






 本文详细介绍了如何使用Python进行网络爬虫,以抓取网页上的表情包资源。从环境配置、模块安装,到代码实现,包括requests、parsel和re库的运用,再到多线程的实现,逐步解析整个过程。通过这个教程,读者可以学习到Python爬虫的基本操作和提高效率的多线程技巧。
本文详细介绍了如何使用Python进行网络爬虫,以抓取网页上的表情包资源。从环境配置、模块安装,到代码实现,包括requests、parsel和re库的运用,再到多线程的实现,逐步解析整个过程。通过这个教程,读者可以学习到Python爬虫的基本操作和提高效率的多线程技巧。
前言
在如今这个人人配一台手机得时代,很多人聊天都是通过网上,但是,怎么样快速缓解尴尬进入快乐而愉快得聊天呢~

刚认识的朋友丢几个表情包出去分分钟拉进关系,女朋友生闷气了整两个表情包开心一下,也可以化解尴尬,没时间打字整两张表情包,礼貌而不失尴尬。不知道回啥时,那更是丢张表情包分分钟钟解决

现在年轻人聊天,不带点表情包都不好意思说自己是年轻人, 表情包已然成为人与人聊天中不可缺少的部分。

准备工作
准备工作很重要,先知道我们要干啥,用什么来做,怎么做,再去一步步实时,稳扎稳打。
开发环境配置
- Python 3.6
- Pycharm
如果有没安装得小伙伴可以左侧主页领取👈👈👈或者私信我领取安装教程~♥♥♥♥♥
模块安装配置
- requests
- parsel
- re
第三方模块,我们需要安装:
-
win + R 输入cmd 输入安装命令 pip install 模块名 如果出现爆红 可能是因为 网络连接超时 切换国内镜像源
-
在pycharm中点击Terminal(终端) 输入安装命令
如何配置pycharm里面的python解释器?
-
选择file(文件) >>> setting(设置) >>> Project(项目) >>> python interpreter(python解释器)
-
点击齿轮, 选择add
-
添加python安装路径
pycharm如何安装插件?
- 选择file(文件) >>> setting(设置) >>> Plugins(插件)
- 点击 Marketplace 输入想要安装的插件名字 比如:翻译插件 输入 translation / 汉化插件 输入 Chinese
- 选择相应的插件点击 install(安装) 即可
- 安装成功之后 是会弹出 重启pycharm的选项 点击确定, 重启即可生效

代码
目标:fabiaoqing
地址前面后面大家自己补全一下,包括后面代码里的,这应该没有不会的吧。
导入模块
import requests
import parsel
import re
import time
请求网址
url = f'fabiaoqing/biaoqing/lists/page/{page}.html'
请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
返回网页源代码
response = requests.get(url=url, headers=headers)
获取数据
# 第一次提取 提取所有的div标签内容
divs = selector.css('#container div.tagbqppdiv') # css 根据标签提取内容
# 通过标签内容提取他的图片url地址
img_url = div.css('img::attr(data-original)').get()
# 提取标题
title = div.css('img::attr(title)').get()
# 获取图片的后缀名
name = img_url.split('.')[-1]
保存数据
new_title = change_title(title)
对表情包图片发送请求 获取它二进制数据
img_content = requests.get(url=img_url, headers=headers).content
保存数据
def save(title, img_url, name):
img_content = get_response(img_url).content
try:
with open('img\\' + title + '.' + name, mode='wb') as f:
# 写入图片二进制数据
f.write(img_content)
print('正在保存:', title)
except:
pass
# 替换标题中的特殊字符
# 因为文件命名不明还有特殊字符,所以我们需要通过正则表达式替换掉特殊字符。
def change_title(title):
mode = re.compile(r'[\\\/\:\*\?\"\<\>\|]')
new_title = re.sub(mode, "_", title)
return new_title
记录时间
time_2 = time.time()
use_time = int(time_2) - int(time_1)
print(f'总共耗时:{use_time}秒')

多线程
import requests
import parsel
import re
import time
import concurrent.futures
def change_title(title):
mode = re.compile(r'[\\\/\:\*\?\"\<\>\|]')
new_title = re.sub(mode, "_", title)
return new_title
def get_response(html_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
repsonse = requests.get(url=html_url, headers=headers)
return repsonse
def save(title, img_url, name):
img_content = get_response(img_url).content
try:
with open('img\\' + title + '.' + name, mode='wb') as f:
f.write(img_content)
print('正在保存:', title)
except:
pass
def main(html_url):
html_data = get_response(html_url).text
selector = parsel.Selector(html_data)
divs = selector.css('#container div.tagbqppdiv')
for div in divs:
img_url = div.css('img::attr(data-original)').get()
title = div.css('img::attr(title)').get()
name = img_url.split('.')[-1]
new_title = change_title(title)
save(new_title, img_url, name)
if __name__ == '__main__':
time_1 = time.time()
exe = concurrent.futures.ThreadPoolExecutor(max_workers=10)
for page in range(1, 201):
url = f'fabiaoqing/biaoqing/lists/page/{page}.html'
exe.submit(main, url)
exe.shutdown()
time_2 = time.time()
use_time = int(time_2) - int(time_1)
print(f'总共耗时:{use_time}秒')
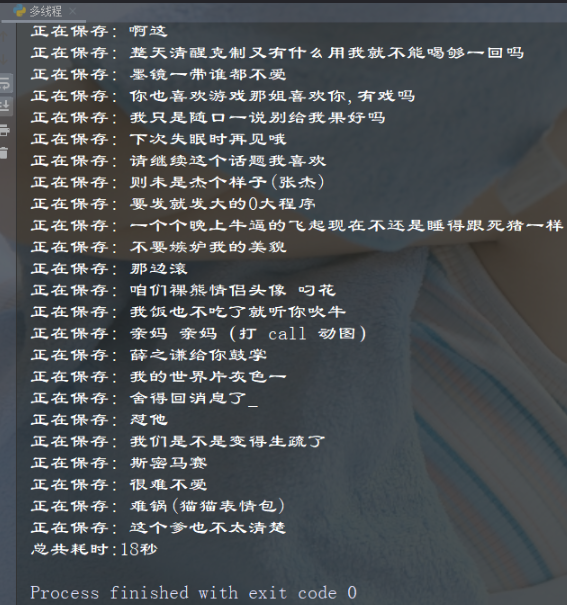
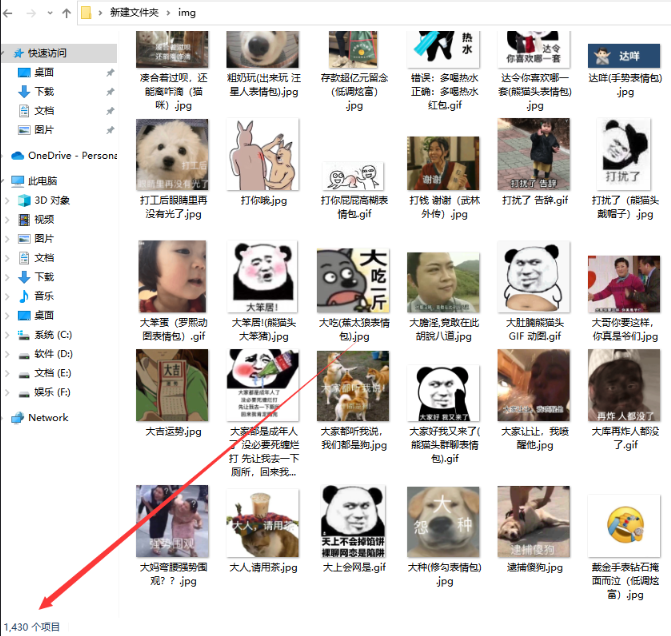
大家看完觉得有用的话,点个赞收藏一下呗 ♥♥♥♥♥♥



















 2373
2373





 到【灌水乐园】发言
到【灌水乐园】发言







