



一、概念解读(小白向)
我们打开deepseek官网,会发现对话框之下:有两个按钮,那他们的含义如何理解🤔?最近爆火的deepseek究竟指的是哪个模型?深度思考R1与联网搜索的作用?
接下来对常用概念做一些入门性质的介绍:
1、联网搜索:
比较好理解,我们知道LLM(大语言模型)的知识是有时效性的,因为大模型知识来源于海量的离线数据训练,而一般来说,其训练数据大约滞后于其发布时间半年到一年以上。比如在 OpenAI 的模型介绍网页上,可以看到 o1 模型的训练数据截止时间为2023年十月份,而deepseek(此处指V3基座),参考其回复发现时间大约也是2023年10月。【所以对于时效性问题,LLM回答不出来实属正常。】而联网搜索,解决的就是时效性问题,当你勾选联网搜索时,你可以把其视为一个能理解你的任意自然语言问题(传统搜索引擎仅仅为关键词搜索)的AI搜索引擎。

2、深度思考(R1)
在介绍深度思考之前,我们先来了解如下常见名词的含义:
deepseek:泛指性的概念,指任意deepseek系列模型。
deepseek V3:对话模型,最新版deepseek基座模型(无深度思考能力),其指令版本具备对话能力,与gpt-4o,qwen2.5系列等模型属于同阶段模型。参数量671B,当前最强开源基座模型,但参数量巨大,完整部署大约需1300G+显存。
deepseek R1:推理模型,【也就是最近爆火的模型,由于其在相对低资源的条件下,SFT+多阶段强化学习训练出能力超强推理能力而闻名】。擅长复杂问题的推理,准确率相较于deepseek V3更高,但思考过程过长。
deepseek R1-zero:推理模型,可以理解deepseek R1的先验版本,R1-zero的训练是一个探索性的过程,它验证了RL本身对于激励base模型产生推理的能力。在这个探索结论上,才开始正式进入R1的训练。【此模型为实验性质,其能力低于deepseek R1,因而也未面向C端用户上线】
DeepSeek-R1-Distill-Qwen-xxxB:知识蒸馏版的推理模型,使用deepseek R1中间阶段的80w条训练数据,对Qwen2.5系列进行SFT指令微调的模型。(无强化学习过程,可以理解为COT思维链数据的SFT)大家平时听到的残血版,蒸馏版,大多指此版本。
二、训练原理解析
1、训练流程
Deepseek R1的训练过程可分为两阶段迭代优化,核心是通过高质量推理数据生成和RL策略提升逻辑推理能力,具体流程如下:
阶段一(Phase 1):COT数据质量提升
1.基座模型
◦使用Deepseek V3 Base(预训练模型)作为初始基座。
2.训练步骤
◦SFT训练:用初始逻辑推理数据(如COT轨迹)进行监督微调。
◦RL强化训练:进一步优化得到Model RL-1,提升推理轨迹的生成质量。
3.核心目的
◦利用Model RL-1生成更高质量的新COT数据,随后弃用Model RL-1,仅保留新数据。
阶段二(Phase 2):干净基座再训练
1.基座模型回退
◦关键策略:重新使用原始Deepseek V3 Base(非Phase 1的Model RL-1,是为了避免使用低质量数据污染的基座)。
2.数据混合
◦新COT数据:Phase 1生成的高质量逻辑推理数据使用拒绝采样的方式来筛选轨迹数据。
◦Post-training数据:加入deepseekV3非逻辑推理类数据(如通用任务),防止模型遗忘其他能力。
3.训练流程
◦再次回到base模型上,首先用这80w的新数据对它做2个epoch的sft。
◦接着执行2个阶段的RL:
▪第1阶段RL:旨在增强模型推理方面的能力。采取类似r1 zero的RL方法,使用基于规则的RM,对模型进行RL训练,以提升模型在数学、代码和逻辑方面的推理能力。(这里用的数据集应该不是那80w,是类似于zero直接构建prompt)
▪第2阶段RL:旨在针对模型的helpfulness和 harmlessness,类似于dpsk v3的训练pipeline
核心训练技巧
1.迭代数据增强
◦通过前阶段模型生成更优质数据,用于后阶段训练(类似微软rStar-Math的MSCT方法)。
2.基座模型重置
◦每轮迭代均从原始干净基座出发,避免误差累积,最大化高质量数据效用。
3.防遗忘机制
◦混合逻辑与非逻辑数据,保持模型多任务平衡性。
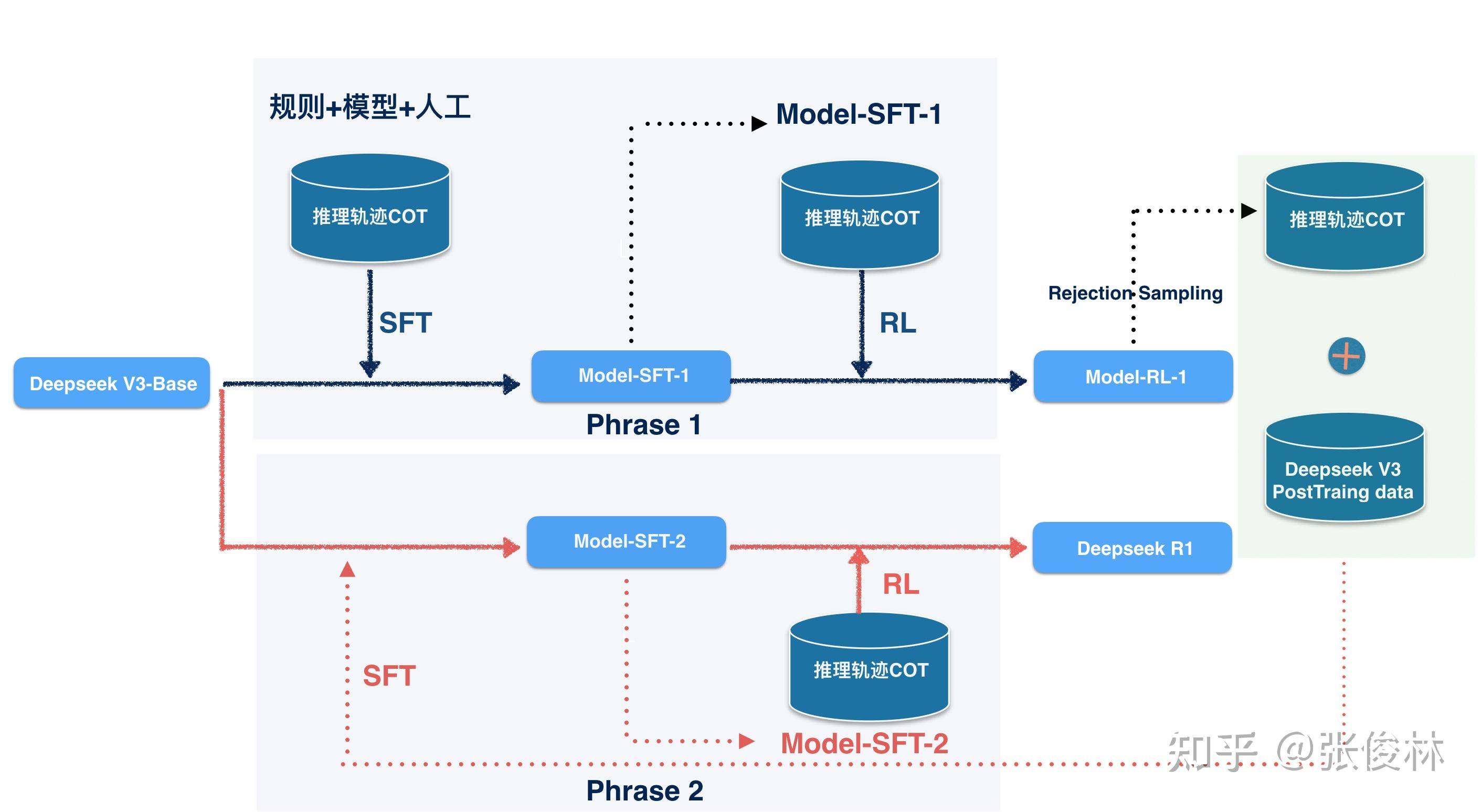
参考图片来源:复刻OpenAI O3之路:Deepseek R1、Kimi K1.5及MCTS技术路线探析-知乎
2、DeepSeek R1 的技术价值思考:
1、r1 zero证明了无需sft,直接用base model做单纯的RL,已经可以取得强大的reasoning能力。这里单纯的RL是指:没有显式提供一些真正的long cot数据让模型去背去学,我只是在sys_msg里告诉模型先思考,再回答。接着通过RL一轮又一轮的训练,模型产出的responses越来越长,且在某个时刻出现了自我评估和反思的行为。
2、随着训练steps的增加,r1 zero倾向于产出更长的response(long cot),并且还出现了反思行为。这些都是在没有外部干预的情况下,r1 zero模型在训练中自我进化的结果。
3、对于小模型,不需要依然RL,只用蒸馏就可以使得其推理能力得到显著提升(对于大模型会是怎么样的,技术报告中没有提)
三、deepseek复现-实践项目
1、高考数学测试
测试数据:《2024年高考新课标一卷数学真题》,一共19道题,满分150分。
测试方式如下
1.Claude sonnet 3.5 (直接把题目输入给模型)
2.Claude sonnet 3.5 + COT
3.Claude sonnet 3.5 + MCTS+ COT(Agent模式)
4.O1-preview (直接把题目输入给模型)
5.Qwen2.5-Math-72B (直接把题目输入给模型)
6.Deepseek-R1 (直接把题目输入给模型)
7.Deepseek-R1-Distill-Qwen-32B (直接把题目输入给模型)
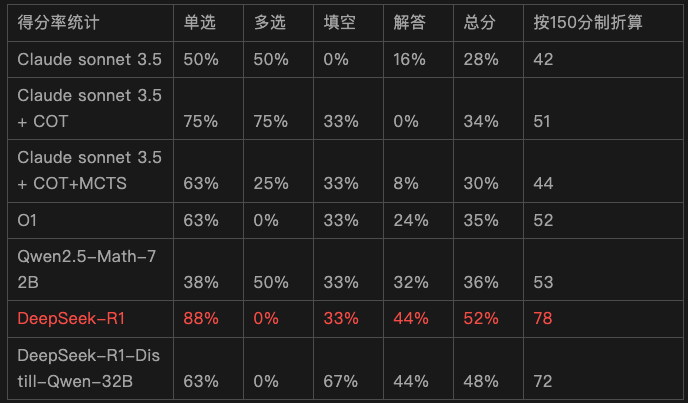
详见:
https://mp.weixin.qq.com/s/jUIHibLdO59fWTAKFMX79A
2、deepscaler
UC伯克利的研究团队基于Deepseek-R1-Distilled-Qwen-1.5B,通过简单的强化学习(RL)微调,得到了全新的DeepScaleR-1.5B-Preview。在AIME2024基准中,模型的Pass@1准确率达高达43.1% ——不仅比基础模型提高了14.3%,而且在只有1.5B参数的情况下超越了OpenAI o1-preview!

Deepseek-R1发现,直接在小型模型上用强化学习,效果不如知识蒸馏。在Qwen-32B模型上做对比实验,强化学习只能让AIME测试的准确率达到47%,但只用知识蒸馏就能达到72.6%。不过,要是从更大的模型中,通过蒸馏得到高质量的SFT数据,再用强化学习,小模型的推理能力也能大幅提升。研究证明了这一点:通过强化学习,小型模型在AIME测试中的准确率从28.9%提高到了43.1%。
https://github.com/agentica-project/deepscaler
3、Logic-RL
中科大某大四科研小组复现,在Logic Puzzle Dataset数据集下。
证明了:原始基座模型在测试集上只会基础的step by step逻辑。 但在无 Long CoT冷启动蒸馏,三阶段Rule Based RL后,模型学会了:
- 迟疑 (标记当前不确定的step等后续验证),
- 多路径探索 (Les't test both possibilities),
- 回溯之前的分析 (Analyze .. statement again),
- 阶段性总结 (Let's summarize, Now we have determined),
- Answer前习惯于最后一次验证答案(Let's verify all statements)
https://github.com/Unakar/Logic-RL
4、Open R1
国外huggingface团队复现,旨在做到完全开放复现 DeepSeek-R1,补齐 DeepSeek 所有未公开的技术细节。
https://github.com/huggingface/open-r1
四、本地实践
1、本地化部署与产品使用
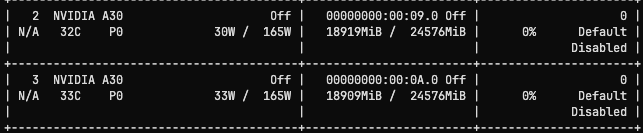
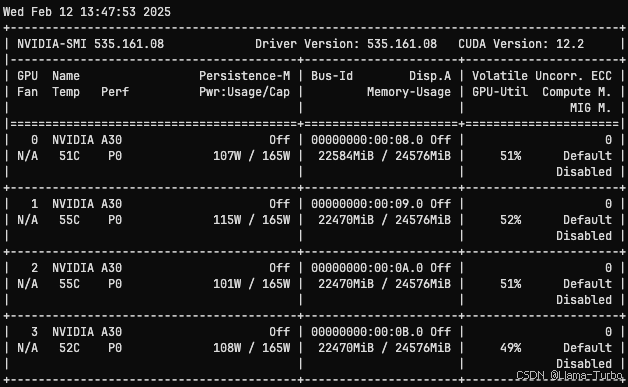
我们在RAG知识增强的问答助手5starAI项目上实践。使用VLLM部署了DeepSeek-R1-Distill-Qwen-32B-4bit版本,显存占用如下。速度实测约50Tokens/S。
RAG场景,在Llamaindex框架下集成,部分代码如下:

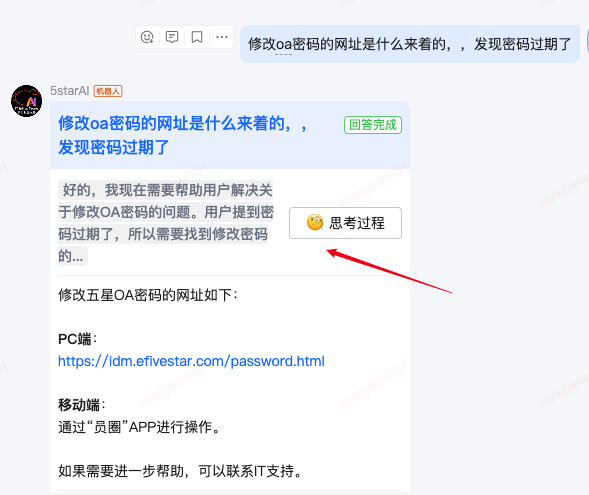
以下是应用效果截图,含思考过程:(ps欢迎大家来尝试使用或者合作,京Me搜索机器人5starAI)
2、强化学习训练实践
由于本地有text2SQL前置实践经验【http://xingyun.jd.com/shendeng/article/detail/31804?forumId=38&jdme_router=jdme://web/202206081297?url%3Dhttp%3A%2F%2Fsd.jd.com%2Farticle%2F31804】,并积累了相关数据集,我们计划在text2SQL任务上,使用DeepSeek-R1-Distill-Qwen-1.5B为基座(资源限制),参考https://github.com/agentica-project/deepscaler的项目经验,进行RL训练。目前正在尝试复现该项目效果中,后续将更新。
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









