




嗨喽~大家好呀,这里是魔王呐 ❤ ~!

python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取
所用软件
-
Python 3.10 解释器
-
Pycharm 编辑器
使用的模块
-
requests ——>数据请求
-
re ——>正则表达式模块
requests是第三方模块,win + R 输入cmd 输入安装命令 pip install requests 安装即可,re 是自带的模块,无需安装。
实现思路与流程
一. 数据来源分析
1. 明确需求: 明确采集的网站以及数据内容
- 网址: https://****/video/play/933940354.html
- 数据: 视频标题 / 视频内容 <主要数据>
2. 抓包分析: 浏览器开发者工具去抓包
- 打开开发者工具: F12 / 右键点击检查选择network (网络)
- 刷新网页: 网页相关数据内容
- 通过关键字去搜索找到对应的数据包位置
搜索: M3U8 -> getMomentContent
数据包地址: ****/moment/getMomentContent
二. 代码实现步骤
- 发送请求 -> 模拟浏览器对于url地址发送请求
- 获取数据 -> 获取服务器返回响应数据
- 解析数据 -> 提取视频标题 / 链接
- 保存数据 -> 获取视频数据保存本地文件夹里面
源码展示
发送请求 -> 模拟浏览器对于url地址发送请求
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
url = f'h*****/moment/getMomentContent?videoId=904494849&uid=&_=1700050245436'
# 发送请求
response = requests.get(url=url, headers=headers)
获取数据 -> 获取服务器返回响应数据
json_data = response.json() # json() 括号里面不需要加东西
解析数据 -> 提取视频标题 / 链接
# 提取标题
title = json_data['data']['moment']['title']
# 提取视频链接
video_url = json_data['data']['moment']['videoInfo']['definitions'][0]['url']
保存数据 -> 获取视频数据保存本地文件夹里面
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
video_content = requests.get(url=video_url, headers=headers).content
with open('video\\' + title + '.mp4', mode='wb') as f:
# 写入数据
f.write(video_content)
print(title, video_url)
完整源码和视频讲解我都打包好了,直接文末名片自取~
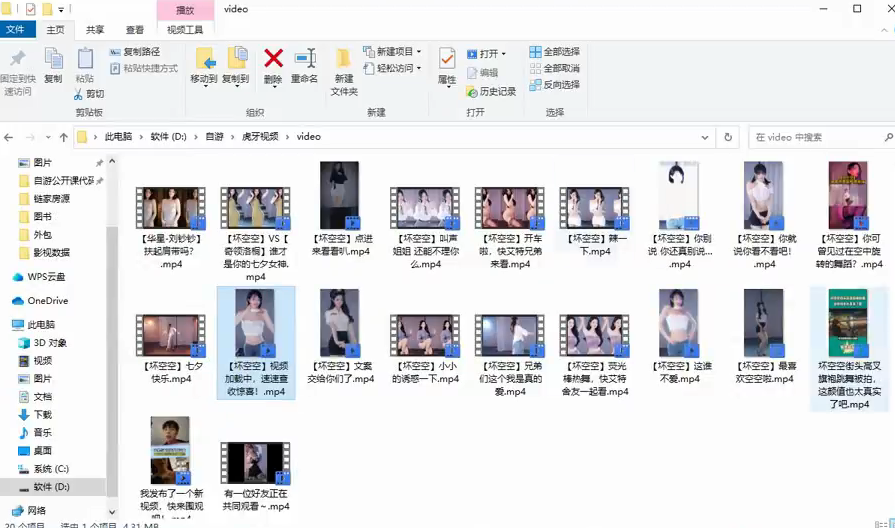
效果展示
播放效果我就不展示了,影响不好,大家自行观看~




尾语
最后感谢你观看我的文章呐~本次航班到这里就结束啦 🛬
希望本篇文章有对你带来帮助 🎉,有学习到一点知识~
躲起来的星星🍥也在努力发光,你也要努力加油(让我们一起努力叭)。


















 827
827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









