




 本文详细解析了爬取boss直聘数据过程中遇到的挑战,包括动态网页解析、目标请求URL的获取、设置请求头以绕过反爬机制等。通过设置多个请求头参数,成功模拟浏览器行为,避免被网站识别为爬虫。
本文详细解析了爬取boss直聘数据过程中遇到的挑战,包括动态网页解析、目标请求URL的获取、设置请求头以绕过反爬机制等。通过设置多个请求头参数,成功模拟浏览器行为,避免被网站识别为爬虫。
概述
boss直聘(https://www.zhipin.com/)是现在互联网招聘比较火热的一个网站,本篇文章主要是针对爬取boss直聘数据遇见的一些问题进行解析。
为什么要爬取boss直聘?
哈哈哈,当然是因为简单,啪,原因如下:
(1)动态网页,爬起来难度更大,讲起来更有内容;
(2)与一般情况不同,我们所需内容通过get请求获取不了,需进行页面分析。
1、网页解析(寻找目标请求网址)
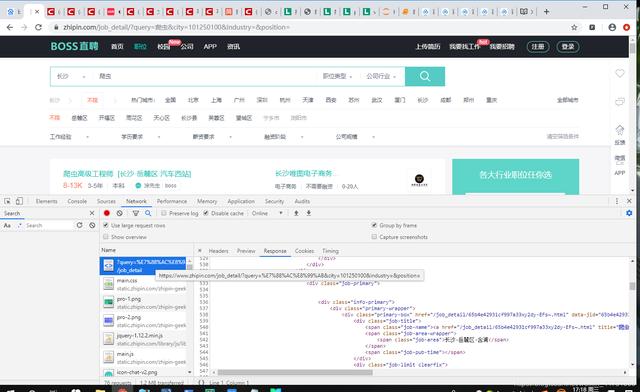
boss直聘比起其他的动态网址爬取,我自我感觉是最简单的,哈哈,因为,目标请求网址很容易就能找到,它的位置就在第一个,然后我们打开header
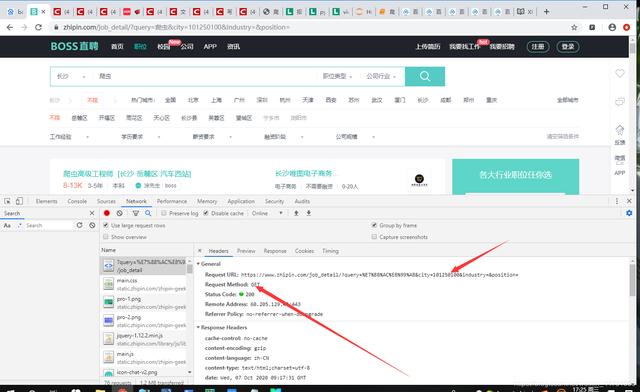
我们很容易就能得到它的请求网址
url = “https://www.zhipin.com/job_detail/?query=%E7%88%AC%E8%99%AB&city=101250100&industry=&position=”
在此我们需要注意到,它的请求方法是GET,因此我们在后面爬取需要将它的请求方法设置为GET。
对网站进行解析完后,接下来我们写爬虫
2、 爬虫
1.先导入我们所需的包
from urllib import request from urllib import parse 12
url = "https://www.zhipin.com/job_detail/?query=python&city=101250100&industry=&position=" 1
2.设置请求头header:
为啥要
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3688
3688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









