



这篇文章继续介绍由“最初版本的RAG”,也就是由论文Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks提出来的RAG,后面被学术界归类为Naive RAG。
这个RAG版本放到如今来看已经过时了,现实中使用的RAG系统是在这个“基础”上升级了很多轮的版本。但是我个人还是觉得需要从这个“原点”出发。
因为了解了最初版本的“Naive RAG”,才能够对“RAG框架到底包含了哪些步骤?”,“每个步骤可能出现什么问题?”,“出现了这些问题有哪些可行的解决方案?”……这一连串的问题有基本的理解。
所谓“技术的演进”,很多时候就是在“改良某一个模块”中慢慢发生的。
上篇文章提到了RAG由Rtriever和Generator两部分组成。RAG利用Retriever找到最可能作为用户Query参考资料的知识库文章,把这些文章和用户的输入一起传递给下游的Generator模块生成答案。
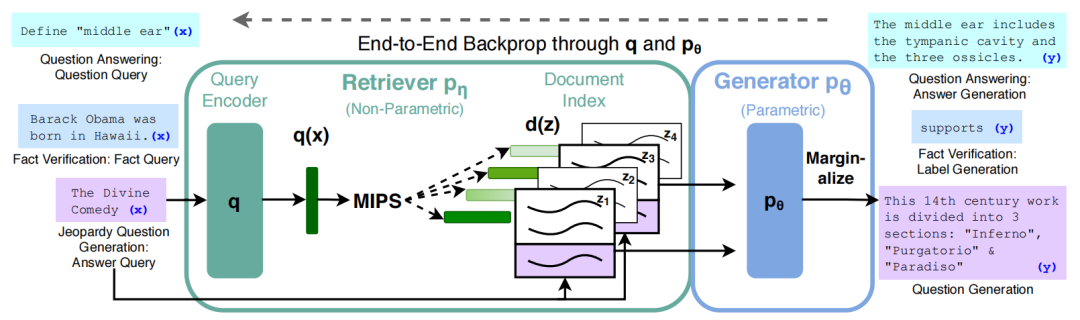
这篇文章来介绍一下RAG的Generator。
我还想分析一下为什么Naive RAG会出现 “一看就会,一做就废” 的神奇现象。以及探讨一下RAG的生命力不如以前强悍了吗?
用论文里面的话来说RAG的Generator其实选择任何一个Encoder-Decoder结构都可以。论文选用了一个已经预训练好的模型BART。因为当时这个BART在一系列生成型任务中达到了state-of-the-art。
那么按照我的风格,当然也是要介绍一下这个“BART”。
如果看完了我前面关于Transformer和BERT的介绍,BART就很好理解,它就是一个BERT的变形。
BERT模型只使用了Transformer的Encoder部分,因为只有Encoder是双向编码的,BERT也被设计来完成“编码”任务,它不是一个针对“生成”的模型。
BART就比较有意思了,它把被删除的“Transformer Decoder”又加回来了,重新变回了一个Encoder-Decoder结构。甚至它论文里就自己承认自己利用一个标准的Transformer作为基础。
那么它的独特之处在哪里呢?在于它的训练方式——它使用了**“去噪(denoising)”方法来训练模型,让训练变成了跟BERT相似的“自监督过程”**。
在上篇文章中我提到过,BERT为了实现“双向编码(Bidiretional Encoding)”,使用“完型填空”来训练大模型,避免了大模型在预测的时候被“剧透”。一整段句子中被[MASK]标识掩盖的token,就可以被看作是一种“噪音”,“完形填空”不就是“去噪任务”的一种吗?
BART是把这种“噪音”的形式给扩大化了,从单纯的利用“挖空”制造“噪音”,**增加了多种噪音的方案。**被各类“噪音”轰炸过,还能够“还原文本”的大模型,能够更好的理解和生成内容。
它使用的“噪音”有以下几种:
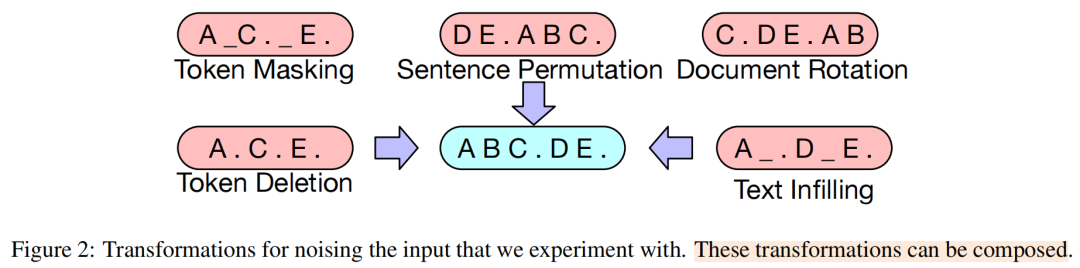
Token Masking(词元屏蔽):这个任务跟BERT一样,就是在一段文字中,随机挑选一定比例的token,使用[MASK]标识进行替换。
比如“这 个 苹 果 有 点 甜”—>“这 个 苹 果 [MASK] 点 甜”。强迫模型利用周围的上下文来预测被遮盖掉的词是什么。它主要训练模型对词汇语义和局部语境的理解能力。
Token Deletion(词元删除):在一段文字中,随机挑选一定比例的token,直接删除。
比如“这 个 苹 果 有 点 甜”—>“这 个 苹 果 点 甜”。模型需要“凭空”推断出在哪个位置、缺失了哪个词。这不仅考验词汇预测能力,还考验了模型对句子结构和语法的理解。
Text Infilling(文本填充):不是删除单个的词,而是随机采样一段连续的文本序列(Text Span),然后用一个[MASK] 标记替换掉整段序列。一段序列可能包含多个词,长度范围是“0-all”。论文使用了一个泊松分布来随机这个“长度”。
比如“这 个 苹 果 有 点 甜”—>“这 个 [MASK] 点 甜”。
模型看到单个[MASK]标记,需要生成完整的“苹 果 有” 这段文本。这个任务直接训练了模型的文本生成能力,特别是生成连贯长序列的能力,这对于摘要、对话等生成任务至关重要。
Sentence Permutation(句子排列):将一篇文档按句子切分,然后将这些句子的顺序完全随机地打乱。需要模型恢复整段文本。眼熟吗,一些高中语文记忆攻击我。
原始文本: “白露横江,水光接天。纵一苇之所如,凌万顷之茫然。”—>加噪输入: “纵一苇之所如,凌万顷之茫然。白露横江,水光接天。”
模型必须学习句子之间的逻辑关系、衔接关系和时序关系,才能将打乱的句子恢复成正确的顺序。这训练了模型对语篇连贯性(Discourse Coherence)的理解。
Document Rotation(文档旋转):随机选择文档中的一个词,然后将整个文档进行“旋转”(循环移位),使得被选中的词成为文档的开头。
比如“纵一苇之所如,凌万顷之茫然。”—>加噪输入: “万顷之茫然。纵一苇之所如,凌”
模型的任务是识别出文档真正的开头在哪里。
这5种加“噪音”的方式可以组合在一起使用。
总结来说,BART通过这5种不同粒度的“噪声任务”,从词汇级别(遮盖、删除)、短语级别(填充)到篇章级别(句子排列、文档旋转),**全方位地训练模型,**使其不仅能“理解”文本(像BERT),还能“生成”文本(像GPT),最终成为一个在各类自然语言理解和生成任务上都表现出色的全能模型。
BART在完成了预训练之后,根据下游具体的语言任务进行微调。比如BART论文里本身使用了序列分类、词元分类、序列生成、机器翻译4种具体的任务进行微调。
现在说回RAG,我们把BART当成RAG的Generator时,其实就是把预训练好的BART在**“序列生成”**这个任务上继续微调。
这个任务的微调操作跟训练Transformer完全一致。如果这里不理解朋友可以看我关于Transformer的文章:
9k字详解Transformer Decoder和啃论文易被忽略的3大技术,零基础Excel手搓邪修版
简而言之,把input传递给Encoder,Encoder最后一层的输出向量与Decoder做Cross Attention;Decoder进行预测,Decoder输出的过程是一个“自回归过程”。
RAG里面给到Generator的输入比较特别,除了“用户的输入”,还需要加上“被检索回来的知识库文章”。RAG直接把它们拼接在了一起传递给Generator。
RAG论文设计了RAG-sequence(输出10个token是参考的相同资料)和RAG-token(每输出1个token可能参考的是不同的资料)两个模型,我们分别来看一下。
- RAG-sequence:
对于RAG-sequence模型来说,接到一次“输入”,输出“N个token”都是参考相同的资料。
因为它是把被检索到的K篇文章“一篇一篇独立的喂给Generator,生成K个‘完整回答’,然后从这K个‘完整回答’里面挑选一个最优秀的返回给用户”。
但是怎么这K个回答里面找到“最好”的那一篇回答呢?要比较“最好”,当然需要有一个“打分机制”,有一个办法是“多个评委打分+加权平均”就得到了每一个回答的“分数”。但是这里没有评委呀?
我们可以这样思考,如果用户的输入真的存在一个“事实意义上的正确答案”,且前面的Retriever工作没有失误,那么无论用检索回来的哪一篇文章生成“回答”,都应该会逼近那个“正确答案”。
假如用户的问题是“黑神话是在哪一天正式发售的?”;Retriever返回了两篇文章z_1和z_2,内容分别如下:
z_1:“《黑神话:悟空》是由杭州游科互动科技有限公司开发 ,浙江出版集团数字传媒有限公司出版的西游题材单机动作角色扮演游戏。2024年8月20日,该作正式登陆PC 、PS5平台。”
z_2:“2024年6月8日,《黑神话:悟空》正式开启预购;8月13日,该作的性能测试工具在Steam商店开放免费下载;8月20日,该作正式在PC(STEAM / EPIC GAMES / WEGAME)、PS5解锁。”
真答案“2024年8月20日”,会受到这两段检索文本的“支撑”——换句话说,我用文章z_1生成了答案序列“2024年8月20日”;把参考文章换成z_2时,“这串答案序列”也会得到较高的“预测概率”,反之亦然。
所以这里给K个答案序列**“打分的评委”就是K篇参考文章**,如果一个“答案序列”得到了多篇参考文章的支持,那么这个答案是“真答案”的信心就更加充分,模型就会把“得到最多支持”的答案序列返回给用户。
如果用户的输入是x,检索回来的文章是z_1和z_2,那么Generator的生成过程是这样的:
把x和z_1拼接在一起,形成序列(z_1,x)–>输入Generator–>输出备选答案序列y_A=(y_A1, y_A2, y_A3, y_A4);
把x和z_2拼接在一起,形成序列(z_2,x)–>输入Generator–>输出备选答案序列y_B=(y_B1, y_B2, y_B3, y_B4);
模型预测答案为y_A的“信心”:模型输出y_A的概率 = 模型参考了z_1输出y_A的概率+ 模型参考了z_2输出y_A的概率
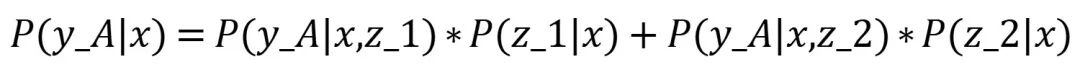
模型预测答案为y_B的“信心”:模型输出y_B的概率 = 模型参考了z_1输出y_B的概率+ 模型参考了z_2输出y_B的概率
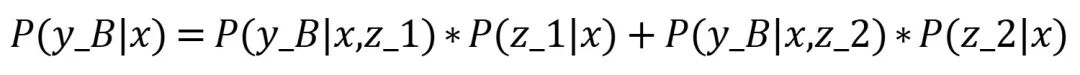
比较P(y_A|x)和P(y_B|x),把“信心高(概率高)”的那一个回答返回给用户(当然实际上是使用了Beam Search,而不是一味找概率最高的)。
可以看见虽然每个回答y_A和y_B都经过了“全部参考文档的评估”获得“信心值”,但是序列y_A和y_B“生成”的时候,都只参考了1篇文章。也就是“回答的每个token,参考资料都相同”的含义。
(有点绕,我第一次也理解了半天)
- RAG-token:
RAG-token模型的不同之处就在于:**回答的每个token,参考资料可能不相同。因为它不是一次性把“回答”生成出来,**而是“按照评分”生成1个token,然后再“评估”,再“按照评分”选择下1个token,直到输出表示“结尾”的标识。
模型依然是把每篇检索回来的文章z_1和z_2,与用户的输入x拼接在一起,只不过生成过程变成了下面这样:
假如我们所有可用的token有d_vocab个;
把x和z_1拼接在一起,形成序列(z_1,x)–>输入Generator–>输出第1个位置,每个token出现的概率。也就是输出了一个d_vocab维的向量。
把x和z_2拼接在一起,形成序列(z_2,x)–>输入Generator–>输出第1个位置,每个token出现的概率。也就是输出了一个d_vocab维的向量。
计算每个token出现在第1个位置的概率,具体的token用y_i表示:
y_i出现的概率= 参考资料是z_1时预测出y_i的概率+参考资料是z_2时预测出y_i的概率。
i的取值范围是1到d_vocab(整个词汇表大小)。
在计算完了d_vocab个概率值之后,选择概率最高的那一个token,当成是第1个位置的“正确答案”,用y_1表示。(实际上是使用了Beam Search,而不是一味找概率最高的输出,但是这里为了简化就按照每次输出概率最高的token来举例子了)
把这个选出来的“y_1”扔进Generator,做“自回归”,预测第2个位置的token:
序列(z_1,x,y_1)–>输入Generator–>输出第2个位置,每个token出现的概率。
序列(z_2,x,y_1)–>输入Generator–>输出第2个位置,每个token出现的概率。
综合计算每个token出现在第2个位置的概率,从而选出y_2……如此循环下去,直到预测到“结束”标识。
根据原论文的实验结果和后续业界的普遍认知,**RAG-Token模型的表现通常更好、更稳定。**在几个主流的开放域问答数据集(如 Natural Questions, WebQuestions, CuratedTrec)上,RAG-Token的表现几乎全面优于或持平于 RAG-Sequence。它在答案的精确匹配率(Exact Match, EM)等关键指标上得分更高,成为了当时最先进的模型之一。
RAG-Token表现更好主要在两方面:第一,它具有更强的知识综合与提炼能力(Superior Synthesis)。假如一个问题的答案分散在多篇不同的参考资料里,用RAG-token可以同时整合多篇资料的信息,而RAG-sequence做不到。
第二,它对检索错误的鲁棒性更强 (More Robust to Retrieval Errors)。如果检索到的多篇参考资料,有1篇存在错误,而Retriever恰好对那一篇文档的评价较高(P(z|x)值较大),那么RAG-sequence很可能会被带偏。
而RAG-token则不会,因为它的每个token都使用加权平均,“错误的噪音”能够被后面多篇参考资料里“正确的声音”给抑制住。它不容易被单一的、不完美的检索结果带偏。
到了这里RAG的组成模块Retriever和Generator都介绍完了。那么在这种结构下,RAG是怎么进行训练的呢?
RAG采用的是**“端到端”的训练方式**,它的Retriever和Generator都是为了特定领域问题一起调整参数的。它只检查输出和“正确答案”之间的区别,不会检查中间Retriever的检索环节。
唯一一个没有参与微调是用于把“知识库”进行编码的BERT,在论文里面作者提到,如果微调这个BERT,就需要定时更新整个知识库的索引(Document Index),这种更新开销很大(毕竟知识库文章2100w),而且在实验中发现微调提升的效果有限,所以就不调整了。
RAG原论文为模型设计了开放领域问答(Open-domain Question Answering)、抽象式问答(Abstractive Question Answering)、Jeopardy问答生成(Jeopardy Question Generation)和事实核查 (Fact Verification) ,5种语言任务。(这几种语言任务具体是什么在上篇文章有,这里我就不再赘述了)
这几种语言任务都偏向于“事实类的”问题,也就是**“存在着标准答案的问题”**,而不是那种“不存在正确答案,正面和反面都有道理的问题”。
拿开放领域问答来举例子,论文使用过的NQ数据库,一条数据会包含一个问题和对应的答案,这个答案又分为“短答案”和“长答案”。
长答案 (Long Answer):通常是包含了简短答案的整个HTML段落。
**短答案 (Short Answer):**真正回答问题的几个词或一句话,比如一个名字、一个日期、一个地点——这是Generator的生成目标。
在Naive RAG中,计算Loss时,会把Generator的输出和“短答案”进行**“字符程度的精确比较”**。也就是,如果正确答案是“黑神话:悟空”,模型的输出是“黑神话”,也是会被计算Loss的。
到这里你肯定就发现了,这种强制模型学习的方式非常**“死板”**。这种方式对于验证模型能否“找到并说出事实”这个核心能力是至关重要的第一步。但它显然无法教会模型如何去“解释和探讨一个概念”。
生活中存在着大量的“表达方式不同的‘正确’答案”;而且生活中还有更多的“根本没有正确答案”的问题。Naive RAG采取的这种训练方式也正是它在理论上“美好”,落地到工程中表现不佳的原因之一。
那么怎么解决这种问题呢?有两种思路是学术界在采用的:**“指令微调(Instruction Tuning)”**和“人类反馈强化学习(RLHF)”。
指令微调是迈向开放式问答的第一步。我们不再给模型“问题-答案对”,而是给它“指令-高质量回答对”。
工程界/学术界,构建了新的数据集,这个数据集里有非常多的复杂指令和由“人类专家”撰写的高质量回答。
比如“问题”不再是“中国的首都是哪里?”,而是“请详细解释一下什么是黑洞,它的形成过程和主要特征是什么?”
而回答则从“短小的精确字符”,变成了人类专家写的**“一个长篇的、结构清晰、逻辑严谨的回答”**。这个回答本身就是一个“范文”。
模型会用负对数似然损失来学习模仿这些高质量的回答。这种训练的目的是让模型学会输出“结构清晰的、长篇的、有逻辑的回答”。
只不过这种训练只是原本训练方法的一个“加长版本”。
还有另外一种思路更加灵活——人类反馈强化学习。这条思路的核心就是,把模型生成的多个答案,拿去给人类专家评分,并且把人类的评分反馈给模型,让模型学会“符合人类的偏好”。
具体而言,让模型生成N个答案。
把这N个答案给到人类专家,对这几个答案进行排序,从最好到最差。标注员不需要写标准答案,只需要做选择题。他们会基于答案的帮助性、真实性、逻辑性、无害性等多个维度进行排序。
用这些排序数据训练一个独立的“奖励模型”。这个模型的任务是学会预测人类会给什么样的答案打高分。它学习到的不是一个具体的答案文本,而是人类偏好的“原则”。
我们用这个奖励模型作为“裁判”,通过强化学习算法(如PPO)来微调我们的 RAG 模型。
这样一来,模型就不再被“标准字符串”约束,而是去寻找一种更加抽象的“符合人类偏好”的回答。
到这里Naive RAG的所有逻辑就已经介绍完了。RAG被提出时,学术界和工程界都对它抱有极大的热情,认为它是连接LLM与现实世界数据的关键桥梁。
因为这个给模型加“知识库外挂”的理论,真的非常简洁,适用性很广,优雅的解决了LLMs可解释性不强、知识无法快速更新等核心痛点。但是为什么到现实中,使用效果不佳呢?
根源在于一个“朴素的 RAG”系统在面对企业复杂的、非结构化的真实数据时,几乎每一步都可能出错。大家说的“效果不好”,实际上是指一个未经优化的、简单的RAG系统表现非常脆弱。
以下是Gemini老师给出的分析,我觉得说得很有道理。
- 检索(R)的脆弱性:垃圾进,垃圾出 (Garbage In, Garbage Out)
检索是 RAG 的基石,如果第一步就找错了或找不到相关的资料,那么再强大的 LLM 也无能为力。这在企业场景中尤其致命。
首先要面临的问题是**“分块的诅咒”**。为了能够高效检索,知识库文章需要被分成“小块”进行编码,但是怎么选择这个“分块的长度”是个艺术问题。
分得太长,一次检索包含太多的冗余信息,很可能让Generator懵逼,反而找不到关键信息;而分块太短,需要的答案可能就被拆到多个模块,而且语义也可能被改变,导致根本无法被检索到。比如,一份复杂的法律合同,如果按固定字数切分,可能会把关键的条款和其限定条件切开,导致系统在回答合规问题时出错。
然后需要面临的是“查询 (Query) 与文档的语义鸿沟”。用户的提问方式千奇百怪,可能与知识库中的措辞完全不同。一个简单的向量搜索可能无法理解用户的真实意图。
比如用户问“我们公司去年的研发投入回报率怎么样?”,而财报里可能只有“研发支出”和“净利润”两个独立数据。系统需要理解查询意图,并找到多个相关数据块进行计算,而不是简单地寻找“回报率”这个词。
还需要面临**“复杂文档的解析”**。现实世界企业的知识库里不只有纯文本,还有大量的表格、图表、扫描版 PDF、带格式的Word文档等。Naive RAG无法准确地提取和理解这些结构化数据。
比如用户要求“对比一下A产品和B产品在第三季度的销售额”,答案就在一张图片或一个表格里。如果系统不能解析表格,这次检索就彻底失败了。
- 生成(G)的挑战:拿到资料,但不会用
即便检索环节幸运地找到了正确的资料,生成环节也面临诸多挑战。
**Generator面临“大海捞针”与“噪音风暴”。**这一步跟“分块”策略和“检索”范围的设定都有关系。
为了保证不漏掉信息,系统可能会检索回很多相关的文档块,这被称为**“上下文填充”(Context Stuffing)**。研究表明,当LLM面临过长的上下文时,它会倾向于关注开头和结尾的信息,而忽略中间的关键部分(这被称为 “Lost in the Middle” 现象)。
比如为了回答一个技术问题,系统检索回了5篇相关的技术手册章节。正确答案在第3篇的中间段落,但LLM可能被第1篇和第4篇的无关信息干扰,最终给出一个错误的或不完整的答案。
除此之外,Generator遇到**“需要逻辑推理和上下文整合”**的问题时,它会力不从心。
比如RAG 擅长“根据资料A,回答问题B”。但如果答案需要综合多个(可能观点还略有冲突的)文档块进行复杂的逻辑推理、比较或总结,LLM常常表现得不好。
比如用户问“根据最近三年的用户反馈报告,我们产品最需要改进的功能是什么?” ——这需要系统不仅要找到三年的报告,还要能识别、分类、统计和总结报告中的核心观点,Naive RAG几乎不可能完成。
最后,Generator无法“拒绝”回答,陷入另外一种“胡编乱造”。如果检索回来的文档里根本没有答案,一个理想的RAG系统应该明确表示“根据现有资料,我无法回答这个问题”。但很多LLM在接收到不相关的上下文后,仍然会尝试基于其内部知识进行“幻觉”创作,使问题又回到了原点。
Naive RAG只是一个“学术界”的起点,纵然面临着多个问题,它给出的“增加知识库外挂的框架”仍然是一种自然的思路。
它是一种极其强大的、将LLM与外部知识连接的设计模式。
RAG包含的3个核心步骤“检索”、“增强”和“生成”,都各自有各自的优化空间。
学者们把RAG的所有环节都拆分成为**“可优化的模块”进行“升级”;还设计出更加复杂和智能的系统,来决策什么时候应该“调用”哪一类标准的“模块”,如何“自行”对每个核心步骤的结果进行“优化”,这就形成了后来更加热门的Agentic RAG**……
从这个角度来讲,RAG的生命力不如从前了吗?不如说RAG摆脱了原本的“静态死板的检索-增强-生成”固定流程,与各种智能系统融合得更加紧密,成为“上下文工程”中不可或缺的基石之一。
下一篇文章准备来介绍一下Naive RAG的进化之路——它可以拆解成几个环节,每个环节可以做什么优化,以及学者们是怎么打破“静态RAG结构”的~
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















 880
880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









