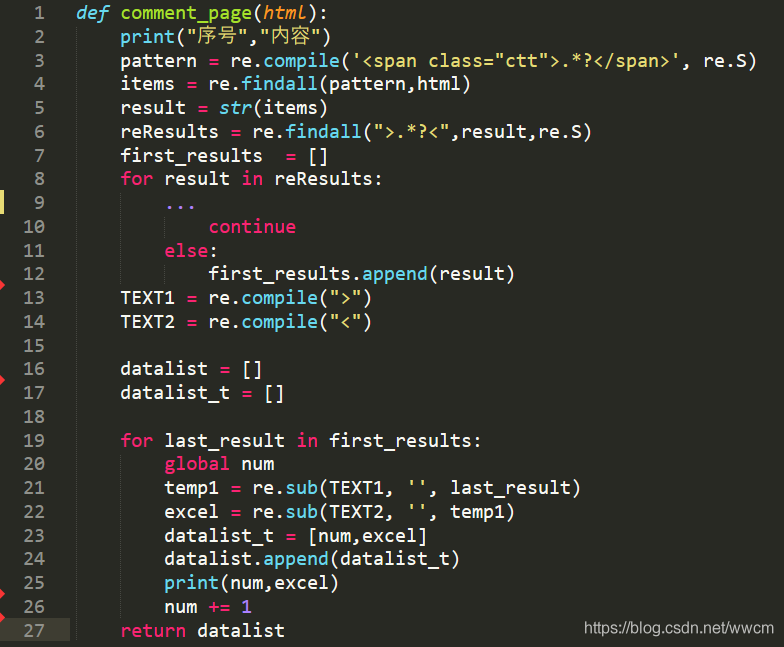
- 爬取图片
该函数主要是用来爬取图片内容,其中根据微博图片/评论图片的不同,对于标签的筛选不同。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









