






 本文介绍布隆过滤器在缓存穿透、击穿和雪崩等问题上的应用,探讨其原理、安装及配置方法,同时讲解布谷鸟过滤器、分布式锁等解决方案。
本文介绍布隆过滤器在缓存穿透、击穿和雪崩等问题上的应用,探讨其原理、安装及配置方法,同时讲解布谷鸟过滤器、分布式锁等解决方案。
布隆过滤器(bloom)
安装
首先需要redis安装布隆过滤器的扩展库:
- 进入布隆过滤器在github的仓库,下载zip包上传到linux或者点击鼠标右键获得下载地址,然后在linux上使用wget命令直接下载。
- 下载完之后获得一个zip的压缩包,需要下载解压工具 yum install unzip。
- 下载完unzip之后执行unzip RedisBloom-master.zip解压zip压缩包,得到RedisBloom-master目录。
- cd 到 RedisBloom-master目录,执行make执行(执行之前确认当前linux里有安装过gcc编译器)。
- make之后目录里会出现redisbloom.so文件,一般情况下我们会把这个文件cp到redis可执行文件的目录里面去。执行命令cp redisbloom.so /opt/zxj/redis5/。
- 查看当前启动的redis进程ps -fe | grep redis,关闭当前已经启动的redis进程service redis_6379 stop,如果没有此条可以忽略。
- 重新启动redis的时候从新挂载扩展库,可以通过修改配置文件启动挂载,也可以手工挂载扩展库启动redis进程redis-server /etc/redis/6379.conf --loadmodule /opt/~/redis5/redisbloom.so。
- 进入redis-cli客户端,输入bf.,按Tab键,能出现BF.ADD,BF.MEXISTS,BF.INSERT等命令就说明挂载成功。
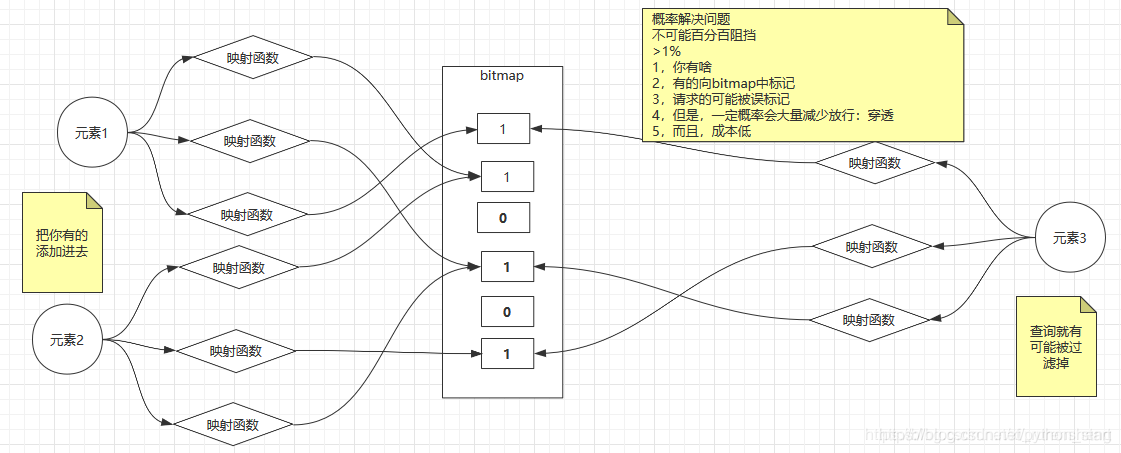
布隆过滤器如何用小的空间解决大量数据的匹配呢?
redis是二进制安全,因此string类型可以操作bitmap位图。
每个商品都代表一个元素,假设这个商品为元素1,元素1会经历N个不同的映射函数,每个映射函数把元素1转换成一个对应的数字,以数字为索引标记bitmap对应位为1。
redis穿透问题
在浏览器访问网站的时候,在请求一条数据的时候,往往会先访问redis中书否存在这个数据,如果存在就直接返回,如果不存在会从数据库查询这个数据是否存在,存在这个数据会返回给浏览器并且存入Redis。下次再有请求这个数据的时候,会直接从redis中查询快速返回,这样既能快速响应浏览器,又可以减轻数据库的压力。
但是如果有很多请求的数据redis中没有,数据库里也没有,甚至有人恶意 高并发请求不存在的数据,每次都使请求命中数据库,每次都和数据库建立socket,可能会造成网站的卡顿,严重的可能让数据库挂掉。
解决穿透
bf.add 添加元素
bf.exists 查询元素是否存在
bf.madd 一次添加多个元素
bf.mexists 一次查询多个元素是否存在
在 redis 中有两个值决定布隆过滤器的准确率:
- error_rate:允许布隆过滤器的错误率,这个值越低过滤器的位数组的大小越大,占用空间也就越大。
- initial_size:布隆过滤器可以储存的元素个数,当实际存储的元素个数超过这个值之后,过滤器的准确率会下降。
redis 中有一个命令可以来设置这两个值:
bf.reserve test 0.01 100
第一个值是过滤器的名字。
第二个值为 error_rate 的值。
第三个值为 initial_size 的值。
redis-server --loadmodule /opt/yupsoftware/redis-5.0.5/redisbloom.so
bf.add hololive minatoaqua
bf.exists hololive minatoaqua
bf.exists hololive kaguramea
bf.madd hololive shirakamifubuki kaguramea nakiriayame ozorasubaru
bf.mexists hololive shirakamifubuki kaguramea nakiriayame ozorasubaru cierrarunis
bf.reserve test 0.001 10000
注意:
必须在add之前使用bf.reserve指令显式创建,如果对应的 key 已经存在,bf.reserve会报错。同时设置的错误率越低,需要的空间越大。如果不使用 bf.reserve,默认的error_rate是 0.01,默认的initial_size是 100。
应用场景
主要是解决大规模数据下不需要精确过滤的场景,如检查垃圾邮件地址,爬虫URL地址去重,解决缓存穿透问题等。
布谷鸟过滤器
实现了布隆过滤器的删除功能
击穿
那么击穿是怎么回事呢?
就是在redis中某个数据刚刚过期淘汰的瞬间,用大量的用户一起访问这个数据,产生高并发。这个时候redis返回的是null,相当于在redis缓存上打了一个窟窿,这些请求就都会去访问数据库,这就是缓存击穿。
解决思路:
思考: 瞬间有大量的并发请求命中数据库,命中的原因是redis中没有key,那么怎么阻止请求并发到达数据库?
- 首先redis是单进程单实例的,并发请求到达redis的时候会串行化,那么肯定会有第一个请求先到达redis而没有找到缓存数据。
- 第一个请求没有拿到数据回到service后,调用redis的 setnx 命令在redis中创建key。setnx 命令只能创建key,如果key不存在,则能创建成功;如果key已经存在,则返回null(分布式锁)。
- 获得锁的请求去访问mysql数据库返回从新把数据缓存进redis,没有获得锁的请求死循环尝试在redis中获取数据,中途可以sleep一定的时间(sleep不能太久,服务链会超时),sleep结束后重复在redis中获取缓存数据,尝试获得锁的过程,直到获得数据跳出循环。
有bug ?
- 可能会产生死锁的问题! 如果去访问数据库的请求挂了,setnx得不到释放,后续请求也无法获取到锁,那些请求就会一直循环sleep。
怎么解决呢?
可以设置setnx的过期时间。
锁设置了过期时间,依然会有bug?
- 第一个去请求数据库的请求可能没有挂,只是因为在mysql这里出现了拥塞,导致锁过期超时。
- 这样就会引起连锁反应,第二个请求拿到了锁,同样到达mysql发生拥塞,就会可能导致访问数据库的请求越堆越多。甚至第一个请求从mysql拿到数据后返回给redis,后续请求从redis拿到数据返回,但是之前拿到锁的请求可能还在mysql排队,或者引起一些用户访问丢失。
解决:
可以利用多线程,一个线程去mysql取数据,另外一个线程监控数据是否取回来,并且及时更新锁的过期时间。
缓存雪崩
- 击穿是某个缓存数据 过期淘汰,并且非常巧的对这个数据有高并发访问,
- 而雪崩是大量的缓存数据 同时 过期淘汰,比如:某些业务要求缓存数据 凌晨0点数据过期,需要从新加载新的数据到缓存,间接造成大量的访问命中数据库
如何解决?
- 普通场合:普通场合:普通场合:
随机过期时间。但是随机过期时间不适合要求凌晨0数据过期的场合。 - 缓存12点必须过期:
- 强依赖缓存击穿方案。并发时,第一个请求获得锁请求数据库,后续数据获得锁失败 -> 休眠 -> 再次尝试获得数据 -> 获取失败循环 -> 获取成功跳出循环。
- 使用0点延迟方案。就是在0点的时候,前置服务里面加一个随机sleep(几十毫秒),保证了请求到达redis时间的差异。
- 强依赖缓存击穿方案 和 0点延迟方案一起使用)
redis分布式锁
实现: setnx
弊端:过期时间。
缺点
- 时间到了,活还没做完,别人又去干了。
- 过期时间没到, 自己挂了。
解决弊端: 多线程,延长过期。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









