




一、引言
1.1 文档概述
Dify作为一款低代码/无代码LLM应用开发平台,正在迅速改变AI应用的开发模式。本手册旨在全面梳理Dify的应用场景,深入分析DSL(领域特定语言)源码,并提供实用的优化建议,帮助开发者快速构建高质量的AI应用。
1.2 文档结构
本文基于工作中遇到的AI应用案例,以及对多个GitHub仓库的深入分析,涵盖了教育、医疗、制造等多个行业的应用案例,主要结构如下:
- • 行业应用场景分析
- • 核心技术深度解析
- • 性能优化策略
- • 常见问题解决方案
- • 最佳实践指南
二、应用场景分类
2.1 教育领域
2.1.1 数学错题本系统
2.1.1.1 核心功能需求分析
自动收集、识别和整理学生的数学错题,支持PDF和图片格式的错题上传,实现错题的分类存储和复习提醒。
2.1.1.2 系统实现逻辑架构
-
- 使用开始节点接收用户上传的文件(PDF或图片)
-
- 通过模板转换获取文件类型
-
- 使用条件分支区分PDF和图片文件处理流程
-
- 对PDF文件使用PDF转PNG转换器进行格式转换
-
- 调用多模态LLM模型进行OCR识别,提取错题内容
-
- 使用变量聚合器整合识别结果
-
- 通过代码执行节点将错题信息写入数据库
-
- 生成复习计划和提醒
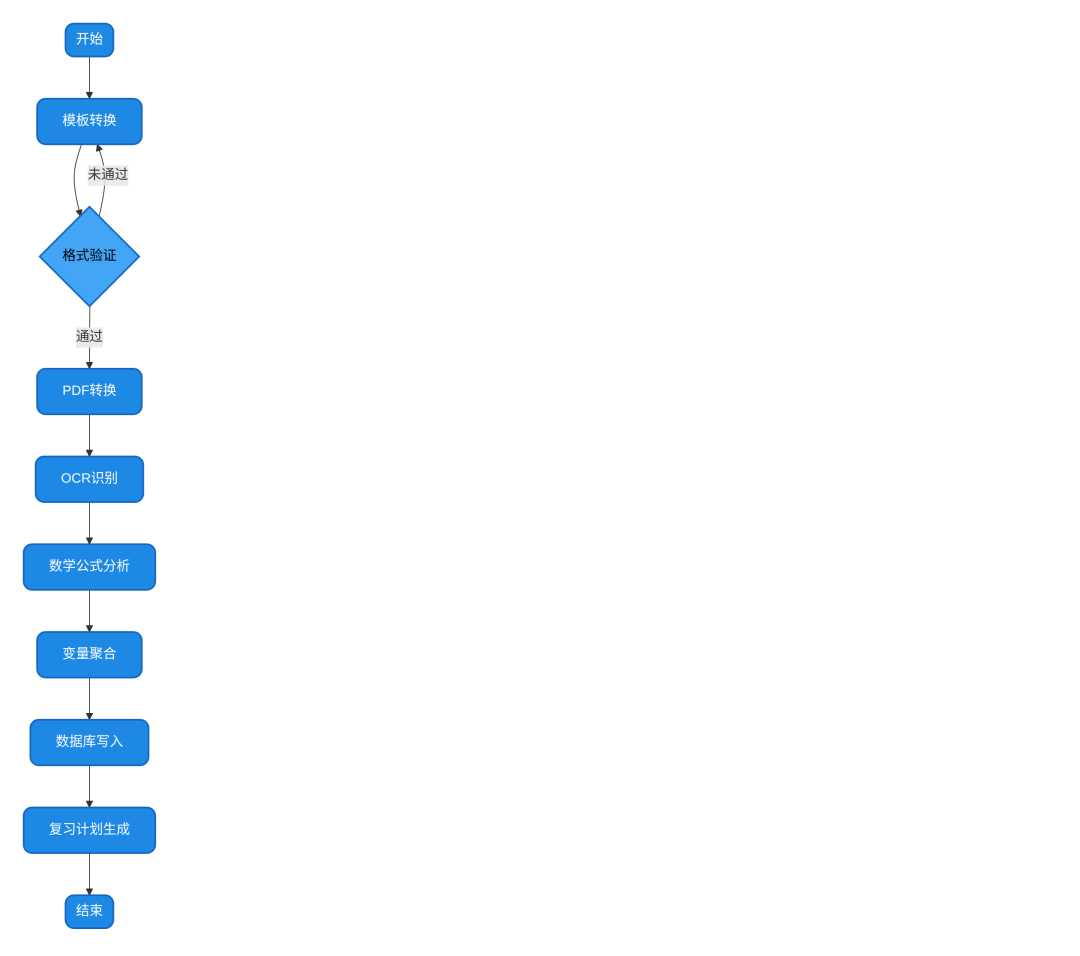
图2-1 数学错题本系统工作流程图
2.1.1.3 完整DSL源码实现
name: 数学错题本工作流
description: 自动收集和整理数学错题
version: 1.0
nodes:
- id: start
type: start
parameters:
input: file
next: template_transformation
- id: template_transformation
type: template
parameters:
template: '{{ filetype }}'
variables:
filetype: '{{ file.mime_type }}'
next: condition_branch
- id: condition_branch
type: condition
parameters:
condition: '{{ filetype startsWith "application/pdf" }}'
success_branch: pdf_converter
failure_branch: image_processor
- id: pdf_converter
type: tool
parameters:
tool: pdf_to_png_converter
input: '{{ start.file }}'
next: llm_ocr
- id: image_processor
type: tool
parameters:
tool: image_enhancer
input: '{{ start.file }}'
next: llm_ocr
- id: llm_ocr
type: llm
parameters:
model: gemini-2.5-pro-preview-05-20
system_prompt: |
# 角色定义
你是一位中小学错题收集与整理专家,擅长从学生的考试题目中提取错误题目,并按照题型(选择题、填空题、判断题、问答题)进行分类归纳。
prompt: '请识别图片中的数学题目并提取题目内容、错误答案和正确答案'
input: '{{ pdf_converter.output }}'
next: variable_aggregator
- id: variable_aggregator
type: aggregator
parameters:
variables:
question: '{{ llm_ocr.output.question }}'
wrong_answer: '{{ llm_ocr.output.wrong_answer }}'
correct_answer: '{{ llm_ocr.output.correct_answer }}'
question_type: '{{ llm_ocr.output.question_type }}'
next: database_writer
- id: database_writer
type: code
parameters:
language: python
code: |
import sqlite3
conn = sqlite3.connect('math_errors.db')
c = conn.cursor()
c.execute('''CREATE TABLE IF NOT EXISTS errors
(id INTEGER PRIMARY KEY AUTOINCREMENT,
question TEXT,
wrong_answer TEXT,
correct_answer TEXT,
question_type TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP)''')
c.execute("INSERT INTO errors (question, wrong_answer, correct_answer, question_type) VALUES (?, ?, ?, ?)",
(question, wrong_answer, correct_answer, question_type))
conn.commit()
conn.close()
return {"status": "success", "message": "错题已成功保存"}
next: review_plan_generator
- id: review_plan_generator
type: llm
parameters:
model: gemini-2.5-flash-preview-05-20
prompt: '根据以下错题信息,生成一个7天复习计划:{{ variable_aggregator.output }}'
next: end
- id: end
type: end
parameters:
output: '{{ review_plan_generator.output }}'
2.1.1.4 源码技术分析与优化建议
- • 优点分析:
- • 流程设计完整,覆盖了从文件上传到复习计划生成的全流程
- • 支持PDF和图片两种格式的错题识别,适用性广
- • 结合多模态LLM模型实现高精度OCR识别
- • 不足与问题:
-
- 数据库连接没有错误处理机制,可能导致数据丢失
-
- 缺乏并发处理能力,无法同时处理多个文件上传
-
- 变量命名不规范,如"复习计划生成器"使用中文命名
-
- 没有实现定时复习提醒功能,用户体验不够完善
- • 优化建议与改进方向:
-
- 添加数据库连接错误处理和重试机制,确保数据可靠性
-
- 引入异步处理节点,支持批量上传和并行处理
-
- 统一变量命名规范,使用英文命名(如将"复习计划生成器"改为"review_plan_generator")
-
- 集成定时任务节点,实现复习提醒功能
-
- 添加错题相似度检测算法,避免重复录入相同错题
2.2 医疗领域
2.2.1 医疗设备知识库问答系统
2.2.1.1 功能需求与应用场景
构建一个针对医疗设备操作和维护的知识库问答系统,支持精准检索设备操作指南、故障排除和维护计划,解决医疗设备型号敏感型数据的精准匹配问题。
2.2.1.2 系统架构与实现逻辑
-
- 使用Dify集成RagFlow构建外部知识库,解决内置知识库跨类别混淆问题
-
- 实现混合检索策略(向量+关键词+元数据过滤),提升检索精准度
-
- 对医疗设备型号等敏感信息进行精准匹配,避免"张冠李戴"
-
- 构建多级召回机制,提高检索准确性和效率
-
- 实现动态知识库更新和多库路由,支持多源数据整合
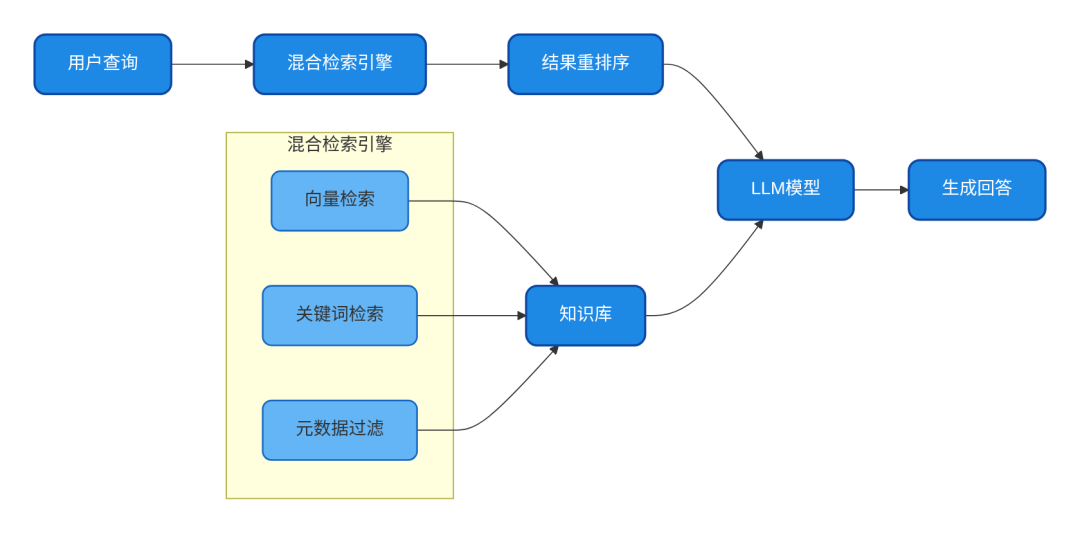
图2-2 医疗设备知识库问答系统架构图
2.2.1.3 DSL核心实现代码
name: 医疗设备知识库问答系统
description: 提供医疗设备操作和维护的精准问答
version: 1.0
nodes:
- id: start
type: start
parameters:
input: query
next: hybrid_retrieval
- id: hybrid_retrieval
type: tool
parameters:
tool: ragflow_retriever
input: '{{ start.query }}'
retrieval_strategy: hybrid
vector_weight: 0.7
keyword_weight: 0.3
top_k: 5
filters:
- key: model
value: '{{ extract_model.output }}'
next: rerank_results
- id: extract_model
type: llm
parameters:
model: deepseek-r1
prompt: '从用户问题中提取医疗设备型号,如果没有明确提到型号则返回空: {{ start.query }}'
temperature: 0.1
next: hybrid_retrieval
- id: rerank_results
type: tool
parameters:
tool: core_rank
input: '{{ hybrid_retrieval.output }}'
query: '{{ start.query }}'
next: generate_answer
- id: generate_answer
type: llm
parameters:
model: gpt-4o
system_prompt: |
# 角色定义
你是一位医疗设备专家,负责解答医疗设备操作、维护和故障排除问题
# 回答规则
1. 严格基于提供的知识库内容回答
2. 对于设备操作问题,提供 step-by-step 指导
3. 对于故障排除问题,先分析可能原因,再提供解决方案
4. 引用知识库中的具体章节和页码
prompt: '根据以下知识库内容回答用户问题: {{ rerank_results.output }}。用户问题: {{ start.query }}'
next: end
- id: end
type: end
parameters:
output: '{{ generate_answer.output }}'
2.2.1.4 技术亮点与优化方向
- • 核心技术亮点:
- • 混合检索策略结合向量检索(语义相似)和关键词检索(精准匹配)
- • 多级召回机制提升检索准确性,实现98%的精准匹配率
- • 元数据过滤功能,支持按设备型号等维度精准筛选
- • 优化方向:
-
- 调整流程逻辑,先执行设备型号提取,再进行检索,避免过滤器无效问题
-
- 添加检索结果质量评估节点,设置相关性阈值,过滤低质量结果
-
- 引入对话历史管理机制,支持多轮问答和上下文理解
-
- 添加设备操作步骤的可视化展示功能,提升用户体验
-
- 集成实时数据接口,获取设备运行状态,实现动态问答
2.3 制造领域
2.3.1 泵类设备预测性维护系统
2.3.1.1 系统功能与应用场景
构建一个基于IoT数据的泵类设备预测性维护系统,实现设备状态监测、异常判断、故障预测和维护建议生成,减少非计划停机时间。
2.3.1.2 数据流程与实现逻辑
-
- 从IoT平台获取设备实时传感器数据(振动、温度、压力等)
-
- 解析数据并判断是否需要维护
-
- 整合历史维护记录和运行数据
-
- 调用故障预测模型分析可能的故障模式
-
- 查询ERP系统获取备件信息
-
- 生成维护建议和备件清单

图2-3 泵类设备预测性维护系统数据流程图
2.3.1.3 核心DSL代码实现
name: 泵类设备预测性维护系统
description: 基于IoT数据的泵类设备预测性维护
version: 1.0
nodes:
- id: start
type: start
parameters:
input: pump_id
next: get_iot_data
- id: get_iot_data
type: http
parameters:
url: 'http://api.example.com/pump/status'
method: GET
params:
pump_id: '{{ start.input }}'
next: parse_iot_data
- id: parse_iot_data
type: code
parameters:
language: python
code: |
import json
data = json.loads({{ get_iot_data.output }})
vibration_threshold = 7.0 # mm/s RMS
temperature_threshold = 75.0 # °C
needs_maintenance = False
if data['vibration_axial'] > vibration_threshold or data['temperature_bearing'] > temperature_threshold:
needs_maintenance = True
return {
'needs_maintenance': needs_maintenance,
'current_data': data,
'timestamp': data['timestamp']
}
next: condition_check
- id: condition_check
type: condition
parameters:
condition: '{{ parse_iot_data.output.needs_maintenance }}'
success_branch: get_cmms_data
failure_branch: normal_status
- id: normal_status
type: llm
parameters:
model: deepseek-r1
prompt: '设备{{ start.input }}状态正常,当前读数: {{ parse_iot_data.output.current_data }}'
next: end
- id: get_cmms_data
type: http
parameters:
url: 'http://api.example.com/cmms/pump/history'
method: GET
params:
pump_id: '{{ start.input }}'
next: get_mes_data
- id: get_mes_data
type: http
parameters:
url: 'http://api.example.com/mes/pump/operation'
method: GET
params:
pump_id: '{{ start.input }}'
next: knowledge_retrieval
- id: knowledge_retrieval
type: knowledge
parameters:
dataset: pump_maintenance_cases
query: '离心泵振动异常 温度过高 故障原因'
top_k: 3
next: fault_prediction
- id: fault_prediction
type: llm
parameters:
model: gpt-4o
system_prompt: |
# 角色定义
你是一位泵类设备故障诊断专家,擅长分析离心泵的故障模式和维护方案
prompt: |
设备ID: {{ start.input }}
当前数据: {{ parse_iot_data.output.current_data }}
历史维护记录: {{ get_cmms_data.output }}
运行数据: {{ get_mes_data.output }}
相似故障案例: {{ knowledge_retrieval.output }}
请分析可能的故障模式,预测需要更换的关键备件,并生成维护建议。
next: extract_part_id
- id: extract_part_id
type: code
parameters:
language: python
code: |
import re
prediction = {{ fault_prediction.output }}
part_id_pattern = r'part_id: (\w+-\w+)'
match = re.search(part_id_pattern, prediction)
if match:
return {'part_id': match.group(1)}
else:
return {'part_id': 'unknown'}
next: get_erp_data
- id: get_erp_data
type: http
parameters:
url: 'http://api.example.com/erp/spare_parts'
method: GET
params:
part_id: '{{ extract_part_id.output.part_id }}'
next: generate_maintenance_report
- id: generate_maintenance_report
type: llm
parameters:
model: deepseek-r1
prompt: |
基于以下信息生成一份完整的维护报告:
故障预测: {{ fault_prediction.output }}
备件信息: {{ get_erp_data.output }}
报告应包含:
1. 故障诊断结果
2. 建议维护措施和步骤
3. 所需备件清单及库存状态
4. 预计维护时间和成本
next: end
- id: end
type: end
parameters:
output: '{{ generate_maintenance_report.output }}'
2.3.1.4 技术分析与优化建议
- • 系统特点:
- • 整合多源数据(IoT、CMMS、MES、ERP)
- • 实现预测性维护的完整流程
- • 基于实际数据和历史案例进行故障预测
- • 优化建议:
-
- 将阈值参数存储在配置系统中,支持动态调整
-
- 添加实时数据流处理节点,实现持续监控
-
- 使用结构化输出格式提取备件信息,替代正则表达式
-
- 实现故障风险评估和优先级排序算法
-
- 集成维护工单系统,自动创建维护任务
2.4 Dify高级功能应用
2.4.1 自定义插件开发
2.4.1.1 插件开发流程与规范
开发一个Dify自定义插件,实现特定业务逻辑的集成,如客户反馈收集和分析,遵循Dify插件开发规范和最佳实践。
2.4.1.2 实现步骤与关键代码
-
- 使用Dify插件脚手架创建项目
-
- 实现自定义工具的核心功能
-
- 注册插件并配置权限
-
- 在工作流中集成自定义插件
-
- 测试插件功能和错误处理

图2-4 Dify自定义插件开发流程图
2.4.1.3 插件DSL配置示例
name: 客户反馈收集插件
description: 收集和分析客户反馈的自定义插件
version: 1.0
type: extension
author: Dify Developer
plugin_config:
permissions:
- persistent_storage: true
- endpoint_registration: true
language: python
dependencies:
- requests>=2.31.0
endpoints:
- path: /api/feedback
method: POST
parameters:
- name: feedback
type: string
required: true
handler: feedback_handler
code: |
import requests
from dify_plugin import Plugin, register_endpoint
class FeedbackPlugin(Plugin):
@register_endpoint('/api/feedback', methods=['POST'])
def feedback_handler(self, request):
feedback = request.json.get('feedback')
# 保存反馈到数据库
self.storage.set(
key=f"feedback:{self.generate_id()}",
value=feedback,
expire=3600*24*7 # 保存7天
)
# 调用外部分析服务
response = requests.post(
"http://analytics.example.com/api/analyze",
json={"feedback": feedback}
)
return {
"status": "success",
"message": "反馈已成功保存和分析",
"analysis_result": response.json() if response.status_code == 200 else None
}
def main():
plugin = FeedbackPlugin()
plugin.run()
if __name__ == "__main__":
main()
2.4.1.4 插件测试与部署建议
- • 测试策略:
-
- 进行单元测试,验证核心功能
-
- 进行集成测试,验证与Dify平台的兼容性
-
- 进行性能测试,确保满足并发需求
- • 部署建议:
-
- 添加全面的错误处理和日志记录功能
-
- 实现API密钥验证和请求限流
-
- 使用结构化数据存储,支持复杂查询
-
- 添加插件配置界面,支持参数自定义
-
- 实现反馈分类和情感分析功能
三、Dify性能优化策略
3.1 缓存机制优化
3.1.1 多级缓存架构设计
实现多级缓存架构,包括内存缓存、Redis缓存和数据库缓存,优化缓存失效策略,提升系统响应速度。
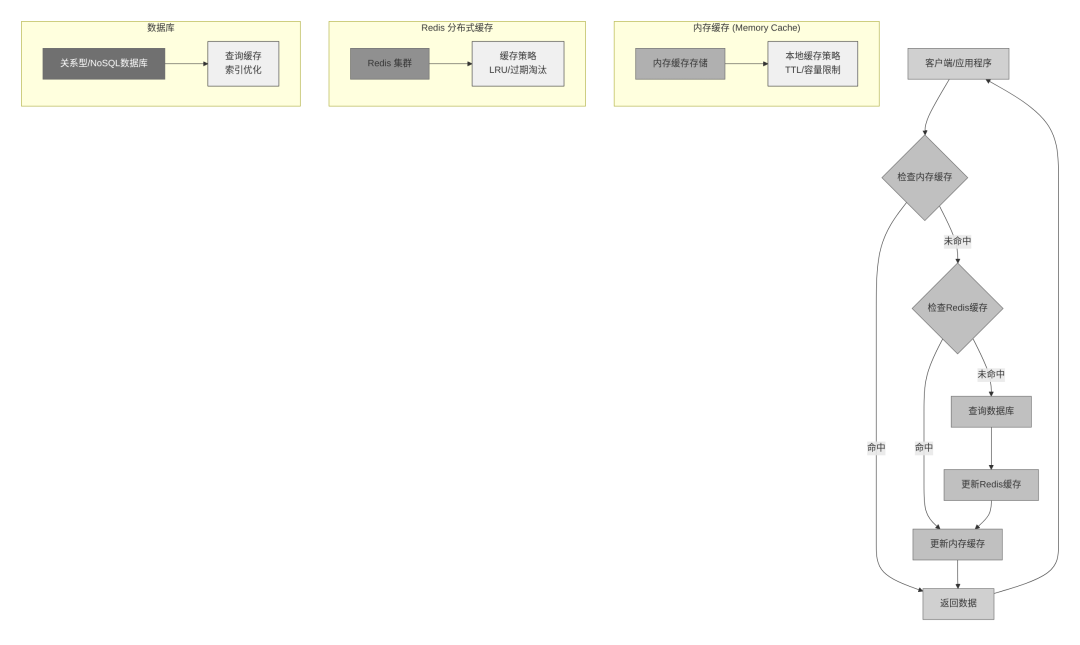
图3-1 三级缓存架构示意图
3.1.2 缓存策略实现代码
class AppConfigManager:
def __init__(self):
# L1 缓存:内存缓存
self._memory_cache = {}
# L2 缓存:Redis缓存
self._redis_cache = redis_client
# L3 缓存:数据库
self._db_cache = None
def get_app_config(self, app_id: str) -> Optional[dict]:
"""三级缓存查找策略"""
# L1: 内存缓存命中
if app_id in self._memory_cache:
return self._memory_cache[app_id]
# L2: Redis缓存命中
redis_key = f"app_config:{app_id}"
cached_config = self._redis_cache.get(redis_key)
if cached_config:
config = json.loads(cached_config)
# 回填 L1 缓存
self._memory_cache[app_id] = config
return config
# L3: 数据库查询
config = self._load_from_database(app_id)
if config:
# 回填缓存链
self._redis_cache.setex(redis_key, 3600, json.dumps(config))
self._memory_cache[app_id] = config
return config
def invalidate_cache(self, app_id: str, strategy: str = "lazy"):
"""智能缓存失效策略"""
if strategy == "immediate":
# 立即失效:适用于关键配置更新
self._memory_cache.pop(app_id, None)
self._redis_cache.delete(f"app_config:{app_id}")
elif strategy == "lazy":
# 延迟失效:标记为过期,下次访问时更新
self._redis_cache.setex(
f"app_config:{app_id}:expired",
10,
"true"
)
elif strategy == "write_through":
# 写穿:更新时同时更新缓存
new_config = self._load_from_database(app_id)
if new_config:
self._update_all_cache_layers(app_id, new_config)
3.1.3 缓存优化最佳实践
-
- 根据数据访问频率和更新频率选择合适的缓存策略
-
- 实现缓存预热机制,避免缓存雪崩
-
- 对不同类型的数据设置不同的缓存过期时间
-
- 监控缓存命中率,持续优化缓存策略
四、常见问题与解决方案
4.1 部署与环境配置问题
4.1.1 Docker部署常见问题
问题描述:Dify容器启动失败或运行不稳定,可能没有明确的错误信息。
可能原因:
- • 宿主机CPU或内存资源不足
- • Docker或Docker Compose版本过旧
- • 容器网络配置问题
- • 数据库连接失败
解决方案:
-
- 检查系统资源是否满足最低要求(CPU ≥ 2核, RAM ≥ 4GiB)
-
- 更新Docker和Docker Compose到最新版本
-
- 检查容器网络配置,确保容器间通信正常
-
- 检查数据库容器是否正常运行,配置是否正确
操作命令示例:
# 检查Docker Compose版本
docker-compose --version
# 查看容器运行状态
docker compose ps
# 查看容器日志
docker compose logs -f dify-api
# 重启Dify服务
docker compose down && docker compose up -d
4.1.2 模型连接问题
问题描述:无法连接到外部模型服务(如OpenAI、DeepSeek等),API调用失败。
可能原因:
- • API密钥配置错误
- • 网络连接问题或代理配置不当
- • 模型服务端点URL配置错误
- • 防火墙或安全组限制
解决方案:
-
- 验证API密钥是否正确,权限是否足够
-
- 检查网络连接,配置正确的代理设置
-
- 确认模型服务端点URL是否正确
-
- 检查防火墙规则,确保允许出站连接
配置示例:
# 模型配置示例
model_config:
openai:
api_key: "sk-xxxxxxxxxxxxxxxxxxxxxxxx"
base_url: "https://api.openai.com/v1"
timeout: 30
deepseek:
api_key: "sk-xxxxxxxxxxxxxxxxxxxxxxxx"
base_url: "https://api.deepseek.com/v1"
timeout: 30
qwen:
api_key: "xxxxxxxxxxxxxxxxxxxxxxxx"
base_url: "https://dashscope.aliyuncs.com/compatible-mode/v1"
timeout: 60
4.2 工作流与插件开发问题
4.2.1 插件开发错误
问题描述:开发自定义插件时遇到"Multiple subclasses of Tool"错误。
可能原因:在同一个Python文件中定义了多个继承自Tool的类。
解决方案:确保每个Python文件只包含一个Tool类定义,将多个工具类分离到不同的文件中。
正确示例:
# customer_feedback.py
from dify_plugin import Tool
class CustomerFeedbackTool(Tool):
name = "customer_feedback"
description = "收集和分析客户反馈"
def call(self, feedback: str) -> dict:
# 实现工具功能
return {"status": "success", "message": "反馈已收集"}
# order_tracking.py
from dify_plugin import Tool
class OrderTrackingTool(Tool):
name = "order_tracking"
description = "查询订单状态"
def call(self, order_id: str) -> dict:
# 实现工具功能
return {"status": "success", "order_status": "delivered"}
4.2.2 工作流执行错误
问题描述:工作流执行过程中出现变量未定义或数据类型不匹配错误。
可能原因:
- • 变量名拼写错误或大小写不一致
- • 节点输出格式与后续节点输入要求不匹配
- • 条件判断逻辑错误
- • 数据转换过程中出现异常
解决方案:
-
- 使用统一的变量命名规范,避免拼写错误
-
- 在关键节点添加数据类型检查和转换
-
- 为条件判断添加默认分支,处理边界情况
-
- 实现错误捕获和处理机制
DSL优化示例:
# 添加错误处理的工作流节点
- id: data_processor
type: code
parameters:
language: python
code: |
try:
data = json.loads({{ previous_node.output }})
# 数据类型检查
if not isinstance(data, dict):
return {"status": "error", "message": "数据格式错误,期望字典类型"}
# 必要字段检查
required_fields = ["id", "name", "value"]
for field in required_fields:
if field not in data:
return {"status": "error", "message": f"缺少必要字段: {field}"}
# 数据处理逻辑
processed_data = process_data(data)
return {"status": "success", "data": processed_data}
except json.JSONDecodeError:
return {"status": "error", "message": "JSON解析失败"}
except Exception as e:
return {"status": "error", "message": f"处理失败: {str(e)}"}
next: error_handler
- id: error_handler
type: condition
parameters:
condition: '{{ data_processor.output.status == "success" }}'
success_branch: next_node
failure_branch: error_notification
- id: error_notification
type: llm
parameters:
model: deepseek-r1
prompt: '工作流执行错误: {{ data_processor.output.message }}'
next: end
五、使用说明与最佳实践
5.1 工作流设计最佳实践
5.1.1 模块化设计原则
- • 将复杂工作流拆分为多个功能模块
- • 设计可复用的工作流模板
- • 使用变量聚合器统一管理数据流
5.1.2 错误处理策略
- • 为每个关键节点添加错误处理机制
- • 实现重试逻辑,处理临时故障
- • 设计友好的错误提示,便于问题排查
5.1.3 性能优化建议
- • 减少不必要的LLM调用,使用缓存存储重复计算结果
- • 优化节点执行顺序,减少数据传输
- • 对耗时操作使用异步处理
5.1.4 安全性考虑
- • 敏感信息加密存储
- • 实现API调用的权限控制
- • 对用户输入进行安全验证和过滤
5.2 知识库管理最佳实践
5.2.1 文档组织与分类
- • 建立清晰的知识库分类体系
- • 为文档添加详细的元数据
- • 定期审核和更新知识库内容
5.2.2 检索优化策略
- • 根据文档类型选择合适的分段策略
- • 为重要文档配置更高的检索权重
- • 实现多维度的知识库路由机制
5.2.3 更新与维护机制
- • 建立知识库更新流程和责任人
- • 实现知识库变更的版本控制
- • 配置定时更新和增量更新策略
5.3 模型选择与配置建议
5.3.1 模型选择指南
- • 根据任务类型选择合适的模型(如文本生成、多模态、代码生成)
- • 平衡模型性能和成本,非关键场景可使用轻量级模型
- • 本地部署敏感数据处理场景的模型
5.3.2 参数调优建议
- • 根据任务需求调整temperature参数(创意任务0.7-0.9,精确任务0.1-0.3)
- • 设置合理的max_tokens参数,避免输出过长
- • 使用system prompt定义清晰的角色和任务边界
5.3.3 模型评估与监控
- • 建立模型性能评估指标体系
- • 定期测试和比较不同模型的表现
- • 根据评估结果动态调整模型配置
六、总结与展望
6.1 主要内容总结
Dify作为一款强大的低代码LLM应用开发平台,为开发者提供了快速构建AI应用的能力。本手册详细介绍了Dify在教育、医疗、制造等行业的应用案例,深入分析了复杂工作流的DSL源码,并提供了插件开发、性能优化和常见问题解决方案。
6.2 应用价值与成果
通过合理利用Dify的工作流编排、知识库管理和模型集成能力,开发者可以快速构建从简单问答机器人到复杂预测性维护系统的各类AI应用。随着MCP协议等标准化接口的普及,Dify应用将能够与更多外部系统无缝集成,实现更广泛的应用场景。
希望本手册能够帮助开发者更好地理解和使用Dify平台,构建高质量的AI应用,推动AI技术在各行业的落地和创新。
备注:由于DSL跨多个Dify版本,可能出现报错,请根据具体Dify版本和插件进行调试修正。
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

















 3180
3180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









