



01 核心内容
- 发布Qwen3 系列
主要包括Dense和MoE架构的模型,其中:
-
6个Dense模型,即 Qwen3-0.6B、Qwen3-1.7B、Qwen3-4B、Qwen3-8B、Qwen3-14B 和 Qwen3-32B
-
2个 MoE 模型,Qwen3-30B-A3B 和 Qwen3-235B-A22B。其中模型 Qwen3-235B-A22B,共有 235B 个参数,有 22B 个激活参数。
- 关键创新点
-
将think模式(用于复杂、多步推理)和no think模式(用于快速的响应)集成到一个统一的框架中。目的是消除通用模型和专用推理模型之间的切换,或者说将这种模型之间的切换转为模式之间的切换
-
引入了思维预算机制,允许用户在推理过程中自适应地分配计算资源,从而基于任务复杂性平衡延迟和性能。简单来说就是,当模型的思考时长达到用户定义的阈值时,手动停止思考过程,并插入停止思考的指令,模型将根据此前积累的推理过程生成最终响应。
-
多语言能力得到有效提高,涵盖多达 119 种语言和方言。
- 结论
-
Qwen3 在不同的基准测试中取得了最先进的结果,包括代码生成、数学推理、代理任务等的任务,与更大的 MoE 模型和专有模型相比具有竞争力。
-
与其前身 Qwen2.5 相比,Qwen3 将多语言支持从 29 种扩展到 119 种语言和方言
02 模型架构
- Dense model
Qwen3 密集模型的架构类似于 Qwen2.5 ,包括:
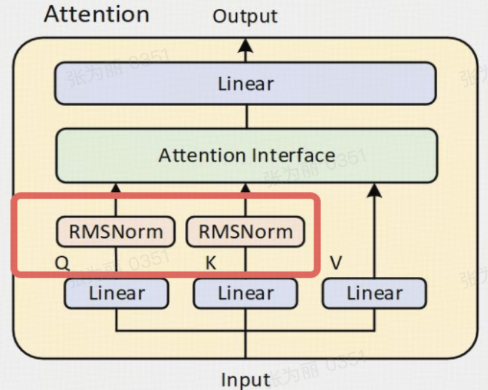
- 使用 GQA、SwiGLU、RoPE 和 RMSNorm
- 删除了 Qwen2 中使用的 QKV 偏差
- 将 QK-Norm 引入注意力机制,来确保 Qwen3 的稳定训练
- MoE model
Qwen3 MoE 模型与 Qwen3 Dense模型的基本架构是一样的:
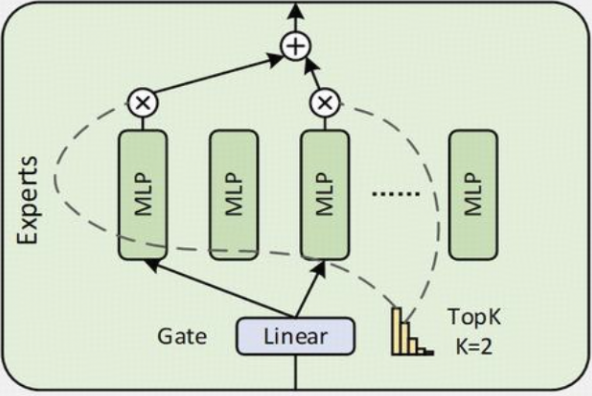
- 与Qwen2.5-MoE一样,均实现了细粒度专家分割。Qwen3 MoE 模型共有 128 个专家,每个token有 8 个激活专家
- 与 Qwen2.5-MoE 不同的是,Qwen3-MoE 去掉了共享专家
- 采用全局批量负载平衡损失来鼓励专家专业化
结构图:
具体来说:
- Qwen3 的 MoE 结构是一种稀疏 MoE 实现。它用一个包含多个(num_experts 个)小型 MLP(Qwen3MoeMLP)专家和一个门控网络(gate)的块(Qwen3MoeSparseMoeBlock)替换了传统 Transformer 中的密集 MLP 层。
- 门控网络为每个 Token 选择最相关的 top_k 个专家,并将 Token 的计算任务加权分配给这些专家。最后,将加权后的专家输出组合起来形成该层的最终输出。这种方式允许模型在保持(甚至降低)每个 Token 推理计算量的情况下,显著增加模型的总参数量(通过增加专家数量),从而可能提升模型的容量和性能。
03 训练
Pre-training
- 扩展训练数据的办法
- 对Qwen2.5-VL进行微调来从广泛的 PDF 文档中提取文本
- 使用特定领域的模型生成合成数据: 利用Qwen2.5-Math生成数学内容和Qwen2.5-Coder生成代码相关数据
- 三阶段训练
(1)第一阶段:模型在大约 30 万亿 个tokens上进行训练,来构建一般知识基础。
(2)第二阶段:在知识密集型数据上进行训练,以增强科学、技术、工程和数学 (STEM) 和编码等领域的推理能力。
(3)第三阶段:模型在长上下文数据上进行训练,将其最大上下文长度从 4,096 增加到 32,768 个token。
Post-training
1.主要目标
(1)学习思考控制:涉及到“非思考”和“思考”模式两种不同的模式的集成,让用户可以灵活选择模型是否参与推理,并通过指定思考过程的tokens长度来控制思考的深度。
(2)实现强弱蒸馏:旨在简化和优化轻量级模型的Post-training过程。通过利用large-scale模型的知识来降低了构建smaller scale模型所需的计算成本和开发工作量。
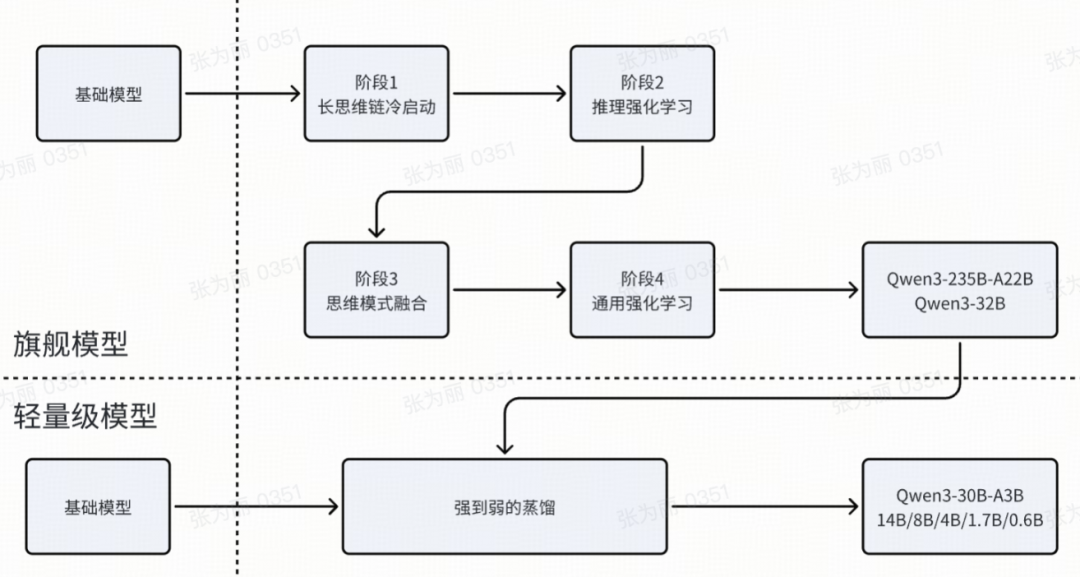
- 四个训练阶段
前两个阶段专注于培养模型的“思考”能力。后两个阶段旨在将强大的“非思考”功能集成到模型中。
每个阶段的主要任务如下:
-
长cot冷启动阶段
首先收集了一个综合数据集,利用Qwen2.5-72B-Instruct来过滤query;然后利用QwQ-32B来生成多个回复,最后人工对回复进行清洗来构建数据集用于推理模式的初始冷启动训练。
-
推理RL阶段
该阶段选用多样性的难度适中的数据进行GRPO训练。
-
思维模式融合阶段
目标:将“非思考”能力整合到先前开发的“思考”模型中。这种方法允许开发者管理和控制推理行为,同时减少为思考和非思考任务部署单独模型的成本和复杂性。
方法:对推理强化学习模型进行持续监督微调(SFT),并设计了一个聊天模板来融合这两种模式。
-
对于处于思考模式和非思考模式的样本,我们在用户查询或系统消息中分别引入了 /think和 /no think 标志。这使得模型可以根据用户的输入选择合适的思考模式。
-
对于非思考模式的样本,在模型的回答中保留了一个空的思考块< think >/n/n< /think >。这一设计确保了模型内部格式的一致性,并允许开发人员通过在聊天模板中附加一个空的思考块来防止模型进行思考行为。
-
默认情况下,模型是以思考模式运行的,所以训练数据中还包含一些虽然有思考但是用户的query里面没有/think标签的训练样本。对于更复杂的多轮对话,数据中随机插入多个/think和/no think标志到用户的query中,模型响应遵循遇到的最后一个标志。

一旦模型学会在非思考模式和思考模式中做出响应,它自然就会发展出处理中间情况的能力——基于不完整思考生成响应。基于这一特性,qwen3提出了思维预算机制。
思维预算机制实现上很简单,当模型的思考过程达到用户定义的阈值时,中断思考过程,并插入停止思考指令:
Considering the limited time by the user, I have to give the solution based on the thinking directly now.\n</think>.\n\n插入此指令后,模型将根据其到目前为止累积的推理生成最终响应。这种能力并非经过明确训练,而是作为应用思维模式融合的结果自然产生的。
-
通用RL阶段
通用RL阶段旨在广泛提升模型在各种场景下的能力和稳定性,通过建立一个复杂的奖励系统在超过20个不同的任务上进行强化学习训练,并且每个任务都有定制的评分标准。
-
模型蒸馏阶段
蒸馏包含两个阶段:
- 离线蒸馏:在初始阶段,使用/think和/no think模式生成的教师模型输出结合起来进行响应蒸馏。这有助于轻量级学生模型发展基本推理技能,并能够在这两种不同思维模式之间切换,为下一个在线训练阶段打下坚实的基础。
- 在线蒸馏:在此阶段,学生模型生成用于微调的在线序列。具体来说,采样提示,学生模型以“思考”或“不思考”模式产生响应。然后通过将学生的logit与教师模型(Qwen3-32B或Qwen3-235B-A22B)的logit对齐来最小化KL散度,从而微调学生模型。
04 评估
Pre-training评估
值得一提的是,相同计算资源下,性能超越上一代模型,甚至Qwen3-32B与Qwen2.5-72B能力相当,Qwen3-32B的参数量在不到Qwen2.5-72B一半的情况下,15个benchmark有10个超过Qwen2.5-72B,4个位居第二
Post-training评估
1. 多语言评估基准

2. 多任务评估基准
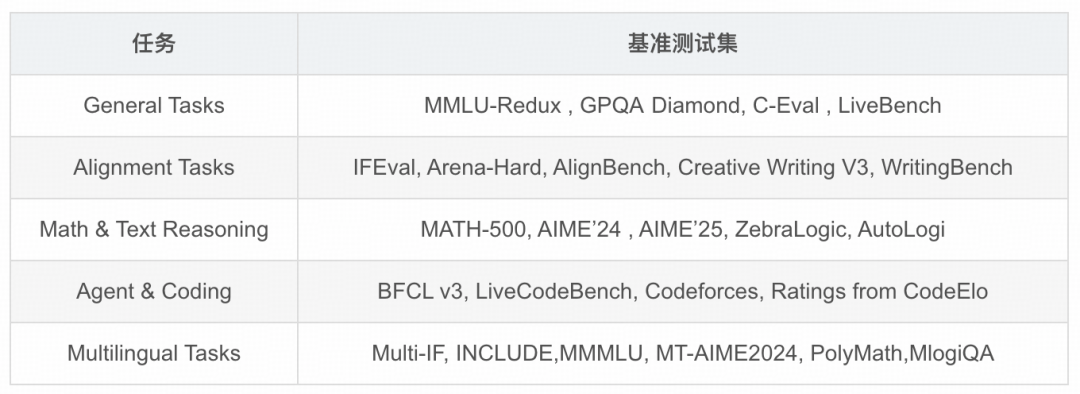
关键结论:
- Qwen3-235B-A22B,在思考模式和非思考模式下,超越了DeepSeek-R1和DeepSeek-V3等强劲基线。Qwen3-235B-A22B还与OpenAI-o1、Gemini2.5-Pro和GPT-4o等闭源领先模型高度竞争,展示了其深厚的推理能力和全面的通用能力。
- Qwen3-32B,在大多数基准测试中超越了之前最强的推理模型QwQ-32B,并且与开源的OpenAI-o3- mini表现相当。Qwen3-32B在非推理模式下也表现出色,超越了之前的Qwen2.5-72B-Instruct。
相关地址
代码地址:
https://github.com/QwenLM/Qwen3
报告地址:
https://github.com/QwenLM/Qwen3/blob/main/Qwen3_Technical_Report.pdf
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









