






原表:
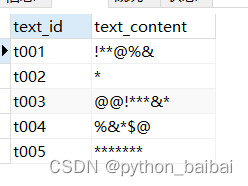
求: 计算每行中*出现的次数
SQL中并没有直接计算字符出现次数的函数,不过也不是不可以算。下面给大家提供一种简单易懂的思路。
SELECT
*, LENGTH(text_content) - LENGTH(
REPLACE (text_content, '*', '')
) as 出现次数
FROM
original_text
结果:
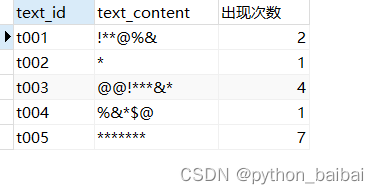
解析:将需要计算的字符替代为空,使用原来字符串的长度减去替换之后的字符串长度,即可得出所需计算的字符出现次数
 SQL计算文本中星号(*)出现次数的实战教程
SQL计算文本中星号(*)出现次数的实战教程
 本文介绍如何在SQL中通过LENGTH和REPLACE函数计算原始文本中'*'字符的出现次数,提供了一种实用的解决方案。
本文介绍如何在SQL中通过LENGTH和REPLACE函数计算原始文本中'*'字符的出现次数,提供了一种实用的解决方案。
原表:
求: 计算每行中*出现的次数
SQL中并没有直接计算字符出现次数的函数,不过也不是不可以算。下面给大家提供一种简单易懂的思路。
SELECT
*, LENGTH(text_content) - LENGTH(
REPLACE (text_content, '*', '')
) as 出现次数
FROM
original_text
结果:
解析:将需要计算的字符替代为空,使用原来字符串的长度减去替换之后的字符串长度,即可得出所需计算的字符出现次数
您可能感兴趣的与本文相关的镜像

Stable-Diffusion-3.5
Stable Diffusion 3.5 (SD 3.5) 是由 Stability AI 推出的新一代文本到图像生成模型,相比 3.0 版本,它提升了图像质量、运行速度和硬件效率
 1371
1371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























