



DeepSeek-R1 7B、32B、671B差距有多大?
先说结论,相比“满血版”671B的DeepSeek-R1,蒸馏版差不多就是“牛肉风味肉卷”和“牛肉卷”的差距…
最近Deepseek成为了AI圈中最火爆的话题,一方面通过稀疏激活的MoE架构、MLA注意力机制优化及混合专家分配策略等创新手段,实现了高效的训练和推理能力,同时大幅降低了API调用成本,达到了行业领先水平。另一方面,Deepseek更是以7天实现用户数破亿的速度,一举超越了OpenAI的ChatGPT(ChatGPT为2个月)。
网上关于本地部署Deepseek-R1的教程,更是如同雨后春笋般出现在各个网络平台上。然而,这些本地部署教程往往会告诉你Deepseek-R1有多强大,但不会告诉你本地部署的“蒸馏版”Deepseek-R1相比“满血版”究竟有多差。
值得注意的是,目前公开发布的小尺寸的DeepSeek-R1模型,均是通过Qwen或Llama从R1中蒸馏过来,尺寸有所缩小,以适应不同性能设备调用DeepSeek-R1模型。
换句话说,无论是7B还是32B的DeepSeek-R1,本质上更像是“R1味儿”的Qwen模型,差不多是“牛肉风味肉卷”和“牛肉卷”的差距。虽然拥有前者部分特性,但更多是后者照猫画虎实现类似的推理功能。
毋庸置疑的是,随着模型尺寸的缩小,其性能也会变得更差,与“满血版”R1的差距也会更大。而今天,大模型之家就带你来看看,不同尺寸的DeepSeek-R1与“满血版”差距究竟有多大?
01
语言能力测试
在语言能力测试环节,大模型之家让7B、32B、671B的DeepSeek-R1,分别用“新年快乐万事如意”写一首藏头诗。
在这个似乎已经被各大模型“玩烂了”的场景下,在很多人看来是LLM最小儿科的场景。
然而正如那句“如果不出意外的话,就要出意外了”。在这一环节中,7B版本的R1竟然率先出现了bug!
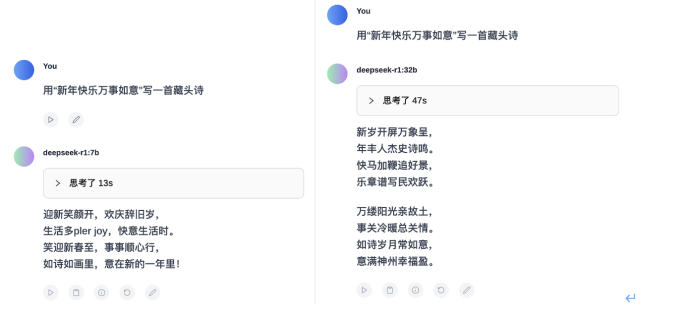
可以看到,左边的7B版本R1的输出结果既没能“藏头”,也不像一首“诗”,甚至还在文中开始说起了英语。显然,在最基础的文字生成能力上,7B并没有达到“及格线”。
相比之下,32B的R1可以正常输出文本内容,成功完成了“藏头诗”的创作。虽然从押韵方面存在些许瑕疵,但胜在七言律诗对仗工整,内容上也没有逻辑错误。

当然,效果最好的还要数“满血版”的R1,不仅对仗工整,韵脚得体,同时还给出了诗词的赏析内容。明确了“新年快乐万事如意”的“藏头诗”背后,寄寓了对新岁万事顺遂的美好祝愿。

为了探究是否是因为小尺寸导致语言能力下降,大模型之家还采用了尺寸相近的9B的GLM4用同样的提示词进行测试。结果发现在语言表达能力方面,GLM4并不输给DeepSeek-R1,可见,当R1规模小到一定程度时,其基本的文本能力方面也会受到严重影响。
02
联网总结测试
在测试完语言能力之后,我们在将R1与网络搜索相结合,测试一下不同尺寸下,对于网络内容的汇总能力。
大模型之家以一首杜甫的《登高》来测试一下R1大模型在联网状态下的表现。
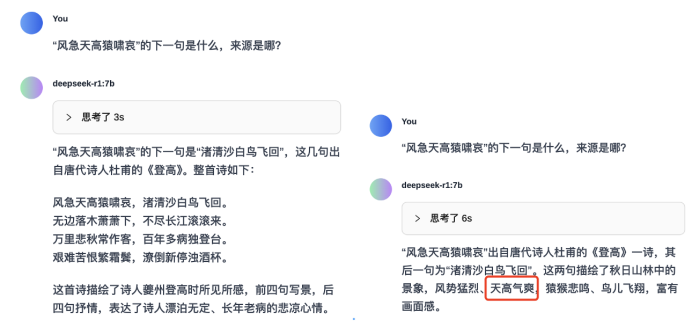
乍一看7B模型输出的表现足够优秀(左),但是实际测试中,大模型之家发现7B模型的输出结果并不稳定。偶尔会出现右边对于诗词理解出现偏差的场景,由此也能够看出,在同等的网络搜索情况下,R1模型因为尺寸缩小,在语言理解与生成能力方面受到了较大的影响。
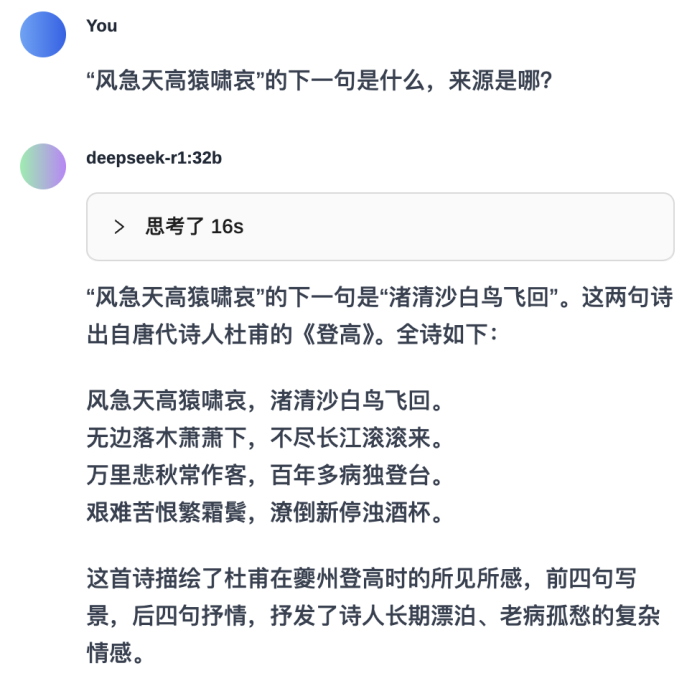
相比之下,32B的R1输出就相对稳定,虽然在输出结果上会存在显示“整首诗”和“一句诗”的左右横跳,但对于诗词内容理解的准确性有了较大提高。

而“满血版”R1依旧是表现最为优秀,不仅能够完整展示诗句内容,同时还会在答案中增加一些点评与背景陈述,增加回答的知识性与专业性。
另一组测试,大模型之家选用了目前游戏中某角色的配队,来测试7B与32B的语言理解能力。
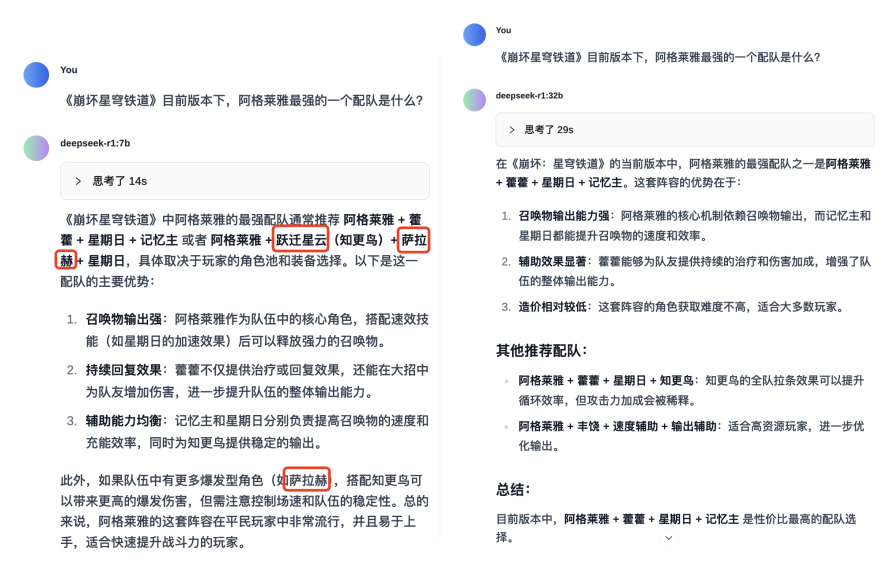
在这一组测试中,7B模型出现了游戏中不存在的角色,而32B则能够准确把握角色名称,同时,在配队的推荐理由方面,32B模型给出的内容也更加科学合理。
03
逻辑推理测试
而在测试的第二个环节,我们用一道经典的“鸡兔同笼”问题来考考不同尺寸的R1模型。提示词为:一个笼子,里头有鸡和兔子,一共有25个头和76只脚,请问笼子里边鸡和兔子各有多少只?

也许是“鸡兔同笼”的问题对于R1而言过于简单,那么换一道更难的“一个三棱柱的上底和下底为两个等腰直角三角形,每个等腰三角形的直角边长为16。直棱柱的高度等于等腰直角三角形的斜边长度。求直棱柱的表面积。”

比较令人惊讶的是,无论是7B还是32B的模型,都可以输出正确的答案。可见,在数学运算能力方面,蒸馏尽可能保留了R1模型的数学能力。
04
代码能力测试
最后,让我们再来对比一下7B与32B的代码能力。这个环节,大模型之家要求R1编写一个**“可以在浏览器上打开的贪吃蛇游戏”**。
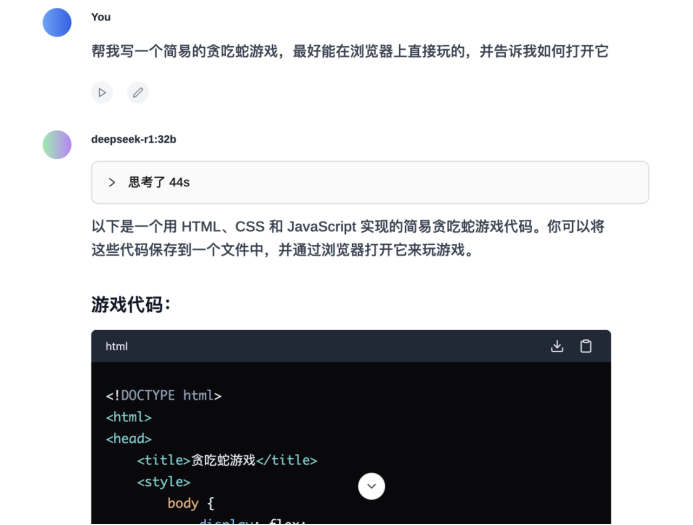
代码太长,让我们直接来看生成好的结果:

Deepseek-R1 7B的生成的游戏程序存在bug,只是一张静态的图片,蛇无法移动。

而Deepseek-R1 32B的生成的游戏程序可以正常运行,可以通过键盘方向键控制蛇的正常移动,同时面板可以正常计分。
05
本地部署门槛高,普通用户慎尝试
从一系列的测试看来,DeepSeek-R1的7B、32B,都与“满血版”671B存在比较明显的差距,因此本地部署更多是用来搭建私有数据库,或让有能力的开发者进行微调与部署使用。对于一般用户而言,无论从技术还是设备门槛都比较高。
官方测试结论也显示,32B的DeepSeek-R1大约能够实现90%的671B的性能,且在AIME 2024、GPQA Daimond、MATH-500等部分场景之下效果略优于OpenAI的o1-mini。
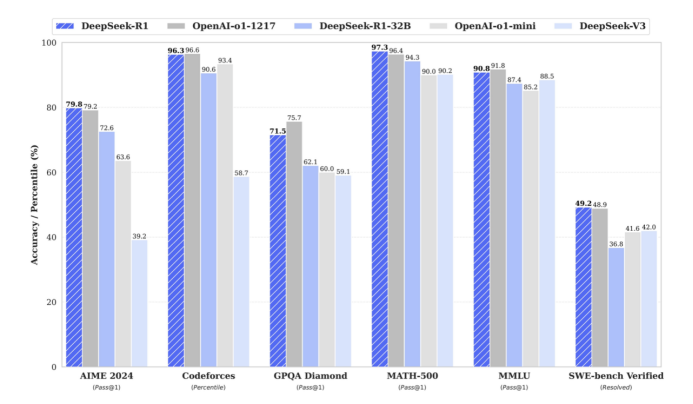
而在实际体验中,也能够看到与官方测试结论基本吻合,32B以上模型勉强尚有本地化部署的可用性,而再小尺寸的模型在基础能力方面有些过于薄弱,甚至输出结果不敌同尺寸其他模型。尤其是网络上大量的本地部署教程所推荐的1.5B、7B、8B尺寸模型,还是忘了它们吧……除了配置需求低、速度快,用起来并不理想。
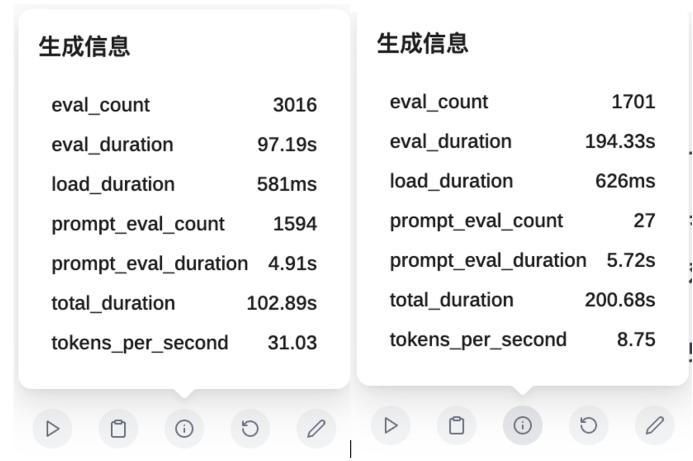 左为7B模型生成信息、右为32B模型生成信息
左为7B模型生成信息、右为32B模型生成信息
前者生成速度是后者3.5倍
所以,从结论上来说,如果你真想本地部署一个DeepSeek-R1模型,那么大模型之家建议从32B起步开始搭建,才有相对完整的大模型体验。
那么,部署32B模型的代价是什么呢?
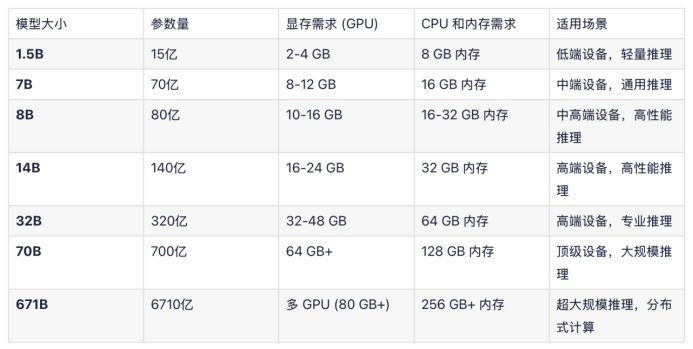 图片来源:51CTO
图片来源:51CTO
运行32B的R1模型,官方建议是64GB内存和32-48GB显存,再配合对应的CPU,一台电脑主机的价格大约在20000元以上。如果以最低配置运行,(20GB内存+24GB显存),价格也要超过万元。(除非你买API)
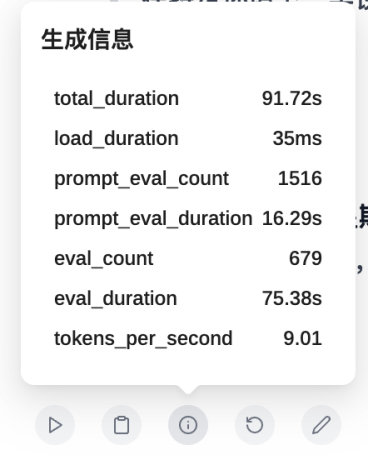
笔者所使用的设备是M2 Max的MacBook Pro(12核CPU+30核GPU+32GB统一内存),在运行32B模型时,每秒仅能输出8-9 tokens,生成速度很慢,同时整机功耗持续维持在60-80W,这也意味着,如果用电池供电持续使用大模型,仅有1个小时的使用时间。
不仅如此,本地化部署R1大模型后,还需要附加的方式为模型增加联网功能或本地化数据库,否则模型内的数据会与日新月异的互联网脱节,体验上多数情况远不及目前已经全面接入联网功能的免费大模型产品。
所以,对于大多数普通用户而言,你费劲心力搭建的本地大模型,可能真的未必有市面上主流的免费大模型产品来得简单、方便、效果好,更多只是让你过一把部署本地大模型的瘾。

DeepSeek系列模型的成功不仅改变了中美之间的技术竞争格局,更对全球范围内的科技创新生态产生了深远影响。据统计,已经有超过50个国家与DeepSeek达成了不同程度的合作协议,在技术应用和场景开发方面展开深度合作。
从DeepSeek引发的全球关注可以看出,人工智能已经成为重塑国际格局的重要力量。面对这场前所未有的科技变革,如何将技术创新优势转化为持续的竞争能力,同时构建开放包容的合作网络,将是未来面临的关键挑战。对于中国而言,这不仅是一场技术实力的较量,更是一场科技创新话语权的争夺。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















 6502
6502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









