



DeepAgents是LangChain推出的Python框架,具备任务规划、工具调用等核心能力。本文详细介绍了如何基于DeepAgents构建MySQL数据分析助手,包括4个核心工具的实现与注册,以及完整的从零搭建部署流程。通过Agent Chat UI进行可视化调试,实现企业级数据分析助手,让开发者轻松应对复杂数据分析任务。
1、核心优势:为什么选DeepAgents做数据分析?
1.工具调用原生支持:无需额外封装,框架自带工具注册、参数解析能力,轻松集成数据库、文件系统等工具;
2.任务规划能力:通过System Prompt定义思维链(CoT),强制AI按步骤调用工具,避免跳跃执行;
3.会话与内存持久化:支持会话级上下文管理,工具调用结果、中间状态自动缓存,无需重复操作;
4.工作区隔离:每个会话拥有独立文件目录,工具执行(如SQL结果保存、文件上传)互不干扰,安全可控。
2、企业级架构设计(4层架构+工具调用核心)
系统采用「基于会话(Session-based)」的分层架构,工具调用贯穿核心流程。
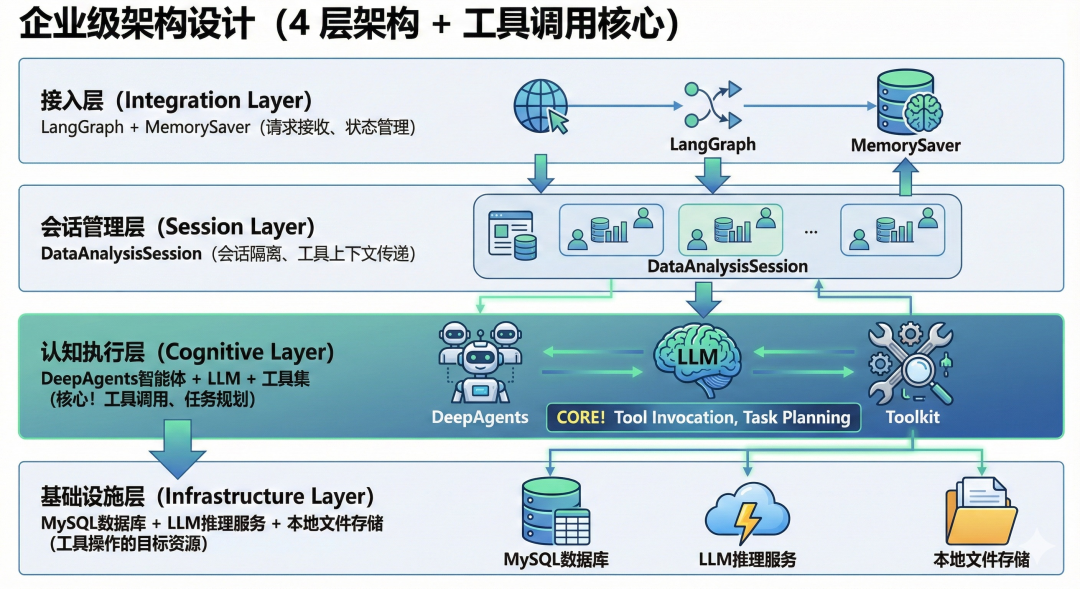
重点聚焦:认知执行层的工具调用设计
这是整个系统的核心,工具调用的「定义-注册-执行-反馈」全流程都在这里实现:
2.1 工具集设计原则
•单一职责:每个工具只做一件事(如查表名、查结构、执行SQL),便于AI理解和调用;
•安全可控:工具内置权限校验(如SQL仅允许查询)、参数校验(如表名合法性);
•返回友好:工具返回结果格式统一(文本/Markdown),便于LLM读取和分析。
3、工具调用核心实现(代码块+逐行分析)
下面我们逐一拆解4个核心工具的实现,以及如何注册到DeepAgents智能体中——这是搭建助手的关键步骤,建议收藏对照代码实操!
3.1 工具1:获取数据库所有表名(get_all_tables)
作用:让AI快速了解数据库全貌,为后续表筛选提供基础。
def get_all_tables() -> str:
"""Show all tables in the database"""
try:
conn = get_db_connection() # 复用数据库连接函数
with conn.cursor() as cursor:
cursor.execute(f"SHOW TABLES FROM {DB_NAME}")
tables = cursor.fetchall()
# 提取表名(适配DictCursor返回格式)
table_names = [list(row.values())[0] for row in tables]
return f"Tables in {DB_NAME}:\n" + "\n".join(table_names)
except Exception as e:
return f"Error fetching tables: {str(e)}"
finally:
# 确保连接关闭,避免资源泄露
if 'conn' in locals() and conn.open:
conn.close()
代码分析:
•连接复用:通过get_db_connection()统一管理数据库连接,降低冗余;•结果格式化:返回清晰的表名列表,LLM无需解析复杂字典结构;•异常处理:捕获数据库连接、查询错误,返回友好提示,避免程序崩溃。
3.2 工具2:获取表结构定义(get_table_definition)
作用:让AI了解目标表的字段名、类型、注释,为写SQL提供依据。
def get_table_definition(table_name: str) -> str:
"""Get the CREATE TABLE statement for a specific table"""
try:
# 核心安全校验:防止SQL注入(表名仅允许字母、数字、点、下划线)
if not table_name.isidentifier() and not table_name.replace('.', '').isidentifier():
return f"Error: Invalid table name '{table_name}'"
conn = get_db_connection()
with conn.cursor() as cursor:
# 执行SHOW CREATE TABLE,获取完整表结构(含注释)
cursor.execute(f"SHOW CREATE TABLE {DB_NAME}.{table_name}")
result = cursor.fetchone()
if result:
return f"Table Definition for '{table_name}':\n{result['Create Table']}"
return f"Table '{table_name}' not found."
except Exception as e:
return f"Error fetching table definition: {str(e)}"
finally:
if 'conn' in locals() and conn.open:
conn.close()
代码分析:
•注入防护:通过isidentifier()校验表名合法性,杜绝table_name="user; DROP TABLE user;"这类恶意输入;•信息完整:返回CREATE TABLE语句,包含字段类型、注释、主键等关键信息,帮助AI准确理解表结构。
3.3 工具3:执行SQL查询(run_sql_query)
作用:AI生成SQL后,通过该工具执行并返回格式化结果(核心工具)。
def run_sql_query(query: str) -> str:
"""Execute a SQL query and return results as markdown table"""
try:
# 核心安全限制:仅允许查询类SQL,杜绝删改操作
allowed_prefixes = ["SELECT", "SHOW", "DESCRIBE"]
if not any(query.strip().upper().startswith(prefix) for prefix in allowed_prefixes):
return "Error: Only SELECT, SHOW, and DESCRIBE queries are allowed for analysis."
conn = get_db_connection()
with conn.cursor() as cursor:
cursor.execute(query)
results = cursor.fetchall()
if not results:
return "Query executed successfully. No results returned."
# 结果格式化:转为Markdown表格,LLM易读,用户直观
df = pd.DataFrame(results)
return df.to_markdown(index=False)
except Exception as e:
return f"Error executing SQL query: {str(e)}"
finally:
if 'conn' in locals() and conn.open:
conn.close()
代码分析:
•操作限制:通过前缀校验,仅允许查询类SQL,从根源避免误删/改数据;•结果优化:用Pandas将字典列表转为Markdown表格,解决LLM难以解析原始数据的问题;•异常捕获:捕获SQL语法错误、字段不存在等问题,返回具体错误信息,帮助AI修正SQL。
3.4 工具4:执行Shell命令(run_shell_command)
作用:辅助操作(如查看文件、数据预处理),扩展助手能力边界。
def run_shell_command(command: str) -> str:
"""Execute a shell command and return stdout/stderr"""
try:
result = subprocess.run(
command,
shell=True,
capture_output=True,
text=True,
timeout=60 # 超时控制:防止命令长时间阻塞
)
output = result.stdout
error = result.stderr
if error:
return f"Output:\n{output}\n\nError:\n{error}"
return output if output else "Command executed successfully (no output)."
except Exception as e:
return f"Error executing command: {str(e)}"
代码分析:
•超时控制:设置60秒超时,避免ping等无限循环命令占用资源;•输出完整:同时返回stdout和stderr,便于AI排查命令执行失败原因。
3.5 工具注册:将工具集成到DeepAgents智能体
工具定义后,需注册到DeepAgents智能体中,LLM才能自主调用。核心代码如下:
# 在DataAnalysisSession类的__init__方法中
def __init__(self, config: AppSessionConfig):
# ... 其他初始化逻辑(工作区、模型配置等)...
# 系统提示词:明确工具调用流程(思维链引导)
system_prompt = """你是专业的MySQL数据分析助手,必须通过以下步骤和工具完成任务:
1. 用write_todos拆解任务(如:1. 查所有表;2. 查用户表结构;3. 统计注册量);
2. 用get_all_tables获取所有表名,筛选相关表;
3. 用get_table_definition查看目标表结构(重点看字段注释);
4. 用run_sql_query执行SQL(仅查询类),获取数据;
5. 分析Markdown结果,生成自然语言总结。
工具调用失败时,根据错误信息修正后重试(如表名错误、SQL语法错误)。
"""
# 核心:注册工具到DeepAgents智能体
self.agent = create_deep_agent(
model=self.model, # 已配置的LLM(如qwen3-coder)
backend=self.backend, # 文件系统后端(工作区访问)
tools=[get_all_tables, get_table_definition, run_sql_query, run_shell_command], # 工具列表
system_prompt=system_prompt # 思维链引导
)
代码分析:
•工具注册:直接将函数列表传入tools参数,DeepAgents会自动解析函数参数、生成调用格式;•思维链引导:通过System Prompt强制AI按步骤调用工具,避免跳过关键环节(如未查表结构就写SQL);•后端绑定:FilesystemBackend与会话工作区关联,工具(如run_shell_command)的文件操作会限制在会话专属目录。
4、工具调用工作流(从用户提问到结果返回)
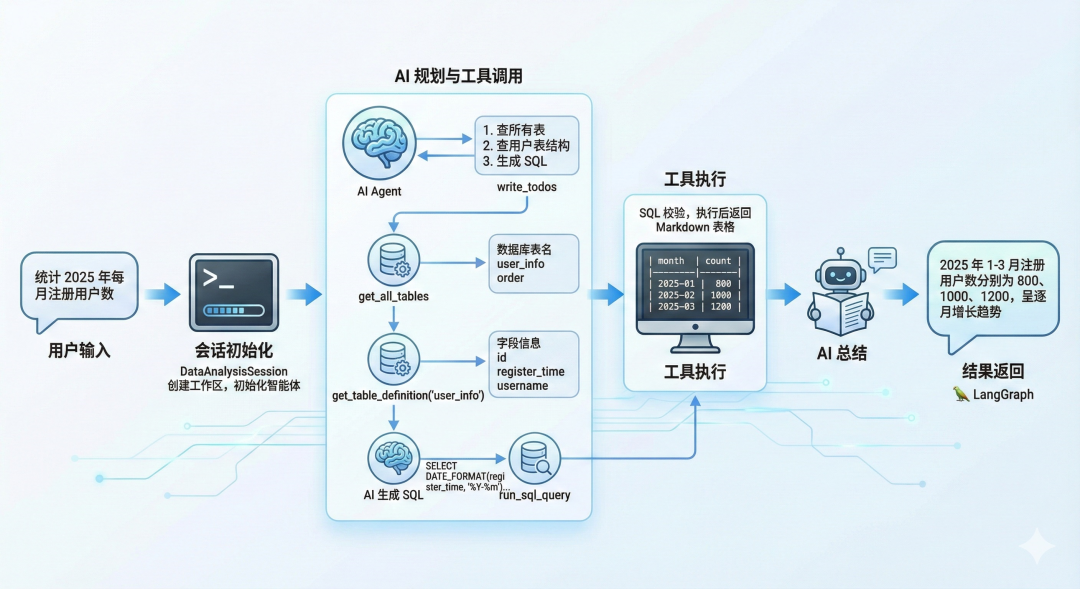
1.用户输入:“统计2025年每月注册用户数”;2.会话初始化:DataAnalysisSession创建独立工作区,初始化智能体;3.AI规划与工具调用:
•第一步:AI调用write_todos生成任务列表(“1. 查所有表;2. 查用户表结构;3. 生成SQL统计每月注册量”);•第二步:AI调用get_all_tables,返回数据库中所有表名(如user_info、order);•第三步:AI调用get_table_definition("user_info"),获取字段(如id、register_time、username);•第四步:AI生成SQL(SELECT DATE_FORMAT(register_time, '%Y-%m') AS month, COUNT(*) AS count FROM user_info WHERE YEAR(register_time)=2025 GROUP BY month),调用run_sql_query;
•工具执行:校验SQL为SELECT类型,执行后返回Markdown表格;
•第五步:AI读取Markdown表格,生成总结(“2025年1-3月注册用户数分别为800、1000、1200,呈逐月增长趋势”);
4.结果返回:将AI总结通过LangGraph返回给用户。
5、手把手实操:从0到1搭建部署
第一步:环境准备
# 创建虚拟环境
python -m venv deepagents-env
# 激活环境(Windows)
deepagents-env\Scripts\activate
# 激活环境(Mac/Linux)
source deepagents-env/bin/activate
# 安装依赖(含DeepAgents、LangGraph、数据库驱动等)
pip install pandas pymysql langchain-openai langgraph deepagents
第二步:核心配置修改
# 1. 数据库配置(替换为你的MySQL信息)
DB_HOST = "你的MySQL地址" # 如127.0.0.1
DB_USER = "用户名" # 如root
DB_PASSWORD = "密码" # 如123456
DB_NAME = "数据库名" # 如user_data
# 2. LLM配置(对接本地/远程模型)
os.environ["OPENAI_API_BASE"] = "http://你的模型地址:端口/v1" # 如http://127.0.0.1:18080/v1
os.environ["OPENAI_API_KEY"] = "dummy" # 本地模型填占位符
第三步:本地测试(工具调用验证)
async def main():
# 会话配置
config = AppSessionConfig(
session_id="test_session_001",
workspace_base=os.path.join(BASE_DIR, "sessions")
)
session = DataAnalysisSession(config)
# 测试查询(触发工具调用流程)
query = "1. 显示数据库所有表;2. 查看user_info表结构;3. 统计2025年每月注册用户数"
response = await session.send_message(query)
# 打印结果(含工具调用过程和最终总结)
for msg in response:
print(msg.content)
if __name__ == "__main__":
asyncio.run(main())
6、可视化调试:用Agent Chat UI对接智能体
Agent Chat UI 是 LangChain 官方开发的 基于 Next.js 的可视化聊天工具,专为 LangGraph 代理设计——支持工具调用流程可视化、会话历史管理、错误日志查看,比命令行测试更直观,是调试智能体的绝佳选择!
6.1 Agent Chat UI 核心优势
1.可视化工具调用:清晰展示AI调用了哪些工具、参数是什么、返回结果如何;2.会话持久化:自动保存聊天记录,支持多轮对话上下文连贯;3.错误排查:工具调用失败时,可查看完整错误日志,快速定位问题;4.零代码对接:只需配置LangGraph服务地址,即可连接智能体。
6.2 部署与配置步骤
第一步:安装Agent Chat UI
# 1. 克隆官方仓库(需提前安装Git)
git clone https://github.com/langchain-ai/agent-chat-ui.git
cd agent-chat-ui
# 2. 安装依赖(需提前安装Node.js 18+)
npm install
第二步:配置LangGraph服务地址
1.打开Agent Chat UI配置文件:agent-chat-ui/app/config.ts2.修改langGraphEndpoint为你的LangGraph服务地址(本地默认是http://localhost:22204):
// agent-chat-ui/app/config.ts
export const config = {
// 核心配置:对接你的LangGraph服务
langGraphEndpoint: "http://localhost:22204", // 本地LangGraph服务地址
// 可选配置:设置API密钥(如果你的服务需要认证)
apiKey: "dummy", // 本地服务无需认证,填占位符即可
// 其他配置保持默认
title: "DeepAgents MySQL数据分析助手",
description: "基于DeepAgents的可视化数据分析工具",
};
第三步:启动LangGraph服务(后端)
回到你的智能体代码目录,启动LangGraph服务:
# 确保已激活Python虚拟环境
langgraph dev --host 0.0.0.0 --port 22204
此时后端服务会在http://localhost:22204运行,等待Agent Chat UI连接。
第四步:启动Agent Chat UI(前端)
在agent-chat-ui目录下执行:
# 启动前端服务(默认端口3000)
npm run dev
第五步:开始可视化调试
1.浏览器访问:http://localhost:3000,即可看到聊天界面;
2.输入测试查询(如“统计2025年每月注册用户数”),点击发送;3.查看工具调用流程:
•左侧:聊天输入/输出区域,展示最终结果;•右侧:工具调用日志,可展开查看每个工具的调用参数、返回结果;•若工具调用失败(如表名错误、SQL语法错误),右侧会显示完整错误信息,便于调试。
6.3 调试示例:查看工具调用详情
当你输入“统计2025年每月注册用户数”后,Agent Chat UI右侧会显示完整的工具调用链路:
1. 调用write_todos → 返回任务列表
2. 调用get_all_tables → 返回数据库表名列表
3. 调用get_table_definition("user_info") → 返回表结构
4. 调用run_sql_query → 返回Markdown格式的统计结果
点击每个工具调用项,可展开查看:
•工具名称和参数;•执行状态(成功/失败);•完整返回结果。
总结:DeepAgents+Agent Chat UI的高效开发组合
1.DeepAgents:负责底层智能体逻辑、工具调用、任务规划,让你无需关注复杂的代理架构,聚焦业务工具开发;2.Agent Chat UI:负责前端可视化调试,让工具调用流程、错误信息一目了然,大幅提升调试效率;3.LangGraph:作为中间层,连接智能体与UI,提供稳定的API服务,支持多用户并发访问。
借助LangChain生态的这套“组合拳”,我们能以极低的成本搭建企业级数据分析助手——既保证了底层架构的稳定性、安全性,又通过可视化工具降低了开发调试门槛。无论是个人开发者快速验证想法,还是团队落地生产级应用,这套方案都能完美适配!
限时免费!优快云 大模型学习大礼包开放领取!
从入门到进阶,助你快速掌握核心技能!
资料目录
- AI大模型学习路线图
- 配套视频教程
- 大模型学习书籍
- AI大模型最新行业报告
- 大模型项目实战
- 面试题合集
👇👇扫码免费领取全部内容👇👇

📚 资源包核心内容一览:
1、 AI大模型学习路线图
- 成长路线图 & 学习规划: 科学系统的新手入门指南,避免走弯路,明确学习方向。

2、配套视频教程
- 根据学习路线配套的视频教程:涵盖核心知识板块,告别晦涩文字,快速理解重点难点。

课程精彩瞬间

3、大模型学习书籍

4、 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

6、大模型大厂面试真题
整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题,涵盖基础理论、技术实操、项目经验等维度,每道题都配有详细解析和答题思路,帮你针对性提升面试竞争力。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









