



 这篇博客介绍了如何在sklearn中使用各种数据集,包括数据和标签的结构,特别是详细探讨了数字数据集的加载和特性。还提供了几个练习,如加载葡萄酒数据集并进行可视化。
这篇博客介绍了如何在sklearn中使用各种数据集,包括数据和标签的结构,特别是详细探讨了数字数据集的加载和特性。还提供了几个练习,如加载葡萄酒数据集并进行可视化。
sklearn 中的数据集

Scikit-learn 提供了大量用于测试学习算法的数据集。它们有三种口味:
- 打包数据:这些小数据集与 scikit-learn 安装一起打包,可以使用 scikit-learn 中的工具下载
sklearn.datasets.load_* - 可下载的数据:这些较大的数据集可供下载,scikit-learn 包含简化此过程的工具。这些工具可以在
sklearn.datasets.fetch_* - 生成的数据:有几个数据集是从基于随机种子的模型生成的。这些可以在
sklearn.datasets.make_*
您可以使用 IPython 的制表符补全功能探索可用的数据集加载器、提取器和生成器。从 导入datasets子模块后sklearn,键入
datasets.load_<TAB>
或者
datasets.fetch_<TAB>
或者
datasets.make_<TAB>
查看可用功能的列表。
数据和标签的结构
scikit-learn 中的数据在大多数情况下保存为形状为 的二维 Numpy 数组(n, m)。许多算法也接受scipy.sparse相同形状的矩阵。
- n: (n_samples) 样本数:每个样本是一个要处理的项目(例如分类)。样本可以是文档、图片、声音、视频、天文物体、数据库或 CSV 文件中的一行,或者您可以用一组固定的数量特征描述的任何内容。
- m: (n_features) 可用于以定量方式描述每个项目的特征或不同特征的数量。特征通常是实值的,但在某些情况下可能是布尔值或离散值的。
从 sklearn 导入 数据集
请注意:其中许多数据集都非常大,下载可能需要很长时间!
加载数字数据
我们将仔细研究这些数据集之一。我们看一下数字数据集。我们将首先加载它:
从 sklearn.datasets 导入 load_digits
位数 = load_digits ()
同样,我们可以通过查看“键”来大致了解可用属性:
数字。键()
输出:
dict_keys(['data', 'target', 'frame', 'feature_names', 'target_names', 'images', 'DESCR'])
让我们来看看项目和功能的数量:
n_samples , n_features = 数字。数据。形状
打印((n_samples , n_features ))
输出:
(1797, 64)
打印(数字。数据[ 0 ])
打印(数字。目标)
输出:
[ 0. 0. 5. 13. 9. 1. 0. 0. 0. 0. 13. 15. 10. 15. 5. 0. 0. 3. 15. 2. 0. 11. 8. 0. 0. 4. 12. 0. 0. 8. 8. 0. 0. 5. 8. 0. 0. 9. 8. 0. 0. 4. 11. 0. 1. 12. 7. 0. 0. 2. 14. 5. 10. 12. 0. 0. 0. 0. 6. 13. 10. 0. 0. 0.] [0 1 2 ... 8 9 8]
这些数据也可以在digits.images 上找到。这是 8 行 8 列形式的图像的原始数据。
对于“数据”,图像对应于长度为 64 的一维 Numpy 数组,“图像”表示包含形状为 (8, 8) 的二维 numpy 数组
打印(“项目的形状:” , 数字。数据[ 0 ] 。形状)
打印(“项目的数据类型:” , 类型(数字。数据[ 0 ]))
打印(“项目的形状:” , 数字.图像[ 0 ] .形状)
打印(“项目的数据类型:” , 类型(数字.图像[ 0 ]))
输出:
物品形状:(64,) 项目的数据类型:<class 'numpy.ndarray'> 物品形状:(8, 8) 项目的数据类型:<class 'numpy.ndarray'>
让我们可视化数据。它比我们上面使用的简单散点图要复杂一些,但我们可以很快完成。
import matplotlib.pyplot as plt
# 设置图形
fig = plt . figure ( figsize = ( 6 , 6 )) # 以英寸为单位的图形大小
fig . subplots_adjust ( left = 0 , right = 1 , bottom = 0 , top = 1 , hspace = 0.05 , wspace = 0.05 )
# 绘制数字:
对于 范围( 64 ) 中的i , 每个图像是 8x8 像素:ax = fig 。add_subplot ( 8 , 8 , i + 1 , xticks = [], yticks = []) ax 。imshow (数字.图像[ i ], cmap = plt . cm . binary ,插值= 'nearest' )
# 用目标值
ax标记图像。文本( 0 , 7 , str (数字。目标[ i ]))

练习
练习 1
sklearn 包含一个“葡萄酒数据集”。
- 查找并加载此数据集
- 你能找到描述吗?
- 类的名称是什么?
- 有哪些特点?
- 数据和标记数据在哪里?
练习 2:
创建特征ash和color_intensity葡萄酒数据集的散点图。
练习 3:
创建葡萄酒数据集特征的散点矩阵。
练习 4:
获取 Olivetti 人脸数据集并可视化人脸。
解决方案
练习 1 的解决方案
加载“葡萄酒数据集”:
从 sklearn 导入 数据集
酒 = 数据集。load_wine ()
可以通过“DESCR”访问描述:
打印(酒。DESCR )
输出:
.. _wine_dataset:
葡萄酒识别数据集
------------------------
**数据集特征:**
:实例数:178(三个类中的每个类50个)
:属性数量:13 个数字、预测属性和类别
:属性信息:
- 酒精
- 苹果酸
- 灰
- 灰分的碱度
- 镁
- 总酚
- 黄酮类
- 非黄酮酚
- 原花青素
- 颜色强度
- 色调
- 稀释葡萄酒的 OD280/OD315
- 脯氨酸
- 班级:
- class_0
- class_1
- class_2
:汇总统计:
==================================================
最小最大平均标准差
==================================================
酒精:11.0 14.8 13.0 0.8
苹果酸:0.74 5.80 2.34 1.12
灰分:1.36 3.23 2.36 0.27
灰分碱度:10.6 30.0 19.5 3.3
镁:70.0 162.0 99.7 14.3
总酚:0.98 3.88 2.29 0.63
类黄酮:0.34 5.08 2.03 1.00
非黄酮酚:0.13 0.66 0.36 0.12
原花青素:0.41 3.58 1.59 0.57
颜色强度:1.3 13.0 5.1 2.3
色相:0.48 1.71 0.96 0.23
稀释葡萄酒的 OD280/OD315:1.27 4.00 2.61 0.71
脯氨酸:278 1680 746 315
==================================================
:缺少属性值:无
:类分布:class_0 (59), class_1 (71), class_2 (48)
:创作者: RA 费舍尔
:捐助者:迈克尔·马歇尔 (MARSHALL%PLU@io.arc.nasa.gov)
:日期:1988年7月
这是 UCI ML Wine 识别数据集的副本。
https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data
数据是对同一地区种植的葡萄酒进行化学分析的结果
三个不同的种植者在意大利的地区。有十三种不同
对三种类型的不同成分进行的测量
葡萄酒。
原业主:
Forina, M. 等人,PARVUS -
用于数据探索、分类和关联的可扩展包。
制药和食品分析与技术研究所,
Via Brigata Salerno, 16147 热那亚, 意大利。
引文:
Lichman, M. (2013)。UCI 机器学习库
[https://archive.ics.uci.edu/ml]。加州尔湾:加州大学,
信息与计算机科学学院。
.. 主题:: 参考
(1) S. Aeberhard、D. Coomans 和 O. de Vel,
高维设置中分类器的比较,
技术。众议员编号 92-02, (1992), Dept. of Computer Science and Dept.
北昆士兰詹姆斯库克大学数学与统计专业。
(也提交给 Technometrics)。
该数据与许多其他数据一起用于比较各种
分类器。这些类是可分离的,虽然只有 RDA
已实现100%正确分类。
(RDA:100%,QDA 99.4%,LDA 98.9%,1NN 96.1%(z 变换数据))
(所有结果都使用留一法)
(2) S. Aeberhard、D. Coomans 和 O. de Vel,
“RDA 的分类性能”
技术。众议员编号 92-01, (1992), Dept. of Computer Science and Dept.
北昆士兰詹姆斯库克大学数学与统计专业。
(也提交给化学计量学杂志)。
可以像这样检索类和功能的名称:
打印(酒。target_names )
打印(酒。feature_names )
输出:
['class_0''class_1''class_2'] ['酒精','苹果酸','灰分','alcalinity_of_ash','镁','total_phenols','flavanoids','nonflavanoid_phenols','proanthocyanins','color_intensity','hue','od35_ofwins , '脯氨酸']
数据 = 酒。数据
labelled_data = wine 。目标
练习 2 的解决方案:
从 sklearn 导入 数据集
导入 matplotlib.pyplot 作为 plt
酒 = 数据集。load_wine ()
features = 'ash' , 'color_intensity'
features_index = [ wine . 功能名称。索引(特征[ 0 ]),
酒。功能名称。索引(特征[ 1 ])]
颜色 = [ '蓝色' 、 '红色' 、 '绿色' ]
为 标签, 颜色 在 拉链(范围(len个(酒。target_names )), 颜色):
PLT 。分散(酒。数据[酒。目标==标签, 特征索引[ 0 ]],
酒。数据[酒。目标==标签, 特征索引[ 1 ]],
标签=酒. target_names [标签],
c =颜色)
PLT 。xlabel ( features [ 0 ])
plt 。ylabel ( features [ 1 ])
plt 。图例(loc = '左上' )
plt 。显示()
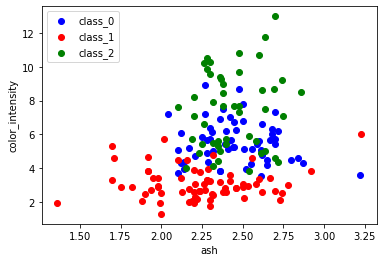
练习 3 的解决方案:
从sklearn导入数据集导入熊猫 作为 pd
酒 = 数据集。load_wine ()
def rotate_labels ( df , axes ):
""" 改变标签输出的旋转,
y 标签水平和 x 标签垂直 """
n = len ( df . columns )
for x in range ( n ):
for y in range ( n ):
# 获取子图的轴
ax = axs [ x , y ]
# 使 x 轴名称垂直
ax 。轴。标签。set_rotation (90 )
#,使y轴的名称水平
斧。yaxis 。标签。set_rotation ( 0 )
# 确保 y 轴名称在绘图区域
ax 之外。yaxis 。标签板 = 50
wine_df = pd 。数据帧(酒。数据, 列=酒。feature_names )
AXS = PD 。绘图。scatter_matrix ( wine_df ,
c = wine . target ,
figsize = ( 8 , 8 ),
);
rotate_labels (wine_df , AXS )

练习 4 的解答
从 sklearn.datasets 导入 fetch_olivetti_faces
# 获取人脸数据
faces = fetch_olivetti_faces ()
脸。键()
输出:
dict_keys(['data', 'images', 'target', 'DESCR'])
n_samples , n_features = faces 。数据。形状
打印((n_samples , n_features ))
输出:
(400, 4096)
NP . 平方(4096 )
输出:
64.0
脸。图像。形状
输出:
(400, 64, 64)
将 numpy 导入为 np
打印( np . all ( faces . images . reshape (( 400 , 4096 )) == faces . data ))
输出:
真的
# 设置图形
fig = plt . figure ( figsize = ( 6 , 6 )) # 以英寸为单位的图形大小
fig . subplots_adjust ( left = 0 , right = 1 , bottom = 0 , top = 1 , hspace = 0.05 , wspace = 0.05 )
# 绘制数字:
对于 范围( 64 ) 中的i , 每个图像是 8x8 像素:ax = fig 。add_subplot ( 8 , 8 , i + 1 , xticks = [], yticks = []) ax 。imshow (面。图像[我],CMAP = PLT 。厘米。骨,插值= '最近' )
# 用目标值
ax标记图像。文本( 0 , 7 , str ( faces . target [ i ]))

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









