



前言
大型语言模型(LLMs)正在重塑我们与技术交互的方式,从对话式人工智能到代码生成、内容创作以及客户服务自动化。这个文章系列旨在从零开始带您逐步了解,从大型语言模型和Transformer的基础概念,到实际代码示例、微调、部署以及模型升级。
在第一部分,我们将:
- 解释什么是大语言模型(LLMs)以及它们为何重要
- 用简单的语言解析 Transformer 架构
- 介绍分词(tokenization)、嵌入(embeddings)、注意力(attention)机制
- 探索实际应用场景
- 分享基础代码片段,助你入门
- 什么是大型语言模型(LLM)?
大型语言模型(LLM)是一种深度学习模型,它通过海量文本数据训练而成,能够理解、生成和处理人类语言。像OpenAI的GPT和Meta的LLaMA这类模型,在以下任务中表现出色:
- 文本生成与补全
- 总结摘要
- 翻译
- 情感分析
- 代码生成
大语言模型(LLMs)中的“大”指的是它们数十亿的参数,这些参数使它们能够捕捉语言中的复杂模式。
- 大语言模型的核心组件
要真正理解大语言模型,你需要掌握三个核心概念:
- ✅ Tokenization:将文本转换为更小的单元(tokens)。
- ✅ Embeddings:将 tokens 表示为数值向量。
- ✅ Attention 机制:使模型能够专注于输入中最相关的部分。
- 简化的 Transformer 架构
Transformer 架构是几乎所有现代大型语言模型的核心。它由以下部分组成:
- Input Embeddings
- Positional Encoding 位置编码
- Multi-Head Self-Attention Layers
- Feed-Forward Neural Networks 前馈神经网络
- Output Layer 输出层
关键创新在于自注意力机制 - 模型能够根据不同单词的相关性对其赋予不同权重的能力。
直观总结如下:
1.Input Tokens → 2. Token Embeddings + Positional Encoding → 3. Self Attention + Feed-Forward Layers (Stacked N times) → 4. Output Prediction
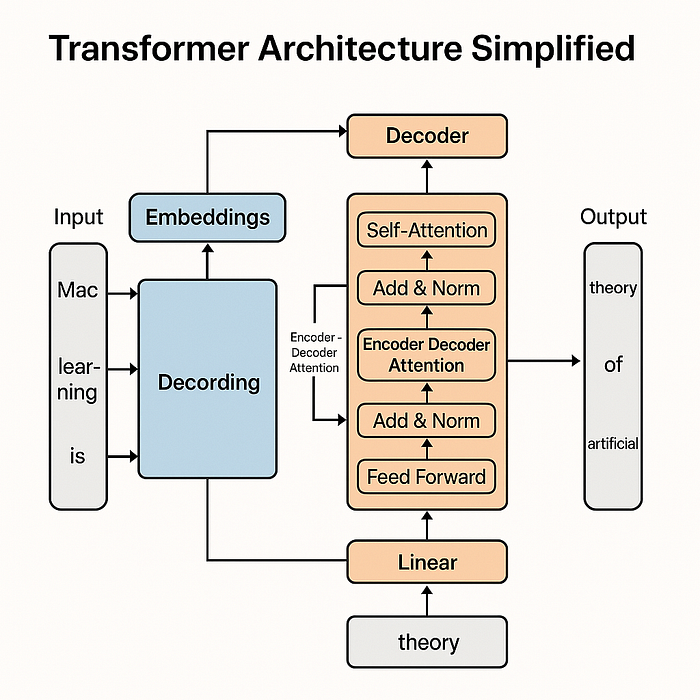
这种模块化设计使 Transformer 能够高效扩展,并捕捉文本中的长距离依赖关系。
- 实践:使用Hugging Face进行分词
让我们从使用 Hugging Face Transformers 对文本进行分词开始:
from transformers import AutoTokenizer
# Load pretrained tokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# Sample text
text = "Transformers are changing the world of AI!"
# Tokenize
tokens = tokenizer.tokenize(text)
print(tokens)
# Convert to input IDs
input_ids = tokenizer.encode(text, return_tensors="pt")
print(input_ids)
- 解释 Embeddings
Embeddings 把 tokens 映射为高维向量:
import torch
from transformers import BertModel
model = BertModel.from_pretrained("bert-base-uncased")
outputs = model(input_ids)
embeddings = outputs.last_hidden_state
print(embeddings.shape)
之后,embeddings 可以作为输入用于 Transformer 中的更高层。
- 简述 Self-Attention
注意力计算的简化版本:
import torch
import torch.nn.functional as F
# Random tensors for queries, keys, values
Q = torch.rand(1, 5, 64)
K = torch.rand(1, 5, 64)
V = torch.rand(1, 5, 64)
scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(64.0))
weights = F.softmax(scores, dim=-1)
attention_output = torch.matmul(weights, V)
print(attention_output.shape)
这就是注意力机制背后的核心思想。
- 大语言模型的实际应用场景
| Use Case | Description |
|---|---|
| Chatbots | 客户服务、虚拟助手 |
| Code Generation | 人工智能结对编程、代码建议(例如,Copilot) |
| Summarization | 法律、医疗、新闻内容摘要 |
| Translation | 高质量的多语言翻译 |
| Text Classification | 情感分析、垃圾邮件检测 |
大型语言模型(LLMs)在开发运维(DevOps)中也得到了越来越多的应用:用于自动化故障响应、生成代码片段,甚至管理持续集成/持续部署(CI/CD)工作流。
- 值得探索的工具和库
- Hugging Face Transformers:用于模型训练和部署
- PyTorch/TensorFlow:后端深度学习框架
- LangChain:用于构建由大语言模型驱动的应用程序
- OpenAI API:快速使用商业级模型
- 接下来是什么?
在第二部分中,我们将:
- 使用PyTorch从零开始构建一个基础的Transformer模型
- 实现一个训练循环
- 在小数据集上训练
这将让你亲身体验大语言模型的内部工作原理。
结语
理解大型语言模型(LLMs)的基础知识是掌握这项强大技术的第一步。在本部分中,你已经了解了什么是大型语言模型、它们的工作原理,看到了用于分词和 Embeddings 的代码,并探讨了它们在现实世界中的应用。在下一部分中,我们将更深入地研究这些模型的实际构建和训练。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









