




 本文介绍了如何使用Python爬虫从特定网站免费下载音乐。通过输入歌曲或歌手名称,获取音乐ID,然后请求音乐播放URL,最终保存为MP3文件。代码中涉及了requests库的使用,以及数据的解析和保存过程。
本文介绍了如何使用Python爬虫从特定网站免费下载音乐。通过输入歌曲或歌手名称,获取音乐ID,然后请求音乐播放URL,最终保存为MP3文件。代码中涉及了requests库的使用,以及数据的解析和保存过程。
前言
嗨喽~大家好呀,这里是魔王呐
yinyue下载不了?只能试听?甚至听不了?
那么今天我就来教你怎么用Python白嫖yinyue~

所需准备
第三方库:
- requests >>> pip install requests
开发环境:
-
版 本: python 3.8
-
编辑器:pycharm 2021.2
实现代码:
-
发送请求 (访问网站)
-
获取数据
-
解析数据
-
保存数据
代码
因审核机制原因,我把网址里的一些东西删掉了,小可耐们可以自己添加一下哈,很容易的
如果有不太会改或者有点点小懒惰的小可耐也可以私信我,我发你呐~ 💖
注意一下哦~具体爬取的网址我会在评论区打出,大家注意看哦 😄
(或查看并点击网页主页(文章)左侧的流动文字免费获取哦~(可能需要往下划一下呐))
也可以直接查看文章下方推广加助理小姐姐V免费获取呐~
对啦~需要视频教程的也是如上文哦
import requests # 发送请求
headers = {
}
key = input('请输入你要搜索的gequ或者歌手名:')
url = f'http://www..cn/api/www/search/searchMusicBykeyWord?key={key}&pn=1&rn=30&httpsStatus=1&reqId=27600630-069d-11ed-80a1-753c5e991919'
json_data = requests.get(url=url, headers=headers).json()
data_list = json_data['data']['list']
for data in data_list:
artist = data['artist']
name = data['name']
rid = data['rid']
print(rid, name, artist)
# 批量爬取yinyue
# url 变量
# x = 1 ,y = 2
info_url = f'https://www..cn/api/v1/www/music/playUrl?mid={rid}&type=convert_url3&br=320kmp3'
# 1. 发送请求
music_url = requests.get(url=info_url).json()['data']['url']
# 4. 保存数据
music_data = requests.get(url=music_url).content
open(f'music/{name}-{artist}.mp3', mode='wb').write(music_data)
效果
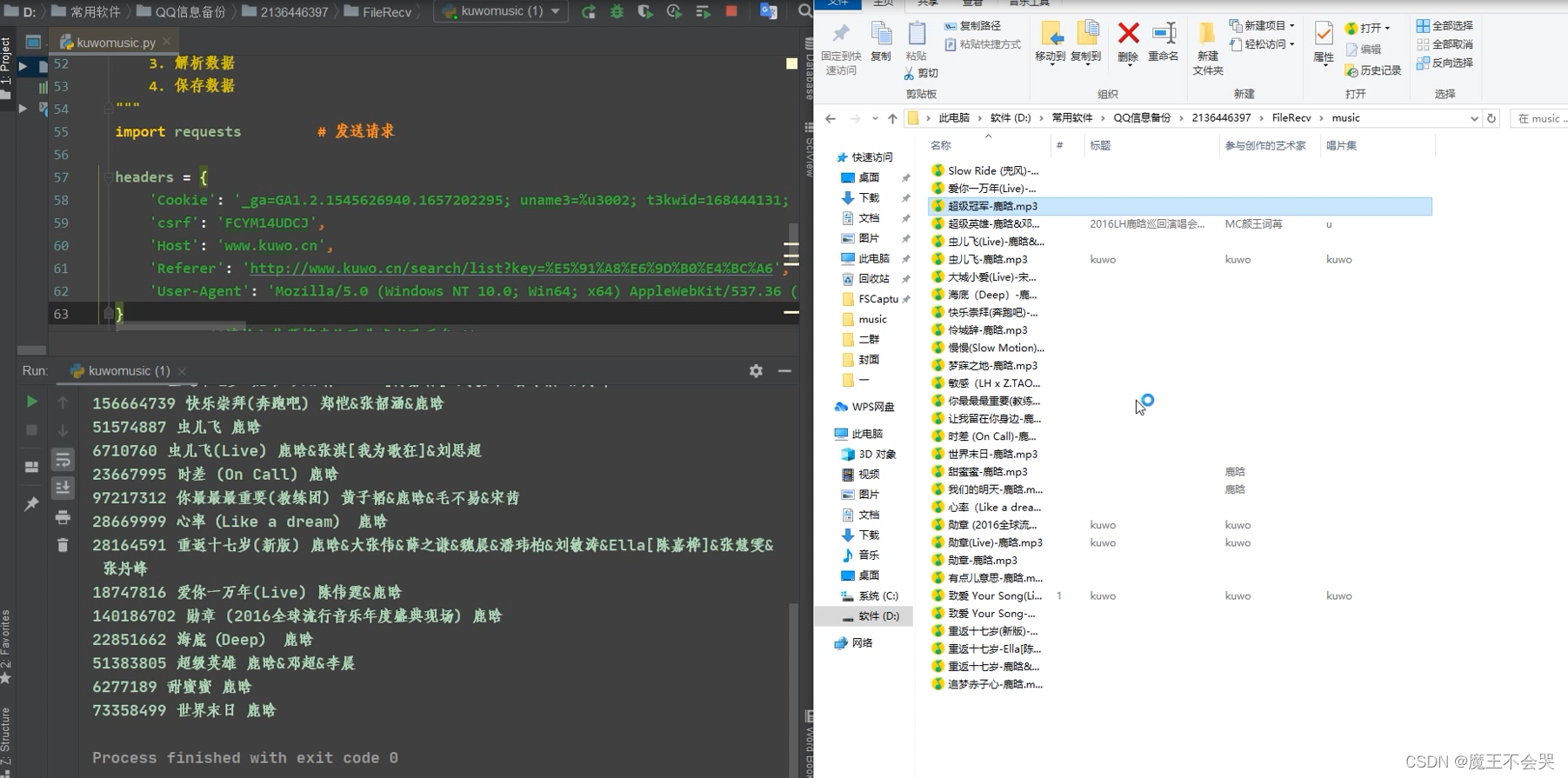
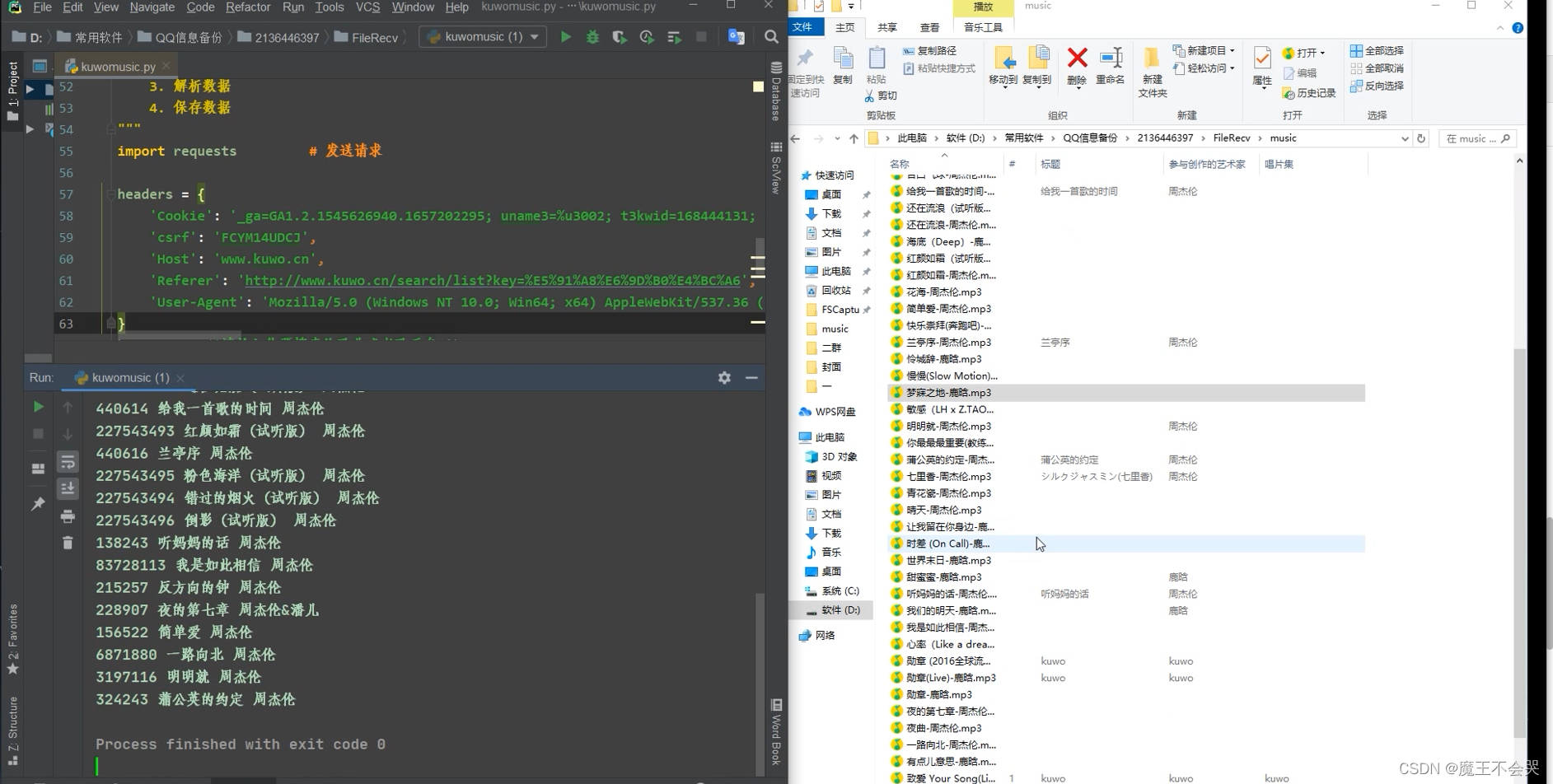
尾语
幸福是可以通过学习来获得的,尽管它不是我们的母语。
人生就是一 场旅行,不在乎目的地,在乎的应该是沿途的风景以及看风景的心情。
——励志语录
本文章到这里就结束啦~感兴趣的小伙伴可以复制代码去试试哦 😝
对啦!!记得三连哦~ 💕 另外,欢迎大家阅读我往期的文章呀~


















 1794
1794




 到【灌水乐园】发言
到【灌水乐园】发言







