




GPU(Graphics Processing Unit,图形处理器),顾名思义,最初是专门为处理计算机图形而设计的芯片。它可以同时处理大量简单、重复的计算任务。也就是说擅长并行处理海量简单任务。
AI(尤其是当前主流的深度学习)的核心是训练和运行巨大的数学模型(神经网络)。这个过程本质上就是进行海量的数学运算,主要是矩阵乘法和加法。
这正是GPU的绝对主场!
1
为什么是GPU
🌐 因为AI计算是高度并行的:神经网络中每个神经元的计算在很大程度上是独立的,可以同时进行。GPU的“千军万马”架构完美匹配了这种“人海战术”的计算需求。
GPU是为了高吞吐量(同时完成海量任务)而设计,而CPU是为了低延迟(快速完成单个任务)而设计。
GPU的地位已经从单纯的游戏显卡,演变成了当今数字时代的 “新石油” 和 “计算世界的动力引擎”。
🔹 AI革命的物理基石
🔹 国家战略与地缘政治的核心
🔹 重塑全球科技产业格局
2
国外主流GPU
全球GPU市场风起云涌,技术创新与生态壁垒正上演一场冰与火的较量。
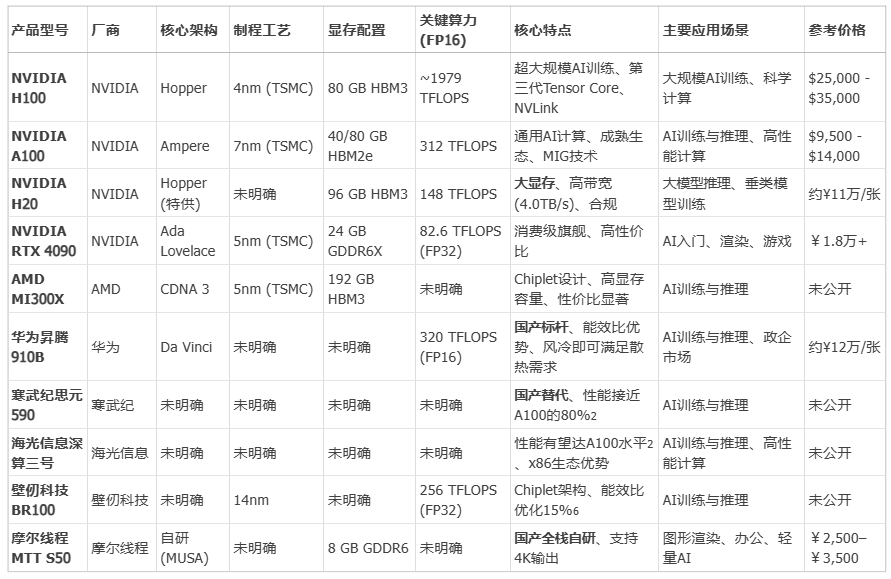
🔹 NVIDIA H100:采用Hopper架构和4nm工艺,拥有FP16算力和Transformer引擎,专为超大规模模型训练设计,生态成熟(CUDA)。价格极其昂贵,且对华禁售。适合大规模AI训练、科学计算。
🔹 NVIDIA A100:基于Ampere架构,经过市场验证,80GB HBM2e显存和MIG(多实例GPU)技术使其非常可靠,生态成熟。性能落后于H100,同样面临出口限制。适合AI训练与推理、高性能计算。
🔹 NVIDIA H20:是针对中国市场的"特供版",96GB HBM3显存是其最大亮点,适合大模型推理,符合合规要求。但计算核心数量相比H100有所减少,FP16算力为148 TFLOPS,性能上有妥协。适合大模型推理、内存密集型任务。
🔹 NVIDIA RTX 4090:消费级旗舰显卡,24GB GDDR6X显存,提供较高的性价比,适合入门AI开发。属于消费级产品,不支持多卡高速互联,可靠性不如数据中心产品,且受到管制政策影响。适合入门AI训练和高性价比微调。
3
国产GPU系列
国产GPU正处在快速发展的阶段,其优势在于自主可控和满足特定市场需求,但在绝对性能和软件生态方面与国际顶尖产品仍有差距。
🔹 华为昇腾910B:普遍被认为是当前国产AI芯片的标杆之一。实测算力可达320 TFLOPS (FP16),能效比优异,且采用风冷即可满足散热需求,降低了部署门槛和成本。构建了CANN框架生态。但受制于外部环境,先进制程获取可能受限。适合AI训练与推理,对能耗敏感的场景。
🔹 寒武纪思元590:作为国产替代方案,其性能据称接近英伟达A100的80%。寒武纪的智能芯片和处理器产品可高效支持大模型训练及推理,以及多模态人工智能任务,并支持目前市场主流开源大模型。但软件生态和开发者社区完善度是其主要挑战。适合AI训练与推理。
🔹 海光信息深算三号:性能有望达到英伟达A100的水平。最大优势在于其x86生态优势,国内90%的政务软件基于x86架构,海光芯片无需重构即可适配。但性能与最先进的国际产品仍有差距。适合AI训练与推理、高性能计算,特别是政务市场。
此外国产主要GPU产品,还有壁仞科技BR100和摩尔线程MTT S50,各有特点和优势,但其性能和生态成熟度上仍有差距。
4
选型建议
✅ 任务类型与规模
🔹超大规模训练时,如预算充足,NVIDIA H100 是当前首选。国产替代可关注华为昇腾910B、寒武纪思元590,但需考虑生态适配。
🔹 大模型推理/内存密集型应用时,NVIDIA H20 的大显存适合此场景;国产方面华为昇腾910B、寒武纪思元590也可考虑。
🔹 入门级AI研究/微调时,RTX 4090 提供了较高的性价比。
✅ 生态与兼容性
🔹 如果项目严重依赖CUDA生态和现有工具链,NVIDIA产品仍是当前最省心的选择,但需考虑获取难度和合规风险。
🔹 国产GPU多支持OpenCL等开放标准,但需仔细评估其软件栈、框架适配度、社区支持以及迁移成本。
✅ 总体拥有成本
🔹 不仅要考虑GPU的购买成本,还要考虑电力、散热、服务器、维护等长期成本。
🔹 国产GPU在某些情况下可能获得政策或补贴支持,间接降低TCO。
✅ 供应链安全与合规
🔹 在对供应链安全要求极高或必须符合国产化要求的领域,国产GPU(华为昇腾、寒武纪、海光、壁仞等)提供了选择,尽管其在绝对性能和生态成熟度上可能仍有差距。
🔹 需要密切关注国际贸易政策和法规变化。
✅ 性能与性价比的权衡
🔹 国产GPU通常在绝对性能上与国际顶尖产品有差距,但可能通过场景优化、性价比或特定优势来综合平衡选择。
6
总结
💡 当前GPU市场,NVIDIA凭借其强大的硬件性能和成熟的CUDA生态,依然在AI计算领域占据主导地位,但其高端产品对华出口受限为国产替代留下了空间,国产GPU正处于快速发展阶段。
选择GPU时,关键是要根据自己的模型规模、预算、软件生态需求、供应链安全要求以及总体拥有成本进行综合考量。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









