




 使用Pycharm环境,通过分析笔下文学网站的URL规律,发现小说文本存储在静态HTML中。通过requests获取页面源码,结合BeautifulSoup(bs4)库解析提取每一章节的内容,成功爬取了《全职高手》的全本小说。代码简洁高效,仅用20行就实现了目标。
使用Pycharm环境,通过分析笔下文学网站的URL规律,发现小说文本存储在静态HTML中。通过requests获取页面源码,结合BeautifulSoup(bs4)库解析提取每一章节的内容,成功爬取了《全职高手》的全本小说。代码简洁高效,仅用20行就实现了目标。
环境 pycharm,bs4
需求:在笔下文学网站上爬取全职高手全本小说
第一步:分析url
第一章的url:
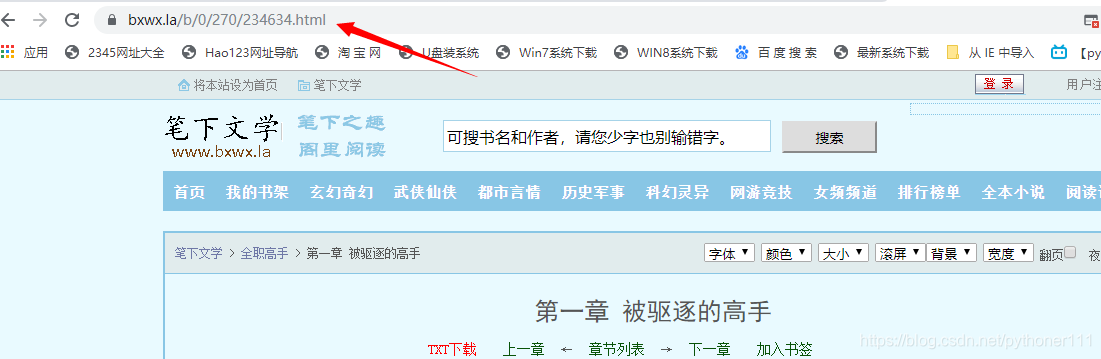
第二章的url:
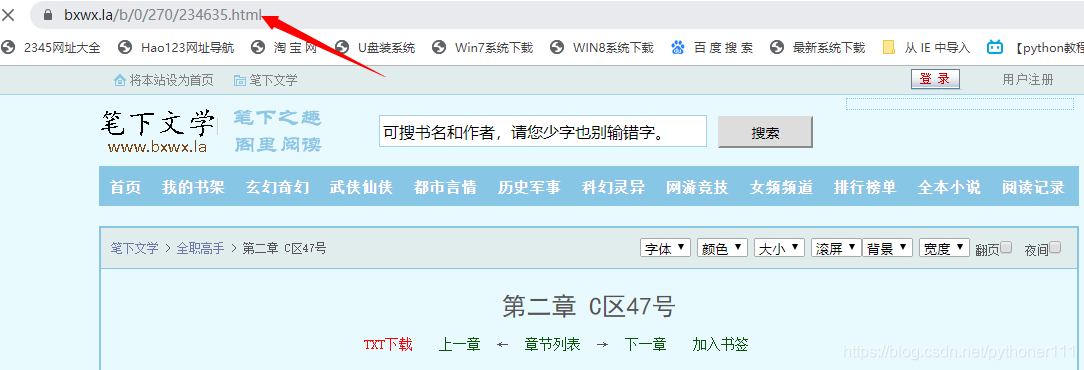
从url的变化很容易找到规律。

看到了源代码,静态html中包含小说文本,所以直接request刚刚分析的链接就能获取源码,然后用bs4解析提取每一章的小说文本即可。下面直接上我写的代码:
import requests
import random
import time
import bs4
import lxml
import re
for x in range(0,1800):
url="https://www.bxwx.la/b/0/270/"+str(234634+x)+".html"
print("全职高手第%s章正在下载....."%(x+1))
#返回response对象
r=requests.get(url).text
#解析数据
#生成soup对象
soup=bs4.BeautifulSoup(r,"lxml")
#获取章节标题
tag_title=soup.title
#获取存放文本的div
div_tag=soup.find_all("div",id="content")
#获取章节文本内容
div_tag_content=soup.find("div",id=" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4139
4139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









