



 博主作为编程新手,利用Python解决批量提取txt文件数据并导入Excel的问题。通过numpy的loadtxt函数跳过标签行读取数据,再用glob模块获取文件名,结合openpyxl写入Excel,有效提高了工作效率。
博主作为编程新手,利用Python解决批量提取txt文件数据并导入Excel的问题。通过numpy的loadtxt函数跳过标签行读取数据,再用glob模块获取文件名,结合openpyxl写入Excel,有效提高了工作效率。
本人是编程小白,同时也是一名准毕业研究生,在处理众多数据时总是要花很多时间来做重复的工作以提取出需要的数据,让我十分头疼。我无法忍受这种低效的工作,于是便开始尝试使用Python进行编程来批量处理数据。我把我编程之路上的历程写下来有三个目的:(1)为了发泄初次使用编程成功解决科研工作中问题的兴奋感(2)记录我在这个过程中遇到的问题和解决问题的方法(3)警示我以后在面对问题时记得用编程来提高效率。接下来开始第一次分享我遇到的一个案例:
一、问题描述
通过模拟获得以下56组保存在txt中的数据,
每组数据中内容如下:
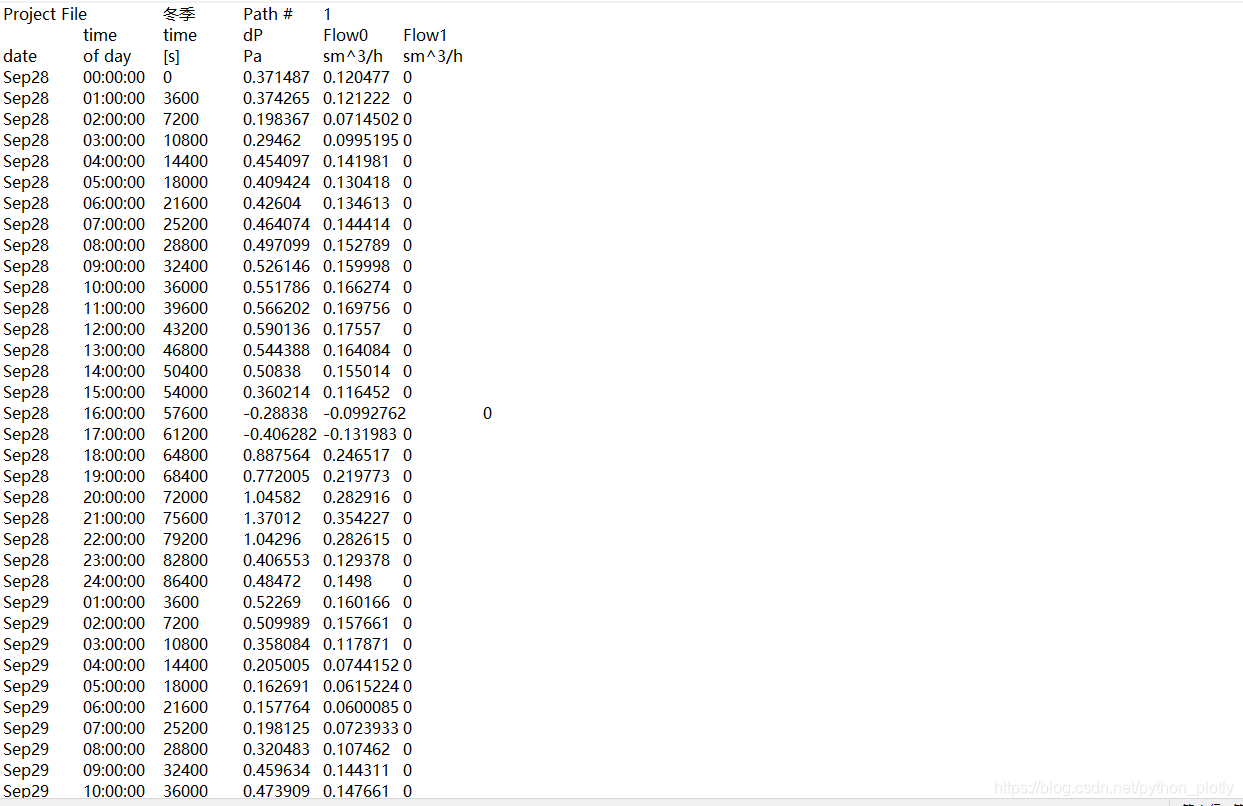
需要将每组数据中的第五列提取出来并保存在excel中以便分析
二、使用numpy读取txt数据
首先考虑如何读取单个txt中数据,这里使用numpy中loadtxt()函数,代码如下:
import numpy as np #引用numpy
array = np.loadtxt('1.txt',dtype=np.str,delimiter='\t') #读取1.txt,数据类型为字符串,分隔符号为tab
运行报错

显示第二行列数错误,原因是前三行是标签行,每行数量元素不统一,于是使用skiprows跳过前三行
import numpy as np
array = np.loadtxt('1.txt',dtype=np.str,delimiter='\t',skiprows=3) #从第四行开始读取
运行没有报错,数据导出正常
以上参考https://blog.youkuaiyun.com/weixin_39609051/article/details/111062501
三、使用glob获取当前文件夹文件,批量读取并写入excel
上面实现了单个txt中数据读取,这太慢了,如果可以批量读取当前文件夹内所有txt文件,并且写入到excel中就好了。这里通过python内置的glob模块来实现,代码如下:
import glob
flist = glob.glob('*.txt')
print(flist)
运行结果如下:

这样就得到了一个列表,列表中包含当前文件夹中所有txt名称,然后将glob应用到数据读取中,并使用openpyxl将读取的数据写入到excel:
import glob #引用glob
import numpy as np #引用numpy
from openpyxl import load_workbook #引用openpyxl的load_workbook
flist = glob.glob('*.txt') #读取当前文件夹所有txt,并存入列表
wb = load_workbook('data.xlsx') #打开要保存数据的excel
sheet = wb['Sheet1'] #打开要保存数据的sheet
i=1 #序数,用来将从txt提取的数据存储到excel的不同列
for filename in flist: #利用for循环逐个读取txt文件
array = np.loadtxt(filename,dtype=np.str,delimiter='\t',skiprows=3) #将当前读取的txt文件数据存储矩阵
number_row = array.shape[0] #获取数据矩阵行数
for j in range(number_row):
sheet.cell(j+1,i).value = float(array[j][4]) #将需要用的第五列数据存储在excel中
i = i+1
wb.save('data.xlsx') #保存excel文件并退出
运行没有报错,需要的数据已经有序地保存在excel中啦
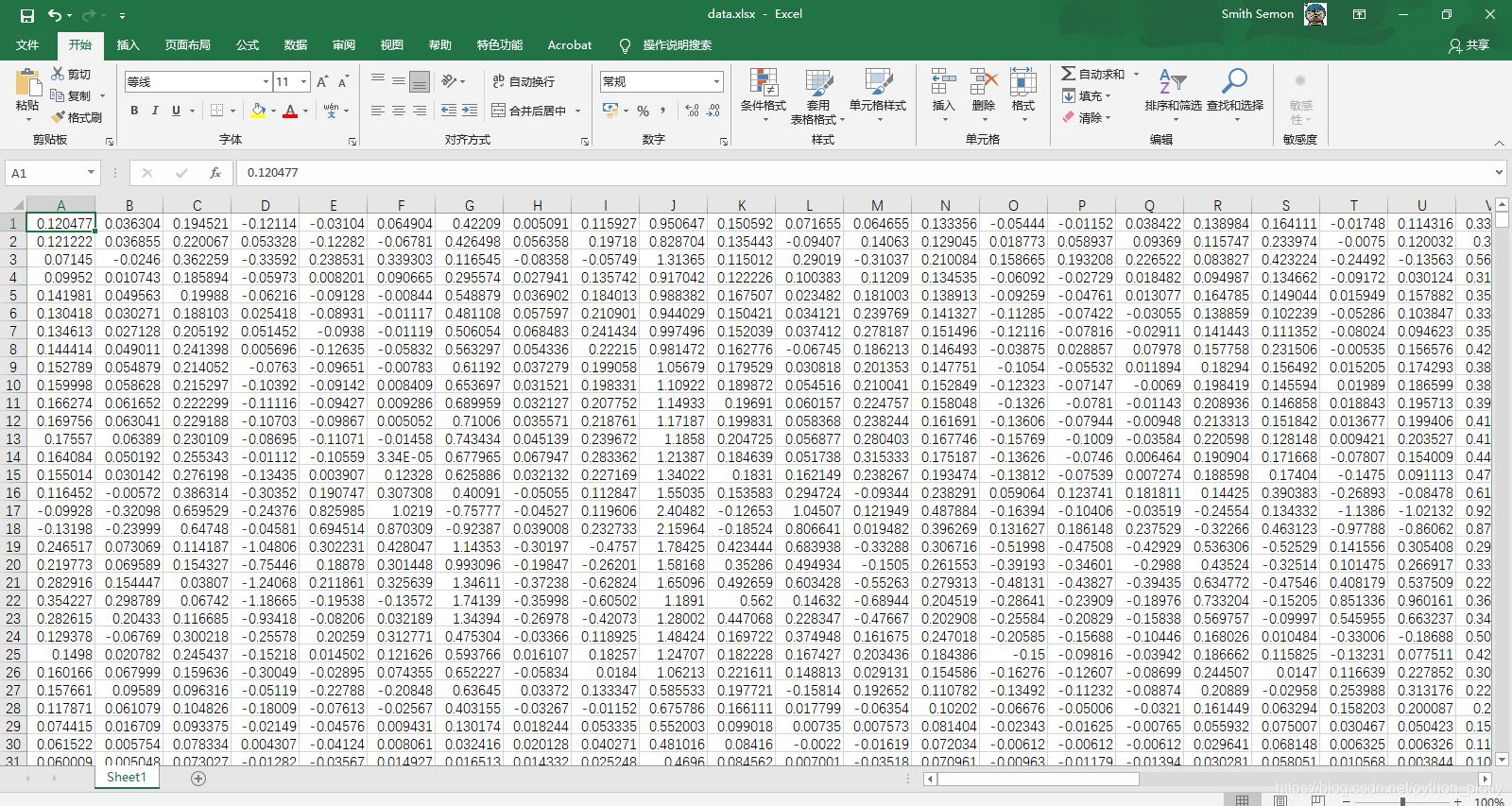
每个数据都站到了自己应该站的位置,太整齐啦哈哈!
以上就是我遇到并解决的第一个问题啦。


















 988
988










 到【灌水乐园】发言
到【灌水乐园】发言







